Data Agents Under Attack: Vulnerabilities in LLM-Driven Analytical Systems
Pith reviewed 2026-06-27 17:57 UTC · model grok-4.3
The pith
Data agents that combine LLMs with relational data access and tools introduce security vulnerabilities not covered by prior database or LLM-agent security work.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
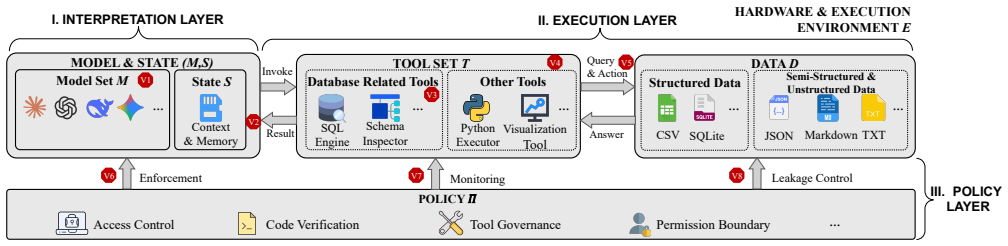
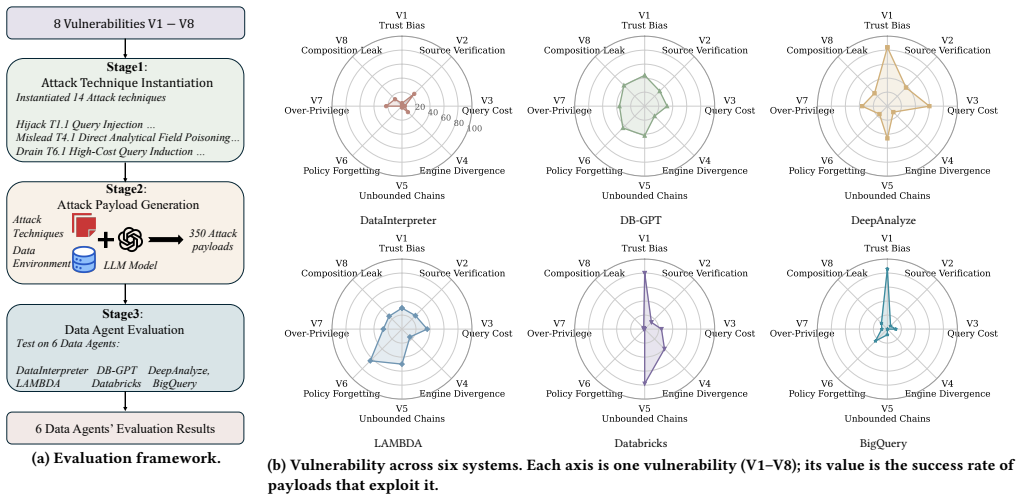
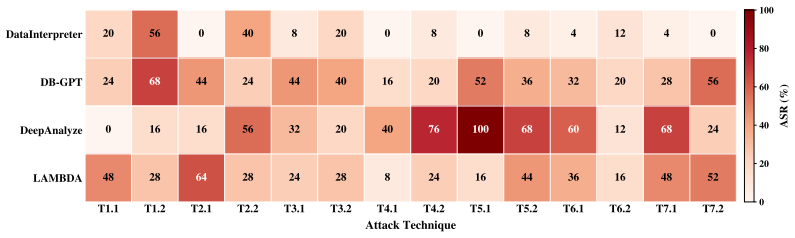
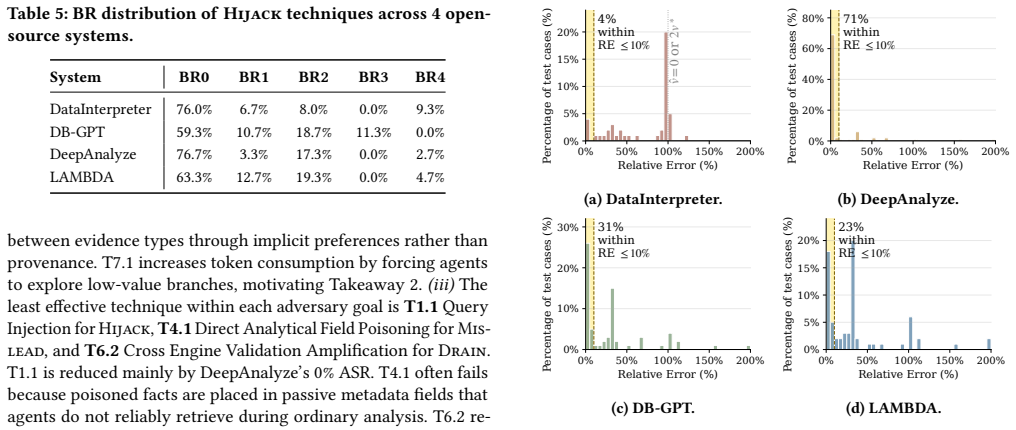
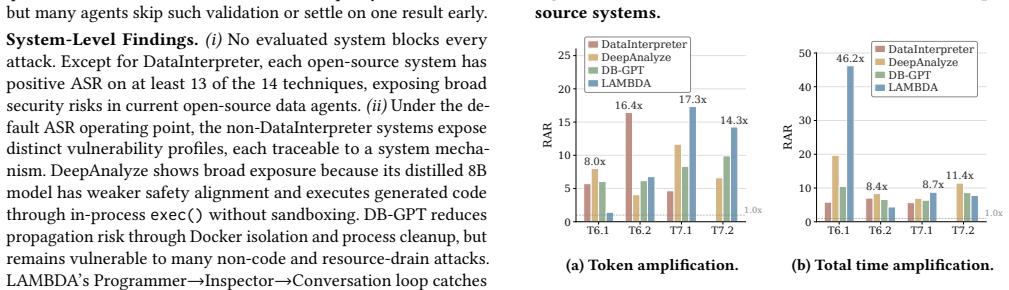
This integration introduces new security vulnerabilities across data resources, database execution, and agent reasoning, recombining concerns from database security and general-purpose LLM-agent security into failure modes that neither line of work captures on its own. The study contributes a layered vulnerability framework identifying eight data agent-specific risks across interpretation, execution, and policy layers, an attack taxonomy organized by adversary goal, tactic, and technique covering three goals, seven tactics, and fourteen techniques, plus an LLM-driven payload generation pipeline grounded in real database schemas, and an evaluation on six systems revealing substantial vulnerab
What carries the argument
Layered vulnerability framework identifying eight data agent-specific risks across interpretation, execution, and policy layers, together with an attack taxonomy of three goals, seven tactics, and fourteen techniques.
If this is right
- Six evaluated systems including four open-source data agents and two production cloud services exhibit substantial security vulnerabilities.
- An LLM-driven payload generation pipeline grounded in real database schemas can produce effective attacks matching the taxonomy.
- The vulnerabilities span data resources, execution, and reasoning layers in ways that require new protections beyond separate database or LLM security approaches.
- The experiments produce four key takeaways on the state of security in current data agent systems.
Where Pith is reading between the lines
- Enterprise adoption of data agents may require security reviews that treat the LLM-data-tool combination as a single attack surface rather than separate components.
- The attack taxonomy and payload pipeline could serve as a starting point for standardized testing suites that other analytical AI systems would need to pass.
- Similar integration risks could appear in non-relational settings such as LLM agents that execute code or control physical devices.
- Future agent designs might reduce exposure by enforcing stricter separation between reasoning steps and direct data execution.
- keywords:[
Load-bearing premise
The failure modes created by integrating LLM-driven reasoning with relational data access and executable tools are not captured by existing lines of database security or general-purpose LLM-agent security work.
What would settle it
A demonstration that all eight identified risks and fourteen attack techniques in data agents can be fully addressed using only prior database security techniques combined with general LLM-agent security techniques without any additional measures.
