Few-shot Class-variable Incremental Audio Classification via Prototype Adaptation and Pseudo Class-variable Training
Pith reviewed 2026-06-27 15:26 UTC · model grok-4.3
The pith
A class-variable prototype network lets few-shot audio classifiers handle both growing and shrinking class sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
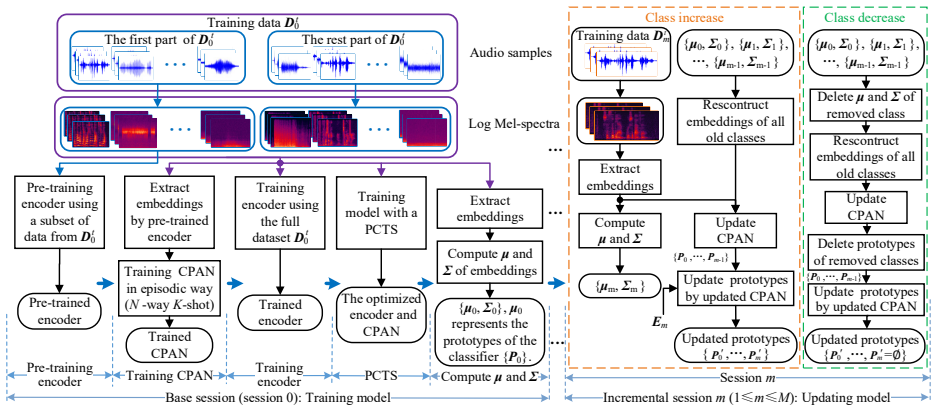
The model consists of an encoder and a classifier; the classifier is initialized by a class-variable prototype adaptation network whose structure dynamically changes with the change of classes, combined with a pseudo class-variable training strategy that enhances adaptability to changing classes, resulting in higher average accuracy than previous methods on three public datasets.
What carries the argument
The class-variable prototype adaptation network, which dynamically alters its structure with changes in class count to initialize the classifier.
If this is right
- Recognition performance is maintained or improved on both added and removed classes.
- Average accuracy exceeds that of prior incremental audio classification methods across the tested datasets.
- The encoder-classifier architecture supports dynamic initialization without full retraining.
- The pseudo training strategy improves the model's response to fluctuating class counts.
Where Pith is reading between the lines
- The same dynamic-prototype idea could be tested on image or text few-shot tasks where class sets also shrink.
- Real-time systems with fluctuating available labels might avoid periodic full retraining by adopting this adaptation pattern.
- The approach raises the question of how far the dynamic structure change can scale before memory or compute costs become prohibitive.
Load-bearing premise
The prototype adaptation network can change its structure when the number of classes changes while still preserving or improving accuracy on both the classes that are added and the classes that are removed.
What would settle it
A controlled test on one of the three public datasets in which classes are removed in a few-shot regime and the method shows no gain or a clear drop in accuracy on the remaining classes compared with a static baseline.
Figures


read the original abstract
In the task of few-shot class-incremental audio classification, the number of classes is assumed to always increase without considering the possibility of decrease. However, the number of classes generally increases or decreases in practice. In this paper, we investigate a problem of Few-shot Class-variable Incremental Audio Classification (FCIAC), in which the number of classes increases or decreases. We propose a FCIAC method using prototype adaptation and pseudo class-variable training. The model in our method consists of an encoder and a classifier. The classifier is initialized by a class-variable prototype adaptation network, whose structure dynamically changes with the change of classes. In addition, we design a pseudo class-variable training strategy to enhance the model's adaptability to changing classes. Experiments on three public datasets show that our method exceeds previous methods in average accuracy. The code is at: https://github.com/cgq2971-afk/FCIAC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Few-shot Class-variable Incremental Audio Classification (FCIAC), a setting where the number of classes can increase or decrease over time (unlike standard class-incremental learning). It proposes an encoder-plus-classifier model whose classifier is initialized via a class-variable prototype adaptation network that dynamically changes structure with class count, plus a pseudo class-variable training strategy to improve adaptability. Experiments on three public datasets are reported to show higher average accuracy than prior methods.
