Cross-View Urban Traffic Dataset: Drone-Supervised Ground Truth for Monocular Bird's-Eye View Localization
Pith reviewed 2026-06-27 22:11 UTC · model grok-4.3
The pith
A dataset from synchronized bicycle and drone videos supplies identity-level alignment for cross-view urban traffic benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
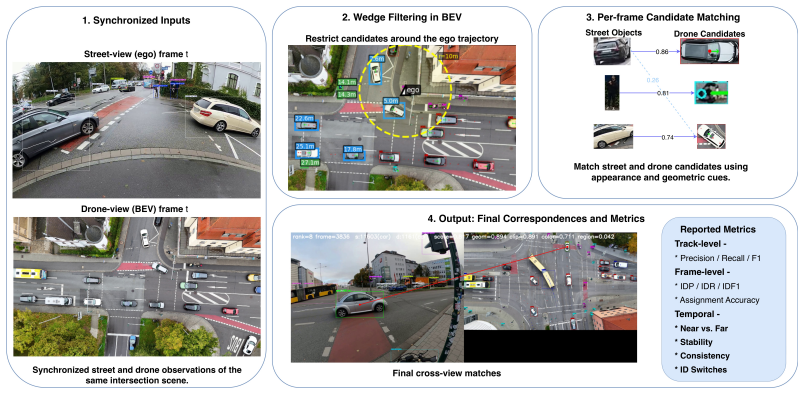
We introduce a dataset and benchmark for cross-view urban traffic perception built from synchronized ego-centric bicycle videos and aerial drone videos recorded at real urban intersections. The benchmark targets two linked tasks: cross-view identity matching between street-view and drone-view object tracks, and ego-to-bird's-eye-view prediction using aerial supervision. In contrast to prior urban driving and V2X datasets, our benchmark provides identity-level alignment across radically different viewpoints together with standardized evaluation, annotation tooling, and baseline implementations.
What carries the argument
Synchronized ego-centric bicycle videos and aerial drone videos that deliver identity-level alignment across viewpoints, together with the two benchmark tasks and their track- and frame-level metrics.
If this is right
- Cross-view matching achieves strong recall but is limited by over-assignment and temporal inconsistency.
- Ego-to-BEV prediction benefits from aerial supervision but remains far from saturated under lightweight monocular sensing.
- The benchmark supports future research on cross-view perception, urban scene alignment, and ego-to-global traffic understanding.
- Evaluation at both track and frame levels includes cross-view ID precision/recall/IDF1, near-far breakdowns, and consistency metrics.
Where Pith is reading between the lines
- The same synchronized pairs could be used to test whether temporal consistency improves when matching incorporates short-term motion models.
- Lightweight monocular BEV models trained on this data might serve as a starting point for testing whether adding a second camera view closes the remaining performance gap.
- The identity-aligned tracks could enable direct measurement of how well local interaction models transfer from one viewpoint to another.
- Releasing the annotation tooling alongside the data allows other groups to extend the benchmark to additional intersections or sensor types without rebuilding the alignment pipeline.
Load-bearing premise
The synchronized ego-centric bicycle videos and aerial drone videos provide accurate identity-level alignment across radically different viewpoints without significant synchronization or annotation errors.
What would settle it
Finding substantial misalignment or annotation errors when re-examining the identity labels between the bicycle and drone tracks would falsify the benchmark's core reliability.
