A Mechanistic Analysis of Adversarial Fine-tuning of Vision Transformers
Pith reviewed 2026-06-29 08:09 UTC · model grok-4.3
The pith
Adversarial fine-tuning on specific corruptions improves Vision Transformer performance only on matching corruption types and leaves sparse representations unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
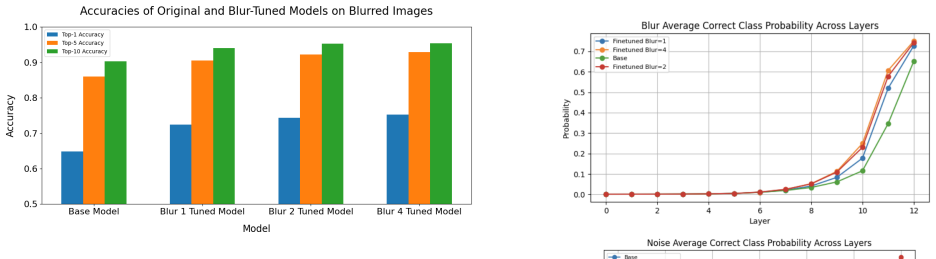
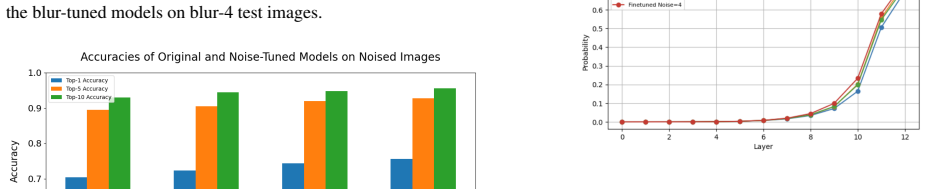
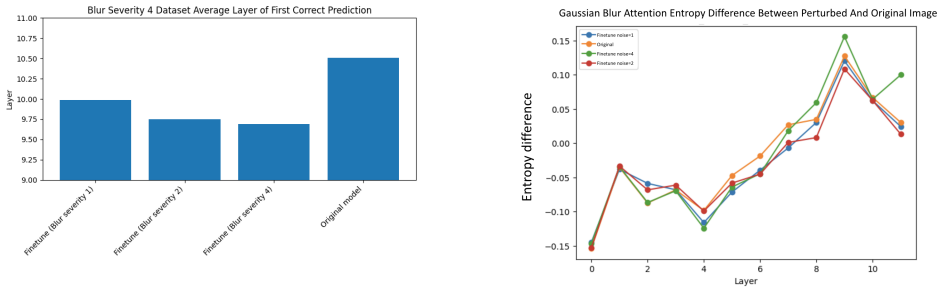
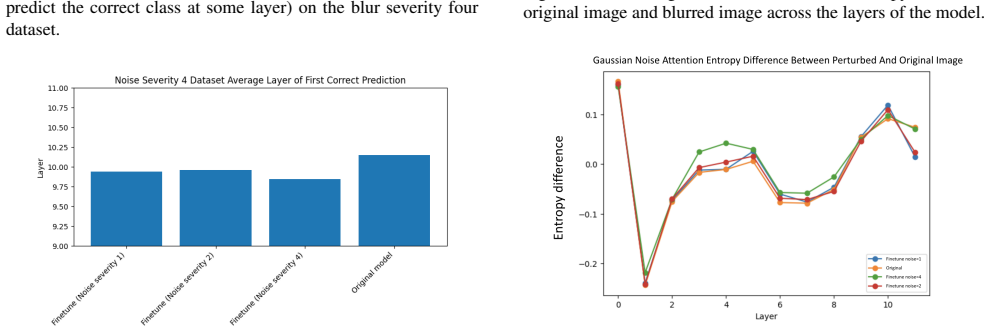
Adversarial fine-tuning on low-frequency and high-frequency image corruptions leads to improved performance and certainty on new instances of those same corruptions, but the improvements do not transfer to other corruption classes. Although visual attention and knowledge evolution change across layers, adversarial training produces no fundamental alterations to the sparse representations learned by the Vision Transformers.
