Adversarial Robustness of Activation Steering in Large Language Models
Pith reviewed 2026-06-27 22:28 UTC · model grok-4.3
The pith
Adversarial text perturbations reduce activation steering directional robustness by up to 64% in LLMs and shift optimal layers by up to 17 positions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
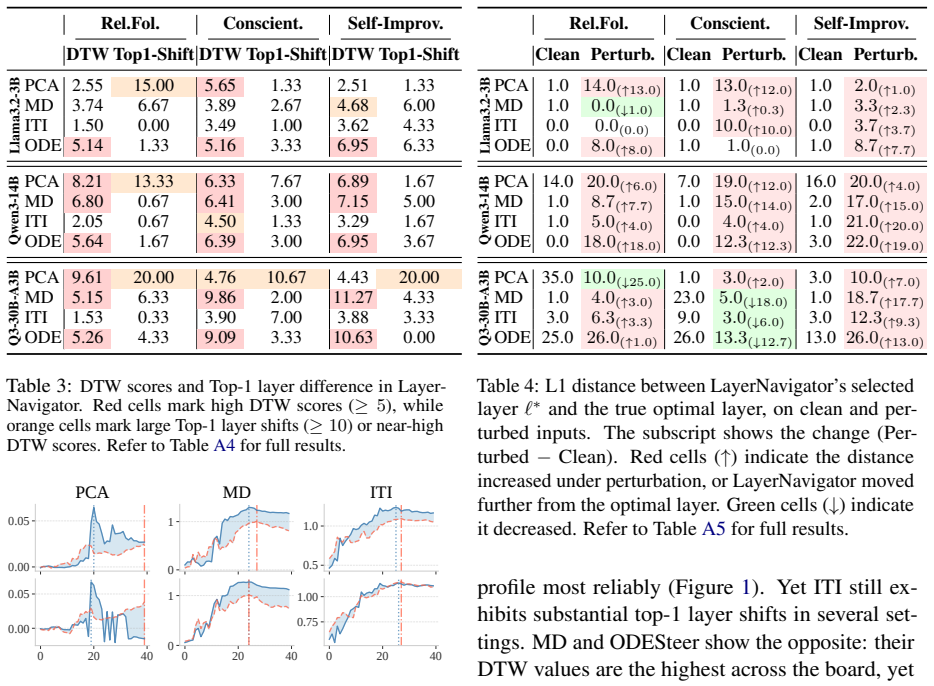
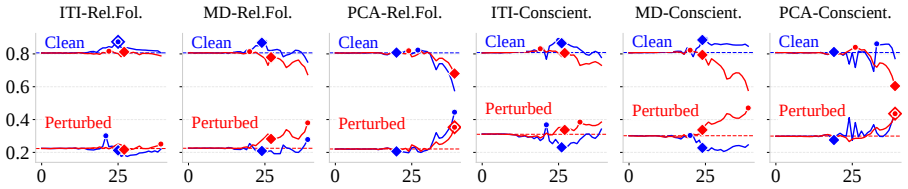
Activation steering lacks robustness to adversarial perturbations on inputs. Directional robustness drops by up to 64 percent, post-attack confidence collapses near or below 0.25 across all methods and models, steering strength degrades on nearly every steerable input, and the optimal layer identified on clean data shifts by up to 17 positions under perturbation. Extracting vectors from perturbed inputs recovers some steerability for PCA and MD on mid-to-large models, yet still fails to locate the improved optimal layer.
What carries the argument
The evaluation of directional robustness, post-attack confidence, steering strength, and automated layer selection under three attack strategies applied to inputs from the Anthropic Model-Written Evaluation Dataset.
If this is right
- Activation steering cannot be deployed reliably on real inputs without additional robustness measures.
- Layer-selection procedures calibrated on clean data fail when inputs are perturbed.
- Extracting vectors from adversarially perturbed inputs recovers partial steerability for PCA and MD on larger models but does not fix layer selection.
- The observed brittleness applies across extraction methods, attack strategies, personas, and model sizes, indicating a general limitation.