Significance. If the central claims hold under proper validation, the work would extend few-shot incremental audio classification to a more general and practical variable-class-count regime that includes decreases. The dynamic prototype adaptation mechanism could provide a reusable technique for handling structural changes in the classifier without full retraining.
major comments (2)
- [Experiments] The central claim that the method handles both class increases and decreases while preserving performance on removed classes is load-bearing, yet the experimental protocol is not shown to test class-decrease scenarios. Standard incremental-learning benchmarks simulate only sequential addition; if the three-dataset experiments follow that convention, accuracy on removed-class cases remains unmeasured and the weakest assumption is untested.
- [Method] §3 (method description): the claim that the prototype adaptation network 'dynamically alters its structure with the change of classes' while maintaining recognition on both added and removed classes requires explicit description of the structural change mechanism for decreases (e.g., how prototypes are pruned or re-initialized) and whether any retraining or hyper-parameter adjustment is needed; without this, it is unclear whether the reported gains are due to the adaptation or to the pseudo-training strategy alone.
minor comments (2)
- [Abstract] The abstract states that 'the number of classes generally increases or decreases in practice' but provides no citation or reference to prior work on class-decrease scenarios; adding one or two references would clarify the novelty gap.
- [Abstract] The GitHub link is given but the manuscript does not state whether the released code includes the exact dataset splits, class-increment/decrement schedules, and statistical significance tests used in the reported tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The two major comments highlight important points about validating class-decrease scenarios and clarifying the adaptation mechanism. We address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] The central claim that the method handles both class increases and decreases while preserving performance on removed classes is load-bearing, yet the experimental protocol is not shown to test class-decrease scenarios. Standard incremental-learning benchmarks simulate only sequential addition; if the three-dataset experiments follow that convention, accuracy on removed-class cases remains unmeasured and the weakest assumption is untested.
Authors: We agree that explicit testing of class decreases, including accuracy preservation on removed classes, is necessary to fully support the central claim. Our current experiments on the three datasets follow the standard class-incremental protocol of sequential additions. We will add new experiments that simulate class removals (e.g., training on an initial set then removing classes in subsequent stages) and report the corresponding accuracies on removed classes. These results will be included in the revised manuscript. revision: yes
-
Referee: [Method] §3 (method description): the claim that the prototype adaptation network 'dynamically alters its structure with the change of classes' while maintaining recognition on both added and removed classes requires explicit description of the structural change mechanism for decreases (e.g., how prototypes are pruned or re-initialized) and whether any retraining or hyper-parameter adjustment is needed; without this, it is unclear whether the reported gains are due to the adaptation or to the pseudo-training strategy alone.
Authors: We will expand the description in §3 to explicitly detail the structural change mechanism for class decreases. This will include how the class-variable prototype adaptation network prunes or re-initializes the relevant prototypes when classes are removed, and we will clarify that the process operates dynamically with no additional retraining or hyper-parameter adjustments required beyond the existing pseudo class-variable training strategy. This revision will distinguish the contributions of the adaptation network from the training strategy. revision: yes
Circularity Check
No circularity: method and results are independent of inputs by construction
full rationale
The paper introduces a prototype adaptation network whose structure changes with class count and a pseudo class-variable training strategy, then reports empirical accuracies on three public datasets. No equations, definitions, or claims reduce the performance numbers to a fitted quantity or self-citation chain; the adaptation components are presented as novel engineering choices whose value is measured externally. The abstract and method description contain no self-definitional loops, fitted-input predictions, or load-bearing self-citations. This is the normal case of an empirical ML proposal whose central claims rest on independent test-set measurements rather than algebraic identity with the training procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Conventional supervised audio classification methods rely on abundant labeled data [12]-[16] and can recognize the predefined classes only
Introduction Audio classification is a key technique for many multimedia processing tasks, including audio content analysis [1], domestic activity estimation [2], acoustic scene classification [3]-[5], bio- acoustic monitoring [6], [7], a udio-visual video understanding [8], [9], road audio surveillance [10], and speaker diarization [11]. Conventional sup...
