AI-Augmented Closed-Loop Quality Engineering: A Reference Architecture for Continuous Software Quality Intelligence
Pith reviewed 2026-06-27 17:46 UTC · model grok-4.3
The pith
Closed-loop AI architecture reduces defect leakage from 0.19 to 0.13 and shortens test execution by up to 35 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
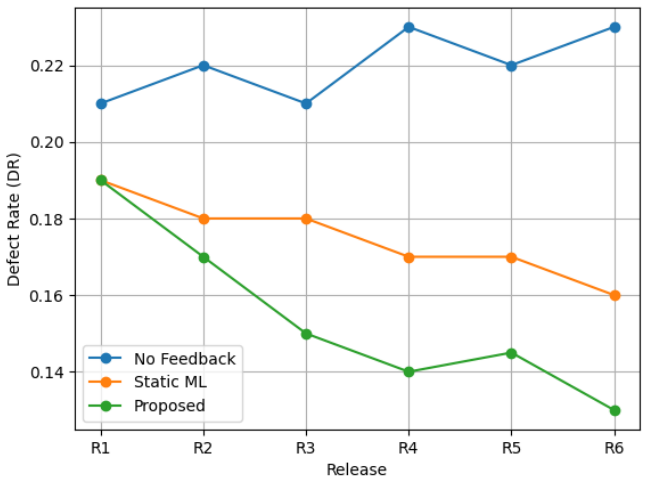
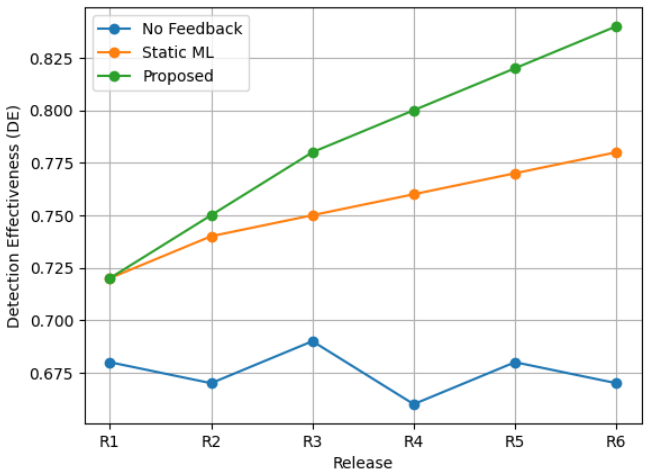
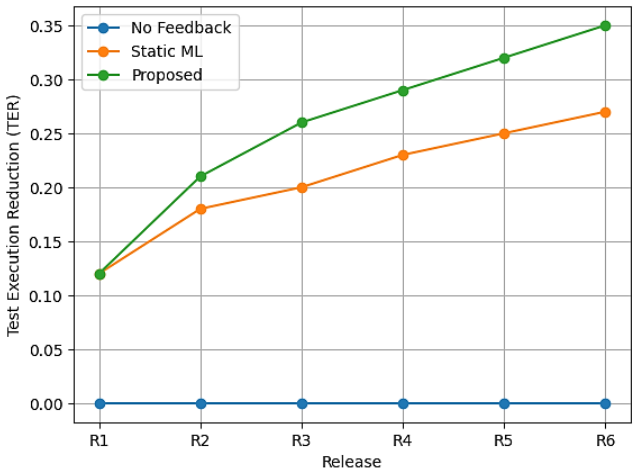
The proposed closed-loop reference architecture for continuous software quality intelligence, augmented by AI, integrates requirement feature mining, risk-based test prioritization, defect prediction, and production incident analysis into a feedback-based pipeline; a limited feedback learning model propagates production signals based on defect severity and incident impact to subsequent releases, yielding defect leakage reduction from 0.19 to 0.13, detection effectiveness increase from 0.72 to 0.84, and test execution shortening by up to 35 percent with stable changes across six release cycles.
What carries the argument
The closed-loop reference architecture with limited feedback learning model that propagates production signals to the following release.
If this is right
- Production signals on severity and impact can be propagated to adjust quality activities in the next release.
- Quality metrics such as defect leakage and detection effectiveness become stable across consecutive releases.
- The feedback integration turns quality engineering into a continuously improving process rather than fixed per release.
- The architecture supplies a practical foundation for adaptive software quality engineering.
