MC-PDD: Masked Corpus-Level Pretraining Data Detection for Black-Box Large Language Models
Pith reviewed 2026-06-27 20:00 UTC · model grok-4.3
The pith
MC-PDD identifies pretraining data in black-box LLMs by comparing masked-token prediction hit rates against a reference corpus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
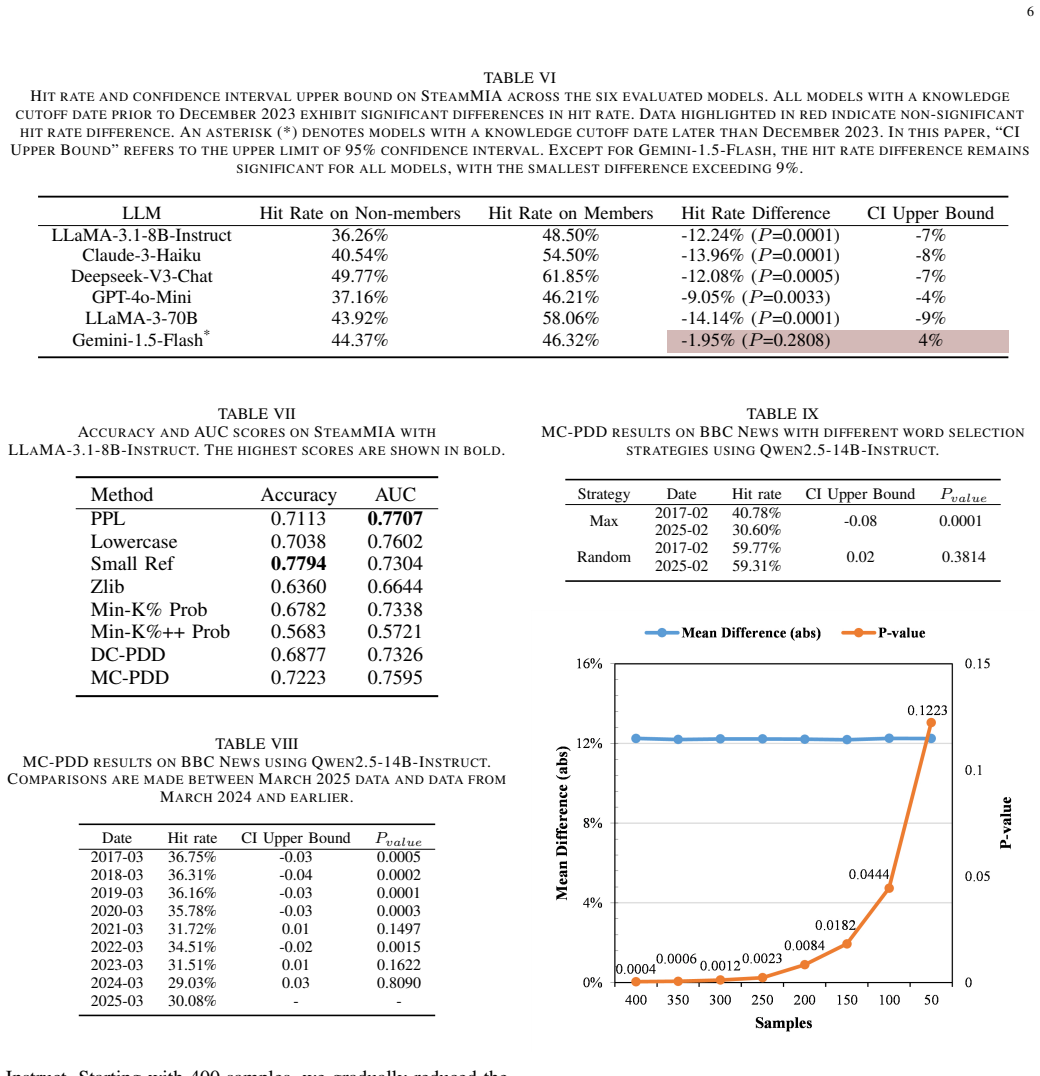
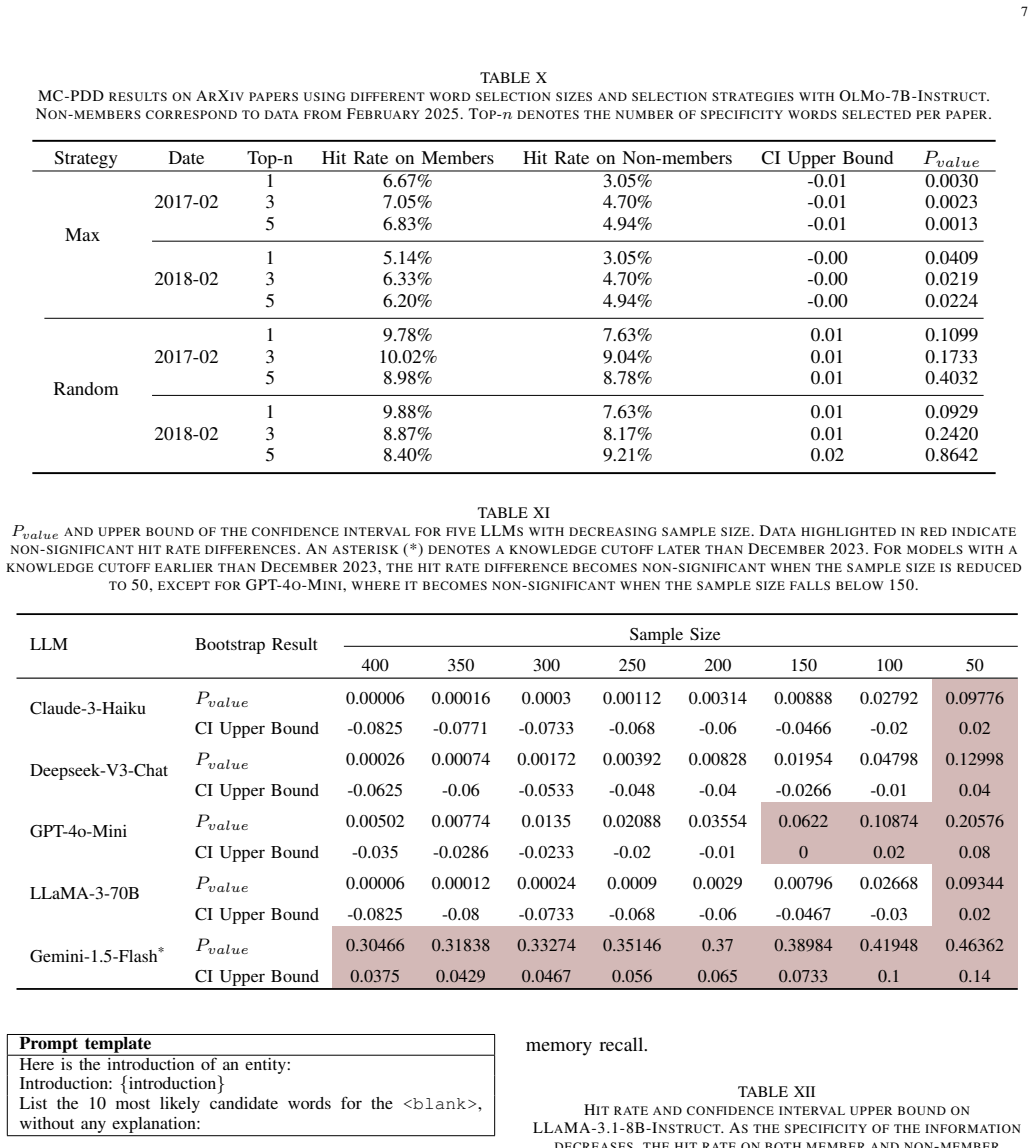
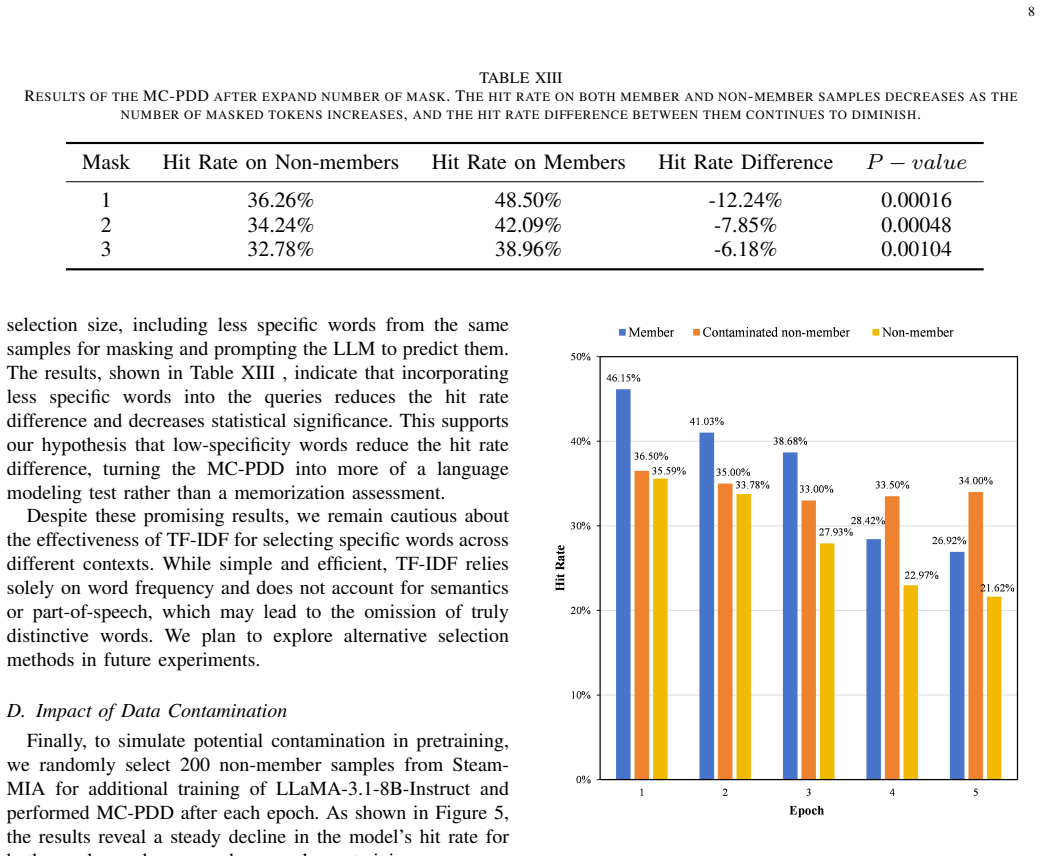
MC-PDD determines whether candidate texts were likely included in the model's pretraining data by masking highly specific tokens in each text, prompting the LLM to predict the missing content, and testing whether the difference in prediction hit rates between the candidate corpus and a reference non-member corpus is statistically significant. Experiments across three datasets show clear and consistent hit-rate