Where Pith is reading between the lines
- Developers may need to combine activation steering with input sanitization or adversarial training to achieve usable reliability.
- The same input-sensitivity pattern could affect other inference-time control techniques that rely on fixed internal directions.
- Future extraction procedures might benefit from explicitly optimizing for stability across small input changes rather than clean-data performance alone.
Load-bearing premise
The chosen adversarial perturbations, extraction methods, and six personas from the Anthropic Model-Written Evaluation Dataset are representative of realistic input variation encountered in deployment.
What would settle it
A controlled experiment that applies the same three attack strategies yet finds directional robustness remains above 90 percent and optimal-layer shifts stay within two positions for all tested models and methods.
Figures
read the original abstract
Activation steering has become a popular training-free method to control LLM behavior by injecting precomputed direction vectors into the model's residual stream at inference time. Yet its robustness to realistic input variation remains unstudied. We present the first systematic evaluation of activation steering robustness under adversarial text perturbations on the inputs, covering four extraction methods, three attack strategies, six personas from Anthropic Model-Written Evaluation Dataset, and five models ranging from 1.5B to 30B parameters. Attacks succeed broadly across all settings: directional robustness drops by up to 64%, post-attack confidence collapses near or below 0.25 across all methods and models, and steering strength degrades on nearly every steerable input. Layer selection is equally fragile, with the optimal layer identified by an automated method on clean inputs shifting by up to 17 positions under perturbation, a failure that compounds the vector-level breakdown. Extracting vectors from adversarially perturbed inputs partially recovers steerability for PCA and MD on mid-to-large models, but they consistently fail to locate the improved optimal layer, limiting the practical benefit of this mitigation. Together, these findings reveal that the brittleness of activation steering is structural rather than method-specific, and that current layer selection strategies are not robust enough for real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that activation steering in LLMs is brittle under adversarial text perturbations on inputs. Through a systematic evaluation covering four extraction methods, three attack strategies, six personas from the Anthropic Model-Written Evaluation Dataset, and five models (1.5B to 30B parameters), it reports that attacks cause directional robustness drops of up to 64%, post-attack confidence to collapse near or below 0.25, steering strength degradation on nearly all inputs, and optimal layer shifts of up to 17 positions. Extracting vectors from perturbed inputs partially recovers steerability for some methods on larger models but fails to identify improved layers. The paper concludes that the brittleness is structural rather than method-specific and that current layer selection strategies are not robust enough for real-world deployment.
Significance. If the experimental regime is representative of deployment conditions, the work would be significant for identifying a key practical limitation of activation steering, a widely used training-free control technique. The breadth of the evaluation across methods, attacks, personas, and model scales provides a useful empirical baseline that could inform more robust steering approaches. The finding that layer selection is also fragile adds a practical dimension beyond vector-level issues.
major comments (1)
- [Abstract] Abstract: The central claim that 'the brittleness of activation steering is structural rather than method-specific' and that 'current layer selection strategies are not robust enough for real-world deployment' rests on the unverified assumption that the three attack strategies, four extraction methods, and six personas produce input variations representative of realistic deployment. No comparison to held-out user logs, alternative perturbation distributions, or other datasets is described to support generalizing from this specific experimental regime to the broader conclusion.
Simulated Author's Rebuttal
We thank the referee for highlighting the scope of our generalization claims. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the brittleness of activation steering is structural rather than method-specific' and that 'current layer selection strategies are not robust enough for real-world deployment' rests on the unverified assumption that the three attack strategies, four extraction methods, and six personas produce input variations representative of realistic deployment. No comparison to held-out user logs, alternative perturbation distributions, or other datasets is described to support generalizing from this specific experimental regime to the broader conclusion.
