Defending Against Malicious Finetuning by Scaling Train-time Adversarial Attacks
Pith reviewed 2026-06-27 20:08 UTC · model grok-4.3
The pith
Scaling the number of optimization steps in the adversarial training loop produces LLMs whose parameters resist full-parameter malicious finetuning after release.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
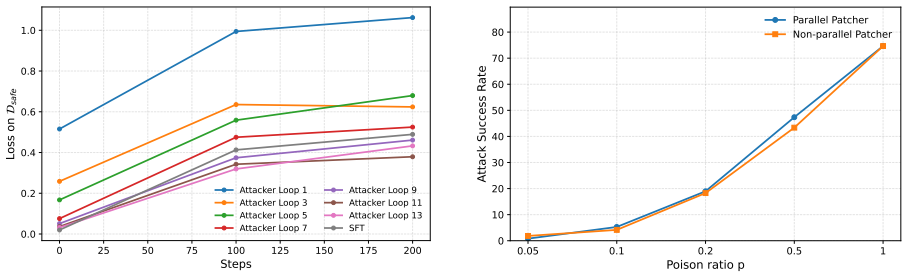
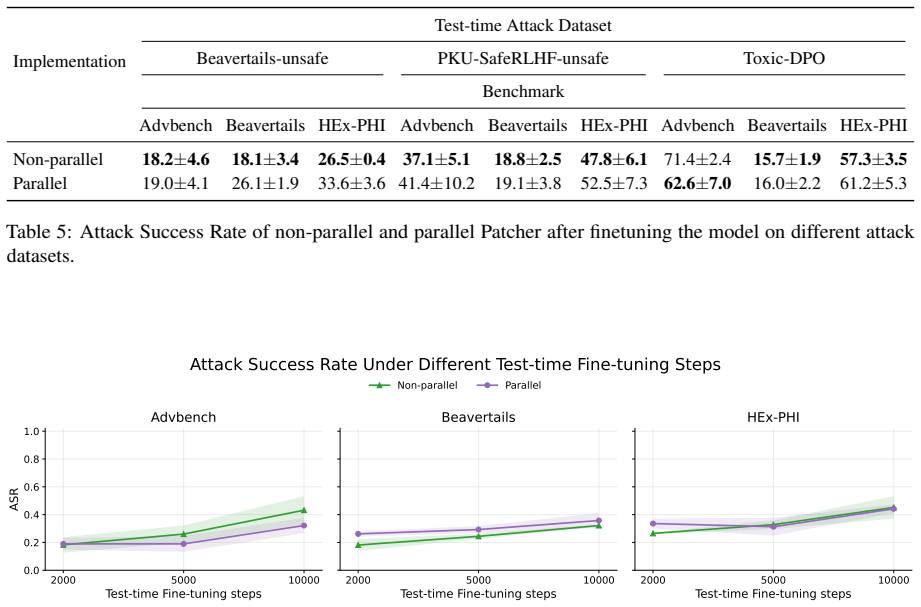
Patcher frames defense as bi-level optimization: the inner level performs many steps of finetuning on adversarial data to simulate a strong attack, and the outer level adjusts the starting parameters to minimize the post-attack loss. This forces the aligned model to be insensitive to subsequent malicious updates.
What carries the argument
Patcher, the bi-level optimization that enlarges the inner adversarial finetuning loop to simulate stronger attacks during training.
If this is right
- Patcher yields higher robustness than standard SFT alignment.
- The robustness improvement transfers across different attack methods and model scales.