Figures

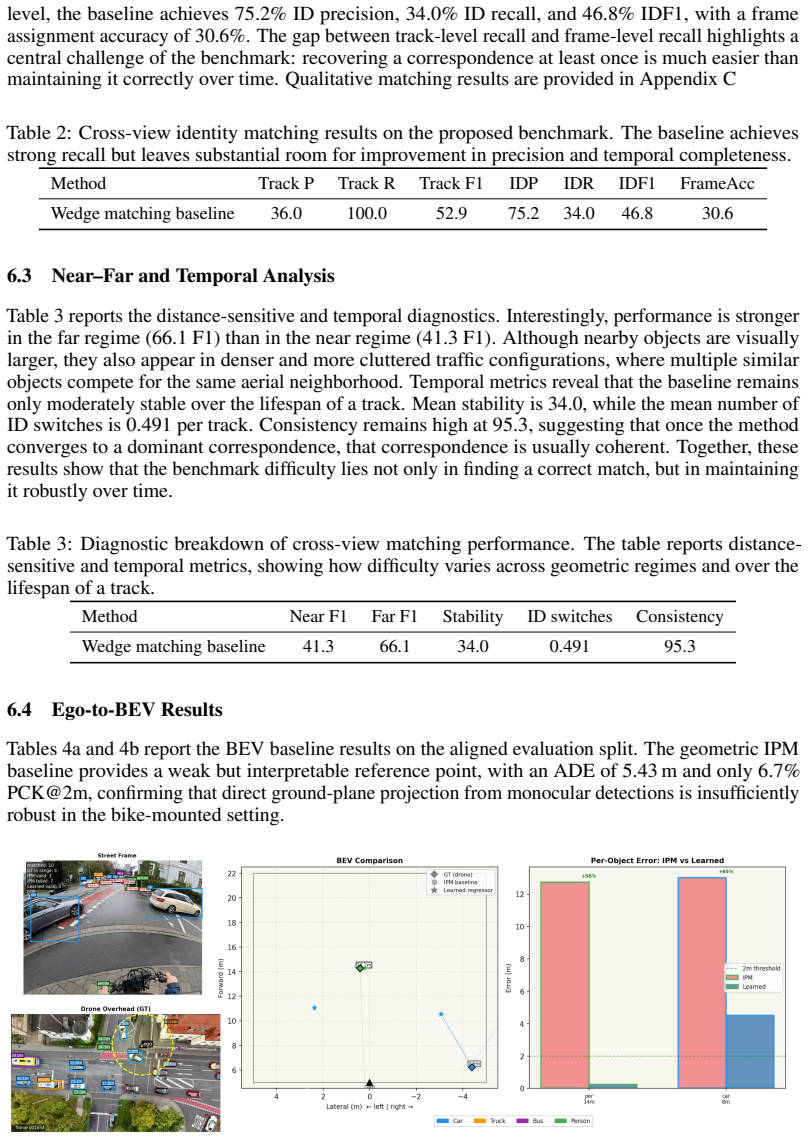
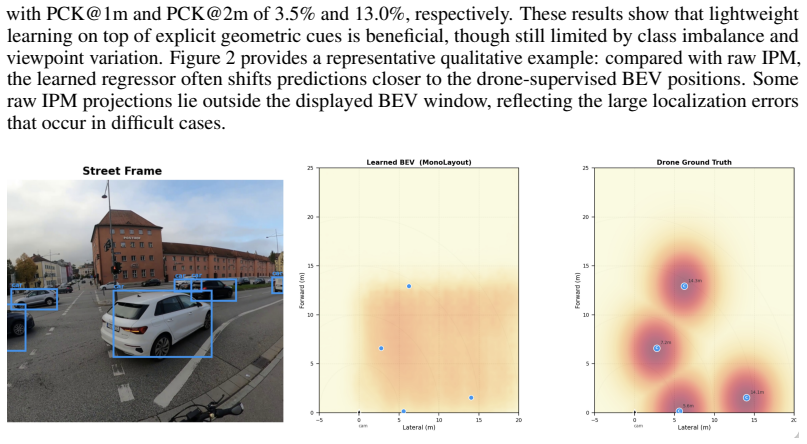

read the original abstract
We introduce a dataset and benchmark for cross-view urban traffic perception built from synchronized ego-centric bicycle videos and aerial drone videos recorded at real urban intersections. The benchmark targets two linked tasks: cross-view identity matching between street-view and drone-view object tracks, and ego-to-bird's-eye-view prediction using aerial supervision. In contrast to prior urban driving and V2X datasets, our benchmark provides identity-level alignment across radically different viewpoints together with standardized evaluation, annotation tooling, and baseline implementations. This setting is motivated by intersection-centric traffic analysis, where identity preservation, local interactions, and global spatial structure must be reasoned about jointly across views. We evaluate methods at both the track and frame levels, including cross-view ID precision/recall/IDF1, near--far breakdowns, temporal stability, and consistency metrics. We also provide baseline results for wedge-based cross-view matching and for three BEV prediction baselines: inverse perspective mapping, a MonoLayout-style learned baseline, and a regression baseline. The results show that the benchmark is feasible but challenging: cross-view matching achieves strong recall yet remains limited by over-assignment and temporal inconsistency, while ego-to-BEV prediction benefits from aerial supervision but remains far from saturated under lightweight monocular sensing. We