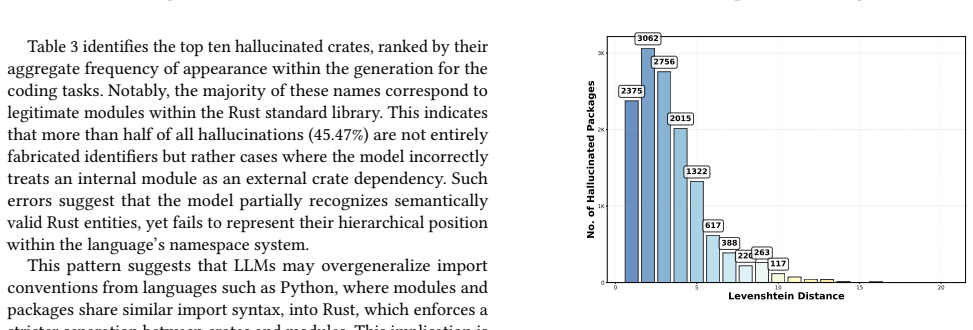
When LLMs Invent Rust Crates: An Empirical Study of Hallucination Patterns and Mitigation
Pith reviewed 2026-06-27 18:21 UTC · model grok-4.3
The pith
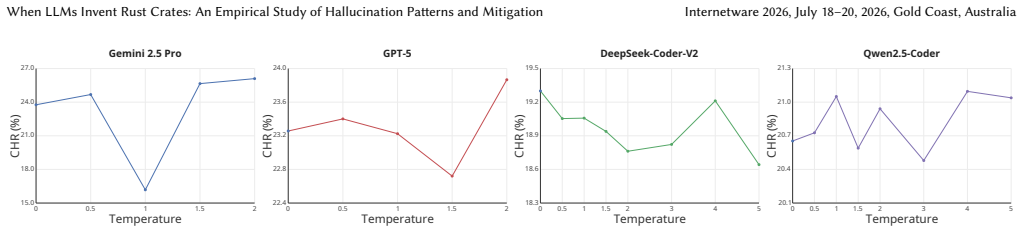
LLM hallucination rates for non-existent Rust crates remain consistent across models and show little change with parameter settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our analysis reveals that, unlike prior findings in Python and JavaScript, hallucination behavior in Rust follows a distinct pattern: different models exhibit surprisingly consistent hallucination rates, and these rates show minimal sensitivity to model parameters. The study evaluates commercial and open-source models on a multi-source dataset and further shows that prompt engineering strategies can mitigate these hallucinations without sacrificing code quality.
What carries the argument
The multi-source dataset of coding tasks from Stack Overflow, GitHub, and LLM-generated sources, used to measure rates of suggested non-existent crates across models and settings.
If this is right
- Prompt engineering can reduce crate hallucinations in Rust code generation while keeping code quality intact.
- LLM-assisted Rust development carries predictable reliability and security implications for the software supply chain.
- Guidance for future research and safer model deployment follows directly from the observed parameter insensitivity.
- Mitigation approaches tested here apply to both commercial and open-source models under standard decoding conditions.
Where Pith is reading between the lines
- If the consistency pattern holds, language-specific hallucination studies may need to treat Rust as a separate category rather than assuming Python-like behavior.
- Security tools that scan for fabricated crates could be calibrated once for multiple models instead of per-model tuning.
- The finding invites direct comparison experiments with other systems languages to test whether the pattern is tied to Rust's crate ecosystem or to something broader.
Load-bearing premise
The dataset built from Stack Overflow, GitHub, and LLM tasks represents typical Rust coding use cases and that all non-existent crates are correctly identified.
What would settle it
Repeating the evaluation on a fresh collection of Rust tasks collected independently from the original sources and finding that hallucination rates now differ substantially across models would falsify the consistency claim.