Authors: We acknowledge that the manuscript does not include comparisons against held-out user logs, alternative perturbation distributions, or additional datasets beyond the Anthropic Model-Written Evaluation Dataset. Such external validation would require access to proprietary deployment data that is not available in this study. The chosen experimental regime draws on a standard public persona dataset and established adversarial attack strategies from the NLP literature precisely to probe robustness under controlled but diverse input variations. The structural claim is supported by the observed consistency of directional robustness drops, confidence collapse, and layer shifts across all four extraction methods, three attacks, six personas, and five model scales. Nevertheless, the referee is correct that the phrasing in the abstract regarding real-world deployment extrapolates beyond the tested regime. We will therefore revise the abstract to qualify the scope of the conclusions and add an explicit limitations paragraph discussing the chosen datasets and attacks. This is a partial revision. revision: partial
Circularity Check
No significant circularity; purely empirical evaluation
full rationale
The paper conducts a direct empirical measurement campaign evaluating activation steering robustness under adversarial text perturbations, using external datasets (Anthropic Model-Written Evaluation Dataset), attack strategies, extraction methods, and models. No derivation chain, equations, fitted parameters presented as predictions, uniqueness theorems, or self-citations are described or invoked to support the central claims. All reported results (directional robustness drops, confidence collapse, layer shifts) are measurements against chosen experimental conditions rather than reductions to inputs by construction. This matches the default expectation of no circularity for empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversarial text perturbations generated by the three attack strategies constitute realistic input variation for steering evaluation.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Analysing the generalisation and reliability of steering vectors , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[2]
arXiv preprint arXiv:2601.03093 , year=
ATLAS: Adaptive Test-Time Latent Steering with External Verifiers for Enhancing LLMs Reasoning , author=. arXiv preprint arXiv:2601.03093 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Layernavigator: Finding promising intervention layers for efficient activation steering in large language models , author=. Advances in Neural Information Processing Systems , volume=. 2025 , url=
2025
-
[4]
Proceedings of the AAAI conference on artificial intelligence , volume=
Is bert really robust? a strong baseline for natural language attack on text classification and entailment , author=. Proceedings of the AAAI conference on artificial intelligence , volume=. 2020 , url=
2020
-
[5]
arXiv preprint arXiv:2308.10248 , year=
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
-
[6]
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[7]
Advances in Neural Information Processing Systems , volume=
Leace: Perfect linear concept erasure in closed form , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[8]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Liu, Sheng and Ye, Haotian and Xing, Lei and Zou, James , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[9]
International conference on learning representations , volume=
Function vectors in large language models , author=. International conference on learning representations , volume=. 2024 , url=
2024
-
[10]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[11]
arXiv preprint arXiv:2310.01405 , year=
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
-
[12]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[13]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[14]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[15]
arXiv preprint arXiv:2212.03827 , year=
Discovering latent knowledge in language models without supervision , author=. arXiv preprint arXiv:2212.03827 , year=
-
[16]
E xtracting L atent S teering V ectors from P retrained L anguage M odels
Subramani, Nishant and Suresh, Nivedita and Peters, Matthew. Extracting Latent Steering Vectors from Pretrained Language Models. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.48
-
[17]
Advances in Neural Information Processing Systems , volume=
Personalized steering of large language models: Versatile steering vectors through bi-directional preference optimization , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[18]
Causal Learning and Reasoning , pages=
Finding alignments between interpretable causal variables and distributed neural representations , author=. Causal Learning and Reasoning , pages=. 2024 , organization=
2024
-
[19]
Advances in Neural Information Processing Systems , volume=