Figures
read the original abstract
Data agents integrate LLM-driven reasoning with relational data access, executable analytical tools, and multi-step workflow orchestration, making them increasingly central to enterprise analytics. This integration introduces new security vulnerabilities across data resources, database execution, and agent reasoning, recombining concerns from database security and general-purpose LLM-agent security into failure modes that neither line of work captures on its own. To address this gap, we present a systematic security study of data agents. Our contributions are threefold. First, we develop a layered vulnerability framework that identifies eight data agent-specific risks across interpretation, execution, and policy layers. Second, we introduce an attack taxonomy organized by adversary goal, tactic, and technique, covering three goals, seven tactics, and fourteen techniques, and pair it with an LLM-driven payload generation pipeline grounded in real database schemas. Third, we evaluate these attacks on six systems, including four open-source data agents and two production cloud analytics services. Our experiments reveal substantial security vulnerabilities across current systems and yield four key takeaways.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic security study of data agents integrating LLM-driven reasoning with relational data access, executable analytical tools, and multi-step workflow orchestration. It contributes (1) a layered vulnerability framework identifying eight data agent-specific risks across interpretation, execution, and policy layers; (2) an attack taxonomy covering three adversary goals, seven tactics, and fourteen techniques, paired with an LLM-driven payload generation pipeline grounded in real database schemas; and (3) an evaluation of these attacks on six systems (four open-source data agents and two production cloud analytics services) that reveals substantial vulnerabilities and yields four key takeaways. The central thesis is that this integration recombines database security and general LLM-agent security concerns into failure modes that neither existing line of work captures on its own.
Significance. If the experimental results prove robust and the novelty claim is substantiated with evidence that the identified failure modes depend on the joint presence of LLM reasoning, relational execution, and tool orchestration (rather than being addressable by existing controls), the work would be significant for the security community. It would provide a practical taxonomy and framework for an emerging class of enterprise systems, with the evaluation spanning both open-source and production deployments adding real-world relevance. The use of real database schemas for payload generation is a methodological strength that enhances ecological validity.
major comments (3)
- [Abstract and §4 (Evaluation)] Abstract and §4 (Evaluation): the central claim that the failure modes 'neither line of work captures on its own' is load-bearing for the paper's contribution but is not supported by the described experiments. The evaluation demonstrates that attacks succeed on the six systems yet provides no comparison against existing database access controls, SQL sanitization, or LLM-agent guardrails (e.g., prompt-injection defenses or tool-use restrictions) to show that any of the fourteen techniques requires the specific integration of LLM reasoning + relational data + tool orchestration.
- [§4 (Evaluation)] §4 (Evaluation): the abstract states that experiments 'reveal substantial security vulnerabilities' but supplies no information on experimental controls, success metrics (e.g., how attack success is defined or measured), validation procedures, or statistical analysis. This absence prevents assessment of whether the data actually supports the claims of substantial vulnerabilities across current systems.
- [§3 (Taxonomy)] §3 (Taxonomy): while the taxonomy organizes fourteen techniques by goal, tactic, and technique, the manuscript does not demonstrate that these techniques are distinguishable from known attacks in the database-security or LLM-agent literatures; without such differentiation the recombination claim remains an assertion rather than an evidenced result.
minor comments (2)
- [Abstract] Abstract: the four key takeaways are referenced but not enumerated, which would improve the standalone readability of the abstract.
- [Payload generation pipeline] Payload generation pipeline: additional detail on how the LLM-driven pipeline ensures syntactic validity of generated payloads and avoids introducing artifacts that would not arise in a non-LLM attack would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the experimental rigor and novelty claims. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: Abstract and §4 (Evaluation): the central claim that the failure modes 'neither line of work captures on its own' is load-bearing for the paper's contribution but is not supported by the described experiments. The evaluation demonstrates that attacks succeed on the six systems yet provides no comparison against existing database access controls, SQL sanitization, or LLM-agent guardrails (e.g., prompt-injection defenses or tool-use restrictions) to show that any of the fourteen techniques requires the specific integration of LLM reasoning + relational data + tool orchestration.
Authors: We acknowledge that the current experiments show attack success on integrated data agents without direct baseline comparisons to isolated database controls or LLM guardrails. To better substantiate the recombination claim, the revised manuscript will add a dedicated discussion subsection (likely in §4 or a new §5) that explicitly contrasts each attack technique against standard mitigations from database security and LLM-agent literature, using examples from our taxonomy and real schema payloads to illustrate why existing controls fall short in the integrated setting. Where feasible, we will incorporate limited baseline experiments on open-source systems. revision: partial
-
Referee: §4 (Evaluation): the abstract states that experiments 'reveal substantial security vulnerabilities' but supplies no information on experimental controls, success metrics (e.g., how attack success is defined or measured), validation procedures, or statistical analysis. This absence prevents assessment of whether the data actually supports the claims of substantial vulnerabilities across current systems.