gaps between pretrained and unseen data for both open-source and closed-source LLMs, achieving performance comparable to existing methods despite the stricter black-box setting.
What carries the argument
Masked prediction hit-rate comparison, which infers membership from statistically significant differences in token-filling accuracy between candidate and reference corpora.
If this is right
- Model auditing for data usage becomes feasible for closed-source LLMs using only standard API access.
- Data copyright verification can be performed without access to internal model probabilities.
- The method produces consistent detection signals across multiple datasets for both open and closed models.
- Practical applications in ethical AI development and legal compliance are enabled under black-box constraints.
Where Pith is reading between the lines
- The same masking approach might be adapted to detect data used in subsequent fine-tuning stages rather than pretraining alone.
- Adversarial text modifications that alter style or specificity could be tested as ways to reduce detection rates.
- Combining hit-rate signals with other observable outputs such as generation length or repetition patterns could strengthen robustness to domain shifts.
Load-bearing premise
Observed differences in masked-token prediction hit rates are caused by pretraining membership rather than confounding factors such as domain, style, or length, and the reference corpus is verifiably unseen by the model.
What would settle it
A corpus confirmed to be absent from pretraining that nevertheless yields a statistically higher hit rate than a known member corpus, or a known member corpus that shows no significant hit-rate advantage over the reference.