Figures


read the original abstract
Large Language Models (LLMs) have become powerful tools for code generation, yet they remain prone to hallucinations-producing plausible but incorrect or fabricated outputs. Among these, package hallucination, where an LLM suggests non-existent dependencies, poses an emerging security risk to the software supply chain. While previous studies focus on popular languages like Python or JavaScript, in this work we present the first large-scale empirical study on crate hallucination in LLM-generated Rust code. We construct a multi-source dataset combining coding tasks from Stack Overflow, GitHub, and LLM-generated tasks, and evaluate both commercial and open-source models under various decoding settings. Our analysis reveals that, unlike prior findings in Python and JavaScript, hallucination behavior in Rust follows a distinct pattern: different models exhibit surprisingly consistent hallucination rates, and these rates show minimal sensitivity to model parameters. Furthermore, we investigate prompt engineering strategies to mitigate hallucinations without sacrificing code quality. This study provides new insights into the reliability and security implications of LLM-assisted Rust development, offering guidance for future research and safer model deployment in software engineering workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale empirical study of crate hallucinations in LLM-generated Rust code. It constructs a multi-source dataset from Stack Overflow, GitHub, and LLM-generated tasks, evaluates commercial and open-source models under various decoding settings, and reports that Rust exhibits consistent hallucination rates across models with minimal sensitivity to parameters—unlike prior findings in Python and JavaScript. It also examines prompt engineering strategies for mitigation without sacrificing code quality.
Significance. If the central claims hold after addressing methodological details, the work is significant for identifying language-specific hallucination patterns in code generation, with implications for supply-chain security in Rust. It offers the first dedicated empirical data on Rust crate hallucinations and concrete mitigation guidance, extending the literature beyond Python/JS.
major comments (2)
- [§3] §3 (Dataset Construction): The manuscript provides no quantitative breakdown of task counts or sampling balance across the three sources (Stack Overflow, GitHub, LLM-generated), nor any validation that the tasks represent typical Rust LLM usage. This is load-bearing for the 'distinct pattern' claim, as the observed consistency could be an artifact of task selection rather than a Rust-specific property.
- [§4] §4 (Hallucination Identification): No description is given of the crate-existence verification procedure (e.g., crates.io queries, handling of timing effects, case variants, yanked crates, or contextually inappropriate but real crates). This directly undermines the accuracy of the reported rates and the conclusion of minimal parameter sensitivity.
minor comments (2)
- The abstract and methods should explicitly list the exact decoding parameters tested (temperature, top-p, etc.) and the number of generations per task for reproducibility.
- Add a summary table of hallucination rates by model and setting to visually support the consistency and insensitivity claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on methodological transparency. We address each major point below and will revise the manuscript to incorporate additional details on dataset composition and verification procedures.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The manuscript provides no quantitative breakdown of task counts or sampling balance across the three sources (Stack Overflow, GitHub, LLM-generated), nor any validation that the tasks represent typical Rust LLM usage. This is load-bearing for the 'distinct pattern' claim, as the observed consistency could be an artifact of task selection rather than a Rust-specific property.
Authors: We agree that a quantitative breakdown is required for full transparency and will add it in the revision. Section 3 will include a table reporting exact task counts and proportions from each source (e.g., X from Stack Overflow, Y from GitHub, Z LLM-generated). The sources were selected to capture real developer queries, existing codebases, and controlled synthetic tasks; we will add a paragraph discussing how this mix approximates typical Rust LLM usage based on community reports. While a dedicated user survey on representativeness is outside the current scope, we will note this limitation and argue that the observed cross-model consistency is unlikely to be solely an artifact given the diversity of sources. revision: yes
-
Referee: [§4] §4 (Hallucination Identification): No description is given of the crate-existence verification procedure (e.g., crates.io queries, handling of timing effects, case variants, yanked crates, or contextually inappropriate but real crates). This directly undermines the accuracy of the reported rates and the conclusion of minimal parameter sensitivity.
