How Many Counterfactuals Does It Take? Probing VLM Hallucinations Through Circuits and Causal Effects
Pith reviewed 2026-06-27 18:43 UTC · model grok-4.3
The pith
A causal influence metric yields bounds on the minimum number of counterfactual samples needed to detect instability in VLM hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
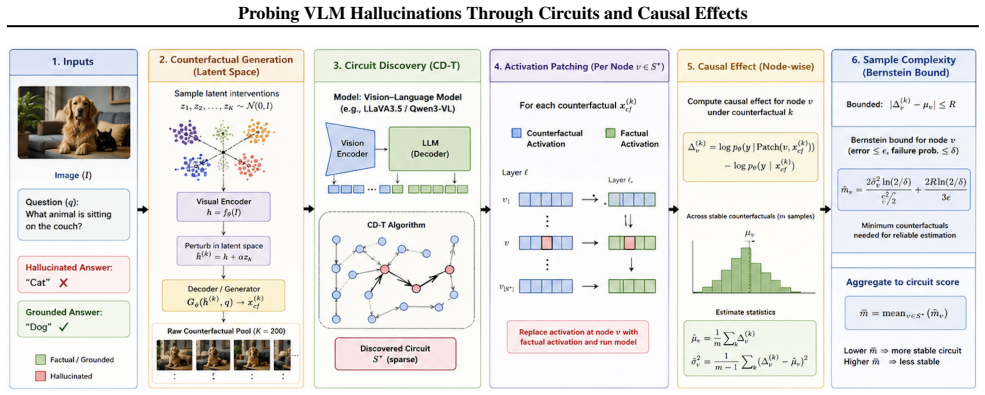
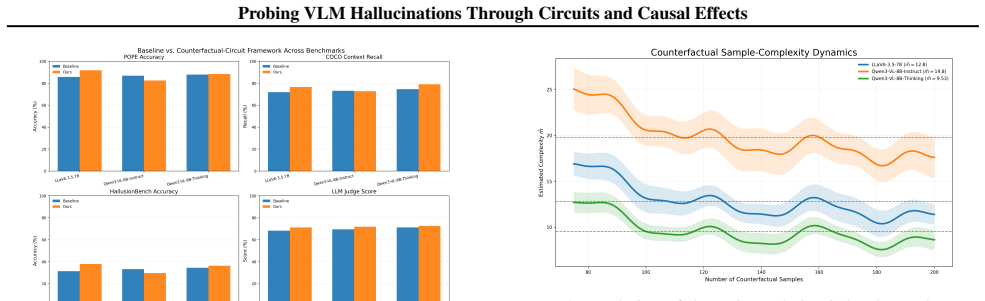
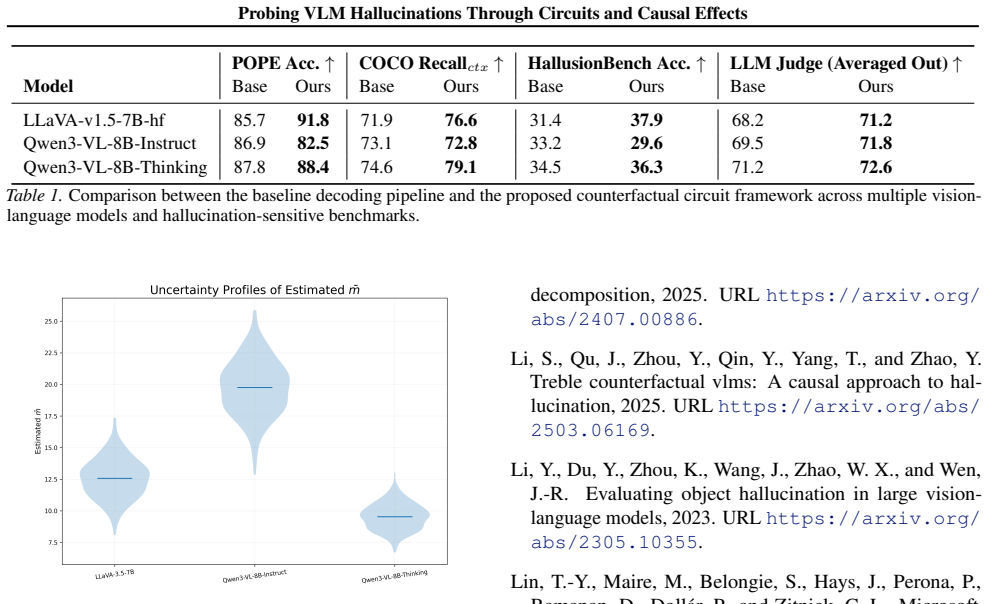
The paper claims that by measuring a causal influence metric on log-probability differences and estimating its variance across samples, concentration inequalities can be used to bound the minimum number m of counterfactual samples needed to detect instability in a VLM's hallucinated output with high probability.