Reft: Representation finetuning for language models , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[20]
arXiv preprint arXiv:2507.21509 , year=
Persona vectors: Monitoring and controlling character traits in language models , author=. arXiv preprint arXiv:2507.21509 , year=
-
[21]
arXiv preprint arXiv:2412.10427 , year=
Identifying and manipulating personality traits in LLMs through activation engineering , author=. arXiv preprint arXiv:2412.10427 , year=
-
[22]
Shifting Perspectives: Steering Vectors for Robust Bias Mitigation in LLM s
Siddique, Zara and Khalid, Irtaza and Turner, Liam and Espinosa-Anke, Luis. Shifting Perspectives: Steering Vectors for Robust Bias Mitigation in LLM s. Findings of the A ssociation for C omputational L inguistics: EACL 2026. 2026. doi:10.18653/v1/2026.findings-eacl.41
-
[23]
S afe S witch: Steering Unsafe LLM Behavior via Internal Activation Signals
Han, Peixuan and Qian, Cheng and Chen, Xiusi and Zhang, Yuji and Ji, Heng and Zhang, Denghui. S afe S witch: Steering Unsafe LLM Behavior via Internal Activation Signals. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.366
-
[24]
arXiv preprint arXiv:2403.18680 , year=
Non-linear inference time intervention: Improving llm truthfulness , author=. arXiv preprint arXiv:2403.18680 , year=
-
[25]
The Fourth Blogpost Track at ICLR 2025 , year=
Steering LLMs' Behavior with Concept Activation Vectors , author=. The Fourth Blogpost Track at ICLR 2025 , year=
2025
-
[26]
arXiv preprint arXiv:2502.18862 , year=
One-shot optimized steering vectors mediate safety-relevant behaviors in LLMs , author=. arXiv preprint arXiv:2502.18862 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Angular steering: Behavior control via rotation in activation space , author=. Advances in Neural Information Processing Systems , volume=. 2026 , url=
2026
-
[28]
arXiv preprint arXiv:2510.04309 , year=
Activation Steering with a Feedback Controller , author=. arXiv preprint arXiv:2510.04309 , year=
-
[29]
arXiv preprint arXiv:2505.22637 , year=
Understanding (un) reliability of steering vectors in language models , author=. arXiv preprint arXiv:2505.22637 , year=
-
[30]
Wang, Xintong and Pan, Jingheng and Ding, Liang and Wang, Longyue and Jiang, Longqin and Li, Xingshan and Biemann, Chris. C og S teer: Cognition-Inspired Selective Layer Intervention for Efficiently Steering Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1308
-
[31]
arXiv preprint arXiv:2502.17420 , year=
The geometry of refusal in large language models: Concept cones and representational independence , author=. arXiv preprint arXiv:2502.17420 , year=
-
[32]
arXiv preprint arXiv:2410.17245 , year=
Towards reliable evaluation of behavior steering interventions in LLMs , author=. arXiv preprint arXiv:2410.17245 , year=
-
[33]
International Conference on Learning Representations , volume=
Semantics-adaptive activation intervention for llms via dynamic steering vectors , author=. International Conference on Learning Representations , volume=. 2025 , url=
2025
-
[34]
International conference on learning representations , volume=
Programming refusal with conditional activation steering , author=. International conference on learning representations , volume=. 2025 , url=
2025
-
[35]
Multi-property Steering of Large Language Models with Dynamic Activation Composition
Scalena, Daniel and Sarti, Gabriele and Nissim, Malvina. Multi-property Steering of Large Language Models with Dynamic Activation Composition. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.34
-
[36]
Proceedings of the ACM on Web Conference 2025 , pages=
Adaptive activation steering: A tuning-free llm truthfulness improvement method for diverse hallucinations categories , author=. Proceedings of the ACM on Web Conference 2025 , pages=. 2025 , url=
2025
-
[37]
arXiv preprint arXiv:2604.03867 , year=
Where to Steer: Input-Dependent Layer Selection for Steering Improves LLM Alignment , author=. arXiv preprint arXiv:2604.03867 , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Learning to steer: Input-dependent steering for multimodal llms , author=. Advances in Neural Information Processing Systems , volume=. 2026 , url=
2026
-
[39]
arXiv preprint arXiv:2603.12298 , year=
Global Evolutionary Steering: Refining Activation Steering Control via Cross-Layer Consistency , author=. arXiv preprint arXiv:2603.12298 , year=
-
[40]
arXiv preprint arXiv:2601.19375 , year=
Selective Steering: Norm-Preserving Control Through Discriminative Layer Selection , author=. arXiv preprint arXiv:2601.19375 , year=
-
[41]
Activation-Space Personality Steering: Hybrid Layer Selection for Stable Trait Control in LLM s
Bhandari, Pranav and Fay, Nicolas and Selvaganapathy, Sanjeevan and Datta, Amitava and Naseem, Usman and Nasim, Mehwish. Activation-Space Personality Steering: Hybrid Layer Selection for Stable Trait Control in LLM s. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 20...