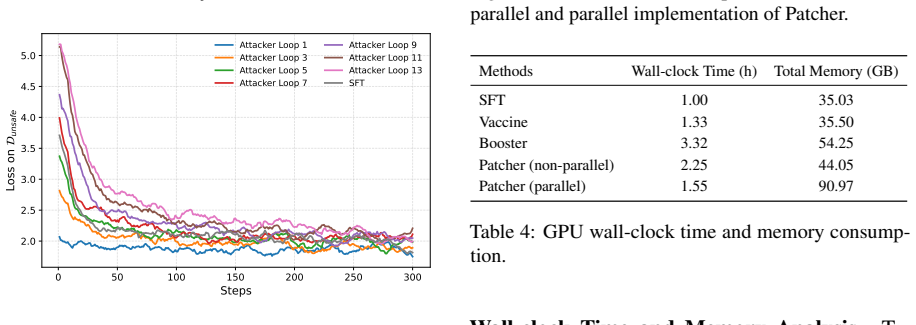
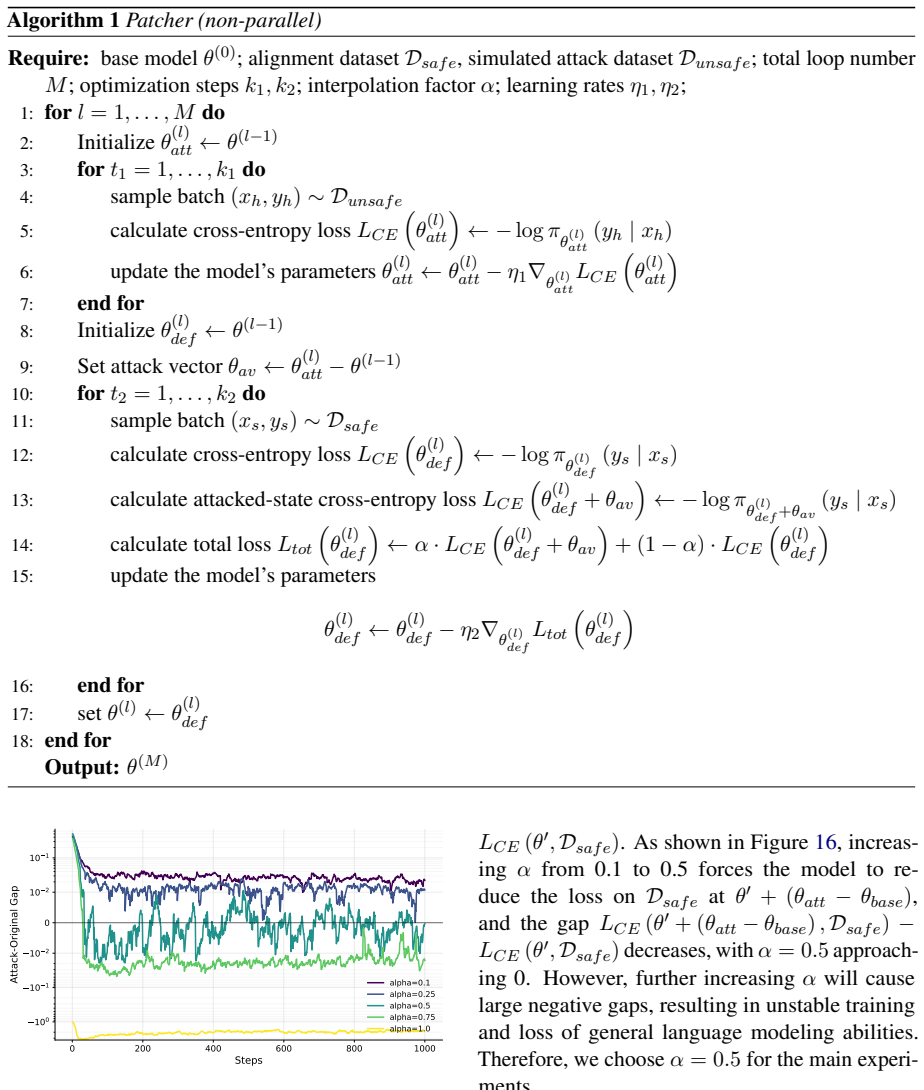
- The parallel implementation allows the method to run with reduced wall-clock time without losing effectiveness.
Where Pith is reading between the lines
- If the simulation matches real attacks closely enough, similar scaling could apply to other alignment techniques like RLHF.
- Models released after Patcher training might require attackers to use substantially more compute or data to succeed.
- This approach highlights that defense strength can be tuned by the intensity of the simulated threat during training.
Load-bearing premise
That increasing the simulated attack strength in training will make the resulting model robust to actual full-parameter finetuning attacks that occur after the model weights are released.
What would settle it
An experiment where an attacker performs full-parameter finetuning on a Patcher-aligned model using a poisoned dataset and still achieves high success in bypassing safety, despite the scaled training.