What carries the argument
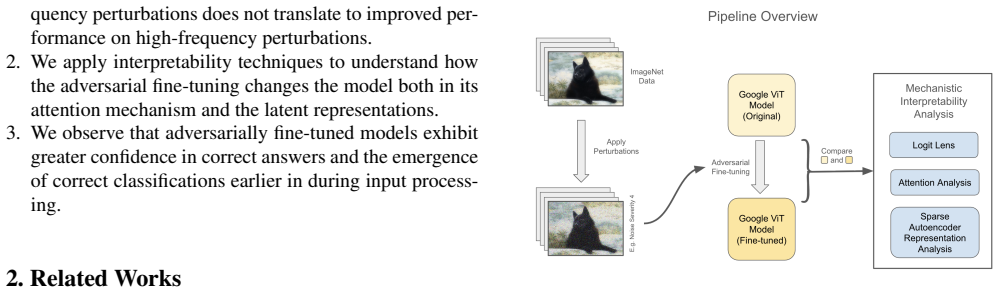
Mechanistic examination of attention mechanisms, internal representations, and knowledge evolution across layers to track effects of adversarial fine-tuning.
If this is right
- Performance and certainty improve specifically on new instances of the corruptions used during fine-tuning.
- Robustness gains do not extend to corruption classes absent from the fine-tuning data.
- Visual attention and knowledge evolution shift across layers after adversarial training.
- The sparse representations inside the Vision Transformer remain unchanged in their fundamental structure.
Where Pith is reading between the lines
- Training on a wider mix of corruption types during fine-tuning may be needed to achieve broader robustness.
- The unchanged sparse representations suggest that ViT architectures may require different training strategies to alter their core internal processing.
- Similar mechanistic checks could be applied to other fine-tuning methods or to multimodal models that incorporate ViTs.
Load-bearing premise
That the tracked changes in attention, representations, and layer-wise knowledge evolution are the factors that determine whether robustness transfers between corruption types.
What would settle it
Finding that fine-tuning on one set of corruptions raises accuracy on a completely different, unseen corruption class would contradict the non-transfer result.
Figures


read the original abstract
The widespread use of image classification models in high-risk, real-world situations necessitates making these models robust to slight disturbances or perturbations, such as blurring or sharpening, in the input images. While vision transformers (ViTs) play an integral role in many modern-day multi-modal models like Vision-Language-Models (VLMs) and Vision-Language-Action (VLA) models, they have received a lack of attention in the setting of robustness. In this work, we analyze the effects of adversarial fine-tuning, a popular method for improving model robustness to image perturbations, on a ViT's performance on perturbed and regular images through a mechanistic lens. We adversarially train a ViT on low-frequency and high-frequency image corruptions, and attempt to explain changes in downstream model performance through an examination of the model's attention mechanisms, internal representations, and knowledge evolution. Overall, our results suggest that, while fine-tuning on inputs with common corruptions improves model performance and certainty on new instances of corrupted data, these improvements do not transfer to other classes of corruptions not seen in the training. Additionally, despite observing changes in visual attention and knowledge evolution across layers, we found that adversarial training did not lead to fundamental changes in the sparse representations learned by ViTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines adversarial fine-tuning of Vision Transformers (ViTs) on low-frequency and high-frequency image corruptions. It reports that such fine-tuning improves model performance and certainty on new instances of the trained corruptions but that these gains do not transfer to other corruption classes. Through mechanistic analysis of attention mechanisms, internal representations, and layer-wise knowledge evolution, the authors conclude that adversarial training produces observable changes in attention and knowledge evolution yet leaves the sparse representations learned by ViTs fundamentally unchanged.
