HARP: Efficient Data Selection for Finetuning Large Language Models
Pith reviewed 2026-06-27 22:47 UTC · model grok-4.3
The pith
HARP selects high-utility finetuning data for large language models by evaluating only representative leaves in a hierarchy and inferring the rest via empirical Bayes posteriors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
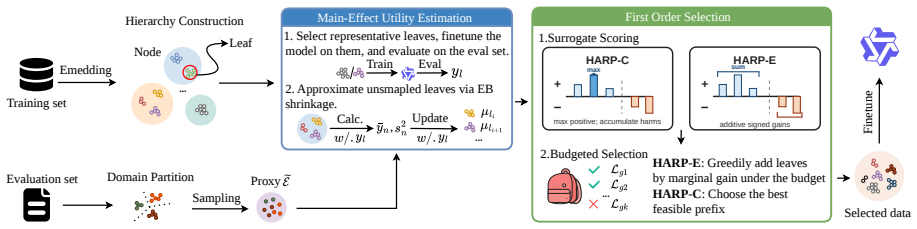
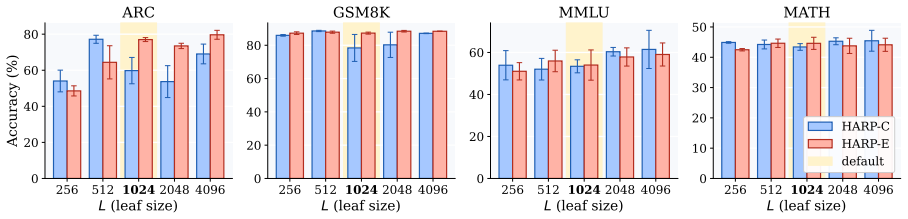
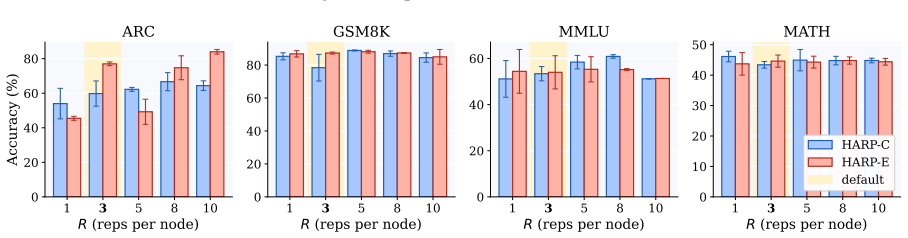
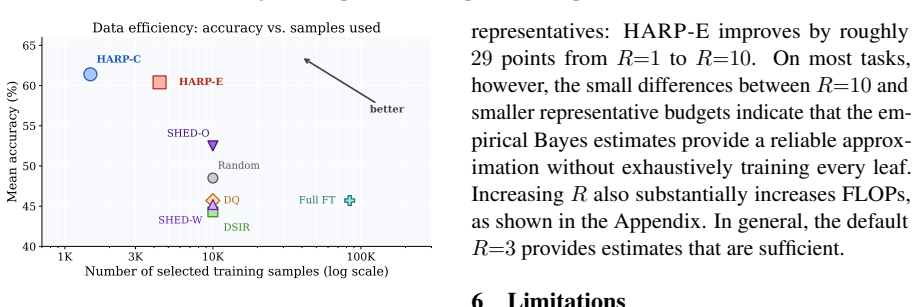
HARP organizes the training pool into a node-leaf hierarchy, evaluates only representative leaves, infers unmeasured utilities with empirical Bayes posteriors, and selects data using two complementary envelopes (HARP-C for conservative redundancy control and HARP-E for additive reward of complementary regions) to control selection error while reducing train-evaluate cost, thereby achieving the best downstream results with up to 8.9 point gains and roughly 7 times fewer training examples.
What carries the argument
The node-leaf data hierarchy together with empirical Bayes posterior inference over unmeasured leaves, which lets the method evaluate only a small fraction of the pool while still selecting on estimated downstream utility.
If this is right
- Selection error stays controlled when local smoothness and bounded estimation error hold.
- HARP-C limits redundancy while HARP-E rewards complementary regions.
- Downstream performance improves by as much as 8.9 points over the strongest baseline.
- The number of required train-evaluate iterations drops by a factor of roughly seven.
- The method preserves alignment with the target objective at lower cost than prior train-based selectors.
Where Pith is reading between the lines
- The same hierarchy-plus-inference pattern could be applied to data selection in domains outside language modeling, such as vision or reinforcement learning, where utility evaluation is also expensive.