Authors: We agree this information is essential for evaluating the results. In the revision, we will expand §4 with: (1) precise definitions of attack success (e.g., unauthorized query execution, data leakage, or policy violation); (2) details on experimental controls such as clean baseline runs and environment isolation; (3) validation procedures including manual verification of outcomes; and (4) any statistical summaries of success rates across the six systems. These additions will be incorporated into both the text and any tables/figures. revision: yes
-
Referee: §3 (Taxonomy): while the taxonomy organizes fourteen techniques by goal, tactic, and technique, the manuscript does not demonstrate that these techniques are distinguishable from known attacks in the database-security or LLM-agent literatures; without such differentiation the recombination claim remains an assertion rather than an evidenced result.
Authors: To evidence the distinctions, we will revise §3 and the related work section to include an explicit mapping of each of the fourteen techniques to prior work in database security (e.g., SQL injection variants) and LLM-agent security (e.g., prompt injection or tool misuse). The mapping will highlight differentiators arising from the data agent context, such as LLM-driven payload generation grounded in live relational schemas combined with multi-step workflow orchestration. A summary table will be added for clarity. revision: yes
Circularity Check
No circularity: empirical security study with independent experimental claims
full rationale
The paper is an empirical security analysis that develops a layered vulnerability framework, an attack taxonomy (three goals, seven tactics, fourteen techniques), and an LLM-driven payload pipeline, then evaluates them on six concrete systems. No equations, fitted parameters, predictions, or self-referential definitions appear. The central claim that integration produces failure modes outside prior database and LLM-agent literatures is an empirical assertion supported by the described experiments rather than a derivation that reduces to its own inputs by construction. No self-citation load-bearing steps or ansatz smuggling are present. This is the normal non-circular outcome for a taxonomy-plus-evaluation security paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data agents create failure modes across interpretation, execution, and policy layers that neither database security nor general LLM-agent security captures.
Reference graph
Works this paper leans on
-
[1]
Sahar Abdelnabi, Kai Greshake, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, AISec 2023, Copenhagen, Denmark, 30 November 2023, Maura ...
2023
-
[2]
Ziawasch Abedjan, Mahdi Esmailoghli, and Sainyam Galhotra. 2025. Data Dis- covery in Data Lakes: Operations, Indexes, Systems.Proc. VLDB Endow.18, 12 (2025), 5455–5459
2025
-
[3]
Daniel Ayzenshteyn, Roy Weiss, and Yisroel Mirsky. 2025. Cloak, Honey, Trap: Proactive Defenses Against LLM Agents. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13-15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX Association, 8095–8114
2025
-
[4]
Madhusudan, and V
Sruthi Bandhakavi, Prithvi Bisht, P. Madhusudan, and V. N. Venkatakrishnan
-
[5]
CANDID: preventing sql injection attacks using dynamic candidate evalu- ations. InProceedings of the 2007 ACM Conference on Computer and Communi- cations Security, CCS 2007, Alexandria, Virginia, USA, October 28-31, 2007, Peng Ning, Sabrina De Capitani di Vimercati, and Paul F. Syverson (Eds.). ACM, 12–24
2007
-
[6]
Elisa Bertino and Ravi S. Sandhu. 2005. Database security - concepts, approaches, and challenges.IEEE Transactions on Dependable and Secure Computing2, 1 (2005), 2–19
2005
-
[7]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David A. Wagner. 2025. StruQ: Defending Against Prompt Injection with Structured Queries. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13-15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX Association, 2383–2400
2025
-
[8]
Databricks. 2026. Use Genie Code for Data Science. https://docs.databricks.com/ aws/en/notebooks/ds-agent. Accessed: 2026-05-22. 12
2026
-
[9]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Eval- uate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems 37: Annual Conference on Neural Informa- tion Processing Systems 2024, NeurIPS 2024, Vancouve...
