Revisiting Articulated Parts Perception in Robot Manipulation
Pith reviewed 2026-06-27 19:34 UTC · model grok-4.3
The pith
Geometric Primary Structure representation lets robots perceive articulated parts from one RGB-D image and manipulate them at 73% success without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
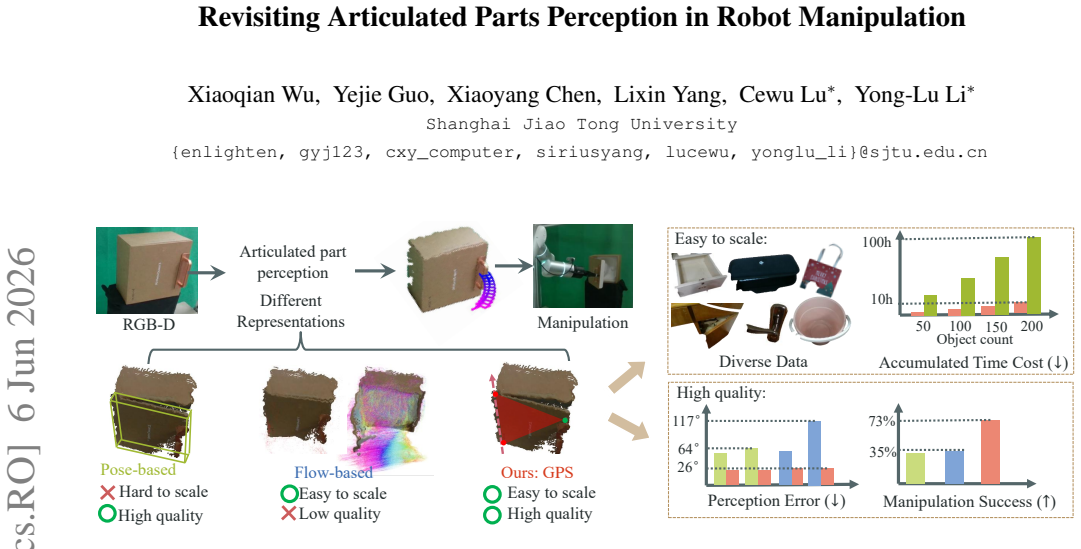
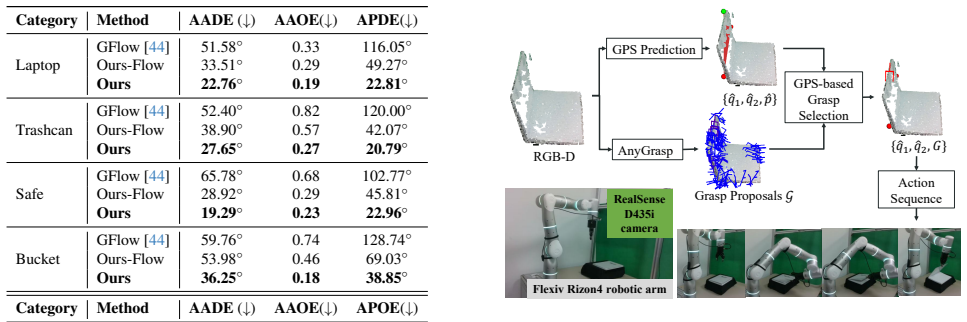
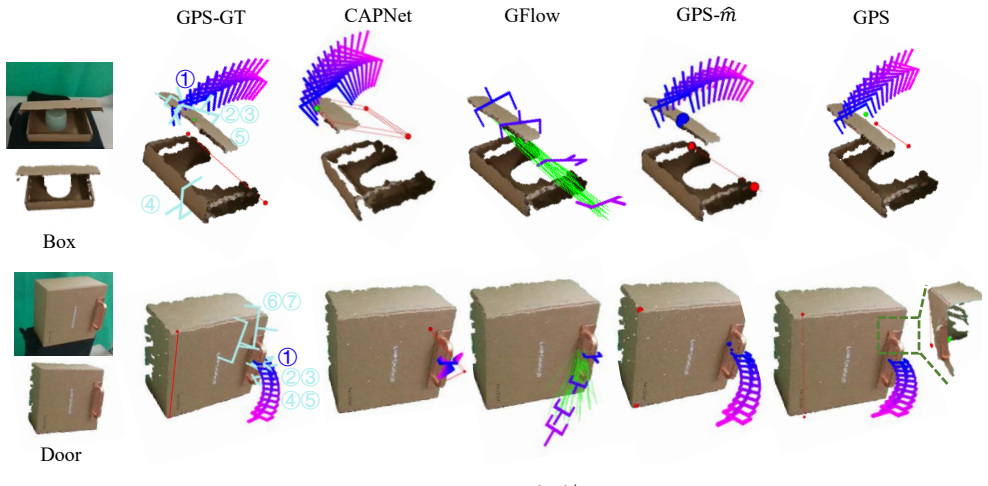
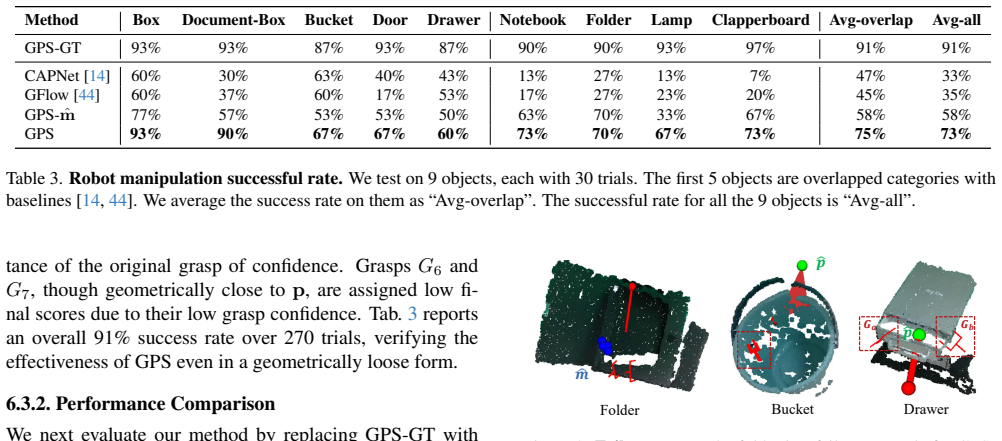
Geometric Primary Structure (GPS) is introduced as an abstraction of part geometry structure that supports efficient VR-based annotation and yields a generalizable perception model from single RGB-D images; a heuristic policy built on GPS predictions then achieves 73% success on real-robot manipulation of articulated parts across 270 states for nine objects without any in-domain fine-tuning.
What carries the argument
Geometric Primary Structure (GPS), an abstraction of the part geometry structure that encodes key geometric features for manipulation tasks.
If this is right
- GPS enables direct deployment of manipulation policies on new objects without retraining.
