FlashCP: Load-Balanced Communication-Efficient Context Parallelism for LLM Training
Pith reviewed 2026-06-27 18:09 UTC · model grok-4.3
The pith
FlashCP combines Whole-Doc sharding with a heuristic search to eliminate redundant KV communication and balance workloads in context-parallel LLM training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
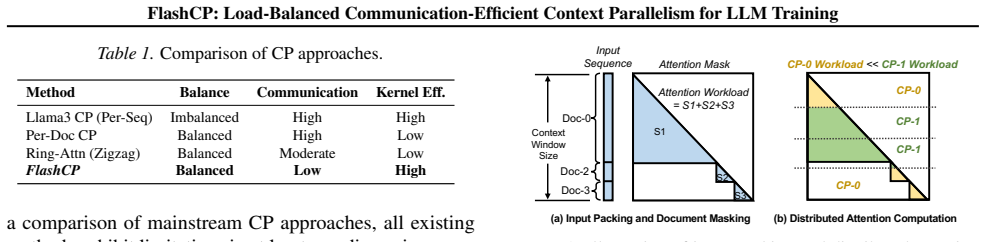
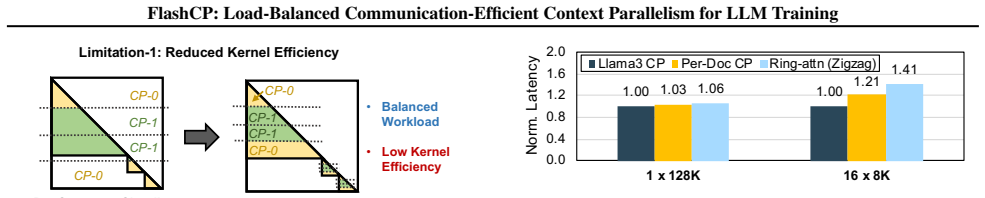
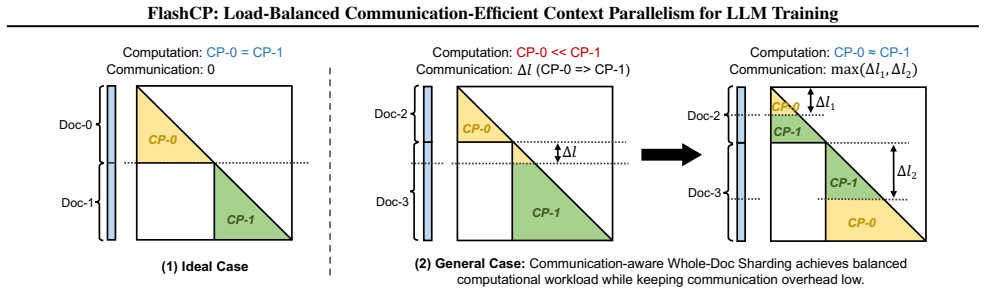
FlashCP achieves load-balanced and communication-efficient context parallelism through a sharding-aware communication mechanism that removes redundant KV tensor traffic, a Whole-Doc sharding strategy that maximizes communication savings under balanced loads, and a heuristic algorithm that searches for near-optimal combinations of Whole-Doc and Per-Doc sharding plans.
What carries the argument
Whole-Doc sharding strategy paired with sharding-aware communication and a heuristic search for mixed sharding plans.
If this is right
- KV tensor communication volume drops because the sharding-aware mechanism avoids sending unchanged data across sequence partitions.
- Device utilization stays even because the Whole-Doc strategy and heuristic together enforce workload balance.