hope that this benchmark will support future research on cross-view perception, urban scene alignment, and ego-to-global traffic understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cross-View Urban Traffic Dataset constructed from synchronized ego-centric bicycle videos and aerial drone videos recorded at real urban intersections. It defines two linked benchmark tasks—cross-view identity matching between street-view and drone-view object tracks, and ego-to-BEV prediction using aerial supervision—along with standardized evaluation metrics (track- and frame-level ID precision/recall/IDF1, near-far breakdowns, temporal stability, consistency), annotation tooling, and baseline implementations (wedge-based matching; IPM, MonoLayout-style, and regression BEV predictors). The reported results indicate that cross-view matching achieves strong recall but is limited by over-assignment and temporal inconsistency, while ego-to-BEV prediction benefits from aerial supervision yet remains far from saturated under lightweight monocular sensing.
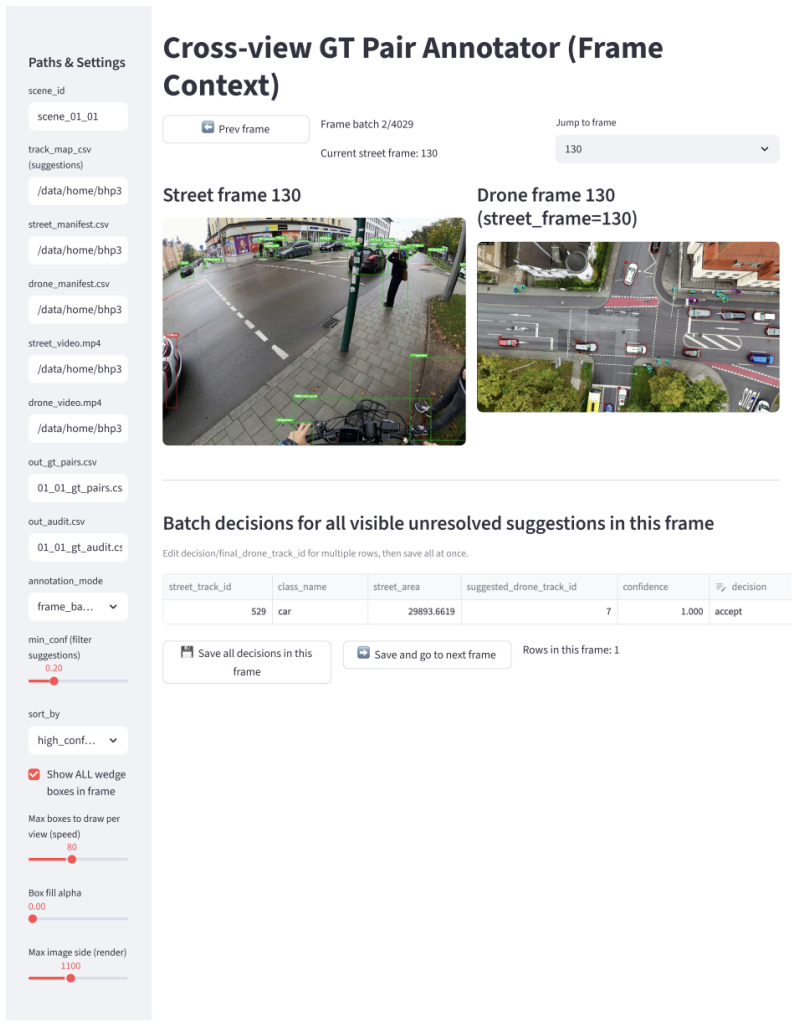
Significance. If the identity-level alignments are accurate, the dataset supplies a valuable new resource for intersection-centric traffic analysis by enabling joint reasoning over identity preservation, local interactions, and global spatial structure across radically different viewpoints. The explicit provision of standardized evaluation protocols, tooling, and baseline code is a concrete strength that supports reproducible follow-on research in cross-view perception and urban scene alignment.