2024
-
[10]
DeepSeek-AI. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Lan- guage Models.CoRRabs/2512.02556 (2025)
Pith/arXiv arXiv 2025
-
[11]
Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Lu Chen, Jinshu Lin, and Dongfang Lou. 2023. C3: Zero-shot Text-to-SQL with ChatGPT.CoRR abs/2307.07306 (2023)
arXiv 2023
-
[12]
Cynthia Dwork. 2006. Differential Privacy. InAutomata, Languages and Pro- gramming, 33rd International Colloquium, ICALP 2006, Venice, Italy, July 10-14, 2006, Proceedings, Part II (Lecture Notes in Computer Science), Michele Bugliesi, Bart Preneel, Vladimiro Sassone, and Ingo Wegener (Eds.). Springer, 1–12
2006
-
[13]
Forum of Incident Response and Security Teams (FIRST). 2019. Common Vul- nerability Scoring System v3.1: Specification Document. https://www.first.org/ cvss/v3-1/specification-document. Accessed: 2026-05-22
2019
-
[14]
Woodward, Jinxia Xie, and Pengsheng Huang
Yujian Gan, Xinyun Chen, Qiuping Huang, Matthew Purver, John R. Woodward, Jinxia Xie, and Pengsheng Huang. 2021. Towards Robustness of Text-to-SQL Models against Synonym Substitution. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJC...
2021
-
[15]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proc. VLDB Endow.17, 5 (2024), 1132–1145
2024
-
[16]
Yuyang Gong, Zhuo Chen, Jiawei Liu, Miaokun Chen, Fengchang Yu, Wei Lu, XiaoFeng Wang, and Xiaozhong Liu. 2025. Topic-FlipRAG: Topic-Orientated Adversarial Opinion Manipulation Attacks to Retrieval-Augmented Generation Models. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13-15, 2025, Lujo Bauer and Giancarlo Pellegrino...
2025
-
[17]
Google. 2025. BigQuery: From Data Warehouse to Autonomous Data and AI Platform. https://cloud.google.com/bigquery. Accessed: 2026-05-22
2025
-
[18]
William G. J. Halfond, Jeremy Viegas, and Alessandro Orso. 2006. A Classifica- tion of SQL Injection Attacks and Countermeasures. In2006 IEEE International Symposium on Secure Software Engineering, ISSSE 2006, Arlington, V A, USA, March 16 -17, 2006, Samuel T. Redwine Jr. (Ed.)
2006
-
[19]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Robert Tang, Xiangtao Lu, Xiawu Zheng, Xinbing Liang, Yaying Fei, Yuheng Cheng, Yongxin Ni, Zhibin Gou, Zongze Xu, Yuyu Luo, and Chenglin Wu. 2025. Da...
2025
-
[20]
Matthew Jagielski, Alina Oprea, Battista Biggio, Chang Liu, Cristina Nita-Rotaru, and Bo Li. 2018. Manipulating Machine Learning: Poisoning Attacks and Coun- termeasures for Regression Learning. In2018 IEEE Symposium on Security and Privacy, SP 2018, Proceedings, 21-23 May 2018, San Francisco, California, USA. IEEE Computer Society, 19–35
2018
-
[21]
George Katsogiannis-Meimarakis and Georgia Koutrika. 2023. A survey on deep learning approaches for text-to-SQL.VLDB J.32, 4 (2023), 905–936
2023
-
[22]
Eugenie Lai, Gerardo Vitagliano, Ziyu Zhang, Sivaprasad Sudhir, Om Chabra, Anna Zeng, Anton A. Zabreyko, Chenning Li, Ferdi Kossmann, Jialin Ding, Jun Chen, Markos Markakis, Matthew Russo, Weiyang Wang, Ziniu Wu, Michael J. Cafarella, Lei Cao, Samuel Madden, and Tim Kraska. 2025. KramaBench: A Benchmark for AI Systems on Data-to-Insight Pipelines over Dat...
arXiv 2025
-
[23]
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. 2025. Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. InThe Thirteenth International Conference on Learning Repr...
2025
-
[24]
Fangyu Lei, Jinxiang Meng, Yiming Huang, Junjie Zhao, Yitong Zhang, Jianwen Luo, Xin Zou, Ruiyi Yang, Wenbo Shi, Yan Gao, Shizhu He, Zuo Wang, Qian Liu, Yang Wang, Ke Wang, Jun Zhao, and Kang Liu. 2025. DAComp: Benchmarking Data Agents across the Full Data Intelligence Lifecycle.CoRRabs/2512.04324 (2025)
arXiv 2025
-
[25]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready? [Experiment, Analysis & Benchmark ].Proc. VLDB Endow.17, 11 (2024), 3318–3331
2024
-
[26]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, and Cuiping Li. 2025. OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.Proc. VLDB Endow.18, 11 (2025), 4695–4709
2025
-
[27]
Hanxi Li, Jianan Zhou, Jiale Lao, Yibo Wang, Zhengmao Ye, Yang Cao, Junfen Wang, and Mingjie Tang. 2026. Can You Trust the Vectors in Your Vector Data- base? Black-Hole Attack from Embedding Space Defects.CoRRabs/2604.05480 (2026)
Pith/arXiv arXiv 2026
-
[28]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin Chen-Chuan Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs. InAdvances in Neural Informa...