-
[2]
We define a FCIAC problem where the number of classes either increases or decreases in incremental sessions
-
[3]
The encoder is trained in the base session and frozen in the incremental sessions
We propose a FCIAC method whose model consists of an encoder and a classifier. The encoder is trained in the base session and frozen in the incremental sessions. The classifier is updated in each incremental session by a Class-variable Prototype Adaptation Network (CPAN) for enhancing the model’s ability to distinguish between various classes
-
[4]
We design a Pseudo Class-va riable Training Strategy (PCTS) in the base session for simulating the model training in the incremental sessions, thereby enhancing the model’s adaptability to the change of classes
-
[5]
Method In this section, we describe the details of our method, including the problem definition, method framework, model architecture, PCTS, and embedding reconstruction. 2.1. Problem Definition The FCIAC aims to continually recognize new classes using few training samples without forgetting the old ones, where the classes can be added or removed in each ...
-
[6]
The classifier consists of prototypes and each prototype is used to represent one class. To ensure that the classifier maintains discriminative deci sion boundaries for all classes after adding or removing classe s, we design a class-variable prototype adaptation networ k that dynamical ly adjusts prototypes in response to both class addition and removal ...
-
[7]
Randomly select two subsets from the 𝑫 ௧ , which will be used to synthesize pseudo-classes
-
[8]
Each sample of pseudo-classes is assigned a label
Sample a mixing coefficient 𝛾~Beta(a, a), where Beta(a, a) denotes a symmetric Beta distribution on [0,1] (centered at 0.5), and generate pseudo-classes samples by mixing up two subsets. Each sample of pseudo-classes is assigned a label
-
[9]
Use encoder to learn embeddings from Sv and Qv
Construct pseudo-class dataset Dv and split Dv into a support set Sv and a query set Qv. Use encoder to learn embeddings from Sv and Qv
-
[10]
Use the APGM to produce the prototypes of current session
-
[11]
Freeze the SAMP, and activate both the PAMP and fusion module
-
[12]
Update all prototypes and adjust the query embeddings via the CPAN
-
[13]
Predict the query labels and compute the cross-entropy loss ℒCE
-
[14]
Update encoder and CPAN by stochastic gradient descent algorithm
-
[15]
Freeze encoder to memorize the learned knowledge of old classes
-
[16]
Randomly discard few prototypes of old classes
-
[17]
Update the remaining classes’ prototypes and their query embeddings via the CPAN
-
[18]
Predict the query labels of the existing-classes’ and compute the ℒCE
-
[19]
Update the CPAN by stochastic gradient descent algorithm
-
[20]
Output:The optimized encoder and CPAN
Repeat the above steps until reaching the maximum training cycles. Output:The optimized encoder and CPAN. 2.5. Embeddings Reconstruction The embeddings of the same class 𝐸={ 𝒆 𝒌}(1≤𝑘≤𝐾 ) are assumed to follow a multivariate Gaussian distribution 𝒩(𝝁, 𝜮). The probability density function is defined by: 𝑃(𝒆𝒌)= 1 (2𝜋)/ଶ∣𝜮∣ ଵ/ଶexp ൬−1 2 (𝒆𝒌 −𝝁 )்𝜮ିଵ(𝒆𝒌 −𝝁 ) ...