What carries the argument
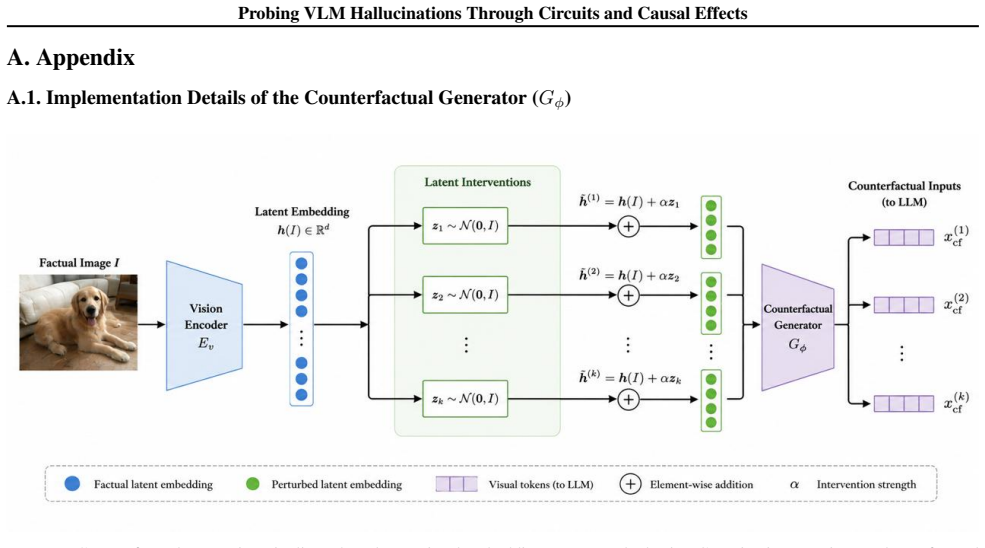
The causal influence metric computed from log-probability differences between factual, counterfactual, and activation-patched runs, applied to components found by circuit discovery (CD-T).
Load-bearing premise
The defined causal influence metric based on log-probability differences and the observed variance of this metric are sufficient to apply concentration inequalities and obtain valid bounds on the required number of samples m.
What would settle it
Running the method on a VLM with a known hallucination and finding that the computed m does not detect the instability when using that many samples, or that the empirical variance leads to bounds that are violated by actual instability rates.
Figures
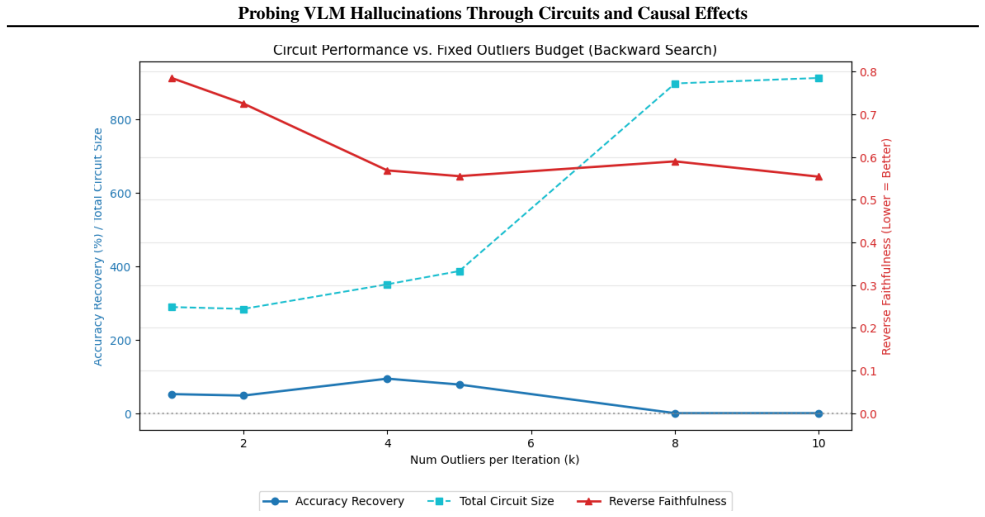
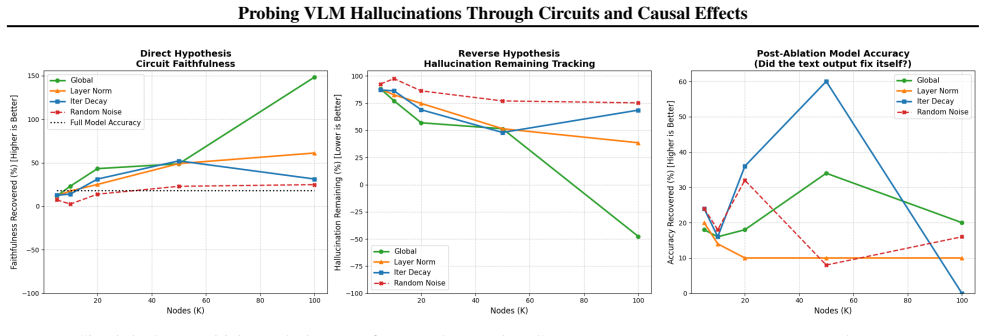
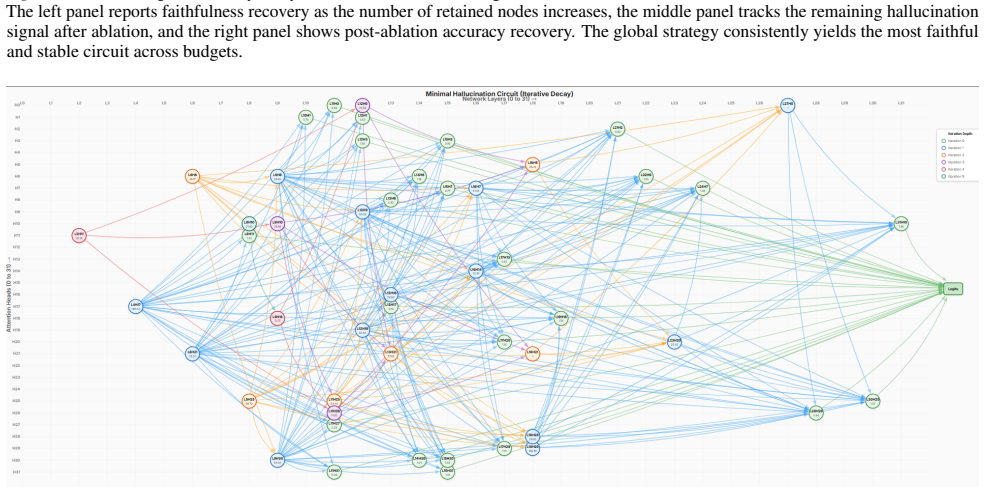
read the original abstract
Visual Language Models (VLMs) are known to produce hallucinated predictions that are not grounded in visual evidence, yet existing approaches lack a principled understanding of how robust such predictions are under counterfactual perturbations. In this work, we study the sample complexity of counterfactual robustness for hallucinated outputs in VLMs. We define a causal influence metric based on log-probability differences between factual, counterfactual, and activation-patched runs, and use it to characterize the stability of hallucinated predictions. By leveraging circuit discovery techniques (CD-T), we identify model components responsible for these predictions and track their activation differences across counterfactual samples. We then derive empirical bounds on the minimum number of counterfactual samples m required to reliably detect instability in hallucinated outputs, using concentration inequalities and variance estimates of the causal influence distribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines a causal influence metric based on log-probability differences between factual, counterfactual, and activation-patched runs in VLMs to characterize stability of hallucinated predictions. It applies circuit discovery (CD-T) to identify responsible model components and derives empirical bounds on the minimum number m of counterfactual samples needed to reliably detect instability, using concentration inequalities together with variance estimates of the causal influence distribution.