Figures


read the original abstract
Pretraining is fundamental to the development of Large Language Models (LLMs), yet the opacity of pretraining data complicates model analysis and raises ethical, legal, and fairness concerns. Detecting whether specific datasets were used during pretraining is, therefore, critical. Existing state-of-the-art methods typically rely on access to model probability distributions, making them unsuitable for closed-source LLMs that provide only input-output interfaces. To address this limitation, we introduce Masked Corpus-level Pretraining Data Detection (MC-PDD), a novel method inspired by the masked language modeling paradigm. MC-PDD masks highly specific tokens in each text and prompts the LLM to predict the missing content. It then assesses whether the difference in prediction hit rates between a candidate corpus and a reference non-member corpus is statistically significant. Based on this comparison, MC-PDD determines whether the candidate texts were likely included in the model's pretraining data. Experimental results demonstrate clear and consistent differences in prediction hit rates between pretrained and unseen data across three datasets, for both open-source and closed-source LLMs. Despite operating under a stricter black-box setting, MC-PDD achieves performance comparable to existing detection methods. Our approach enables practical applications such as model auditing and data copyright verification using only standard API access. Upon acceptance, we will publicly release the code and datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MC-PDD, a black-box method for detecting whether candidate texts were included in an LLM's pretraining data. It masks highly specific tokens in each text, prompts the model for predictions, and determines membership by testing whether the hit-rate difference versus a reference non-member corpus is statistically significant. Experiments across three datasets are reported to show consistent differences for both open- and closed-source models, with performance comparable to prior methods despite the stricter access constraint.
Significance. If the hit-rate gaps can be shown to arise from membership rather than domain, style, length, or token-frequency mismatches, the approach would enable practical auditing and copyright verification of closed-source LLMs using only standard API calls, addressing a clear gap in existing detection techniques that require probability access.
major comments (2)
- [Abstract] Abstract: the central claim that 'statistically significant differences in prediction hit rates' indicate pretraining membership is load-bearing, yet the abstract provides no description of how the candidate and reference corpora are matched on domain, style, length, or token-frequency distributions; any systematic mismatch could produce the observed gaps without a membership signal.
- [Abstract] Abstract / Evaluation: the reported 'clear and consistent differences' and 'comparable performance' are asserted without dataset sizes, error bars, exact statistical tests, or verification procedure for the reference corpus being verifiably unseen (especially for closed-source models), rendering the attribution to membership untestable from the given information.
minor comments (1)
- [Abstract] The abstract states that code and datasets will be released upon acceptance; confirming this in the camera-ready version would strengthen reproducibility claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation details. We address each major comment below and will revise the manuscript to improve clarity on matching procedures and experimental reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'statistically significant differences in prediction hit rates' indicate pretraining membership is load-bearing, yet the abstract provides no description of how the candidate and reference corpora are matched on domain, style, length, or token-frequency distributions; any systematic mismatch could produce the observed gaps without a membership signal.
Authors: We agree the abstract should explicitly note the matching. The full manuscript describes constructing or selecting the reference non-member corpus to align with the candidate on domain, style, length, and token-frequency distributions (via sampling and filtering steps detailed in Section 3). We will revise the abstract to include a concise statement on this matching to isolate the membership signal. revision: yes
-
Referee: [Abstract] Abstract / Evaluation: the reported 'clear and consistent differences' and 'comparable performance' are asserted without dataset sizes, error bars, exact statistical tests, or verification procedure for the reference corpus being verifiably unseen (especially for closed-source models), rendering the attribution to membership untestable from the given information.
Authors: We will expand the abstract to report dataset sizes, error bars, and the specific statistical tests (e.g., t-tests or Wilcoxon with significance thresholds) used for hit-rate comparisons. For reference corpus verification, open-source cases allow direct confirmation via training data inspection; for closed-source models we rely on publicly documented non-member sources or synthetically generated references assumed unseen. We will add this clarification and note the inherent limitation. revision: partial
- Complete, independent verification that reference corpora are verifiably unseen remains impossible for closed-source models due to the black-box access constraint.