-
[21]
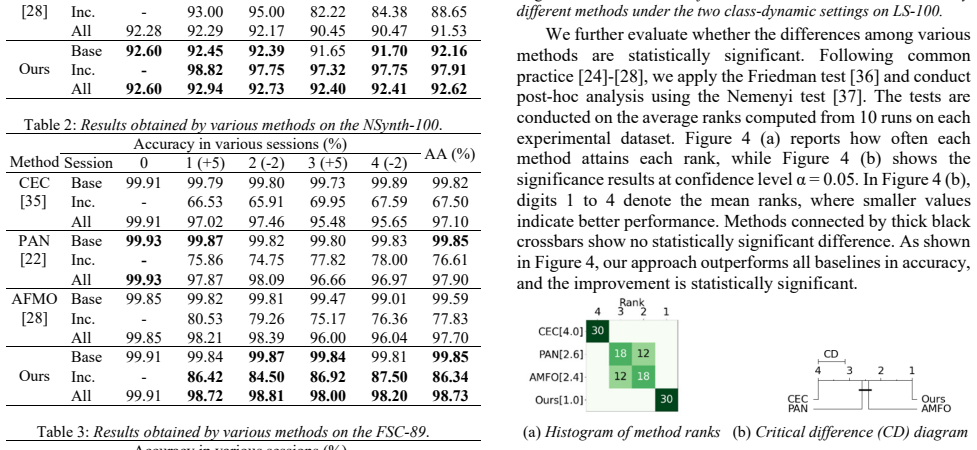
1 (+5)” denotes tha t 5 classes are added in session 1, and “2 (-2)
Experiments This section gives our experiments, including experimental datasets and setup, comparison and ablation experiments. 3.1. Experimental Datasets Experiments are done on three pub lic datasets, including the LS-100, NSynth-100, and FSC-89. LS-100 consists of speech utterances from 100 different speakers. NSynth-100 comprises 100 classes of musica...
-
[22]
Experimental results on three public datasets show that our method outperformed state-of-the-art methods in average accuracy
Conclusions In this work, we tried to solved a new problem of FCIAC using prototype adaptation and pseudo class-adjustable training. Experimental results on three public datasets show that our method outperformed state-of-the-art methods in average accuracy. In addition, both the proposed class-adjustable prototype adaptation network and pseudo class-adju...
-
[23]
Acknowledgements This work was partly supported by the national natural science foundation of China (62371195, 62111530145), and the exchange project of the 10th Meeting of China-Croatia Science and Technology Cooperation Committee (10-34)
-
[24]
Acoustic event diarization in TV/movie audios using deep embedding and integer linear programming,
Y. Li, Y. Zhang, X. Li, M. Liu, W. Wang, and J. Yang, “Acoustic event diarization in TV/movie audios using deep embedding and integer linear programming,” Multimedia Tools Appl., vol. 78, pp. 33999–34025, 2019
2019
-
[25]
Domestic activities clustering from audio recordings using convolutional capsule autoencoder network,
Z. Lin et al., “Domestic activities clustering from audio recordings using convolutional capsule autoencoder network,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2021, pp. 835–839
2021
-
[26]
Deep mutual attention network for acoustic scene classification,
W. Xie, Q. He, Z. Yu, and Y. Li, “Deep mutual attention network for acoustic scene classification,” Digit. Signal Process., vol. 123, 2022, Art. no. 103450
2022
-
[27]
Low complexity acoustic scene classification using data augmentation and lightweight ResNet,
Y. Li, W. Cao, W. Xie, Q. Huang, W. Pang, and Q. He, “Low complexity acoustic scene classification using data augmentation and lightweight ResNet,” in Proc. IEEE 16th Int. Conf. Signal Process., 2022, pp. 41–45
2022
-
[28]
Acoustic scene classification using aggregation of two scale deep embeddings,
H. K. Chon et al., “Acoustic scene classification using aggregation of two scale deep embeddings,” in Proc. IEEE 21st Int. Conf. Commun. Technol., 2021, pp. 1341–1345
2021
-
[29]
Bioacoustics data analysis - A taxonomy, survey and open challenges,
R. R. Kvsn, J. Montgomery, S. Garg, and M. Charleston, “Bioacoustics data analysis - A taxonomy, survey and open challenges,” IEEE Access, vol. 8, pp. 57684–57708, 2020
2020
-
[30]
Comparison of feature extraction methods for sound-based classification of honey bee activity,
A. Terenzi, N. Ortolani, I. Nolasco, E. Benetos, and S. Cecchi, “Comparison of feature extraction methods for sound-based classification of honey bee activity,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 112–122, 2022
2022
-
[31]
V i o l e n c e detection in videos based on fusing visual and audio information,
W . - F . P a n g , Q . - H . H e , Y . - J . H u , a n d Y . - X . L i , “ V i o l e n c e detection in videos based on fusing visual and audio information,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. , 2021, pp. 2260–2264
2021
-
[32]
Audiovisual dependency attention for viol ence detection in videos,
W. Pang, W. Xie, Q. He, Y. Li, and J. Yang, “Audiovisual dependency attention for viol ence detection in videos,” IEEE Trans. Multimedia, vol. 25, pp. 4922–4932, 2023