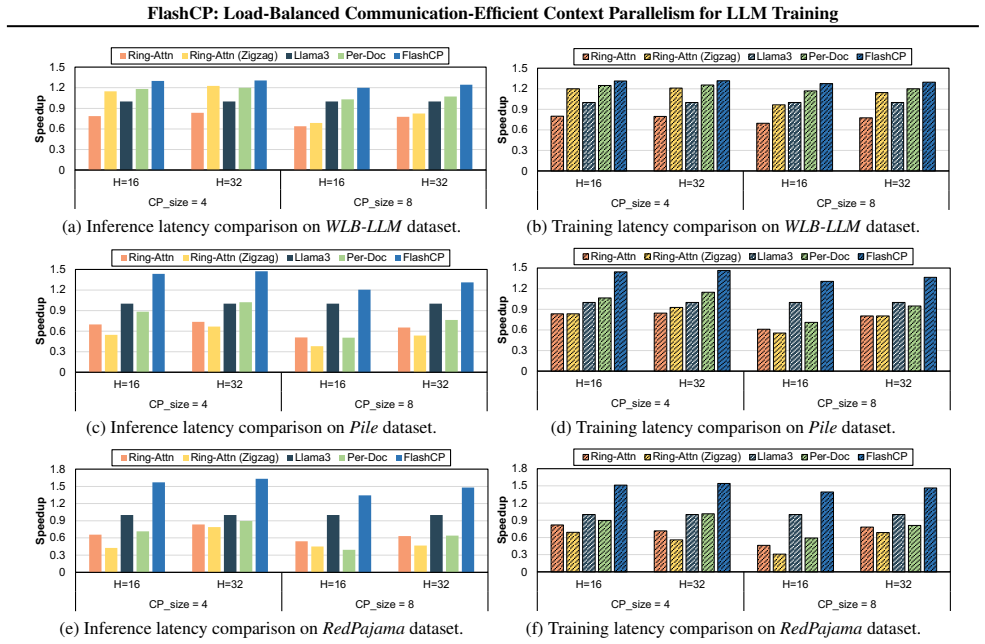
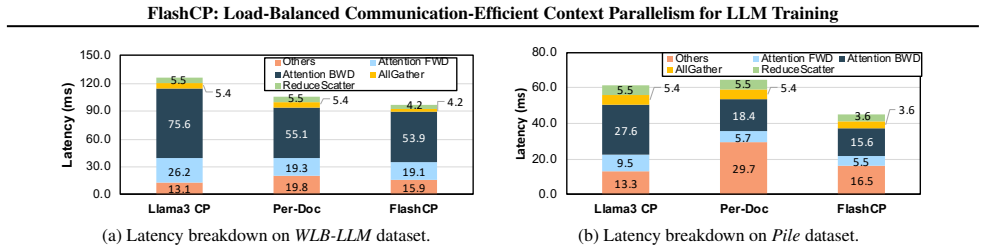
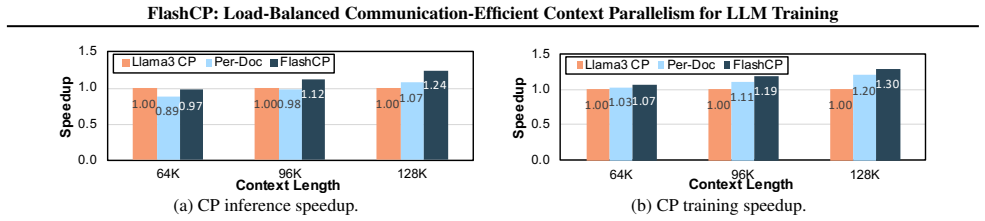
- End-to-end training time improves by up to 1.63 times across datasets when the searched plans are applied.
- The same framework can be reused on new model sizes or context lengths by re-running the heuristic on the target workload.
Where Pith is reading between the lines
- If the heuristic generalizes, similar search methods could be applied to other distributed training dimensions such as pipeline or tensor parallelism.
- Lower communication overhead might allow longer context lengths to be trained on the same number of GPUs without adding hardware.
- The load-balancing guarantee could reduce the engineering effort needed to tune CP for new model architectures.
Load-bearing premise
The heuristic algorithm can reliably locate near-optimal combinations of Whole-Doc and Per-Doc sharding that simultaneously maximize communication savings and keep workloads balanced.
What would settle it
A workload where the heuristic returns a plan whose measured communication volume or per-device load imbalance exceeds that of a hand-tuned baseline would show the central claim does not hold.