Authors: We acknowledge the omission and will expand §4 with a dedicated subsection detailing the verification procedure. Crate existence was checked via the crates.io API using exact names from LLM output; queries were performed against a fixed snapshot date to control timing effects. Case variants were normalized to lowercase before lookup. Yanked crates were identified and excluded via the API status field. A crate was counted as real if it existed on crates.io at the snapshot time, even if contextually inappropriate for the task. We will include pseudocode or enumerated steps for reproducibility and discuss any edge cases encountered. revision: yes
Circularity Check
Empirical observational study with no derivations or self-referential modeling
full rationale
This is a purely empirical study that constructs a multi-source dataset from Stack Overflow, GitHub, and LLM-generated tasks, then directly measures hallucination rates across models under varying decoding settings. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the abstract or described methodology. The central claim of a 'distinct pattern' in Rust is presented as an observation from the experiments rather than a reduction to prior self-citations or ansatzes. The analysis is self-contained against external benchmarks (crates.io existence checks, task sources), warranting a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Non-existent crates suggested by LLMs can be reliably identified as hallucinations through external verification.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2408.08333 (2025)
Agarwal, V., Pei, Y., Alamir, S., Liu, X.: Codemirage: Hallucinations in code generated by large language models (2024). arXiv preprint arXiv:2408.08333 (2025)
-
[2]
Al-Zofi, W.: Ai-induced supply-chain compromise: A systematic review of pack- age hallucinations and slopsquatting attacks (2025)
2025
-
[3]
https: //github.com/astral-sh/ruff
Astral: astral-sh/ruff: An extremely fast python linter and code formatter. https: //github.com/astral-sh/ruff. Accessed: 2026-01-22
2026
-
[4]
https://github.com/astral-sh/ty
Astral: astral-sh/ty: An extremely fast python type checker and language server. https://github.com/astral-sh/ty. Accessed: 2026-01-22
2026
-
[5]
https://github.com/astral-sh/uv
Astral: astral-sh/uv: An extremely fast python package and project manager. https://github.com/astral-sh/uv. Accessed: 2026-01-22
2026
-
[6]
Proceedings of the ACM on Programming Languages8(OOPSLA2), 677–708 (2024)
Cassano, F., Gouwar, J., Lucchetti, F., Schlesinger, C., Freeman, A., Anderson, C.J., Feldman, M.Q., Greenberg, M., Jangda, A., Guha, A.: Knowledge transfer from high-resource to low-resource programming languages for code llms. Proceedings of the ACM on Programming Languages8(OOPSLA2), 677–708 (2024)
2024
-
[7]
Evaluating Large Language Models Trained on Code
Chen, M.: Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
and Contributors: denoland/deno: A modern runtime for javascript and typescript
Deno Land Inc. and Contributors: denoland/deno: A modern runtime for javascript and typescript. https://github.com/denoland/deno. Accessed: 2026-01- 22
2026
-
[9]
In: Breakthroughs in statistics: Methodology and distribution, pp
Fisher, R.A.: Statistical methods for research workers. In: Breakthroughs in statistics: Methodology and distribution, pp. 66–70. Springer (1970)
1970
-
[10]
arXiv preprint arXiv:2511.00776 (2025)
Gao, C., Fan, G., Chong, C.Y., Chen, S., Liu, C., Lo, D., Zheng, Z., Liao, Q.: A systematic literature review of code hallucinations in llms: Characterization, mitigation methods, challenges, and future directions for reliable ai. arXiv preprint arXiv:2511.00776 (2025)
-
[11]
https://github.com/
GitHub, Inc.: Github. https://github.com/. Accessed: 2026-01-23
2026
-
[12]
a state of the art review of large generative ai models
Gozalo-Brizuela, R., Garrido-Merchan, E.C.: Chatgpt is not all you need. a state of the art review of large generative ai models. arXiv preprint arXiv:2301.04655 (2023)
-
[13]
ACM Transactions on Information Systems43(2), 1–55 (2025)
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., et al.: A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43(2), 1–55 (2025)
2025
-
[14]
arXiv preprint arXiv:2411.04905 (2024)