- The VR annotation pipeline reduces manual effort to roughly one minute per object sequence.
- Single RGB-D input makes GPS prediction practical for onboard robot cameras.
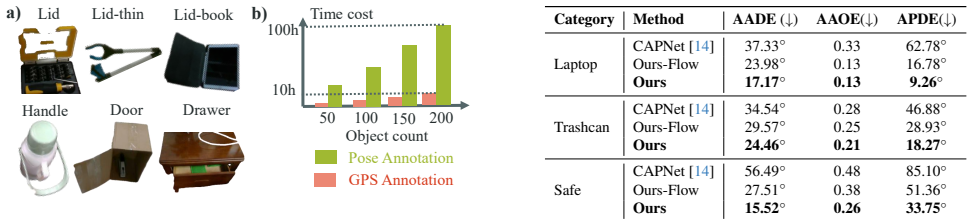
- The collected 41K-frame dataset supports training across six part classes for broader coverage.
Where Pith is reading between the lines
- If GPS generalizes across more mechanisms, it could support manipulation of objects with multiple joints such as laptops or cabinets.
- The approach may allow mixing VR-annotated real data with simulation to improve robustness in cluttered scenes.
- Extending the heuristic policy to use probabilistic GPS outputs could reduce failures from uncertain predictions.
Load-bearing premise
The heuristic policy derived from GPS predictions will transfer successfully to physical robots and the VR annotations will prove accurate and consistent enough to train a generalizable model.
What would settle it
Measure whether success rate remains near 73% when the trained GPS model is tested on a held-out set of objects from new part classes or when the heuristic policy is run on physical robots with varied lighting and initial states.