Figures

read the original abstract
Context parallelism (CP) is essential for training large-scale, long-context language models, as it partitions sequences to reduce memory overhead. However, existing CP methods suffer from workload imbalance, inefficient kernels, and redundant communication due to static sequence sharding and key-value (KV) tensor communication. We present FlashCP, a load-balanced and communication-efficient framework for CP training. FlashCP introduces a sharding-aware communication mechanism to eliminate redundant KV communication and proposes a novel Whole-Doc sharding strategy that maximizes communication savings while maintaining balanced workloads. To efficiently combine Whole-Doc and Per-Doc sharding, FlashCP further designs a heuristic algorithm to search for near-optimal sharding plans. Extensive experiments show that FlashCP achieves up to 1.63x speedup over state-of-the-art CP frameworks across diverse datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlashCP, a load-balanced and communication-efficient framework for context parallelism (CP) in LLM training. It introduces a sharding-aware communication mechanism to eliminate redundant KV tensor communication, a Whole-Doc sharding strategy to maximize communication savings while maintaining workload balance, and a heuristic algorithm to search for near-optimal combinations of Whole-Doc and Per-Doc sharding. The central claim is that these techniques yield up to 1.63x speedup over state-of-the-art CP frameworks across diverse datasets.
Significance. If the speedup claims hold under properly documented baselines, hardware, and statistical controls, the work could offer a practical advance in scaling long-context LLM training by reducing communication overhead without sacrificing load balance. The heuristic search for sharding plans is a potentially reusable contribution if its correctness and efficiency are demonstrated.
major comments (2)
- [Abstract] Abstract: the central performance claim of up to 1.63x speedup supplies no information on baselines, dataset sizes, hardware configuration, or statistical significance, preventing evaluation of the result.
- [Heuristic algorithm] Heuristic algorithm section: the claim that the heuristic reliably locates near-optimal Whole-Doc/Per-Doc combinations rests on an unverified assumption; without pseudocode, complexity analysis, or ablation on search quality versus exhaustive enumeration, the load-balancing guarantee cannot be assessed.
minor comments (1)
- All experimental setups (baselines, hardware, dataset statistics, number of runs) must be described in the main text or a dedicated appendix section.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to clarify our contributions. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of up to 1.63x speedup supplies no information on baselines, dataset sizes, hardware configuration, or statistical significance, preventing evaluation of the result.
Authors: We agree that the abstract would be strengthened by additional context. In the revised version we will expand the abstract to explicitly name the baselines (prior CP implementations in Megatron and DeepSpeed), note the sequence lengths and datasets used (up to 128K-token contexts across multiple benchmarks), specify the hardware (8-GPU A100 nodes), and indicate that reported speedups are averages over repeated runs with observed variance. revision: yes
-
Referee: [Heuristic algorithm] Heuristic algorithm section: the claim that the heuristic reliably locates near-optimal Whole-Doc/Per-Doc combinations rests on an unverified assumption; without pseudocode, complexity analysis, or ablation on search quality versus exhaustive enumeration, the load-balancing guarantee cannot be assessed.