Huang, S., Cheng, T., Liu, J.K., Hao, J., Song, L., Xu, Y., Yang, J., Liu, J., Zhang, C., Chai, L., et al.: Opencoder: The open cookbook for top-tier code large language models. arXiv preprint arXiv:2411.04905 (2024)
-
[15]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al.: Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
ACM computing surveys55(12), 1–38 (2023)
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM computing surveys55(12), 1–38 (2023)
2023
-
[17]
A Survey on Large Language Models for Code Generation
Jiang, J., Wang, F., Shen, J., Kim, S., Kim, S.: A survey on large language models for code generation. arXiv preprint arXiv:2406.00515 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., Narasimhan, K.: Swe- bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
arXiv preprint arXiv:2211.15533 , year=
Kocetkov, D., Li, R., Allal, L.B., Li, J., Mou, C., Ferrandis, C.M., Jernite, Y., Mitchell, M., Hughes, S., Wolf, T., et al.: The stack: 3 tb of permissively licensed source code. arXiv preprint arXiv:2211.15533 (2022)
-
[20]
Importing phantoms: Measuring llm package hallucination vulnerabilities,
Krishna, A., Galinkin, E., Derczynski, L., Martin, J.: Importing phantoms: Measur- ing llm package hallucination vulnerabilities. arXiv preprint arXiv:2501.19012 (2025)
-
[21]
In: International Conference on Machine Learning, pp
Lai, Y., Li, C., Wang, Y., Zhang, T., Zhong, R., Zettlemoyer, L., Yih, W.t., Fried, D., Wang, S., Yu, T.: Ds-1000: A natural and reliable benchmark for data science code generation. In: International Conference on Machine Learning, pp. 18319–18345. PMLR (2023)
2023
-
[22]
In: Soviet physics-doklady, vol
Lcvenshtcin, V.: Binary coors capable or ‘correcting deletions, insertions, and reversals. In: Soviet physics-doklady, vol. 10 (1966)
1966
-
[23]
Advances in neural information processing systems33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33, 9459–9474 (2020)
2020
-
[24]
Beyond functional correctness: ex- ploring hallucinations in LLM-generated code,
Liu, F., Liu, Y., Shi, L., Huang, H., Wang, R., Yang, Z., Zhang, L., Li, Z., Ma, Y.: Exploring and evaluating hallucinations in llm-powered code generation. arXiv preprint arXiv:2404.00971 (2024)
-
[25]
Advances in Neural Information Processing Systems36, 21558–21572 (2023)
Liu, J., Xia, C.S., Wang, Y., Zhang, L.: Is your code generated by chatgpt really cor- rect? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems36, 21558–21572 (2023)
2023
-
[26]
StarCoder 2 and The Stack v2: The Next Generation
Lozhkov, A., Li, R., Allal, L.B., Cassano, F., Lamy-Poirier, J., Tazi, N., Tang, A., Pykhtar, D., Liu, J., Wei, Y., et al.: Starcoder 2 and the stack v2: The next generation. arXiv preprint arXiv:2402.19173 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Advances in Neural Information Processing Systems36, 46534–46594 (2023)
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., et al.: Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems36, 46534–46594 (2023)
2023
-
[28]
In: 32nd USENIX Security Sympo- sium (USENIX Security 23), pp
Neupane, S., Holmes, G., Wyss, E., Davidson, D., De Carli, L.: Beyond typosquat- ting: an in-depth look at package confusion. In: 32nd USENIX Security Sympo- sium (USENIX Security 23), pp. 3439–3456 (2023)
2023
-
[29]
In: International Conference on Machine Learning, pp
Orlanski, G., Xiao, K., Garcia, X., Hui, J., Howland, J., Malmaud, J., Austin, J., Singh, R., Catasta, M.: Measuring the impact of programming language distribution. In: International Conference on Machine Learning, pp. 26619–26645. PMLR (2023)
2023
-
[30]
arXiv preprint arXiv:2406.17910 (2024)
Pandey, R., Singh, P., Wei, R., Shankar, S.: Transforming software development: Evaluating the efficiency and challenges of github copilot in real-world projects. arXiv preprint arXiv:2406.17910 (2024)
-
[31]
URL https://blog.rust-lang.org/2025/09/24/crates.io-malicious-crates-fasterlog- and-asyncprintln/
Pearce, W.: crates.io: Malicious crates faster_log and async_println (2025). URL https://blog.rust-lang.org/2025/09/24/crates.io-malicious-crates-fasterlog- and-asyncprintln/. Rust Blog. Walter Pearce on behalf of the crates.io team. Updated Sept. 24, 2025
2025
-
[32]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