Figures
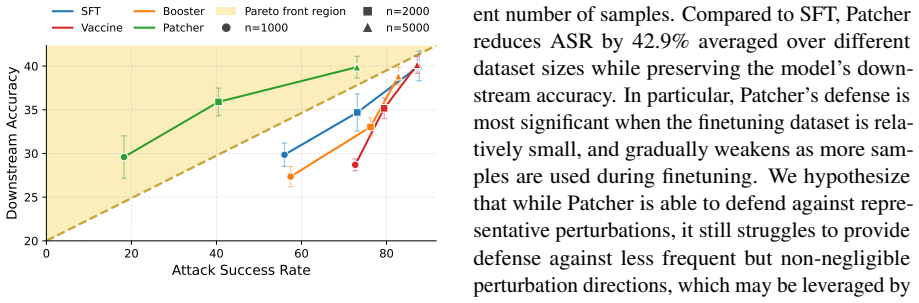
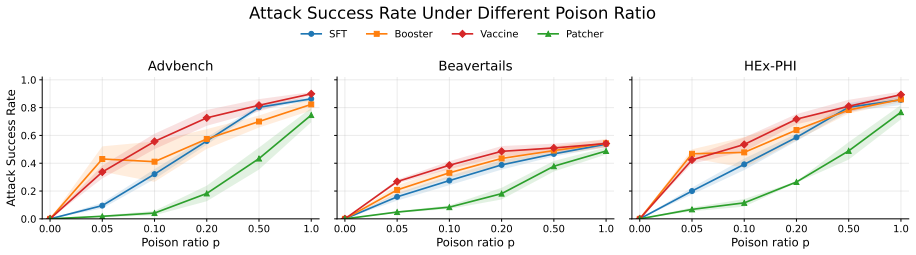
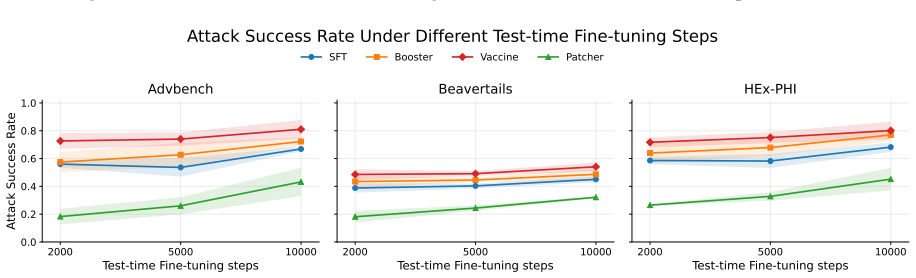
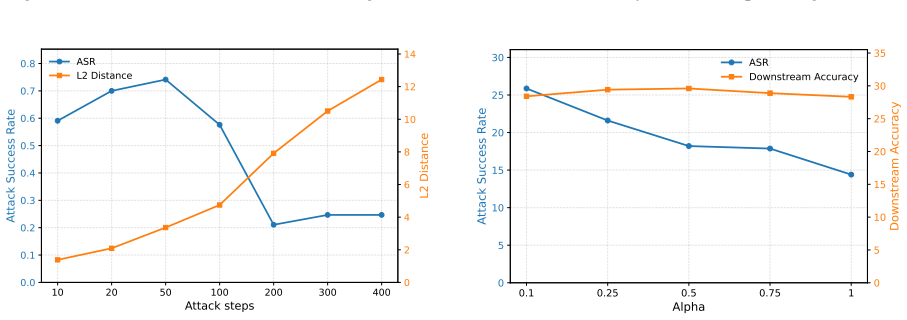
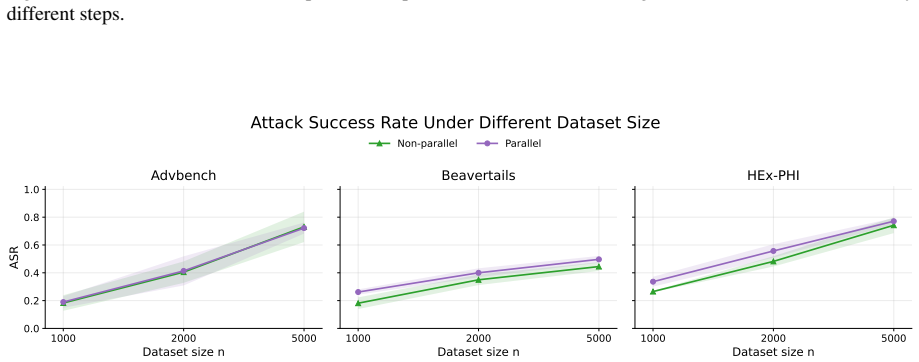



read the original abstract
Current open-weight large language models (LLMs) are prone to malicious finetuning attacks, which could compromise the safety alignment of LLMs with only a few steps of supervised finetuning (SFT) on poisoned datasets. Existing alignment-stage defenses are primarily designed to defend against attacks that use parameter-efficient finetuning methods. However, they fail to defend against stronger attacks that use full-parameter finetuning. In this paper, we propose Patcher, a method inspired by adversarial training and bi-level optimization, to combat such attacks. Patcher strengthens the simulated attack by scaling up the optimization steps in the adversarial loop, thus forcing the defender to find model parameters that are insensitive to stronger attacks. Furthermore, we propose an efficient parallel algorithm to implement Patcher, decreasing the wall-clock time of training while preserving Patcher's performance. Extensive experiments show that Patcher substantially improves the model's robustness compared to vanilla SFT alignment, and transfers to diverse attack scenarios and model sizes. Code is available at https://github.com/haomingwen/patcher.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Patcher, a defense method for open-weight LLMs against malicious full-parameter finetuning attacks. Inspired by adversarial training, it employs bi-level optimization where the inner loop's optimization steps are scaled up to simulate stronger attacks, aiming to produce model parameters that are robust to such attacks. An efficient parallel algorithm is presented to reduce training time, and extensive experiments are reported to show substantial robustness improvements over vanilla SFT alignment, with transfer to diverse scenarios and model sizes.
Significance. If the empirical findings hold, this work could be significant for the field of LLM alignment and safety, as it addresses a gap in defending against full-parameter attacks that current methods do not handle well. The release of code supports reproducibility, which is a strength.
major comments (2)
