Auditable Graph-Guided Root Cause Analysis for Kubernetes Incidents
Pith reviewed 2026-06-27 18:08 UTC · model grok-4.3
The pith
Graph-guided RCA agent raises root-cause-entity F1 from 0.6087 to 0.9130 on ITBench Kubernetes snapshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
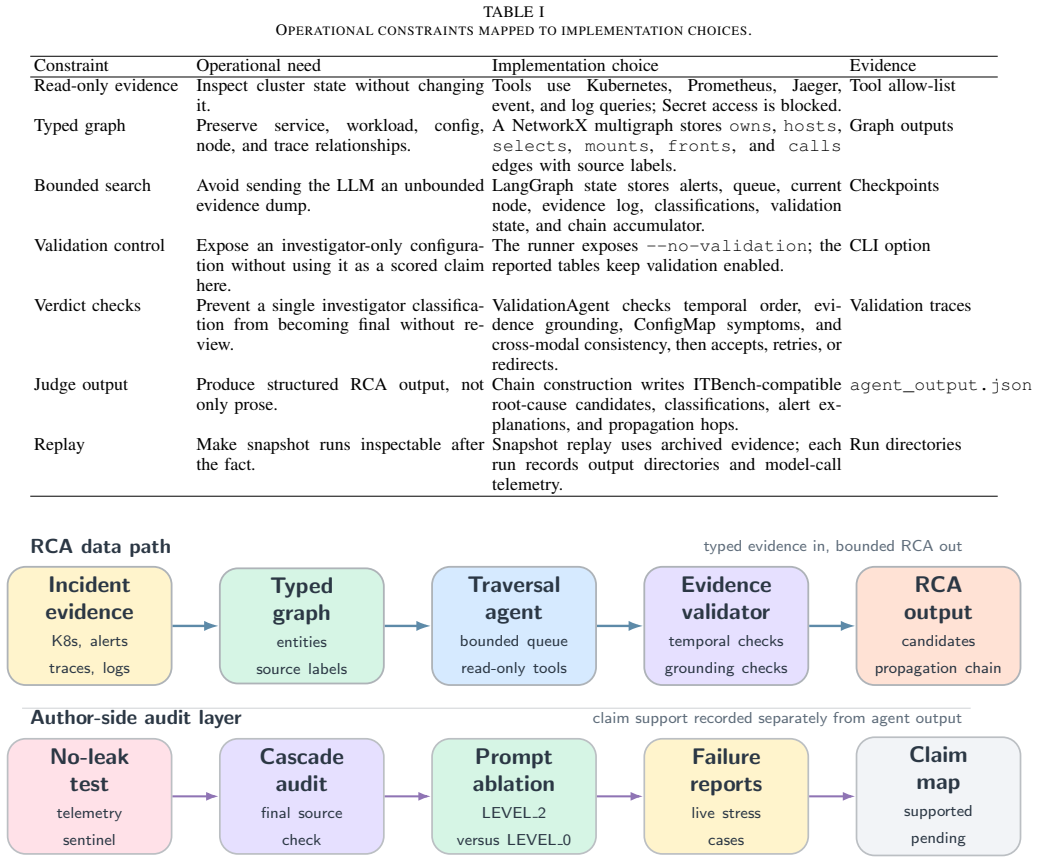
The Graph Traversal Agent reasons over a typed evidence graph while deterministic graph and tool operations collect evidence, bound the search, and check proposed verdicts. We map operational constraints, including read-only evidence collection, propagation-aware diagnosis, bounded execution, and independently validated verdicts, to a typed incident graph, a LangGraph traversal state machine, and a separate validation stage. On ITBench snapshots scored by one fixed qwen-plus judge, the audited system raises root-cause-entity F1 over an earlier iteration of the same system from 0.6087 to 0.9130 on a 23-scenario common subset. A prompt-level ablation separates prompt-tuned gains from gains tha
What carries the argument
Typed incident graph and LangGraph traversal state machine that guide LLM reasoning while deterministic operations collect evidence, bound execution, and validate verdicts.
If this is right
- The audited system achieves 0.9130 root-cause-entity F1 on the 23-scenario common subset.