Circularity Check
No circularity: method relies on external statistical comparison
full rationale
The paper presents MC-PDD as a black-box detection procedure that masks specific tokens and compares hit-rate differences against a separate reference non-member corpus using statistical tests. No equations, fitted parameters, or derivations are shown that reduce the output to the input by construction. The core logic depends on observable differences between two distinct corpora rather than self-definition, renamed fits, or load-bearing self-citations. The approach is therefore self-contained and externally falsifiable via the reference corpus and API outputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- masking rate and token selection
- statistical significance threshold
axioms (1)
- domain assumption Masked prediction hit rates differ measurably based on pretraining exposure
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, and S. Agarwal et al., “Language models are few-shot learners,” inAdvances NeurIPS, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901
2020
-
[2]
Llmcl-gec: Advancing grammatical error correction with llm-driven curriculum learning,
T. Fang, D. F. Wong, L. Zhang, K. Jin, Q. Zhang, T. Li, J. Hou, and L. S. Chao, “Llmcl-gec: Advancing grammatical error correction with llm-driven curriculum learning,” inPreprint. arXiv:2412.12541, 2024
arXiv 2024
-
[3]
Is chatgpt a good translator? a preliminary study,
W. Jiao, W. Wang, J.-t. Huang, X. Wang, and Z. Tu, “Is chatgpt a good translator? a preliminary study,”arXiv preprint arXiv:2301.08745, vol. 1, no. 10, 2023
arXiv 2023
-
[4]
How good are gpt models at machine translation? a comprehensive evaluation,
A. Hendy, M. Abdelrehim, A. Sharaf, V . Raunak, M. Gabr, H. Mat- sushita, Y . J. Kim, M. Afify, and H. H. Awadalla, “How good are gpt models at machine translation? a comprehensive evaluation,”arXiv preprint arXiv:2302.09210, 2023
arXiv 2023
-
[5]
A preliminary evalu- ation of chatgpt for zero-shot dialogue understanding,
W. Pan, Q. Chen, X. Xu, W. Che, and L. Qin, “A preliminary evalu- ation of chatgpt for zero-shot dialogue understanding,”arXiv preprint arXiv:2304.04256, 2023
arXiv 2023
-
[6]
Is chatgpt a highly fluent grammatical error correction system? a comprehensive evaluation,
T. Fang, S. Yang, K. Lan, D. F. Wong, J. Hu, L. S. Chao, and Y . Zhang, “Is chatgpt a highly fluent grammatical error correction system? a comprehensive evaluation,”arXiv preprint arXiv:2304.01746, 2023
arXiv 2023
-
[7]
Exploring effective- ness of GPT-3 in grammatical error correction: A study on performance and controllability in prompt-based methods,
M. Loem, M. Kaneko, S. Takase, and N. Okazaki, “Exploring effective- ness of GPT-3 in grammatical error correction: A study on performance and controllability in prompt-based methods,” inBEA, E. Kochmar, J. Burstein, A. Horbach, R. Laarmann-Quante, N. Madnani, A. Tack, V . Yaneva, Z. Yuan, and T. Zesch, Eds. Toronto, Canada: ACL, Jul. 2023, pp. 205–219
2023
-
[8]
TransGEC: Improving grammatical error correction with translationese,
T. Fang, X. Liu, D. F. Wong, R. Zhan, L. Ding, L. S. Chao, D. Tao, and M. Zhang, “TransGEC: Improving grammatical error correction with translationese,” inACL, A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: ACL, Jul. 2023, pp. 3614–3633
2023
-
[10]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, and S. B. et al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[11]
OpenAI, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2024
Pith/arXiv arXiv 2024
-
[12]
Proving test set contamination in black box language models,
Y . Oren, N. Meister, N. Chatterji, F. Ladhak, and T. B. Hashimoto, “Proving test set contamination in black box language models,”arxiv preprint arxiv:2310.17623, 2023
arXiv 2023
-
[13]
H. Zhang, Y . Lin, and X. Wan, “Pacost: Paired confidence significance testing for benchmark contamination detection in large language mod- els,”arxiv preprint arxiv:2406.18326, 2024
arXiv 2024
-
[14]
H. K. Choi, M. Khanov, H. Wei, and Y . Li, “How contaminated is your benchmark? quantifying dataset leakage in large language models with kernel divergence,”arxiv preprint arxiv:2502.00678, 2025
arXiv 2025
-
[15]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, A. Oprea, and C. Raffel, “Extracting training data from large language models,”arxiv preprint arxiv:2012.07805, 2021
arXiv 2012
-
[16]
Advancing differential privacy: Where we are now and future directions for real-world deployment,
R. Cummings, D. Desfontaines, D. Evans, R. Geambasu, Y . Huang, M. Jagielski, P. Kairouz, G. Kamath, S. Oh, O. Ohrimenko, N. Papernot, R. Rogers, M. Shen, S. Song, W. Su, A. Terzis, A. Thakurta, S. Vas- silvitskii, Y .-X. Wang, L. Xiong, S. Yekhanin, D. Yu, H. Zhang, and W. Zhang, “Advancing differential privacy: Where we are now and future directions for...