- [§3 (Method)] The bi-level optimization in Patcher scales the number of inner-loop steps to force insensitivity to stronger attacks, but the manuscript does not demonstrate that this scaling regime covers variations in attacker procedures such as optimizer choice, learning-rate schedule, or data selection; this assumption is load-bearing for the claim that the resulting parameters remain robust against real malicious full-parameter finetuning after release.
- [§4 (Experiments)] While transfer to diverse attack scenarios is claimed, specific details on the range of attack strengths tested and whether gains persist against attacks that deviate from the training distribution are needed to substantiate the central robustness claim.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., improvement in robustness metric) to support the claims of substantial improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and agree to make revisions that clarify assumptions and provide additional experimental details to strengthen the robustness claims.
read point-by-point responses
-
Referee: [§3 (Method)] The bi-level optimization in Patcher scales the number of inner-loop steps to force insensitivity to stronger attacks, but the manuscript does not demonstrate that this scaling regime covers variations in attacker procedures such as optimizer choice, learning-rate schedule, or data selection; this assumption is load-bearing for the claim that the resulting parameters remain robust against real malicious full-parameter finetuning after release.
Authors: We agree this is a valid point and that the scaling regime's coverage of attacker variations is an important assumption. The bi-level optimization is motivated as a way to simulate stronger attacks through increased inner-loop steps, with the goal of producing parameters insensitive to such attacks, and the paper reports transfer across scenarios. However, we did not test all possible attacker procedures. In the revision we will add an explicit discussion paragraph in §3 on these assumptions and limitations, plus new experiments in the supplement evaluating different optimizers and learning-rate schedules. revision: yes
-
Referee: [§4 (Experiments)] While transfer to diverse attack scenarios is claimed, specific details on the range of attack strengths tested and whether gains persist against attacks that deviate from the training distribution are needed to substantiate the central robustness claim.