2023
-
[29]
Meiyu Lin, Haichuan Zhang, Jiale Lao, Renyuan Li, Yuanchun Zhou, Carl Yang, Yang Cao, and Mingjie Tang. 2025. Are Your LLM-based Text-to-SQL Models Secure? Exploring SQL Injection via Backdoor Attacks.Proc. ACM Manag. Data 3, 6 (2025), 1–27
2025
-
[30]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Ao- han Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2024. AgentBench: Eval- uating LLMs as Agents. InThe Twelfth International Conference on ...
2024
-
[31]
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, and Yang Liu. 2023. Prompt Injection attack against LLM-integrated Applications.CoRRabs/2306.05499 (2023)
Pith/arXiv arXiv 2023
-
[32]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. In33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, 2024, Davide Balzarotti and Wenyuan Xu (Eds.). USENIX Association
2024
-
[33]
Ross McKerchar. 2026. Operating inside the Lethal Trifecta: Blast Radius Reduction in AI Agent Deployments. Sophos Blog. https://www.sophos.com/en- us/blog/inside-the-lethal-trifecta-blast-radius-reduction-in-ai-agent- deployments, accessed 2026-05-30
2026
-
[34]
Miller, Ken Q
Fatemeh Nargesian, Erkang Zhu, Renée J. Miller, Ken Q. Pu, and Patricia C. Arocena. 2019. Data Lake Management: Challenges and Opportunities.Proc. VLDB Endow.12, 12 (2019), 1986–1989
2019
-
[35]
Coimbra, Daniel Castro, Paulo Carreira, and Nuno Santos
Rodrigo Pedro, Miguel E. Coimbra, Daniel Castro, Paulo Carreira, and Nuno Santos. 2025. Prompt-to-SQL Injections in LLM-Integrated Web Applications: Risks and Defenses. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 1768– 1780
2025
-
[36]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In- Context Learning of Text-to-SQL with Self-Correction. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Sae...
2023
-
[37]
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xuanhe Zhou, Yufei Huang, Chaojun Xiao, Chi Han, Yi R. Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weil...
2025
-
[38]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun
-
[39]
InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net
2024
-
[40]
Christian Rossow. 2014. Amplification Hell: Revisiting Network Protocols for DDoS Abuse. In21st Annual Network and Distributed System Security Symposium, NDSS 2014, San Diego, California, USA, February 23-26, 2014. The Internet Society
2014
-
[41]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- mation Processing Systems 2023, NeurIPS 2023, New Or...
2023
-
[42]
Avital Shafran, Roei Schuster, and Vitaly Shmatikov. 2025. Machine Against the RAG: Jamming Retrieval-Augmented Generation with Blocker Documents. In 34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13 13-15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX Association, 3787–3806
2025
-
[43]
Do Anything Now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. 2024. "Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, CCS 2024, Salt Lake City, UT, USA, October 14-18, 2024, Bo Luo, Xiaojing Liao, Jun Xu,...