Figures




read the original abstract
We are surrounded by various objects with movable, articulated parts, e.g., box, handle, door. An accurate and generalizable perception of articulated parts is essential to enhance robotic manipulation capabilities. Building on this need, recent efforts in articulated parts perception have followed two main directions: One line of work uses pose-based representation, which requires high manual cost; in parallel, affordance-based methods extract future object motion from point tracking without additional manual efforts, but suffer from low-quality data. In this paper, we propose a new representation of articulated parts, Geometric Primary Structure (GPS), an abstraction of the part geometry structure to balance scalability and quality. For efficient and scalable data collection, GPS is integrated with a portable Virtual Reality (VR) device and requires only one minute to annotate one object sequence. This direct human annotation provides higher quality than the estimated affordance. With this efficient VR-GPS system, we collect 41K frames for 234 objects across six part classes, and train a generalizable GPS model with a single RGB-D object image as input. For object manipulation, we deploy a heuristic policy based on GPS prediction. Without any in-domain fine-tuning, our method achieves an 73% success rate, covering 270 initial states for 9 objects. Our code, data and reusable tool are available at https://enlighten0707.github.io/gps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Geometric Primary Structure (GPS) as a new abstraction of articulated part geometry that balances scalability and annotation quality. It integrates GPS with VR for efficient data collection (41K frames, 234 objects, 6 part classes), trains a model to predict GPS from a single RGB-D image, and deploys an unspecified heuristic policy to achieve 73% success on 270 initial states across 9 held-out objects with no in-domain fine-tuning.
Significance. If the empirical claims hold after proper evaluation, the work offers a practical middle ground between costly pose annotations and noisy affordance tracking, with public release of code, data, and tools as an additional strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the 73% success rate on 270 states is reported without baselines, error bars, ablation studies on the heuristic policy, or any quantitative comparison to prior pose-based or affordance-based methods, so the contribution of the GPS representation itself cannot be isolated.
- [Abstract / Results] Deployment paragraph (abstract and results): the heuristic policy derived from GPS predictions is never defined (no pseudocode, equations, or parameter values), and no robustness analysis to GPS prediction noise on real RGB-D images is provided; this is load-bearing for the no-fine-tuning generalization claim.
- [Data Collection] Data collection section: the claim that VR-GPS annotations are higher quality than affordance estimates is stated but unsupported by any inter-annotator agreement metrics, comparison experiments, or error statistics on the collected 41K frames.
minor comments (2)
- [Abstract] Abstract: 'covering 270 initial states for 9 objects' should explicitly state the success metric (e.g., fraction of trials where the articulated part reaches the target configuration) and the number of trials per state.
- [Method] Notation: the distinction between GPS as a geometric abstraction versus the learned predictor should be clarified with a short formal definition or diagram in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical evaluation and data quality claims. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 73% success rate on 270 states is reported without baselines, error bars, ablation studies on the heuristic policy, or any quantitative comparison to prior pose-based or affordance-based methods, so the contribution of the GPS representation itself cannot be isolated.
Authors: We agree that the reported success rate would be strengthened by explicit baselines and statistical reporting to better isolate the GPS contribution. In the revised manuscript we will add quantitative comparisons against a representative pose-based method and an affordance-based method, include error bars computed over repeated trials, and provide ablations on the heuristic policy. These results will be summarized in the abstract and detailed in the results section. revision: yes
-
Referee: [Abstract / Results] Deployment paragraph (abstract and results): the heuristic policy derived from GPS predictions is never defined (no pseudocode, equations, or parameter values), and no robustness analysis to GPS prediction noise on real RGB-D images is provided; this is load-bearing for the no-fine-tuning generalization claim.
Authors: We acknowledge that the heuristic policy must be explicitly specified for reproducibility and to support the generalization claim. In the revision we will add pseudocode, the governing equations, and all parameter values in the methods section. We will also include a robustness analysis that measures performance degradation under controlled noise injected into the GPS predictions on real RGB-D inputs. revision: yes
-
Referee: [Data Collection] Data collection section: the claim that VR-GPS annotations are higher quality than affordance estimates is stated but unsupported by any inter-annotator agreement metrics, comparison experiments, or error statistics on the collected 41K frames.