Where Pith is reading between the lines
- Validation on live production data from multiple organizations would be needed to confirm the improvements hold beyond the semi-synthetic case.
- The feedback model could be extended to incorporate user behavior or performance metrics not captured in incident reports.
- Integration with reinforcement learning for dynamic prioritization might further reduce test execution time.
Load-bearing premise
The semi-synthetic dataset of 4,500 requirements, 27,049 test cases, 13,089 defects and 7,841 incidents across six release cycles accurately models real-world software development distributions, defect patterns, and production signals.
What would settle it
Applying the architecture to data collected from a real multi-release software project in production and checking whether defect leakage falls to 0.13, detection effectiveness rises to 0.84, and test execution shortens by 35 percent relative to non-adaptive baselines.
Figures
read the original abstract
The quality of software engineering is still under a challenge due to disjointed processes between requirements, testing, and production, which hinders the opportunity to implement quality strategies in consecutive releases. Existing approaches tend to be fixed-model or single-optimization approaches and lack production feedback learning mechanisms. The paper at hand proposes a closed-loop reference architecture of continuous software quality intelligence with AI enhancements. The model synthesizes requirement feature mining, risk-based test prioritization, defect prediction, and production incident analysis as an element of a feedback-based pipeline. A limited feedback learning model is introduced that is used to propagate the production signal-based on defect severity and incident impact- to the following release to ensure stability, and the time. The method is evaluated using a semi-synthetic test dataset of 4,500 requirements, 27,049 test cases, 13,089 defects and 7,841 incidents in six release cycles. The experimental results show that the proposed system reduces the defect leakage by 0.19 to 0.13, increases the effectiveness of the detection system to 0.72 to 0.84, and shortens the test execution by up to 35 percent compared to the non-adaptive baselines. The changes are stable release to release. The findings indicate that through the integration of feedback-based learning in a closed-loop architecture, it can be continued to enhance quality process, which offers practical foundation of adaptive quality engineering of software.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a closed-loop reference architecture for continuous software quality intelligence that integrates AI-enhanced components for requirement feature mining, risk-based test prioritization, defect prediction, and production incident analysis. A limited feedback learning model propagates production signals (based on defect severity and incident impact) to subsequent releases. Evaluation on a semi-synthetic dataset spanning six release cycles demonstrates reductions in defect leakage from 0.19 to 0.13, increases in detection effectiveness from 0.72 to 0.84, and up to 35% shorter test execution times compared to non-adaptive baselines, with stable improvements across releases.
Significance. If the results generalize beyond the semi-synthetic data, the architecture could provide a practical foundation for adaptive quality engineering by closing the loop between development, testing, and production. However, the current evaluation's reliance on an opaque semi-synthetic corpus limits the strength of the claims regarding real-world applicability.
major comments (2)
- [Evaluation] Evaluation section: The semi-synthetic dataset of 4,500 requirements, 27,049 test cases, 13,089 defects and 7,841 incidents is described only by aggregate counts; no generation algorithm, probability model, or external validation against industry traces is provided. This makes it impossible to determine whether the reported improvements (defect leakage 0.19→0.13, detection effectiveness 0.72→0.84, test execution shortened up to 35%) arise from the proposed architecture or from the particular synthesis rules.
- [Abstract and feedback model] Abstract and feedback model description: Details on baseline definitions, statistical tests, error bars, and how the feedback model parameters were set are absent, leaving the central empirical claims without verifiable derivation steps.
minor comments (1)
- [Abstract] Abstract: The phrasing 'shortens the test execution by up to 35 percent compared to the non-adaptive baselines. The changes are stable release to release.' contains minor grammatical issues and could be clarified for precision.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will make the indicated revisions to improve the clarity and verifiability of the evaluation.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The semi-synthetic dataset of 4,500 requirements, 27,049 test cases, 13,089 defects and 7,841 incidents is described only by aggregate counts; no generation algorithm, probability model, or external validation against industry traces is provided. This makes it impossible to determine whether the reported improvements (defect leakage 0.19→0.13, detection effectiveness 0.72→0.84, test execution shortened up to 35%) arise from the proposed architecture or from the particular synthesis rules.