-
[42]
BERT - ATTACK : Adversarial Attack Against BERT Using BERT
Li, Linyang and Ma, Ruotian and Guo, Qipeng and Xue, Xiangyang and Qiu, Xipeng. BERT - ATTACK : Adversarial Attack Against BERT Using BERT. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.500
-
[43]
arXiv preprint arXiv:1812.05271 , year=
Textbugger: Generating adversarial text against real-world applications , author=. arXiv preprint arXiv:1812.05271 , year=
-
[44]
Morris, John and Lifland, Eli and Yoo, Jin Yong and Grigsby, Jake and Jin, Di and Qi, Yanjun. T ext A ttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. doi:10.18653/v1/2020.emnlp-demos.16
-
[45]
arXiv preprint arXiv:2502.02716 , year=
A unified understanding and evaluation of steering methods , author=. arXiv preprint arXiv:2502.02716 , year=
-
[46]
Findings of the Association for Computational Linguistics: ACL 2023 , year =
Perez, Ethan and Ringer, Sam and Lukosiute, Kamile and Nguyen, Karina and Chen, Edwin and Heiner, Scott and Pettit, Craig and Olsson, Catherine and Kundu, Sandipan and Kadavath, Saurav and Jones, Andy and Chen, Anna and Mann, Benjamin and Israel, Brian and Seethor, Bryan and McKinnon, Cameron and Olah, Christopher and Yan, Da and Amodei, Daniela and Amode...
-
[47]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=. 2022 , url =
2022
-
[48]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[49]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[50]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[51]
Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=
Gpt-4 passes the bar exam , author=. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2024 , publisher=
2024
-
[52]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[53]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=. 2024 , url=
2024
-
[54]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[55]
Webber, William and Moffat, Alistair and Zobel, Justin , title =. ACM Trans. Inf. Syst. , month = nov, articleno =. 2010 , issue_date =. doi:10.1145/1852102.1852106 , abstract =
-
[56]
arXiv preprint arXiv:2605.03907 , year=
Steer Like the LLM: Activation Steering that Mimics Prompting , author=. arXiv preprint arXiv:2605.03907 , year=
-
[57]
arXiv preprint arXiv:2602.17560 , year=
Odesteer: A unified ode-based steering framework for llm alignment , author=. arXiv preprint arXiv:2602.17560 , year=
-
[58]
Cer, Daniel and Yang, Yinfei and Kong, Sheng-yi and Hua, Nan and Limtiaco, Nicole and St. John, Rhomni and Constant, Noah and Guajardo-Cespedes, Mario and Yuan, Steve and Tar, Chris and Strope, Brian and Kurzweil, Ray. Universal Sentence Encoder for E nglish. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System De...
-
[59]
and Su, Pei-Hao and Vandyke, David and Wen, Tsung-Hsien and Young, Steve
Mrk s i \'c , Nikola and \'O S \'e aghdha, Diarmuid and Thomson, Blaise and Ga s i \'c , Milica and Rojas-Barahona, Lina M. and Su, Pei-Hao and Vandyke, David and Wen, Tsung-Hsien and Young, Steve. Counter-fitting Word Vectors to Linguistic Constraints. Proceedings of the 2016 Conference of the North A merican Chapter of the Association for Computational ...
-
[60]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[61]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[62]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[63]
arXiv preprint arXiv:1412.6572 , year=
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
-
[64]
arXiv preprint arXiv:1706.06083 , year=
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
-
[65]
arXiv preprint arXiv:2511.01689 , year=
Open character training: Shaping the persona of AI assistants through constitutional AI , author=. arXiv preprint arXiv:2511.01689 , year=
-
[66]
Transformer Circuits Thread , year=
Lindsey, Jack , title=. Transformer Circuits Thread , year=
-
[67]
arXiv preprint arXiv:2510.14318 , year=
Evaluating & Reducing Deceptive Dialogue From Language Models with Multi-turn RL , author=. arXiv preprint arXiv:2510.14318 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.