Significance. If the experimental outcomes are reproducible, the work supplies concrete observational evidence on the specificity of corruption robustness in ViTs and on the stability of their sparse representations under adversarial fine-tuning. These findings are relevant to the robustness of ViTs inside larger multi-modal architectures and could guide the design of more generalizable robustness interventions.
major comments (2)
- [Abstract] Abstract: the central claim that 'adversarial training did not lead to fundamental changes in the sparse representations' is stated without any description of the sparsity metric, the quantitative threshold for 'fundamental,' or the statistical test used to establish invariance; this measurement detail is load-bearing for the mechanistic conclusion.
- [Abstract] Abstract: the performance and transfer claims ('improves model performance and certainty on new instances... these improvements do not transfer') are presented without reference to specific datasets, corruption parameters, accuracy deltas, or controls for model capacity and training budget, preventing assessment of whether the non-transfer result is robust.
minor comments (2)
- [Abstract] The abstract uses the term 'adversarially train' without clarifying whether this refers to standard adversarial training (e.g., PGD) or a corruption-specific procedure; a brief definition would improve clarity.
- [Abstract] The phrase 'knowledge evolution across layers' is introduced without indicating the operational definition or visualization method employed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the abstract for greater precision and self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'adversarial training did not lead to fundamental changes in the sparse representations' is stated without any description of the sparsity metric, the quantitative threshold for 'fundamental,' or the statistical test used to establish invariance; this measurement detail is load-bearing for the mechanistic conclusion.
Authors: The referee is correct that the abstract omits these measurement details. The main text defines the sparsity metric (activation sparsity via L0-norm on MLP outputs) and the invariance criterion (no statistically significant change via paired tests across layers). We will revise the abstract to include a concise reference to the metric and the invariance test. revision: yes
-
Referee: [Abstract] Abstract: the performance and transfer claims ('improves model performance and certainty on new instances... these improvements do not transfer') are presented without reference to specific datasets, corruption parameters, accuracy deltas, or controls for model capacity and training budget, preventing assessment of whether the non-transfer result is robust.
Authors: The referee correctly observes that the abstract is high-level. The full manuscript specifies the ImageNet dataset, low- and high-frequency corruptions from the Common Corruptions benchmark, accuracy deltas on seen vs. unseen corruptions, and controls for ViT size and training budget in the experimental setup. We will revise the abstract to reference the dataset family and report the key quantitative outcomes. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports observational results from controlled adversarial fine-tuning experiments on ViTs using frequency-based corruptions, measuring downstream performance, attention maps, layer-wise knowledge evolution, and representation sparsity. No equations, derivations, or first-principles claims appear; all central statements are presented as direct experimental outcomes without reduction to fitted parameters, self-definitions, or self-citation chains. The analysis is self-contained against external benchmarks and contains no load-bearing steps that collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A computer vision approach for autonomous cars to drive safe at construction zone, 2024
Abu Shad Ahammed, Md Shahi Amran Hossain, and Roman Obermaisser. A computer vision approach for autonomous cars to drive safe at construction zone, 2024. 1
2024
-
[2]
Batchtopk sparse autoencoders, 2024
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders, 2024. 3
2024
-
[3]
Sparse autoencoders find highly interpretable features in language models, 2023
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models, 2023. 2, 3
2023
-
[4]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 2, 3
2009
-
[5]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. 3
2021
-
[6]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 3
2025
-
[7]
C-lead: Con- trastive learning for enhanced adversarial defense, 2025