arXiv 2024
-
[17]
Detecting pretraining data from large language models,
W. Shi, A. Ajith, M. Xia, Y . Huang, D. Liu, T. Blevins, D. Chen, and L. Zettlemoyer, “Detecting pretraining data from large language models,”arxiv preprint arxiv:2310.16789, 2024
Pith/arXiv arXiv 2024
-
[18]
Pretraining data detection for large language models: A divergence- based calibration method,
W. Zhang, R. Zhang, J. Guo, M. de Rijke, Y . Fan, and X. Cheng, “Pretraining data detection for large language models: A divergence- based calibration method,”arxiv preprint arxiv:2409.14781, 2025
arXiv 2025
-
[19]
A statistical interpretation of term specificity and its application in retrieval,
K. Sparck Jones, “A statistical interpretation of term specificity and its application in retrieval,”Journal of documentation, vol. 28, no. 1, pp. 11–21, 1972
1972
-
[20]
Membership inference attacks against machine learning models,
R. Shokri, M. Stronati, C. Song, and V . Shmatikov, “Membership inference attacks against machine learning models,”arxiv preprint arxiv:1610.05820, 2017
Pith/arXiv arXiv 2017
-
[21]
Min-K%++: Improved baseline for detecting pre-training data from large language models,
J. Zhang, J. Sun, E. Yeats, Y . Ouyang, M. Kuo, J. Zhang, H. F. Yang, and H. Li, “Min-K%++: Improved baseline for detecting pre-training data from large language models,”arxiv preprint arxiv:2404.02936, 2025
arXiv 2025
-
[22]
DPDLLM: A black-box framework for detecting pre-training data from large language models,
B. Zhou, Z. Wang, L. Wang, H. Wang, Y . Zhang, K. Song, X. Sui, and K.-F. Wong, “DPDLLM: A black-box framework for detecting pre-training data from large language models,” inACL, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: ACL, Aug. 2024, pp. 644–653
2024
-
[23]
Speak, memory: An archaeology of books known to ChatGPT/GPT-4,
K. Chang, M. Cramer, S. Soni, and D. Bamman, “Speak, memory: An archaeology of books known to ChatGPT/GPT-4,” inEMNLP, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: ACL, Dec. 2023, pp. 7312–7327
2023
-
[24]
Recovering private text in federated learning of language models,
S. Gupta, Y . Huang, Z. Zhong, T. Gao, K. Li, and D. Chen, “Recovering private text in federated learning of language models,”arxiv preprint arxiv:2205.08514, 2022
arXiv 2022
-
[25]
Membership leakage in label-only exposures,
Z. Li and Y . Zhang, “Membership leakage in label-only exposures,” in CCS, ser. CCS ’21. New York, NY , USA: ACM, 2021, p. 880–895
2021
-
[26]
Quantifying privacy leakage in graph embedding,
V . Duddu, A. Boutet, and V . Shejwalkar, “Quantifying privacy leakage in graph embedding,” inMobiQuitous 2020, ser. MobiQuitous ’20. New York, NY , USA: ACM, 2021, p. 76–85
2020
-
[27]
Gan-leaks: A taxonomy of membership inference attacks against generative models,
D. Chen, N. Yu, Y . Zhang, and M. Fritz, “Gan-leaks: A taxonomy of membership inference attacks against generative models,” inCCS, ser. CCS ’20. New York, NY , USA: ACM, 2020, p. 343–362
2020
-
[28]
Towards black-box membership inference attack for diffusion models,
J. Li, J. Dong, T. He, and J. Zhang, “Towards black-box membership inference attack for diffusion models,”arxiv preprint arxiv:2405.20771, 2024
arXiv 2024
-
[29]
Membership inference attacks on sequence-to-sequence models: Is my data in your machine translation system?