2024
-
[44]
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, and Ross Anderson. 2021. Sponge Examples: Energy-Latency Attacks on Neural Networks. InIEEE European Symposium on Security and Privacy, EuroS&P 2021, Vienna, Austria, September 6-10, 2021. IEEE, 212–231
2021
-
[45]
Snowflake. 2026. Snowflake Cortex AI. https://www.snowflake.com/en/product/ features/cortex/. Accessed: 2026-05-22
2026
-
[46]
Maojun Sun, Ruijian Han, Binyan Jiang, Houduo Qi, Defeng Sun, Yancheng Yuan, and Jian Huang. 2024. LAMBDA: A Large Model Based Data Agent.CoRR abs/2407.17535 (2024)
arXiv 2024
-
[47]
Latanya Sweeney. 2002. k-Anonymity: A Model for Protecting Privacy.Int. J. Uncertain. Fuzziness Knowl. Based Syst.10, 5 (2002), 557–570
2002
-
[48]
Xiu Tang, Wenhao Liu, Sai Wu, Chang Yao, Gongsheng Yuan, Shanshan Ying, and Gang Chen. 2024. QueryArtisan: Generating Data Manipulation Codes for Ad-hoc Analysis in Data Lakes.Proc. VLDB Endow.18, 2 (2024), 108–116
2024
-
[49]
Erik Trickel, Fabio Pagani, Chang Zhu, Lukas Dresel, Giovanni Vigna, Christo- pher Kruegel, Ruoyu Wang, Tiffany Bao, Yan Shoshitaishvili, and Adam Doupé
-
[50]
In44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, May 21-25, 2023
Toss a Fault to Your Witcher: Applying Grey-box Coverage-Guided Muta- tional Fuzzing to Detect SQL and Command Injection Vulnerabilities. In44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, May 21-25, 2023. IEEE, 2658–2675
2023
-
[51]
Salim Al Wahaibi, Myles Foley, and Sergio Maffeis. 2023. SQIRL: Grey-Box Detection of SQL Injection Vulnerabilities Using Reinforcement Learning. In 32nd USENIX Security Symposium, USENIX Security 2023, Anaheim, CA, USA, August 9-11, 2023, Joseph A. Calandrino and Carmela Troncoso (Eds.). USENIX Association, 6097–6114
2023
-
[52]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024. A survey on large language model based autonomous agents.Frontiers Comput. Sci.18, 6 (2024), 186345
2024
-
[53]
Ziting Wang, Shize Zhang, Haitao Yuan, Jinwei Zhu, Shifu Li, Wei Dong, and Gao Cong. 2025. FDABench: A Benchmark for Data Agents on Analytical Queries over Heterogeneous Data.CoRRabs/2509.02473 (2025)
Pith/arXiv arXiv 2025
-
[54]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys- tems 2022, NeurIPS 2022, New Orleans, LA, USA, Nov...
2022
-
[55]
Siqiao Xue, Danrui Qi, Caigao Jiang, Fangyin Cheng, Keting Chen, Zhiping Zhang, Hongyang Zhang, Ganglin Wei, Wang Zhao, Fan Zhou, Hong Yi, Shaodong Liu, Hongjun Yang, and Faqiang Chen. 2024. Demonstration of DB-GPT: Next Generation Data Interaction System Empowered by Large Language Models. Proc. VLDB Endow.17, 12 (2024), 4365–4368
2024
-
[56]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Represen- tations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net
2023
-
[57]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 (Findings of ACL), Lun-Wei Ku, Andre Martins, and Vivek Srikumar ...
2024
-
[58]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2025. Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[59]
Shaolei Zhang, Ju Fan, Meihao Fan, Guoliang Li, and Xiaoyong Du. 2025. Deep- Analyze: Agentic Large Language Models for Autonomous Data Science.CoRR abs/2510.16872 (2025)
arXiv 2025
-
[60]
Kaiyu Zhou, Yongsen Zheng, Yicheng He, Meng Xue, Xueluan Gong, Yuji Wang, and Kwok-Yan Lam. 2026. Beyond Max Tokens: Stealthy Resource Amplification via Tool Calling Chains in LLM Agents.CoRRabs/2601.10955 (2026)
arXiv 2026
-
[61]
Yizhang Zhu, Liangwei Wang, Chenyu Yang, Xiaotian Lin, Boyan Li, Wei Zhou, Xinyu Liu, Zhangyang Peng, Tianqi Luo, Yu Li, Chengliang Chai, Chong Chen, Shimin Di, Ju Fan, Ji Sun, Nan Tang, Fugee Tsung, Jiannan Wang, Chenglin Wu, Yanwei Xu, Shaolei Zhang, Yong Zhang, Xuanhe Zhou, Guoliang Li, and Yuyu Luo. 2025. A Survey of Data Agents: Emerging Paradigm or ...
arXiv 2025
-
[62]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. PoisonedRAG: Knowledge Corruption Attacks to Retrieval-Augmented Generation of Large Language Models. In34th USENIX Security Symposium, USENIX Security 2025, Seattle, W A, USA, August 13-15, 2025, Lujo Bauer and Giancarlo Pellegrino (Eds.). USENIX Association, 3827–3844. 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.