- If the initial hierarchy is constructed from embeddings, the quality of those embeddings becomes an implicit factor in how well utilities can be inferred.
- A practitioner could tune the balance between the conservative and additive envelopes on a validation set to trade off safety against coverage for a given task.
- The approach suggests that hybrid selectors combining a cheap hierarchy with limited expensive measurements may scale better than either pure train-free or pure train-based methods.
Load-bearing premise
The downstream utility function must be locally smooth across the data hierarchy and the empirical Bayes estimation error must remain bounded.
What would settle it
An experiment in which the true utility function changes sharply between nearby points in the hierarchy, producing selection error larger than that of a simple baseline despite the reduced number of evaluations.
Figures
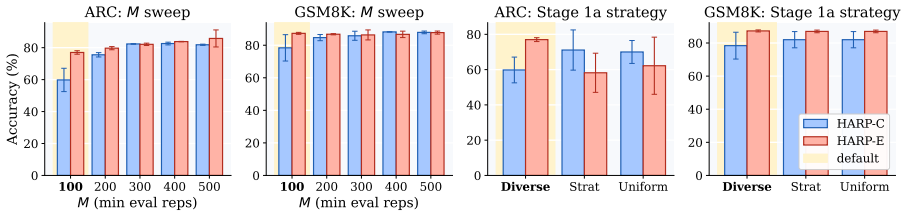
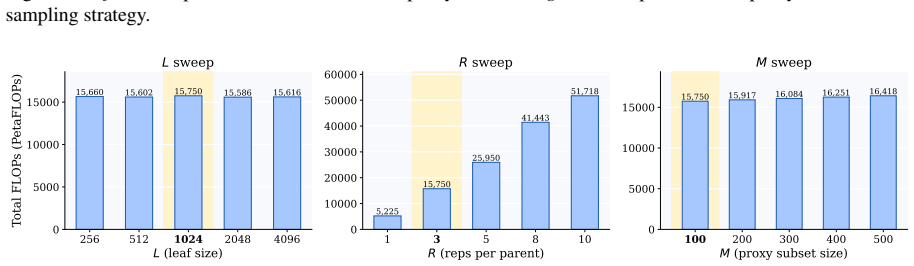
read the original abstract
Finetuning data selection requires balancing two competing goals: selecting examples that improve the downstream objective, and doing so without repeatedly finetuning models. Train-free selectors are scalable but rely on proxies such as embedding similarity or clustering, which may not match the target objective. Train-based selectors better reflect downstream utility through gradient signals, subset evaluation, or Shapley attribution, but require many costly train--evaluate iterations. We propose Hierarchical Active Region Pruning (HARP), an efficient train-based selector that preserves downstream alignment while reducing selection cost. HARP organizes the training pool into a node--leaf hierarchy, evaluates only representative leaves, and infers unmeasured utilities with empirical Bayes posteriors. It then selects data using two complementary envelopes: HARP-C, which conservatively controls redundancy, and HARP-E, which additively rewards complementary regions. We theoretically show that, under local smoothness and bounded estimation error, HARP controls selection error while reducing train--evaluate cost. We further validate that HARP variants achieve the best result and outperform the strongest baseline by up to $+8.9$ points, while using roughly $7\times$ fewer training examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Active Region Pruning (HARP) for efficient finetuning data selection in LLMs. It organizes the training pool into a node-leaf hierarchy, evaluates utilities only at representative leaves, infers the rest via empirical Bayes posteriors, and selects subsets using HARP-C (conservative redundancy control) and HARP-E (additive reward for complementary regions). Under assumptions of local smoothness of the utility function and bounded estimation error, it claims to control selection error while reducing train-evaluate iterations. Empirically, HARP variants are reported to achieve the best results, outperforming the strongest baseline by up to +8.9 points with roughly 7× fewer training examples.
Significance. If the theoretical guarantees hold under the stated assumptions and the empirical gains prove robust, HARP would provide a valuable middle ground between scalable but proxy-based train-free selectors and accurate but expensive train-based methods. The hierarchical structure combined with empirical Bayes inference for utility estimation represents a novel technical contribution that could reduce computational overhead in LLM adaptation pipelines. The manuscript is credited for pairing a theoretical error-control argument with reported empirical outperformance on downstream tasks.
major comments (2)
- [Abstract / theoretical analysis] Abstract / theoretical analysis: The error-control guarantee is stated to follow from local smoothness of the downstream utility across the node-leaf hierarchy together with bounded estimation error in the empirical Bayes posteriors. No verification, sensitivity analysis, or discussion is supplied on whether these assumptions are plausible for the non-convex utility landscapes typical of LLM finetuning, which directly undermines attribution of the reported gains to the proposed mechanism.