Authors: The statement reflects that VR-GPS uses direct human annotation while affordance methods rely on indirect estimation; however, we did not collect inter-annotator agreement or quantitative error statistics during the 41K-frame collection. In revision we will qualify the claim to focus on the direct-annotation nature of the process and add qualitative side-by-side examples, while removing any unsupported quantitative superiority language. revision: partial
Circularity Check
No circularity in empirical pipeline or claims
full rationale
The paper defines GPS as a new abstraction, collects fresh VR-annotated data (41K frames, 234 objects), trains a model on RGB-D input, and reports an empirical 73% success rate for a heuristic policy on 270 held-out states across 9 objects with no in-domain fine-tuning. This success metric is measured on newly collected real-robot data and does not reduce to any fitted parameter, self-defined quantity, or self-citation chain inside the paper. No equations, uniqueness theorems, or ansatzes are invoked that would make the reported result equivalent to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RGB-D images contain sufficient geometric information to recover part structure
invented entities (1)
-
Geometric Primary Structure (GPS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Affordances from human videos as a versatile representation for robotics
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13778–13790, 2023. 2, 3, 8
2023
-
[2]
The ycb object and model set: Towards common benchmarks for manipula- tion research
Berk Calli, Arjun Singh, Aaron Walsman, Siddhartha Srini- vasa, Pieter Abbeel, and Aaron M Dollar. The ycb object and model set: Towards common benchmarks for manipula- tion research. In2015 international conference on advanced robotics (ICAR), pages 510–517. IEEE, 2015. 3
2015
-
[3]
Sirui Chen, Chen Wang, Kaden Nguyen, Li Fei-Fei, and C Karen Liu. Arcap: Collecting high-quality human demon- strations for robot learning with augmented reality feedback. arXiv preprint arXiv:2410.08464, 2024. 4, 12
arXiv 2024
-
[4]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, page 02783649241273668, 2023
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, page 02783649241273668, 2023. 8
2023
-
[5]
3d affordancenet: A benchmark for visual object af- fordance understanding
Shengheng Deng, Xun Xu, Chaozheng Wu, Ke Chen, and Kui Jia. 3d affordancenet: A benchmark for visual object af- fordance understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1778–1787, 2021. 3
2021
-
[6]
Anygrasp: Robust and efficient grasp perception in spa- tial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and efficient grasp perception in spa- tial and temporal domains.IEEE Transactions on Robotics, 39(5):3929–3945, 2023. 2, 6, 7
2023
-
[7]
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Chenxi Wang, Junbo Wang, Haoyi Zhu, and Cewu Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 653–660. IEEE,
-
[8]
Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981
Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. 13
1981
-
[9]
Stephanie Fu, Mark Hamilton, Laura Brandt, Axel Feldman, Zhoutong Zhang, and William T Freeman. Featup: A model- agnostic framework for features at any resolution.arXiv preprint arXiv:2403.10516, 2024. 5
arXiv 2024
-
[10]
Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts
Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang, and He Wang. Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7081–7091, 2023. 2, 3, 6
2023
-
[11]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 2
2022
-
[12]
Onepose++: Keypoint-free one- shot object pose estimation without cad models.Advances in Neural Information Processing Systems, 35:35103–35115,
Xingyi He, Jiaming Sun, Yuang Wang, Di Huang, Hujun Bao, and Xiaowei Zhou. Onepose++: Keypoint-free one- shot object pose estimation without cad models.Advances in Neural Information Processing Systems, 35:35103–35115,
-
[13]
Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes
Stefan Hinterstoisser, Stefan Holzer, Cedric Cagniart, Slobo- dan Ilic, Kurt Konolige, Nassir Navab, and Vincent Lepetit. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. In2011 international conference on computer vision, pages 858–865. IEEE, 2011. 3
2011
-
[14]
Cap-net: A unified network for 6d pose and size estimation of categorical articulated parts from a single rgb-d image