- Prompt ablation retains 0.6958 F1 on the 19-scenario subset after removal of scenario-specific hints.
- The surviving gain concentrates on ChaosMesh scenarios whose ground-truth root cause is the injected fault object already present in the evidence graph.
- Lightweight checks including same-judge comparison, prompt-level ablation, cascade-source checking, and telemetry no-leak test classify claims as supported, pending, or out of scope.
- Results are scoped to ITBench OpenTelemetry-demo snapshots with no production-readiness or mean-time-to-repair claims.
Where Pith is reading between the lines
- The graph-guided structure with explicit validation stages could be tested on other RCA benchmarks to check whether performance gains generalize beyond ITBench.
- Using multiple independent judges on the same outputs would test whether the F1 lift depends on the particular qwen-plus scorer.
- The concentration of gains on cases where the fault object is already in the graph points to the value of benchmarks that include root causes requiring inference across multiple evidence types.
- The noted instability of alert state and trace data in live clusters indicates an engineering requirement for stable telemetry before controlled production scoring becomes feasible.
Load-bearing premise
The fixed qwen-plus judge model produces stable and unbiased root-cause correctness labels that can be treated as ground truth for F1 measurements across ITBench scenarios.
What would settle it
Re-scoring the same agent outputs on the ITBench scenarios with a different judge model or with human experts and finding no F1 improvement would falsify the reported performance gain.
Figures
read the original abstract
Kubernetes incidents are diagnosed reliably only when a root-cause system's reported gains come from incident evidence rather than scenario-specific shortcuts. We present Graph Traversal Agent, a graph-guided RCA agent that combines LLM reasoning with specialized tools. The model reasons over a typed evidence graph, while deterministic graph and tool operations collect evidence, bound the search, and check proposed verdicts. We map operational constraints, including read-only evidence collection, propagation-aware diagnosis, bounded execution, and independently validated verdicts, to a typed incident graph, a LangGraph traversal state machine, and a separate validation stage. On ITBench snapshots scored by one fixed qwen-plus judge, the audited system raises root-cause-entity F1 over an earlier iteration of the same system from 0.6087 to 0.9130 on a 23-scenario common subset. A prompt-level ablation separates prompt-tuned gains from gains that survive once scenario-specific hints are removed: the stripped-prompt configuration retains 0.6958 F1 on a 19-scenario subset. The surviving gain concentrates on ChaosMesh scenarios whose ground-truth root cause is the injected fault object already present in the evidence graph, so we report it as benchmark-coupled rather than broad cross-cluster RCA evidence. Lightweight checks, including same-judge comparison, prompt-level ablation, cascade-source checking, and a telemetry no-leak test, mark claims as supported, pending, or out of scope. We scope the work to ITBench OpenTelemetry-demo snapshots. Live-cluster trials served as an engineering stress test, but alert state and trace availability did not stay stable enough for controlled scoring, so we make no production-readiness or mean-time-to-repair claim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Graph Traversal Agent, an LLM-driven RCA system for Kubernetes incidents that reasons over a typed evidence graph while using deterministic graph traversal, tool operations, and a separate validation stage to enforce operational constraints such as read-only access and bounded execution. On ITBench snapshots, it reports raising root-cause-entity F1 from 0.6087 to 0.9130 on a 23-scenario common subset (and retaining 0.6958 after prompt ablation on 19 scenarios) when scored by one fixed qwen-plus judge; the surviving gain is localized to ChaosMesh cases whose injected fault object is already present in the graph, and the work explicitly qualifies results as benchmark-coupled rather than general RCA evidence.
Significance. If the judge-based labels are reliable, the approach illustrates how graph guidance plus auditable deterministic components can produce measurable entity-identification gains within a fixed benchmark distribution, while the prompt ablation, cascade-source check, and telemetry no-leak test provide a useful template for scoped empirical claims in LLM agent papers.
major comments (2)
- [Abstract] Abstract and evaluation description: the reported F1 gains (0.6087 o 0.9130, and 0.6958 post-ablation) are computed exclusively against root-cause-entity labels produced by a single fixed qwen-plus instance. No inter-judge agreement statistics, human adjudication, or cross-model consistency results are provided for these labels, which directly affects whether the delta can be attributed to improved RCA logic versus judge-specific preferences for graph-present entities.