- [Abstract / experimental results] Abstract / experimental results: The central performance claim (outperformance by up to +8.9 points with 7× fewer examples) is presented without reference to the concrete baselines, downstream tasks, evaluation metrics, number of random seeds, or error bars. This absence prevents assessment of whether the gains are statistically reliable or attributable to the HARP envelopes rather than implementation details.
minor comments (1)
- [Abstract] Abstract: The phrase 'empirical Bayes posteriors' is used without a short inline definition or citation; a one-sentence clarification would improve accessibility for readers outside Bayesian statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract / theoretical analysis: The error-control guarantee is stated to follow from local smoothness of the downstream utility across the node-leaf hierarchy together with bounded estimation error in the empirical Bayes posteriors. No verification, sensitivity analysis, or discussion is supplied on whether these assumptions are plausible for the non-convex utility landscapes typical of LLM finetuning, which directly undermines attribution of the reported gains to the proposed mechanism.
Authors: We agree that the manuscript would be strengthened by explicit discussion of the assumptions. The theoretical result is derived under local smoothness of the utility function and bounded posterior estimation error; these are standard regularity conditions that enable the error-control argument. In the revision we will add a paragraph in Section 3 (Theoretical Analysis) that (i) states the assumptions more explicitly, (ii) discusses their plausibility for the non-convex loss landscapes encountered in LLM finetuning, and (iii) provides a brief qualitative argument, supported by the observed empirical behavior, that the local-smoothness regime is reasonable at the scale of the hierarchical regions we consider. We will also note that a full sensitivity study lies beyond the current scope but could be explored in follow-up work. revision: yes
-
Referee: [Abstract / experimental results] Abstract / experimental results: The central performance claim (outperformance by up to +8.9 points with 7× fewer examples) is presented without reference to the concrete baselines, downstream tasks, evaluation metrics, number of random seeds, or error bars. This absence prevents assessment of whether the gains are statistically reliable or attributable to the HARP envelopes rather than implementation details.
Authors: The abstract is deliberately concise; the full experimental protocol—including the concrete baselines (e.g., random, embedding-based, gradient-based selectors), downstream tasks (GLUE, SuperGLUE, and instruction-following benchmarks), metrics (accuracy/F1), number of random seeds (5), and error bars—is reported in Section 4 and the associated tables/figures. Nevertheless, we accept that the abstract would be more informative if it referenced the main experimental setting. In the revision we will expand the final sentence of the abstract to read: “On GLUE and instruction-tuning benchmarks, HARP variants outperform the strongest baseline by up to +8.9 points while using roughly 7× fewer training examples (5 random seeds, reported with standard error).” Full statistical details remain in the experimental section. revision: yes
Circularity Check
Derivation chain is self-contained; no reductions to inputs by construction
full rationale
The paper states a conditional theoretical guarantee: under the external assumptions of local smoothness of the utility function across the hierarchy and bounded estimation error in the empirical Bayes posteriors, HARP controls selection error. This is presented as a standard implication from stated assumptions rather than any quantity being fitted and then renamed as a prediction. Empirical performance results (+8.9 points, 7× fewer examples) are reported as separate experimental outcomes on benchmarks. No self-citations appear as load-bearing for uniqueness theorems, no ansatzes are smuggled via prior work, and no equations reduce the claimed control of selection error to a tautology or fitted input. The derivation remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Local smoothness of the utility function over the data hierarchy
- domain assumption Bounded estimation error for the empirical Bayes posteriors
Reference graph
Works this paper leans on
-
[1]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Influence Guided Context Selection for Effective Retrieval-Augmented Generation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
Lima: Less is more for alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Xia, Mengzhou and Malladi, Sadhika and Gururangan, Suchin and Arora, Sanjeev and Chen, Danqi , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[4]
Jingtan Wang and Xiaoqiang Lin and Rui Qiao and Pang Wei Koh and Chuan-Sheng Foo and Bryan Kian Hsiang Low , booktitle=
-
[5]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
He, Yexiao and Wang, Ziyao and Shen, Zheyu and Sun, Guoheng and Dai, Yucong and Wu, Yongkai and Wang, Hongyi and Li, Ang , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[6]
Ge, Yuan and Liu, Yilun and Hu, Chi and Meng, Weibin and Tao, Shimin and Zhao, Xiaofeng and Xia, Mahong and Li, Zhang and Chen, Boxing and Yang, Hao and Li, Bei and Xiao, Tong and Zhu, JingBo. Clustering and Ranking: Diversity-preserved Instruction Selection through Expert-aligned Quality Estimation. Proceedings of the 2024 Conference on Empirical Methods...