Suklav Ghosh, Sonal Kumar, and Arijit Sur. C-lead: Con- trastive learning for enhanced adversarial defense, 2025. 2
2025
-
[8]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples, 2015. 2
2015
-
[9]
Benchmarking neu- ral network robustness to common corruptions and perturba- tions, 2019
Dan Hendrycks and Thomas Dietterich. Benchmarking neu- ral network robustness to common corruptions and perturba- tions, 2019. 2
2019
-
[10]
Vision transformers don’t need trained registers, 2025
Nick Jiang, Amil Dravid, Alexei Efros, and Yossi Gandels- man. Vision transformers don’t need trained registers, 2025. 2
2025
-
[11]
Laying the foundations for vision and multimodal mechanistic interpretability & open problems.https://www.alignmentforum
Sonia Joseph and Neel Nanda. Laying the foundations for vision and multimodal mechanistic interpretability & open problems.https://www.alignmentforum. org/posts/kobJymvvcvhbjWFKe/laying- the- foundations - for - vision - and - multimodal - mechanistic, 2024. AI Alignment Forum post. 2
2024
-
[12]
Openvla: An open- source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Fos- ter, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kol- lar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open- source vision-language-action model, 2024. 1
2024
-
[13]
Towards deep learning models resistant to adversarial attacks, 2019
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks, 2019. 2
2019
-
[14]
On the robustness of vision transformers to adversarial ex- amples, 2021
Kaleel Mahmood, Rigel Mahmood, and Marten van Dijk. On the robustness of vision transformers to adversarial ex- amples, 2021. 2
2021
-
[15]
Locating and editing factual associations in gpt,
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in gpt,
-
[16]
interpreting gpt: the logit lens
nostalgebraist. interpreting gpt: the logit lens. https : / / www . lesswrong . com / posts / AcKRB8wDpdaN6v6ru / interpreting - gpt - the- logit- lens, 2020. LessWrong post, accessed
2020
-
[17]
A closer look at robustness to l-infinity and spatial perturbations and their composition, 2022
Luke Rowe, Benjamin Th ´erien, Krzysztof Czarnecki, and Hongyang Zhang. A closer look at robustness to l-infinity and spatial perturbations and their composition, 2022. 2 6
2022
-
[18]
Berg, and Li Fei-Fei
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Chal- lenge.International Journal of Computer Vision (IJCV), 115 (3):211–252, 2015. 3
2015
-
[19]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra. Grad-cam: Visual explanations from deep networks via gradient-based localization.International Journal of Com- puter Vision, 128(2):336–359, 2019. 2
2019
-
[20]
Interpretable and testable vision features via sparse au- toencoders, 2025
Samuel Stevens, Wei-Lun Chao, Tanya Berger-Wolf, and Yu Su. Interpretable and testable vision features via sparse au- toencoders, 2025. 2
2025
-
[21]
Diffusion lens: Interpreting text encoders in text-to-image pipelines
Michael Toker, Hadas Orgad, Mor Ventura, Dana Arad, and Yonatan Belinkov. Diffusion lens: Interpreting text encoders in text-to-image pipelines. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), page 9713–9728. Association for Computational Linguistics, 2024. 2
2024
-
[22]
Analysing the robustness of vision-language-models to common cor- ruptions, 2025
Muhammad Usama, Syeda Aishah Asim, Syed Bilal Ali, Syed Talal Wasim, and Umair Bin Mansoor. Analysing the robustness of vision-language-models to common cor- ruptions, 2025. 2
2025
-
[23]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small,
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small,
-
[24]
A survey on the robustness of computer vision models against common corruptions, 2024
Shunxin Wang, Raymond Veldhuis, Christoph Brune, and Nicola Strisciuglio. A survey on the robustness of computer vision models against common corruptions, 2024. 2
2024
-
[25]
Visual transform- ers: Token-based image representation and processing for computer vision, 2020
Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Zhicheng Yan, Masayoshi Tomizuka, Joseph Gonzalez, Kurt Keutzer, and Peter Vajda. Visual transform- ers: Token-based image representation and processing for computer vision, 2020. 3
2020
-
[26]
Med3dvlm: An efficient vision-language model for 3d med- ical image analysis, 2025
Yu Xin, Gorkem Can Ates, Kuang Gong, and Wei Shao. Med3dvlm: An efficient vision-language model for 3d med- ical image analysis, 2025. 1
2025
-
[27]
Investigating the catastrophic for- getting in multimodal large language models, 2023
Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, and Yi Ma. Investigating the catastrophic for- getting in multimodal large language models, 2023. 1 7
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.