Jingshun Huang, Haitao Lin, Tianyu Wang, Yanwei Fu, Xi- angyang Xue, and Yi Zhu. Cap-net: A unified network for 6d pose and size estimation of categorical articulated parts from a single rgb-d image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11654– 11664, 2025. 5, 6, 8
2025
-
[15]
Ditto: Building digital twins of articulated objects from interaction
Zhenyu Jiang, Cheng-Chun Hsu, and Yuke Zhu. Ditto: Building digital twins of articulated objects from interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5616–5626, 2022. 2, 12
2022
-
[16]
Robo-abc: Affordance gener- alization beyond categories via semantic correspondence for robot manipulation
Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Min- grun Jiang, and Huazhe Xu. Robo-abc: Affordance gener- alization beyond categories via semantic correspondence for robot manipulation. InEuropean Conference on Computer Vision, pages 222–239. Springer, 2024. 3
2024
-
[17]
Sampling-based algo- rithms for optimal motion planning.The international jour- nal of robotics research, 30(7):846–894, 2011
Sertac Karaman and Emilio Frazzoli. Sampling-based algo- rithms for optimal motion planning.The international jour- nal of robotics research, 30(7):846–894, 2011. 7
2011
-
[18]
Justin Kerr, Chung Min Kim, Mingxuan Wu, Brent Yi, Qianqian Wang, Ken Goldberg, and Angjoo Kanazawa. Robot see robot do: Imitating articulated object manipu- lation with monocular 4d reconstruction.arXiv preprint arXiv:2409.18121, 2024. 2, 3, 12
arXiv 2024
-
[19]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 8
Pith/arXiv arXiv 2024
-
[20]
Category-level articulated ob- ject pose estimation
Xiaolong Li, He Wang, Li Yi, Leonidas J Guibas, A Lynn Abbott, and Shuran Song. Category-level articulated ob- ject pose estimation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3706–3715, 2020. 2, 3, 13
2020
-
[21]
Paris: Part-level reconstruction and motion analysis for articulated objects
Jiayi Liu, Ali Mahdavi-Amiri, and Manolis Savva. Paris: Part-level reconstruction and motion analysis for articulated objects. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 352–363, 2023. 2, 3, 12
2023
-
[22]
Akb-48: A real-world articulated object knowledge base
Liu Liu, Wenqiang Xu, Haoyuan Fu, Sucheng Qian, Qiao- jun Yu, Yang Han, and Cewu Lu. Akb-48: A real-world articulated object knowledge base. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14809–14818, 2022. 2, 3
2022
-
[23]
Trace any- thing: Representing any video in 4d via trajectory fields
Xinhang Liu, Yuxi Xiao, Donny Y Chen, Jiashi Feng, Yu- Wing Tai, Chi-Keung Tang, and Bingyi Kang. Trace any- thing: Representing any video in 4d via trajectory fields. arXiv preprint arXiv:2510.13802, 2025. 2, 3, 6
arXiv 2025
-
[24]
Hoi4d: A 4d egocentric dataset for category-level human- object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category-level human- object interaction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 21013–21022, 2022. 2, 3, 5
2022
-
[25]
Taco: Benchmarking gener- alizable bimanual tool-action-object understanding
Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxiang Zhang, Yebin Liu, and Li Yi. Taco: Benchmarking gener- alizable bimanual tool-action-object understanding. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21740–21751, 2024. 2, 3
2024
-
[26]
Artgs: Building interactable repli- cas of complex articulated objects via gaussian splatting
Yu Liu, Baoxiong Jia, Ruijie Lu, Junfeng Ni, Song-Chun Zhu, and Siyuan Huang. Artgs: Building interactable repli- cas of complex articulated objects via gaussian splatting. arXiv preprint arXiv:2502.19459, 2025. 2, 3, 12
arXiv 2025
-
[27]
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021. 3
Pith/arXiv arXiv 2021
-
[28]
The rbo dataset of articulated objects and interactions.The International Journal of Robotics Research, 38(9):1013– 1019, 2019
Roberto Martín-Martín, Clemens Eppner, and Oliver Brock. The rbo dataset of articulated objects and interactions.The International Journal of Robotics Research, 38(9):1013– 1019, 2019. 3
2019
-
[29]
Partnet: A large- scale benchmark for fine-grained and hierarchical part-level 3d object understanding
Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. Partnet: A large- scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 909–918, 2019. 2, 3
2019
-
[30]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 5
2017
-
[31]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 5
2021
-
[32]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:24...