major comments (2)
- [Dataset construction (abstract and §3)] Dataset construction (abstract and §3): the manuscript asserts synchronized ego/drone videos with identity-level alignment but supplies no quantitative verification of synchronization error, frame-offset statistics, annotation protocol, or inter-annotator agreement. Because every reported metric (IDF1, temporal consistency, near-far recall) is computed against these correspondences, the absence of such verification makes the central claim that the benchmark is “feasible but challenging” impossible to assess.
- [Evaluation protocol (§5)] Evaluation protocol (§5): the cross-view matching baselines are reported to suffer from over-assignment and temporal inconsistency, yet without an independent check on ground-truth identity accuracy it is impossible to determine whether these limitations are properties of the methods or artifacts of annotation noise.
minor comments (1)
- [Abstract] The abstract refers to “near--far breakdowns” and “consistency metrics” without a forward reference to the exact definitions or table/figure that presents them; adding a brief pointer would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, agreeing that additional verification is needed to support the benchmark claims.
read point-by-point responses
-
Referee: [Dataset construction (abstract and §3)] Dataset construction (abstract and §3): the manuscript asserts synchronized ego/drone videos with identity-level alignment but supplies no quantitative verification of synchronization error, frame-offset statistics, annotation protocol, or inter-annotator agreement. Because every reported metric (IDF1, temporal consistency, near-far recall) is computed against these correspondences, the absence of such verification makes the central claim that the benchmark is “feasible but challenging” impossible to assess.
Authors: We agree that the current manuscript lacks the requested quantitative details on synchronization and annotation quality. In the revision we will add a dedicated subsection in §3 reporting measured frame-offset statistics across the synchronized sequences, the exact annotation protocol for establishing identity-level correspondences, and inter-annotator agreement figures (e.g., Cohen’s kappa on a sampled subset). These additions will directly support the feasibility claim. revision: yes
-
Referee: [Evaluation protocol (§5)] Evaluation protocol (§5): the cross-view matching baselines are reported to suffer from over-assignment and temporal inconsistency, yet without an independent check on ground-truth identity accuracy it is impossible to determine whether these limitations are properties of the methods or artifacts of annotation noise.