Authors: The manuscript presents the heuristic as a practical method for selecting mixed sharding plans, but we acknowledge the absence of the requested supporting material. We will add (1) pseudocode, (2) a complexity analysis of the search procedure, and (3) an ablation that compares heuristic solutions against exhaustive enumeration on small instances, thereby demonstrating that the heuristic consistently finds near-optimal load-balanced plans. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents an engineering framework (sharding strategies + heuristic search) whose central claims are empirical speedups measured on hardware. No equations, fitted parameters, or first-principles derivations appear that could reduce a reported result to its own inputs by construction. The heuristic is described as a search procedure, not a closed-form prediction whose value is forced by the data it is evaluated on. Self-citations, if present, are not load-bearing for the speedup numbers. This matches the reader's assessment that no circular reduction is visible from the supplied material.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774,
-
[2]
Why does the effective context length of llms fall short?arXiv preprint arXiv:2410.18745,
An, C., Zhang, J., Zhong, M., Li, L., Gong, S., Luo, Y ., Xu, J., and Kong, L. Why does the effective context length of llms fall short?arXiv preprint arXiv:2410.18745,
-
[3]
URL https: //doi.org/10.5281/zenodo.5297715. If you use this software, please cite it using these metadata. Computer, T. Redpajama: An open source recipe to reproduce llama training dataset,
-
[4]
URL https://github.com/togethercomputer/ RedPajama-Data. Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783,
-
[5]
The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027,
-
[6]
Ge, H., Feng, J., Huang, Q., Fu, F., Nie, X., Zuo, L., Lin, H., Cui, B., and Liu, X. Bytescale: Efficient scaling of llm training with a 2048k context length on more than 12,000 gpus.arXiv preprint arXiv:2502.21231,
-
[7]
Gu, D., Sun, P., Hu, Q., Huang, T., Chen, X., Xiong, Y ., Wang, G., Chen, Q., Zhao, S., Fang, J., et al. Loong- train: Efficient training of long-sequence llms with head- context parallelism.arXiv preprint arXiv:2406.18485,
-
[8]
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[9]
A., Tanaka, M., Zhang, C., Zhang, M., Song, S
Jacobs, S. A., Tanaka, M., Zhang, C., Zhang, M., Song, S. L., Rajbhandari, S., and He, Y . DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models.arXiv preprint arXiv:2309.14509,
-
[10]
Krell, M. M., Kosec, M., Perez, S. P., and Fitzgibbon, A. Efficient Sequence Packing without Cross-contamination: Accelerating Large Language Models without Impacting Performance.arXiv preprint arXiv:2107.02027,
-
[11]
Kundu, A., Lee, R. D., Wynter, L., Ganti, R. K., and Mishra, M. Enhancing training efficiency using packing with flash attention.arXiv preprint arXiv:2407.09105,
-
[12]
Liu, H., Zaharia, M., and Abbeel, P. Ring Attention with Blockwise Transformers for Near-Infinite Context.arXiv preprint arXiv:2310.01889,
-
[13]
Nijkamp, E., Pang, B., Hayashi, H., Tu, L., Wang, H., Zhou, Y ., Savarese, S., and Xiong, C. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Syn- thesis.arXiv preprint arXiv:2203.13474,
-
[14]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
9 FlashCP: Load-Balanced Communication-Efficient Context Parallelism for LLM Training Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv preprint arXiv:1909.08053,
Pith/arXiv arXiv 1909
-
[15]
M., Hauth, A., Millican, K., et al
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
-
[16]
I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al
Team, G., Georgiev, P., Lei, V . I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al. Gemini 1.5: Unlocking multimodal understand- ing across millions of tokens of context.arXiv preprint arXiv:2403.05530,
-
[17]
Llama 2: Open Foundation and Fine- Tuned Chat Models.arXiv preprint arXiv:2307.09288,
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open Foundation and Fine- Tuned Chat Models.arXiv preprint arXiv:2307.09288,
-
[18]
Wang, S., Wang, G., Wang, Y ., Li, J., Hovy, E., and Guo, C. Packing analysis: Packing is more appropriate for large models or datasets in supervised fine-tuning.arXiv preprint arXiv:2410.08081,
-
[19]
Wang, T., Chen, X., Li, K., Cao, T., Ren, J., and Zhang, Y . Lemo: Enabling less token involvement for more context fine-tuning.arXiv preprint arXiv:2501.09767, 2025a. Wang, Z., Cai, A., Xie, X., Pan, Z., Guan, Y ., Chu, W., Wang, J., Li, S., Huang, J., Cai, C., et al. Wlb-llm: Workload-balanced 4d parallelism for large language model training. In19th USE...
-
[20]
Analysing the impact of sequence composition on language model pre-training
Zhao, Y ., Qu, Y ., Staniszewski, K., Tworkowski, S., Liu, W., Miło´s, P., Wu, Y ., and Minervini, P. Analysing the impact of sequence composition on language model pre-training. arXiv preprint arXiv:2402.13991,
-
[21]
Zhu, T., Liu, Q., Wang, H., Chen, S., Gu, X., Pang, T., and Kan, M.-Y . Skyladder: Better and faster pretrain- ing via context window scheduling.arXiv preprint arXiv:2503.15450,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.