Peng, S., Kalliamvakou, E., Cihon, P., Demirer, M.: The impact of ai on developer productivity: Evidence from github copilot. arXiv preprint arXiv:2302.06590 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
https://docs.pola.rs/
Polars Contributors: Polars user guide. https://docs.pola.rs/. Accessed: 2026-01-22
2026
-
[34]
Ravi, R., Bradshaw, D., Ruberto, S., Jahangirova, G., Terragni, V.: Llmloop: Improv- ing llm-generated code and tests through automated iterative feedback loops. ICSME. IEEE (2025)
2025
-
[35]
Authorea Preprints (2025)
Ray, P.P.: A review on vibe coding: Fundamentals, state-of-the-art, challenges and future directions. Authorea Preprints (2025)
2025
-
[36]
https://doc.rust-lang.org/stable/ nightly-rustc
Rust Project: Crate rustc_middle (nightly-rustc). https://doc.rust-lang.org/stable/ nightly-rustc. Accessed: 2026-01-22
2026
-
[37]
arXiv preprint arXiv:2512.09088 (2025)
Ryser, A., Allwein, F., Schlippe, T.: Calibrated trust in dealing with llm hallucina- tions: A qualitative study. arXiv preprint arXiv:2512.09088 (2025)
-
[38]
Multimedia Tools and Applications84(21), 23661–23700 (2025)
Sengar, S.S., Hasan, A.B., Kumar, S., Carroll, F.: Generative artificial intelligence: a systematic review and applications. Multimedia Tools and Applications84(21), 23661–23700 (2025)
2025
-
[39]
In: 34th USENIX Security Symposium (USENIX Security 25), pp
Spracklen, J., Wijewickrama, R., Sakib, A.N., Maiti, A., Viswanath, B.: We have a package for you! a comprehensive analysis of package hallucinations by code generating {LLMs}. In: 34th USENIX Security Symposium (USENIX Security 25), pp. 3687–3706 (2025)
2025
-
[40]
https://stackoverflow.com/
Stack Exchange, Inc.: Stack overflow. https://stackoverflow.com/. Accessed: 2026-01-23
2026
-
[41]
https: //github.com/swc-project/swc
SWC Contributors: swc-project/swc: Rust-based platform for the web. https: //github.com/swc-project/swc. Accessed: 2026-01-22
2026
-
[42]
https://doc.rust-lang
The Rust Project Developers: The rust standard library. https://doc.rust-lang. org/std/. Accessed: 2026-01-22
2026
-
[43]
URL https://doc.rust-lang.org/stable/book/
The Rust Project Developers: The rust programming language (2026). URL https://doc.rust-lang.org/stable/book/
2026
-
[44]
In: Proceedings of the AAAI Conference on Artificial Intelligence, vol
Tian, Y., Yan, W., Yang, Q., Zhao, X., Chen, Q., Wang, W., Luo, Z., Ma, L., Song, D.: Codehalu: Investigating code hallucinations in llms via execution-based verifica- tion. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, pp. 25300–25308 (2025) Internetware 2026, July 18–20, 2026, Gold Coast, Australia Jieming Zheng, Hao Guan, ...
2025
-
[45]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
Tonmoy, S., Zaman, S., Jain, V., Rani, A., Rawte, V., Chadha, A., Das, A.: A compre- hensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.013136(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and- digital-threats/slopsquatting-when-ai-agents-hallucinate-malicious-packages (2025)
Trend Micro Research: Slopsquatting: When ai agents hallucinate malicious packages. https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and- digital-threats/slopsquatting-when-ai-agents-hallucinate-malicious-packages (2025). Accessed: 2025-08-20
2025
-
[47]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Yu, J., Lin, X., Yu, Z., Xing, X.: Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts, 2024. ArXiv, abs/2309.10253
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Computational Linguistics pp
Zhang, Y., Li, Y., Cui, L., Cai, D., Liu, L., Fu, T., Huang, X., Zhao, E., Zhang, Y., Chen, Y., et al.: Siren’s song in the ai ocean: A survey on hallucination in large language models. Computational Linguistics pp. 1–46 (2025)
2025
-
[49]
Proceedings of the ACM on Software Engineering2(ISSTA), 481–503 (2025)
Zhang, Z., Wang, C., Wang, Y., Shi, E., Ma, Y., Zhong, W., Chen, J., Mao, M., Zheng, Z.: Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation. Proceedings of the ACM on Software Engineering2(ISSTA), 481–503 (2025)
2025
-
[50]
Hfuzzer: Testing large language models for package hallucinations via phrase-based fuzzing,
Zhao, Y., Wu, M., Hu, X., Xia, X.: Hfuzzer: Testing large language models for package hallucinations via phrase-based fuzzing. arXiv preprint arXiv:2509.23835 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.