Authors: We appreciate the request for greater specificity. The manuscript already reports results across varying attack strengths (via different numbers of inner-loop and finetuning steps) and shows transfer to diverse scenarios and model sizes. To better substantiate the claims, we will revise §4 to include a table or section explicitly listing the tested attack strength ranges and add results for attacks that deviate from the training distribution (e.g., altered data selection), confirming that gains persist. revision: yes
Circularity Check
No circularity: empirical adversarial training procedure with no self-referential derivations or fitted predictions
full rationale
The paper presents Patcher as an empirical bi-level optimization procedure that scales inner-loop adversarial steps during training. No equations, parameters, or uniqueness theorems are defined in terms of the target robustness metric, nor are any 'predictions' shown to reduce to fitted inputs by construction. The central claim rests on experimental transfer results rather than a closed logical chain. No self-citation load-bearing steps or ansatz smuggling are present in the provided text. The method is self-contained as a practical defense algorithm evaluated on held-out attack scenarios.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Increasing inner-loop optimization steps in a bi-level adversarial setup produces parameters insensitive to stronger attacks
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.10671 , year=
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
-
[2]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[3]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[4]
International Conference on Learning Representations , volume=
Fine-tuning aligned language models compromises safety, even when users do not intend to! , author=. International Conference on Learning Representations , volume=
-
[5]
arXiv preprint arXiv:2409.18169 , year=
Harmful fine-tuning attacks and defenses for large language models: A survey , author=. arXiv preprint arXiv:2409.18169 , year=
-
[6]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[7]
International conference on machine learning , pages=
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[8]
Advances in Neural Information Processing Systems , volume=
Vaccine: Perturbation-aware alignment for large language models against harmful fine-tuning attack , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International Conference on Learning Representations , volume=
Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation , author=. International Conference on Learning Representations , volume=
-
[10]
Advances in Neural Information Processing Systems , volume=
Representation noising: A defence mechanism against harmful finetuning , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
International Conference on Learning Representations , volume=
Tamper-resistant safeguards for open-weight llms , author=. International Conference on Learning Representations , volume=
-
[12]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International Conference on Learning Representations , volume=
Robust LLM safeguarding via refusal feature adversarial training , author=. International Conference on Learning Representations , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
Llms encode harmfulness and refusal separately , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:1412.6572 , year=
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
-
[16]
arXiv preprint arXiv:1706.06083 , year=
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
-
[17]
arXiv preprint arXiv:2010.01412 , year=
Sharpness-aware minimization for efficiently improving generalization , author=. arXiv preprint arXiv:2010.01412 , year=
Pith/arXiv arXiv 2010
-
[18]
Advances in neural information processing systems , volume=
Adversarial weight perturbation helps robust generalization , author=. Advances in neural information processing systems , volume=
-
[19]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[20]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Immunization against harmful fine-tuning attacks , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[21]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[23]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[24]
Advances in Neural Information Processing Systems , volume=
Keeping llms aligned after fine-tuning: The crucial role of prompt templates , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:1711.05101 , year=
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
-
[26]
2025 , eprint=
AntiDote: Bi-level Adversarial Training for Tamper-Resistant LLMs , author=. 2025 , eprint=
2025
-
[27]
arXiv preprint arXiv:2308.13320 , year=
Fine-tuning can cripple your foundation model; preserving features may be the solution , author=. arXiv preprint arXiv:2308.13320 , year=
-
[28]
arXiv preprint arXiv:2402.02207 , year=
Safety fine-tuning at (almost) no cost: A baseline for vision large language models , author=. arXiv preprint arXiv:2402.02207 , year=
-
[29]
Advances in Neural Information Processing Systems , volume=
Lisa: Lazy safety alignment for large language models against harmful fine-tuning attack , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Making harmful behaviors unlearnable for large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[31]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Language models are homer simpson! safety re-alignment of fine-tuned language models through task arithmetic , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
arXiv preprint arXiv:2408.09600 , year=
Antidote: Post-fine-tuning safety alignment for large language models against harmful fine-tuning , author=. arXiv preprint arXiv:2408.09600 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Safe lora: The silver lining of reducing safety risks when finetuning large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2505.12186 , year=
Self-destructive language model , author=. arXiv preprint arXiv:2505.12186 , year=
-
[35]
International Conference on Learning Representations , volume=
On evaluating the durability of safeguards for open-weight llms , author=. International Conference on Learning Representations , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.