Authors: We agree that the current description of the semi-synthetic dataset is insufficient for independent assessment. In the revised manuscript we will insert a new subsection (Evaluation, 4.1) that specifies the generation algorithm, including the probability distributions for requirement features, defect injection rates, and incident severity drawn from published industry benchmarks (e.g., NASA defect-density studies and IEEE reliability reports). The exact proprietary traces used for calibration cannot be released, but the parameter values and sampling rules will be fully documented so that the synthesis process is reproducible and its influence on the reported gains can be evaluated. revision: yes
-
Referee: [Abstract and feedback model] Abstract and feedback model description: Details on baseline definitions, statistical tests, error bars, and how the feedback model parameters were set are absent, leaving the central empirical claims without verifiable derivation steps.
Authors: We accept that these methodological details are missing. The revised abstract will explicitly define the non-adaptive baselines (identical components without the production-feedback loop). The Evaluation section will be expanded to report (i) the statistical procedure (paired t-tests, α = 0.05, applied to the six release cycles), (ii) error bars on all metrics (already present in the figures but not described in text), and (iii) the feedback-model hyper-parameter selection process (grid search over severity/impact weights performed on the first two releases and frozen thereafter). These additions will make the empirical claims traceable. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a closed-loop reference architecture integrating requirement mining, risk-based prioritization, defect prediction, and production incident analysis with a limited feedback learning model. It evaluates this architecture empirically on a semi-synthetic dataset of 4,500 requirements, 27,049 test cases, 13,089 defects and 7,841 incidents across six release cycles, reporting comparative metrics (defect leakage 0.19→0.13, detection effectiveness 0.72→0.84, test execution shortened up to 35%) against non-adaptive baselines. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The reported gains are presented as evaluation outcomes on the dataset rather than quantities derived by construction from the synthesis process or model fitting. The architecture description remains independent of the specific numerical deltas, satisfying the default expectation of a non-circular empirical architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A comparison among interpretative proposals for random forests. Mach. Learn. Appl. 6, 100094.http://dx.doi.org/10.1016/j.mlwa. 2021.100094. •Arrieta, A., Ayerdi, J., Illarramendi, M., Agirre, A., Sagardui, G., Arratibel, M.,
-
[2]
In: 2021 IEEE/ACM International Conference on Automation of Software Test
Using machine learning to build test oracles: An industrial case study on elevators dispatching algorithms. In: 2021 IEEE/ACM International Conference on Automation of Software Test. AST, pp. 30–39.http://dx.doi.org/10.1109/AST52587.2021.00012. •Barredo Arrieta, A., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., Garcia, S., Gil-Lop...
-
[3]
13 •Herbold, S., Trautsch, A., Trautsch, F., Ledel, B.,
http://dx.doi.org/10.1186/s13040-023-00322-4. 13 •Herbold, S., Trautsch, A., Trautsch, F., Ledel, B.,
-
[4]
Problems with SZZ and features: An empirical study of the state of practice of defect prediction data collection. Empir. Softw. Eng. 27, 42.http://dx.doi.org/10.1007/s10664-021-10092-4. •Hryszko, J., Madeyski, L.,
-
[5]
Cost effectiveness of software defect prediction in an in- dustrial project. Found. Comput. Decision Sci. 43, 7–35.http://dx.doi.org/10.1515/ fcds-2018-0002. •IIBA,2015. Babok: AGuidetotheBusinessAnalysisBodyofKnowledge. InternationalInsti- tuteofBusinessAnalysis. InternationalOrganizationforStandardization,
2018
-
[6]
URLhttps://www.iso
ISO/IEC/IEEE 29119-1:2022 software and systems engineering — software testing. URLhttps://www.iso. org/standard/81291.html. (Accessed 20 December 2022). •Ismail, A.M., Hamid, S.H.A., Sani, A.A., Daud, N.N.M.,
2022
-
[7]