Authors: We concur that an independent check on ground-truth identity accuracy is necessary to isolate method limitations from potential annotation noise. The revised §5 will include a new validation experiment (e.g., additional manual re-annotation of a held-out subset and consistency analysis across annotators) to quantify ground-truth reliability and confirm that the observed over-assignment and temporal issues are primarily attributable to the evaluated methods. revision: yes
Circularity Check
No circularity: dataset paper with no derivations or predictions
full rationale
This paper introduces a dataset of synchronized ego-centric bicycle videos and aerial drone videos for cross-view identity matching and ego-to-BEV prediction tasks. It contains no equations, fitted parameters, first-principles derivations, or statistical predictions that could reduce to inputs by construction. The contribution is the data collection, annotation protocol, and baseline evaluations; all reported metrics (recall, IDF1, etc.) are direct measurements on the provided data rather than outputs of any model that was tuned to the same data in a self-referential loop. No self-citation chains or ansatzes are load-bearing for any claimed result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[2]
Argoverse: 3d tracking and forecasting with rich maps
Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, and James Hays. Argoverse: 3d tracking and forecasting with rich maps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[3]
Changhe Chen, Mozhgan Pourkeshavarz, and Amir Rasouli. Criteria: A new benchmarking paradigm for evaluating trajectory prediction models for autonomous driving.arXiv preprint arXiv:2310.07794, 2023
-
[4]
Motchallenge: A benchmark for single-camera multiple target tracking.International Journal of Computer Vision, 129(4):845–881, 2021
Patrick Dendorfer, Aljoša Ošep, Anton Milan, Konrad Schindler, Daniel Cremers, Ian Reid, Stefan Roth, and Laura Leal-Taixé. Motchallenge: A benchmark for single-camera multiple target tracking.International Journal of Computer Vision, 129(4):845–881, 2021
2021
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009
2009
-
[6]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[7]
Deep learning based 3d segmentation: A survey.arXiv preprint arXiv:2103.05423, 2021
Yong He, Hongshan Yu, Xiaoyan Liu, Zhengeng Yang, Wei Sun, Yaonan Wang, Qiang Fu, Yanmei Zou, and Ajmal Mian. Deep learning based 3d segmentation: A survey.arXiv preprint arXiv:2103.05423, 2021
-
[8]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view.arXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Bev- former: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers
Zhiqi Li, Wenhai Wang, Hongyang Li, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bev- former: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[10]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision – ECCV 2014, pages 740–755. Springer, 2014
2014
-
[11]
Benchmarking fish dataset and evaluation metric in keypoint detection: Towards precise fish morphological assessment in aquaculture breeding
Weizhen Liu, Jiayu Tan, Guangyu Lan, Ao Li, Dongye Li, Le Zhao, Xiaohui Yuan, and Nanqing Dong. Benchmarking fish dataset and evaluation metric in keypoint detection: Towards precise fish morphological assessment in aquaculture breeding. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), pages 7376–7384, 2024
2024
-
[12]
Vision-centric bev perception: A survey
Yuexin Ma, Tai Wang, Xuyang Bai, Huitong Yang, Yuenan Hou, Yaming Wang, Yu Qiao, Ruigang Yang, Dinesh Manocha, and Xinge Zhu. Vision-centric bev perception: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 10
2024
-
[13]
Mallot, Heinrich H
Hanspeter A. Mallot, Heinrich H. Bülthoff, James J. Little, and Stefan Bohrer. Inverse per- spective mapping simplified: A monocular road image to bird’s-eye view transformation that maximizes information in the processed image.Biological Cybernetics, 66(1):75–86, 1991
1991
-
[14]
Karttikeya Mangalam, Harsh Girase, et al. What to predict? vehicle trajectory prediction using off-road motion patterns.arXiv preprint arXiv:2203.03057, 2022
-
[15]
Sai Shankar, Krishna Murthy Jatavallab- hula, and K
Kaustubh Mani, Swapnil Daga, Shubhika Garg, N. Sai Shankar, Krishna Murthy Jatavallab- hula, and K. Madhava Krishna. Monolayout: Amodal scene layout from a single image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2020
2020
-
[16]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[17]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the International Conference on Machine Learning (ICML), 2021
2021
-
[18]
Features for Multi-Target Multi-Camera Tracking and Re-Identification
Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Perfor- mance measures and a data set for multi-target, multi-camera tracking.arXiv preprint arXiv:1803.10859, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Karthikeyan Chandra Sekaran, Markus Geisler, Dominik Rößle, Adithya Mohan, Daniel Cre- mers, Wolfgang Utschick, Michael Botsch, Werner Huber, and Torsten Schön. Urbaning-v2x: A large-scale multi-vehicle, multi-infrastructure dataset across multiple intersections for cooper- ative perception.arXiv preprint arXiv:2510.23478, 2025
-
[20]
Yiming Sun, Bing Cao, Pengfei Zhu, and Qinghua Hu. Drone-based rgb-infrared cross-modality vehicle detection via uncertainty-aware learning.arXiv preprint arXiv:2003.02437, 2020
-
[21]
Viewpoint and scale consistency reinforcement for uav vehicle re-identification.International Journal of Computer Vision, 129(3):719–735, 2021
Shangzhi Teng, Shiliang Zhang, Qingming Huang, and Nicu Sebe. Viewpoint and scale consistency reinforcement for uav vehicle re-identification.International Journal of Computer Vision, 129(3):719–735, 2021
2021
-
[22]
Wide-area image geolocalization with aerial reference imagery
Scott Workman, Richard Souvenir, and Nathan Jacobs. Wide-area image geolocalization with aerial reference imagery. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2015
2015
-
[23]
Articulated pose estimation with flexible mixtures-of-parts
Yi Yang and Deva Ramanan. Articulated pose estimation with flexible mixtures-of-parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011
2011
-
[24]
Marius Zöllner
Melih Yazgan, Mythra Varun Akkanapragada, and J. Marius Zöllner. Collaborative perception datasets in autonomous driving: A survey. In2024 IEEE Intelligent Vehicles Symposium (IV), pages 2269–2276, 2024
2024
-
[25]
V2x-seq: A large-scale sequential dataset for vehicle-infrastructure cooperative perception and forecasting
Haibao Yu, Wenxian Yang, Hongzhi Ruan, Zhenwei Yang, Yingjuan Tang, Xu Gao, Xin Hao, Yifeng Shi, Yifeng Pan, Ning Sun, Juan Song, Jirui Yuan, Ping Luo, and Zaiqing Nie. V2x-seq: A large-scale sequential dataset for vehicle-infrastructure cooperative perception and forecasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni...
2023
-
[26]
Yunpeng Zhang, Zheng Zhu, Wenzhao Zheng, Junjie Huang, Guan Huang, Jie Zhou, and Jiwen Lu. Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving.arXiv preprint arXiv:2205.09743, 2022
-
[27]
Vision Meets Drones: A Challenge
Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Ling, and Qinghua Hu. Vision meets drones: A challenge.arXiv preprint arXiv:1804.07437, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Vigor: Cross-view image geo-localization beyond one-to-one retrieval
Sijie Zhu, Taojiannan Yang, and Chen Chen. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3640–3649, 2021. 11
2021
-
[29]
Tumtraf v2x cooperative perception dataset.arXiv preprint arXiv:2403.01316, 2024
Walter Zimmer, Gerhard Arya Wardana, Suren Sritharan, Xingcheng Zhou, Rui Song, and Alois Knoll. Tumtraf v2x cooperative perception dataset.arXiv preprint arXiv:2403.01316, 2024. 12 A Additional Dataset Statistics This appendix provides additional dataset statistics complementing the summary reported in the main paper. In particular, we report the semanti...
-
[30]
A scene is selected from the scene manifest together with its synchronized street and drone views
-
[31]
The interface loads all currently visible street-view tracks and candidate drone-view tracks for a given aligned frame
-
[32]
For each visible street-view track, the annotator either assigns a drone-view track ID, marks the object as unmatched, or defers uncertain cases for later review
-
[33]
The verified assignments are stored ingt_pairs.csv, while annotation history is optionally recorded ingt_audit.csv. We found frame-batch annotation substantially faster than one-track-at-a-time verification because it allows the annotator to reason jointly about all visible objects in the scene, reducing repeated context switching and improving consistenc...
-
[34]
scene manifest loading,
-
[35]
wedge filtering around the ego trajectory,
-
[36]
crop extraction for street and drone views,
-
[37]
CLIP embedding computation,
-
[38]
frame-level candidate matching,
-
[39]
track-level temporal voting,
-
[40]
This organization supports both large-scale preprocessing and iterative annotation
human verification and evaluation. This organization supports both large-scale preprocessing and iterative annotation. 18 D.3 Coordinate Alignment BEV evaluation requires reliable scene-level alignment between the street-view camera frame and the drone metric frame. We therefore compute per-scene coordinate alignment before evaluating BEV baselines. Scene...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.