Pith/arXiv arXiv 2024
-
[33]
Understanding human hands in contact at inter- net scale
Dandan Shan, Jiaqi Geng, Michelle Shu, and David F Fouhey. Understanding human hands in contact at inter- net scale. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9869–9878,
-
[34]
igibson 1.0: A simulation environment for interactive tasks in large realistic scenes
Bokui Shen, Fei Xia, Chengshu Li, Roberto Martín-Martín, Linxi Fan, Guanzhi Wang, Claudia Pérez-D’Arpino, Shya- mal Buch, Sanjana Srivastava, Lyne Tchapmi, et al. igibson 1.0: A simulation environment for interactive tasks in large realistic scenes. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7520–7527. IEEE, 2021. 3
2021
-
[35]
Least-squares estimation of transforma- tion parameters between two point patterns.IEEE Trans- actions on pattern analysis and machine intelligence, 13(4): 376–380, 2002
Shinji Umeyama. Least-squares estimation of transforma- tion parameters between two point patterns.IEEE Trans- actions on pattern analysis and machine intelligence, 13(4): 376–380, 2002. 13
2002
-
[36]
Rise: 3d perception makes real-world robot imitation simple and effective
Chenxi Wang, Hongjie Fang, Hao-Shu Fang, and Cewu Lu. Rise: 3d perception makes real-world robot imitation simple and effective. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2870–2877. IEEE, 2024. 8, 14
2024
-
[37]
Normalized object coordinate space for category-level 6d object pose and size estimation
He Wang, Srinath Sridhar, Jingwei Huang, Julien Valentin, Shuran Song, and Leonidas J Guibas. Normalized object coordinate space for category-level 6d object pose and size estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2642–2651,
-
[38]
Shape of motion: 4d reconstruc- tion from a single video.arXiv preprint arXiv:2407.13764,
Qianqian Wang, Vickie Ye, Hang Gao, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruc- tion from a single video.arXiv preprint arXiv:2407.13764,
-
[39]
Foundationpose: Unified 6d pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17868– 17879, 2024. 1
2024
-
[40]
Any-point trajectory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning.arXiv preprint arXiv:2401.00025, 2023. 2
Pith/arXiv arXiv 2023
-
[41]
Symbol-llm: leverage language models for symbolic system in visual human activity reasoning.Advances in neural in- formation processing systems, 36:29680–29691, 2023
Xiaoqian Wu, Yong-Lu Li, Jianhua Sun, and Cewu Lu. Symbol-llm: leverage language models for symbolic system in visual human activity reasoning.Advances in neural in- formation processing systems, 36:29680–29691, 2023. 2
2023
-
[42]
Sapien: A simulated part-based interactive environment
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097– 11107, 2020. 2, 3
2020
-
[43]
Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025. 2
arXiv 2025
-
[44]
Chengbo Yuan, Chuan Wen, Tong Zhang, and Yang Gao. General flow as foundation affordance for scalable robot learning.arXiv preprint arXiv:2401.11439, 2024. 2, 3, 6, 8
arXiv 2024
-
[45]
Oakink2: A dataset of bimanual hands-object manipulation in complex task completion
Xinyu Zhan, Lixin Yang, Yifei Zhao, Kangrui Mao, Han- lin Xu, Zenan Lin, Kailin Li, and Cewu Lu. Oakink2: A dataset of bimanual hands-object manipulation in complex task completion. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 445–456, 2024. 2, 3
2024
-
[46]
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jam- pani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming- Hsuan Yang. Monst3r: A simple approach for estimat- ing geometry in the presence of motion.arXiv preprint arXiv:2410.03825, 2024. 3 Revisiting Articulated Parts Perception in Robot Manipulation Supplementary Material a) b) c) d) … … Figure 9. ...
Pith/arXiv arXiv 2024
-
[47]
However, our method has unique advantages
Detailed Comparison with Existing Works For pose-based representation, post-processing methods have emerged to reconstruct articulated objects from visual inputs. However, our method has unique advantages. RSRD [18] uses a 4D differentiable part model to re- cover object motions from an object scan and a single monocular video. It is time-consuming. Recon...
-
[48]
The vir- tual point coordinate is in the world frame determined dur- ing each initial configuration
Detailed Dataset Statistics VR-GPS is developed in Unity and deployed on a Meta Quest 3 device, based on the existing work [3]. The vir- tual point coordinate is in the world frame determined dur- ing each initial configuration. During interaction, the rel- ative transformation of the world frame and the headset is recorded. With the fixed transformation ...
-
[49]
Benchmark Details We evaluate the model on two external datasets: HOI4D and RGBD-Art
Geometric Structure Learning 11.1. Benchmark Details We evaluate the model on two external datasets: HOI4D and RGBD-Art. HOI4D has 1.2K frames for Laptop, 1.4K frames for Trashcan, 2.9K frames for Safe, 0.4K frames for Bucket, 2.8K frames for Drawer. RGBD-Art has 1.1K frames for Laptop, 0.6K frames for Trashcan, 0.5K frames for Safe, 1.4K frames for Bucke...
-
[50]
Heuristic Policy We test on 9 objects with diverse appearances
Real Robot Experiments 12.1. Heuristic Policy We test on 9 objects with diverse appearances. Their categories and part classes are: Box (Lid), Document-Box (Lid), Bucket (Handle), Door (Door), Drawer (Drawer), Notebook (Lid-book), Folder (Lid-book), Lamp (Lid-thin), Clapperboard (Lid-thin). We show a random view for each object in Fig 12. The GPS-based he...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.