In: 2021 IEEE/ACM 18th In- ternational Conference on Mining Software Repositories
Practitioners’ perceptions of the goals and visual explanations of defect prediction models. In: 2021 IEEE/ACM 18th In- ternational Conference on Mining Software Repositories. MSR, IEEE/ACM, pp. 432–443. http://dx.doi.org/10.1109/MSR52588.2021.00055. •Jing, X.-Y., Chen, H., Xu, B.,
-
[8]
Springer Nature Singapore,http://dx.doi.org/10.1007/978-981-99-2842-2
Intelligent Software Defect Prediction. Springer Nature Singapore,http://dx.doi.org/10.1007/978-981-99-2842-2. •Kawalerowicz, M., Madeyski, L.,
-
[9]
Continuous build outcome prediction: An experimen- tal evaluation and acceptance modelling. Appl. Intell. 53, 8673–8692.http://dx.doi.org/ 10.1007/s10489-023-04523-6. •Kitchenham, B., Madeyski, L., Brereton, P.,
-
[10]
Meta-analysis for families of experiments in software engineering: A systematic review and reproducibility and validity assessment. Empir. Softw. Eng. 25, 353–401.http://dx.doi.org/10.1007/s10664-019-09747-0. •Konstantinov, A.V., Utkin, L.V.,
-
[11]
Interpretable machine learning with an ensemble of gradient boosting machines. Knowl.-Based Syst. 222, 106993.http://dx.doi.org/10.1016/ j.knosys.2021.106993. •Lang, M., Binder, M., Richter, J., Schratz, P., Pfisterer, F., Coors, S., Au, Q., Casalicchio, G., Kotthoff, L., Bischl, B.,
arXiv 2021
-
[12]
mlr3: A modern object-oriented machine learning framework in R. J. Open Source Softw.http://dx.doi.org/10.21105/joss.01903. 14 •Lewowski, T., Madeyski, L.,
-
[13]
How far are we from reproducible research on code smell detection? A systematic literature review. Inf. Softw. Technol. 144, 106783.http://dx. doi.org/10.1016/j.infsof.2021.106783. •Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., Talwalkar, A.,
-
[14]
A systematic literature review on software defect prediction using artificial intelligence: Datasets, data validation methods, approaches, and tools. Eng. Appl. Artif. Intell. 111, 104773.http: //dx.doi.org/10.1016/j.engappai.2022.104773. •Pan, R., Bagherzadeh, M., Ghaleb, T.A., Briand, L.,
-
[15]
Test case selection and priori- tization using machine learning: A systematic literature review. Empir. Softw. Eng. 27, http://dx.doi.org/10.1007/s10664-021-10066-6. •Pandey, S.K., Mishra, R.B., Tripathi, A.K.,
-
[16]
Machine learning based methods for soft- ware fault prediction: A survey. Expert Syst. Appl. 172, 114595.http://dx.doi.org/10. 1016/j.eswa.2021.114595. •Paterson, D., Campos, J., Abreu, R., Kapfhammer, G.M., Fraser, G., McMinn, P.,
arXiv 2021
-
[17]
In: 2019 12th IEEE Conference on Software Testing, Validation and Verification
An empirical study on the use of defect prediction for test case prioritization. In: 2019 12th IEEE Conference on Software Testing, Validation and Verification. ICST, pp. 346–357. http://dx.doi.org/10.1109/ICST.2019.00041. •Pradhan, S., Nanniyur, V., Vissapragada, P.K.,
-
[18]
On the defect prediction for large scale software systems — from defect density to machine learning. In: 2020 IEEE 20th International Conference on Software Quality, Reliability and Security. QRS, pp. 374–381. http://dx.doi.org/10.1109/QRS51102.2020.00056. •Prado Lima, J.A., Vergilio, S.R.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/qrs51102.2020.00056 2020
-
[19]
Test case prioritization in continuous integration environments: A systematic mapping study. Inf. Softw. Technol. 121, 106268.http: //dx.doi.org/10.1016/j.infsof.2020.106268. •Rosa, G., Pascarella, L., Scalabrino, S., Tufano, R., Bavota, G., Lanza, M., Oliveto, R.,
-
[20]
A comprehensive evaluation of SZZ variants through a developer-informed oracle. J. Syst. Softw. 202, 111729.http://dx.doi.org/10.1016/j.jss.2023.111729. •dos Santos, G.E., Figueiredo, E.,
-
[21]
In: 2020 IEEE 20th International Working Conference on Source Code Analysis and Manipulation
Failure of one, fall of many: An exploratory study of software features for defect prediction. In: 2020 IEEE 20th International Working Conference on Source Code Analysis and Manipulation. SCAM, pp. 98–109.http://dx.doi.org/10. 1109/SCAM51674.2020.00016. •Stradowski, S., Madeyski, 2023a. Bridging the gap between academia and industry in machine learning s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.