- [Abstract] Abstract: the surviving post-ablation gain is stated to concentrate on ChaosMesh scenarios whose ground-truth fault object is already present in the evidence graph. The fraction of the 19- or 23-scenario subsets that exhibit this property should be reported explicitly so readers can assess how much of the measured improvement is explained by test-distribution alignment with the graph-guided design.
minor comments (1)
- [Abstract] The term 'same-judge comparison' appears in the abstract but is not defined; expand this check in the evaluation section so its scope is clear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point by point to the two major comments, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: the reported F1 gains (0.6087 o 0.9130, and 0.6958 post-ablation) are computed exclusively against root-cause-entity labels produced by a single fixed qwen-plus instance. No inter-judge agreement statistics, human adjudication, or cross-model consistency results are provided for these labels, which directly affects whether the delta can be attributed to improved RCA logic versus judge-specific preferences for graph-present entities.
Authors: We agree this is a valid limitation of the evaluation. The single fixed qwen-plus judge was selected to ensure consistent, reproducible scoring when comparing agent configurations. No inter-judge agreement or human adjudication data were collected. In the revised manuscript we will expand the abstract and evaluation description to state this constraint explicitly and to qualify that observed F1 deltas are relative to this judge's labeling behavior rather than an absolute ground truth. revision: yes
-
Referee: [Abstract] Abstract: the surviving post-ablation gain is stated to concentrate on ChaosMesh scenarios whose ground-truth fault object is already present in the evidence graph. The fraction of the 19- or 23-scenario subsets that exhibit this property should be reported explicitly so readers can assess how much of the measured improvement is explained by test-distribution alignment with the graph-guided design.
Authors: We accept the suggestion. Explicit counts will improve transparency about the degree of benchmark coupling. We will revise the abstract to report the exact number and percentage of scenarios (in both the 23-scenario and 19-scenario subsets) that are ChaosMesh cases whose injected fault object is already present in the evidence graph. revision: yes
Circularity Check
No significant circularity; empirical claims are explicitly scoped
full rationale
The paper reports an empirical F1 improvement on ITBench snapshots evaluated by one fixed qwen-plus judge, with explicit ablations and the statement that surviving gains concentrate on ChaosMesh scenarios whose ground-truth root cause is already present in the evidence graph, labeling the result benchmark-coupled rather than broad RCA evidence. No equations, self-definitional mappings, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text that would reduce the reported improvement to its inputs by construction. The system design (graph traversal agent, LangGraph state machine, validation stage) is presented as independent engineering choices, and the evaluation methodology is flagged with lightweight checks and scope limitations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The typed incident graph constructed from OpenTelemetry data contains sufficient evidence for root-cause diagnosis when the fault object is present.
- domain assumption A single fixed LLM judge produces consistent correctness labels that can serve as ground truth for F1 scoring.
invented entities (1)
-
Graph Traversal Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey of AIOps in the era of large language models,
L. Zhang, T. Jia, M. Jia, Y . Wu, A. Liu, Y . Yang, Z. Wu, X. Hu, P. S. Yu, and Y . Li, “A survey of AIOps in the era of large language models,” 2025, arXiv:2507.12472
-
[2]
A goal-driven survey on root cause analysis,
A. Fang, H. Yang, H. Dong, Q. Lu, J. Xu, and P. He, “A goal-driven survey on root cause analysis,” 2025, arXiv:2510.19593
-
[3]
ITBench: Evaluating AI agents across diverse real-world IT automation tasks,
S. Jha, R. Arora, Y . Watanabe, T. Yanagawa, Y . Chen, J. Clark, B. Bhavya, M. Verma, H. Kumar, H. Kitahara, N. Zheutlin, S. Takano, D. Pathak, F. George, X. Wu, B. O. Turkkan, G. Vanloo, M. Nidd, T. Dai, O. Chatterjee, P. Gupta, S. Samanta, P. Aggarwal, R. Lee, P. Murali, J. wook Ahn, D. Kar, A. Rahane, C. Fonseca, A. Paradkar, Y . Deng, P. Moogi, P. Moh...
-
[4]
Mutiny! how does Kubernetes fail, and what can we do about it?