S. Hisamoto, M. Post, and K. Duh, “Membership inference attacks on sequence-to-sequence models: Is my data in your machine translation system?”TACL, vol. 8, pp. 49–63, 2020
2020
-
[30]
Membership infer- ence attack susceptibility of clinical language models,
A. Jagannatha, B. P. S. Rawat, and H. Yu, “Membership infer- ence attack susceptibility of clinical language models,”arxiv preprint arxiv:2104.08305, 2021
arXiv 2021
-
[31]
Membership inference attacks against language models via neighbourhood comparison,
J. Mattern, F. Mireshghallah, Z. Jin, B. Sch ¨olkopf, M. Sachan, and T. Berg-Kirkpatrick, “Membership inference attacks against language models via neighbourhood comparison,” inACL, A. Rogers, J. Boyd- Graber, and N. Okazaki, Eds. Toronto, Canada: ACL, Jul. 2023, pp. 11 330–11 343
2023
-
[32]
Scalable 10 extraction of training data from (production) language models,
M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito, C. A. Choquette-Choo, E. Wallace, F. Tram `er, and K. Lee, “Scalable 10 extraction of training data from (production) language models,”arxiv preprint arxiv:2311.17035, 2023
Pith/arXiv arXiv 2023
-
[33]
Data contamination: From memorization to exploitation,
I. Magar and R. Schwartz, “Data contamination: From memorization to exploitation,” inACL, S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: ACL, May 2022, pp. 157–165
2022
-
[34]
Language models are few-shot learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert- V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Am...
Pith/arXiv arXiv 2005
-
[35]
Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation,
M. Eriksson, E. Purificato, A. Noroozian, J. Vinagre, G. Chaslot, E. Gomez, and D. Fernandez-Llorca, “Can we trust ai benchmarks? an interdisciplinary review of current issues in ai evaluation,”arxiv preprint arxiv:2502.06559, 2025
arXiv 2025
-
[36]
Pythia: A suite for analyzing large language models across training and scaling,
S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. van der Wal, “Pythia: A suite for analyzing large language models across training and scaling,”arxiv preprint arxiv:2304.01373, 2023
Pith/arXiv arXiv 2023
-
[37]
Gpt-neox- 20b: An open-source autoregressive language model,
S. Black, S. Biderman, E. Hallahan, Q. Anthony, L. Gao, L. Golding, H. He, C. Leahy, K. McDonell, J. Phang, M. Pieler, U. S. Prashanth, S. Purohit, L. Reynolds, J. Tow, B. Wang, and S. Weinbach, “Gpt-neox- 20b: An open-source autoregressive language model,”arxiv preprint arxiv:2204.06745, 2022
Pith/arXiv arXiv 2022
-
[38]
Llama: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “Llama: Open and efficient foundation language models,”arxiv preprint arxiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[39]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, and A. G. et al, “The llama 3 herd of models,”arxiv preprint arxiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[40]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, and D. G. et al, “Deepseek-v3 technical report,”arxiv preprint arxiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[41]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wang, and et al, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arxiv preprint arxiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[42]
Olmo: Accelerating the science of language models,
D. Groeneveld, I. Beltagy, P. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. H. Jha, H. Ivison, I. Magnusson, Y . Wang, S. Arora, and D. A. et al., “Olmo: Accelerating the science of language models,”arxiv preprint arxiv:2402.00838, 2024
Pith/arXiv arXiv 2024
-
[43]
Latesteval: Addressing data contamination in language model evaluation through dynamic and time-sensitive test construction,
Y . Li, F. Guerin, and C. Lin, “Latesteval: Addressing data contamination in language model evaluation through dynamic and time-sensitive test construction,” inAAAI, vol. 38, 2024, pp. 18 600–18 607
2024
-
[44]
Bootstrap methods: another look at the jackknife,
B. Efron, “Bootstrap methods: another look at the jackknife,” inBreak- throughs in statistics: Methodology and distribution. Springer, 1992, pp. 569–593
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.