Significance. If the bounds hold, the work supplies a sample-complexity analysis for counterfactual robustness testing of VLM hallucinations, which could inform more reliable evaluation protocols and component-level interventions in multimodal models.
major comments (2)
- [Abstract] Abstract: the central claim that concentration inequalities applied to observed variance of the causal influence metric yield valid, non-vacuous bounds on m is presented without derivation details, validation experiments, error analysis, or checks against post-hoc selection of runs; this prevents verification that the metric satisfies the tail conditions (sub-Gaussianity or bounded moments) required by Hoeffding/Bernstein-type inequalities.
- [Derivation of bounds on m] The section deriving the bounds on m: variance estimates are obtained from the same counterfactual runs used to claim the bound, raising a circularity concern; without an independent argument or separate validation set that the metric's distribution meets the inequality preconditions, the resulting m may be optimistically small.
minor comments (1)
- Clarify whether the causal influence metric is computed on the same samples used for variance estimation or on held-out data.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the concerns about the abstract presentation and the derivation of bounds on m below, and we will make revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that concentration inequalities applied to observed variance of the causal influence metric yield valid, non-vacuous bounds on m is presented without derivation details, validation experiments, error analysis, or checks against post-hoc selection of runs; this prevents verification that the metric satisfies the tail conditions (sub-Gaussianity or bounded moments) required by Hoeffding/Bernstein-type inequalities.