M. Barletta, M. Cinque, C. D. Martino, Z. T. Kalbarczyk, and R. K. Iyer, “Mutiny! how does Kubernetes fail, and what can we do about it?” in Proceedings of the 54th Annual IEEE/IFIP International Conference on Dependable Systems and Networks. Brisbane, Australia: IEEE, 2024, pp. 1–14
2024
-
[5]
Simplifying root cause analysis in Kubernetes with StateGraph and LLM,
Y . Xiang, C. P. Chen, L. Zeng, W. Yin, X. Liu, H. Li, and W. Xu, “Simplifying root cause analysis in Kubernetes with StateGraph and LLM,” 2025, arXiv:2506.02490
-
[6]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inPro- ceedings of the International Conference on Learning Representations, 2023
2023
-
[7]
Automatic root cause analysis via large language models for cloud incidents,
Y . Chen, H. Xie, M. Ma, Y . Kang, X. Gao, L. Shi, Y . Cao, X. Gao, H. Fan, M. Wen, J. Zeng, S. Ghosh, X. Zhang, C. Zhang, Q. Lin, S. Rajmohan, D. Zhang, and T. Xu, “Automatic root cause analysis via large language models for cloud incidents,” 2023, arXiv:2305.15778
-
[8]
RCAgent: Cloud root cause analysis by autonomous agents with tool-augmented large language models,
Z. Wang, Z. Liu, Y . Zhang, A. Zhong, J. Wang, F. Yin, L. Fan, L. Wu, and Q. Wen, “RCAgent: Cloud root cause analysis by autonomous agents with tool-augmented large language models,” inProceedings of the 33rd ACM International Conference on Information and Knowledge Management. ACM, 2024, pp. 4966–4974
2024
-
[9]
COCA: Generative root cause analysis for distributed systems with code knowledge,
Y . Li, Y . Wu, J. Liu, Z. Jiang, Z. Chen, G. Yu, and M. R. Lyu, “COCA: Generative root cause analysis for distributed systems with code knowledge,” 2025, arXiv:2503.23051
-
[10]
PRAXIS: Integrating Program Analysis with Observability for Root-Cause Analysis
S. Cui, R. Krishna, S. Jha, and R. K. Iyer, “PRAXIS: Integrating program analysis with observability for root-cause analysis,” 2026, arXiv:2512.22113
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Flow-of-action: SOP enhanced LLM-based multi-agent system for root cause analysis,
C. Pei, Z. Wang, F. Liu, Z. Li, Y . Liu, X. He, R. Kang, T. Zhang, J. Chen, J. Li, G. Xie, and D. Pei, “Flow-of-action: SOP enhanced LLM-based multi-agent system for root cause analysis,” 2025, arXiv:2502.08224
-
[12]
W. Zhang, H. Guo, J. Yang, Y . Zhang, C. Yan, Z. Tian, H. Ji, Z. Li, T. Li, T. Zheng, C. Chen, Y . Liang, X. Shi, L. Zheng, and B. Zhang, “mABC: Multi-agent blockchain-inspired collaboration for root cause analysis in micro-services architecture,” 2024, arXiv:2404.12135
-
[13]
STRATUS: A multi-agent system for autonomous reliability engineering of modern clouds,
Y . Chen, J. Pan, J. Clark, Y . Su, N. Zheutlin, B. Bhavya, R. Arora, Y . Deng, S. Jha, and T. Xu, “STRATUS: A multi-agent system for autonomous reliability engineering of modern clouds,” 2026, arXiv:2506.02009
-
[14]
Why Do Multi-Agent LLM Systems Fail?
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandran, M. Zaharia, J. E. Gonzalez, and I. Stoica, “Why do multi-agent LLM systems fail?” 2025, arXiv:2503.13657
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Why do AI agents systematically fail at cloud root cause analysis?
T. Kim, W. Park, H. Yun, and K. Lee, “Why do AI agents systematically fail at cloud root cause analysis?” 2026, arXiv:2602.09937
-
[16]
LangGraph: Building stateful, multi-actor applications with language models,
LangChain, “LangGraph: Building stateful, multi-actor applications with language models,” 2024, open-source framework, github.com/langchain- ai/langgraph
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.