-
[7]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Liu, Zifan and Karbasi, Amin and Rekatsinas, Theodoros , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[8]
Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric
Yang, Yuming and Nan, Yang and Ye, Junjie and Dou, Shihan and Wang, Xiao and Li, Shuo and Lv, Huijie and Gui, Tao and Zhang, Qi and Huang, Xuanjing. Measuring Data Diversity for Instruction Tuning: A Systematic Analysis and A Reliable Metric. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2...
-
[9]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and Hajishirzi, Hannaneh. Self-Instruct: Aligning Language Models with Self-Generated Instructions. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.754
-
[10]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Zhou, Chunting and Liu, Pengfei and Xu, Puxin and Iyer, Srini and Sun, Jiao and Mao, Yuning and Ma, Xuezhe and Efrat, Avia and Yu, Ping and Yu, Lili and Zhang, Susan and Ghosh, Gargi and Lewis, Mike and Zettlemoyer, Luke and Levy, Omer , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 ...
2023
-
[11]
and Zoph, Barret and Wei, Jason and Roberts, Adam , title =
Longpre, Shayne and Hou, Le and Vu, Tu and Webson, Albert and Chung, Hyung Won and Tay, Yi and Zhou, Denny and Le, Quoc V. and Zoph, Barret and Wei, Jason and Roberts, Adam , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[12]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[13]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) , pages=
Data selection for fine-tuning large language models using transferred shapley values , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) , pages=
-
[14]
arXiv preprint arXiv:2311.08182 , year=
Self-evolved diverse data sampling for efficient instruction tuning , author=. arXiv preprint arXiv:2311.08182 , year=
-
[15]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Quantized side tuning: Fast and memory-efficient tuning of quantized large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Active instruction tuning: Improving cross-task generalization by training on prompt sensitive tasks , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[17]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
One-shot learning as instruction data prospector for large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
arXiv preprint arXiv:2309.05447 , year=
Tegit: Generating high-quality instruction-tuning data with text-grounded task design , author=. arXiv preprint arXiv:2309.05447 , year=
-
[20]
arXiv preprint arXiv:2307.06290 , year=
Instruction mining: Instruction data selection for tuning large language models , author=. arXiv preprint arXiv:2307.06290 , year=
-
[21]
arXiv preprint arXiv:2312.15685 , year=
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning , author=. arXiv preprint arXiv:2312.15685 , year=
-
[22]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Superfiltering: Weak-to-strong data filtering for fast instruction-tuning , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Data diversity matters for robust instruction tuning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[24]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[25]
International conference on machine learning , pages=
The flan collection: Designing data and methods for effective instruction tuning , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[26]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Longform: Effective instruction tuning with reverse instructions , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[27]
arXiv preprint arXiv:2304.03277 , year=
Instruction tuning with gpt-4 , author=. arXiv preprint arXiv:2304.03277 , year=
-
[28]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[29]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[30]
arXiv preprint arXiv:2303.16199 , year=
Llama-adapter: Efficient fine-tuning of language models with zero-init attention , author=. arXiv preprint arXiv:2303.16199 , year=
-
[31]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Baize: An open-source chat model with parameter-efficient tuning on self-chat data , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[32]
International Conference on Learning Representations , volume=
Alpagasus: Training a better alpaca with fewer data , author=. International Conference on Learning Representations , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Alpacafarm: A simulation framework for methods that learn from human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[35]
arXiv preprint arXiv:2310.01377 , year=
Ultrafeedback: Boosting language models with scaled ai feedback , author=. arXiv preprint arXiv:2310.01377 , year=
-
[36]
arXiv preprint arXiv:2309.05653 , year=
Mammoth: Building math generalist models through hybrid instruction tuning , author=. arXiv preprint arXiv:2309.05653 , year=
-
[37]
arXiv preprint arXiv:2309.12284 , year=
Metamath: Bootstrap your own mathematical questions for large language models , author=. arXiv preprint arXiv:2309.12284 , year=
-
[38]
arXiv preprint arXiv:2308.09583 , year=
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct , author=. arXiv preprint arXiv:2308.09583 , year=
-
[39]
2023 , publisher=
Stanford alpaca: An instruction-following llama model , author=. 2023 , publisher=
2023
-
[40]
Advances in Neural Information Processing Systems , volume=
Data selection for language models via importance resampling , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Dataset quantization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[42]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[43]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[44]
arXiv preprint arXiv:2411.15124 , year=
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
-
[45]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[46]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[47]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[48]
ArXiv , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. ArXiv , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.