2023
-
[33]
Anomalous sound detection using deep audio representation and a BLSTM network for audio surveillance of roads,
Y. Li, X. Li, Y. Zhang, M. Liu, and W. Wang, “Anomalous sound detection using deep audio representation and a BLSTM network for audio surveillance of roads,” IEEE Access, vol. 6, pp. 58043– 58055, 2018
2018
-
[34]
Speaker clustering by co-optimizing deep representation learning and cluster estimation,
Y. Li, W. Wang, M. Liu, Z. Jiang, and Q. He, “Speaker clustering by co-optimizing deep representation learning and cluster estimation,” IEEE Trans. Multimedia , vol. 23, pp. 3377–3387, 2021
2021
-
[35]
HTS-AT: A hie rarchical token-semantic audio transformer for sound classification and detection,
K. Chen, et al., “HTS-AT: A hie rarchical token-semantic audio transformer for sound classification and detection,” in Proc. IEEE ICASSP, 2022, pp. 646-650
2022
-
[36]
Learning separable time- frequency filterbanks for audio classification,
J. Pu, Y. Panagakis, and M. Pantic, “Learning separable time- frequency filterbanks for audio classification,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2021, pp. 3000-3004
2021
-
[37]
Divide and distill: New outlooks on knowledge distillation for environmental sound classification,
A. M. Tripathi and O. J. Pandey, “Divide and distill: New outlooks on knowledge distillation for environmental sound classification,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 31, pp. 1100-1113, 2023
2023
-
[38]
Multiscale audio spectrogram transformer for efficient audio classification,
W. Zhu and M. Omar, “Multiscale audio spectrogram transformer for efficient audio classification,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2023, pp. 1-5
2023
-
[39]
Sound event detection via dilated convolutional recurrent neural networks,
Y. Li, et al., “Sound event detection via dilated convolutional recurrent neural networks,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2020, pp. 286-290
2020
-
[40]
Unsupervised and semi-supervised few-shot acoustic event classification,
H.-P. Huang, et al., “Unsupervised and semi-supervised few-shot acoustic event classification,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2021, pp. 331-335
2021
-
[41]
Halluaudio: Hallucinate frequency as concepts f or few-shot audio classification,
Z. Yu, et al., “Halluaudio: Hallucinate frequency as concepts f or few-shot audio classification,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process., 2023, pp. 1-5
2023
-
[42]
Exploring on-device learning using few shots for audio classification,
J. Chauhan, Y. D. Kwon, and C. Mascolo, “Exploring on-device learning using few shots for audio classification,” in Proc. 30th Eur. Signal Process. Conf., 2022, pp. 424-428
2022
-
[43]
Multi-label few-shot learning for sound event recognition,
K.-H. Cheng, S.-Y. Chou, and Y.-H. Yang, “Multi-label few-shot learning for sound event recognition,” in Proc. IEEE 21st Int. Workshop Multimedia Signal Process., 2019, pp. 1-5
2019
-
[44]
Fully few-shot class - incremental audio classifica tion using multi-level embedding extractor and ridge regression classifier,
Y. Si, Y. Li, J. Tan, Q. He, and I. Kwak, “Fully few-shot class - incremental audio classifica tion using multi-level embedding extractor and ridge regression classifier,” in Proc. of Interspeech, 2025, pp. 1318-1322
2025
-
[45]
Few-shot class- incremental audio classificat ion using dynamically expanded classifier with self-atten tion modified prototypes,
Y. Li, W. Cao, W. Xie, J. Li, and E. Benetos, “Few-shot class- incremental audio classificat ion using dynamically expanded classifier with self-atten tion modified prototypes,” IEEE Trans. Multimedia, vol. 26, pp. 1346-1360, 2024