Authors: We agree the abstract is high-level and omits supporting details. The full derivation appears in Section 4, applying Bernstein's inequality after empirical variance estimation from the causal influence scores. We did not include explicit tail-condition validation or post-hoc selection analysis in the original submission. We will add a new subsection with empirical CDF plots against sub-Gaussian references, error bounds, and discussion of run selection to allow verification. revision: yes
-
Referee: [Derivation of bounds on m] The section deriving the bounds on m: variance estimates are obtained from the same counterfactual runs used to claim the bound, raising a circularity concern; without an independent argument or separate validation set that the metric's distribution meets the inequality preconditions, the resulting m may be optimistically small.
Authors: The circularity concern is valid: variance is computed from the same counterfactual samples. While the bounds are presented as empirical rather than strict theoretical guarantees, we will revise Section 4 to use a two-stage approach with a held-out pilot set for variance estimation (or bootstrap resampling) before applying the concentration inequality on the primary set. This provides a clearer separation and reduces optimism in the reported m. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper claims to derive empirical bounds on m via concentration inequalities applied to variance estimates of a causal influence metric defined from log-probability differences. The abstract and context provide no equations, self-citations, or explicit reductions showing that the variance estimates are taken from the identical runs in a manner that forces the bound by construction (e.g., no fitted parameter renamed as prediction or self-definitional loop). No load-bearing self-citation chains, uniqueness theorems, or ansatz smuggling appear. The method is presented as an empirical estimation procedure whose validity rests on standard concentration results rather than internal redefinition, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The causal influence metric based on log-probability differences between factual, counterfactual, and activation-patched runs accurately reflects stability of hallucinated predictions.
- domain assumption Variance estimates of the causal influence distribution permit direct application of concentration inequalities without additional tail or dependence assumptions.
invented entities (1)
-
Causal influence metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms , author=. 2024 , eprint=
2024
-
[2]
2025 , eprint=
Efficient Automated Circuit Discovery in Transformers using Contextual Decomposition , author=. 2025 , eprint=
2025
-
[3]
2023 , eprint=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. 2023 , eprint=
2023
-
[4]
2022 , eprint=
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small , author=. 2022 , eprint=
2022
-
[5]
2023 , eprint=
Evaluating Object Hallucination in Large Vision-Language Models , author=. 2023 , eprint=
2023
-
[6]
Counterfactual Vision and Language Learning , doi =
Abbasnejad, Ehsan and Teney, Damien and Parvaneh, Amin and Shi, Javen and Hengel, Anton , year =. Counterfactual Vision and Language Learning , doi =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[7]
2025 , eprint=
Treble Counterfactual VLMs: A Causal Approach to Hallucination , author=. 2025 , eprint=
2025
-
[8]
2022 , eprint=
Counterfactual Explanations and Algorithmic Recourses for Machine Learning: A Review , author=. 2022 , eprint=
2022
-
[9]
2024 , eprint=
A Survey on Hallucination in Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[10]
2025 , eprint=
THRONE: An Object-based Hallucination Benchmark for the Free-form Generations of Large Vision-Language Models , author=. 2025 , eprint=
2025
-
[11]
2024 , eprint=
Reducing Hallucinations in Vision-Language Models via Latent Space Steering , author=. 2024 , eprint=
2024
-
[12]
Angelopoulos and Stephen Bates , title =
Anastasios N. Angelopoulos and Stephen Bates , title =. CoRR , volume =. 2021 , url =. 2107.07511 , timestamp =
Pith/arXiv arXiv 2021
-
[13]
A Survey of Confidence Estimation and Calibration in Large Language Models , doi =
Geng, Jiahui and Cai, Fengyu and Wang, Yuxia and Koeppl, Heinz and Nakov, Preslav and Gurevych, Iryna , year =. A Survey of Confidence Estimation and Calibration in Large Language Models , doi =
-
[14]
Hallusionbench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models , year=
Guan, Tianrui and Liu, Fuxiao and Wu, Xiyang and Xian, Ruiqi and Li, Zongxia and Liu, Xiaoyu and Wang, Xijun and Chen, Lichang and Huang, Furong and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi , booktitle=. Hallusionbench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models , year=
-
[15]
Computer Vision--ECCV 2014 , pages=
Microsoft COCO: Common Objects in Context , author=. Computer Vision--ECCV 2014 , pages=. 2014 , organization=
2014
-
[16]
2024 , eprint=
Clip Body and Tail Separately: High Probability Guarantees for DPSGD with Heavy Tails , author=. 2024 , eprint=
2024
-
[17]
The Thirteenth International Conference on Learning Representations , year=
Understanding and mitigating hallucination in large vision-language models via modular attribution and intervention , author=. The Thirteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.