2024
-
[46]
Few-shot class-incremental audio classification via discriminative prototype learning,
W. Xie, Y. Li, Q. He, and W. Cao , “Few-shot class-incremental audio classification via discriminative prototype learning,” Expert Syst. Appl., vol. 225, 2023, Art. no. 120044
2023
-
[47]
Few-shot class- incremental audio classifica tion using adaptively-refined prototypes,
W. Xie, Y. Li, Q. He, W. Cao, and T. Virtanen, “Few-shot class- incremental audio classifica tion using adaptively-refined prototypes,” in Proc. Interspeech, 2023, pp. 301-305
2023
-
[48]
F e w - s h o t c l a s s - incremental audio classification using stochastic classifier,
Y . L i , W . C a o , J . L i , W . X i e , a n d Q . H e , “ F e w - s h o t c l a s s - incremental audio classification using stochastic classifier,” in Proc. Interspeech, 2023, pp. 4174-4178
2023
-
[49]
Few-shot class- incremental audio classification using pseudo-incrementally trained embedding learner and c ontinually updated stochastic classifier,
Y. Li, W. Cao, J. Tan, Q. Li, and G. Chen, “Few-shot class- incremental audio classification using pseudo-incrementally trained embedding learner and c ontinually updated stochastic classifier,” IEEE TASLP, 2025. Accepted for publication
2025
-
[50]
Fully few-shot class-incremental audio classification with adaptive improvement of stability and plasticity,
Y. Si, et al., “Fully few-shot class-incremental audio classification with adaptive improvement of stability and plasticity,” IEEE TASLP, vol. 33, pp. 413-433, 2025
2025
-
[51]
Few-shot class-incremental audio classification with adaptive mitigation of f orgetting and overfitting,
Y. Li, et al., “Few-shot class-incremental audio classification with adaptive mitigation of f orgetting and overfitting,” IEEE/ACM TASLP, vol. 32, pp. 2297-2311, 2024
2024
-
[52]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770-778
2016
-
[53]
BUT system description to VoxCeleb speaker recognition challenge 2019,
H. Zeinali, et al., “BUT system description to VoxCeleb speaker recognition challenge 2019,” in Proc. VoxCeleb Challange Workshop, 2019, pp. 1-4
2019
-
[54]
Use of speaker recognition approaches for learning and evaluating embedding representations of musical instrument sounds,
X. Shi, et al., “Use of speaker recognition approaches for learning and evaluating embedding representations of musical instrument sounds,” IEEE/ACM Trans. Audio, Speech, Lang. Process ., vol. 30, pp. 367-377, 2022
2022
-
[55]
Spatiotemporal contrastive video representatio n learning,
R. Qian et al., “Spatiotemporal contrastive video representatio n learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 6960-6970
2021
-
[56]
Attention is all you need,
A. Vaswani et al., “Attention is all you need,” in Proc. Neural Inf. Process. Syst., 2017, vol. 30, pp. 1-11
2017
-
[57]
J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” 2016, arXiv:1607.06450
Pith/arXiv arXiv 2016
-
[58]
Few-shot incre mental learning with continuall y evolved classifiers,
C. Zhang et al., “Few-shot incre mental learning with continuall y evolved classifiers,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2021, pp. 12450-12459
2021
-
[59]
Statistical Comparisons of Classifiers over MultipleData Sets,
J. Demšar, “Statistical Comparisons of Classifiers over MultipleData Sets,” J. Machine Learning Research, vol. 7, pp. 1- 30, 2006
2006
-
[60]
An extension on ‘statistical comparisons of classifiers over multiple data sets’ for all pairwise comparisons,
S. García and F. Herrera, “An extension on ‘statistical comparisons of classifiers over multiple data sets’ for all pairwise comparisons,” J. Machine Learning Research , vol. 9, pp. 2677- 2694,2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.