OnlyDense: Reduced-Order Modeling for Lagrangian simulation
Pith reviewed 2026-06-27 17:12 UTC · model grok-4.3
The pith
Lagrangian particle system states can be projected onto a linear subspace of neural basis functions for reduced-order dynamics modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework approximates the state space of particle systems with a linear subspace spanned by learned neural basis functions. This parameterization enables direct projection to obtain latent coefficients and explicit access to the basis functions, avoiding optimization over a nonlinear latent space. The resulting representation admits a natural interpretation where latent variables correspond to coefficients in Hilbert space and basis functions correspond to spatial modes. The framework unifies classical projection-based reduced-order modeling with modern deep learning and remains invariant to the number of discretization points. Experiments on large-scale SPH simulations with over one mi
What carries the argument
a linear subspace spanned by learned neural basis functions that carries the argument by allowing direct projection of system states onto latent coefficients for reconstruction and prediction
If this is right
- The representation remains invariant to the number of discretization points in the particle system.
- Dynamics modeling occurs directly in the latent coefficient space without graph-based interactions.
- Accurate reconstruction and prediction hold for systems with over one million particles and extreme deformation events.
- Basis functions correspond to spatial modes that provide an interpretable view analogous to Proper Orthogonal Decomposition.
Where Pith is reading between the lines
- The Hilbert space formulation may apply directly to other function-based representations of physical fields beyond discrete particles.
- Direct access to the learned basis functions could support visualization of dominant modes in engineering failure scenarios.
- The linear projection step might integrate with existing reduced-order codes without requiring changes to nonlinear solvers.
Load-bearing premise
The state of a Lagrangian particle system can be accurately captured by a low-dimensional linear subspace spanned by learned neural basis functions.
What would settle it
A large-scale SPH simulation with extreme fragmentation where reconstruction using 32 basis functions yields an R² score significantly below 0.99 would falsify the central claim.
Figures

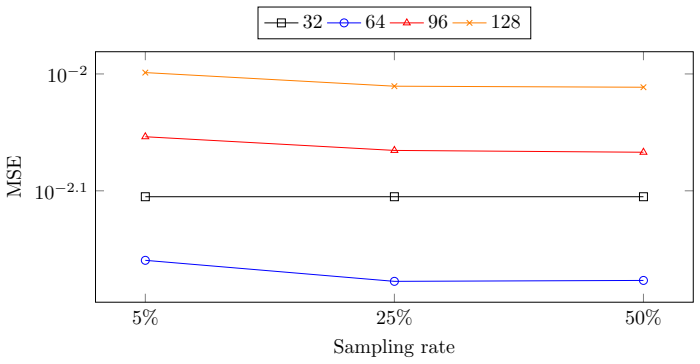
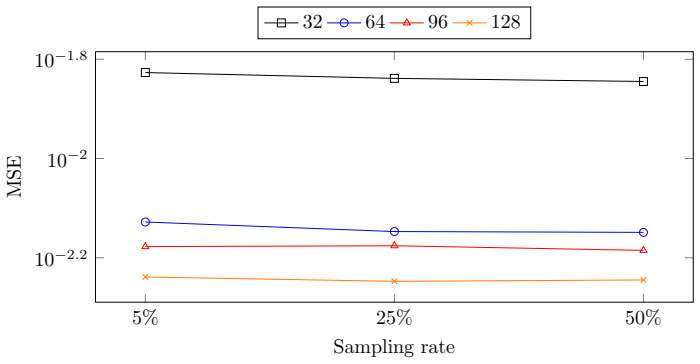
read the original abstract
In science and engineering, Lagrangian simulation methods such as Smooth Particle Hydrodynamics (SPH) or Material Point Method (MPM) are often employed to study the behavior of dynamic systems. However, these methods can be prohibitively computationally expensive, particularly when simulating multi-scale spatial or temporal phenomena, e.g., void growth and coalescence within macro-scale geometries, structural failure of spacecraft components resulting from hypervelocity impact of space debris particles, etc. In contrast to graph-based methods, where the state of the system is understood as a discrete set of particles, we propose a learning framework for scalable representation and dynamics modeling of massive particle systems by treating the system state as a function and its evolution as a trajectory in Hilbert space. Rather than representing the state as a discrete set of particles or embedding it in a nonlinear latent manifold, we approximate the state space with a linear subspace spanned by learned neural basis functions. This parameterization enables direct projection to obtain latent coefficients and explicit access to the basis functions, avoiding optimization over a nonlinear latent space. The resulting representation admits a natural interpretation: latent variables correspond to coefficients in Hilbert space, and basis functions correspond to spatial modes, analogous to Proper Orthogonal Decomposition. The framework thus unifies classical projection-based reduced-order modeling with modern deep learning, while remaining invariant to the number of discretization points. Experiments on large-scale SPH simulations with over one million particles, including dynamic events with extreme deformation and fragmentation, demonstrate that the proposed method accurately reconstructs and predicts dynamics, achieving an R$^2$ score above $0.99$ with as few as $32$ basis functions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OnlyDense, a reduced-order modeling approach for large-scale Lagrangian particle simulations (e.g., SPH) that represents system states as functions in a Hilbert space approximated by a linear subspace spanned by learned neural basis functions. Latent coefficients are obtained by direct projection, and dynamics are modeled in this subspace, yielding a representation invariant to particle count. The central claim is that this accurately reconstructs and predicts dynamics on simulations with >1M particles, including extreme deformation and fragmentation, achieving R² > 0.99 with only 32 basis functions.
Significance. If the experimental claims hold under proper validation, the method would provide a scalable bridge between classical projection-based reduced-order modeling (e.g., POD) and deep learning for particle systems, avoiding nonlinear latent optimization and graph-based interactions while remaining discretization-invariant.
major comments (2)
- [Abstract] Abstract: The abstract states that the method 'accurately reconstructs and predicts dynamics, achieving an R² score above 0.99 with as few as 32 basis functions' on large-scale SPH simulations with fragmentation, but supplies no information whatsoever on the training procedure for the neural basis functions, the form of the latent dynamics model, validation splits, error bars, or sensitivity to basis count; without these, the central empirical claim cannot be evaluated.
- [Abstract] Abstract and method description: The framework assumes that even after fragmentation the instantaneous state remains well-approximated by a fixed low-dimensional linear span of the learned basis functions whose coefficients evolve inside that span; the manuscript provides no analysis or counter-example addressing whether independent rigid-body motions and deformations of spatially disconnected fragments can be captured without the required dimensionality growing with the number of fragments.
minor comments (1)
- [Abstract] The abstract refers to 'learned neural basis functions' and 'explicit access to the basis functions' but does not clarify whether these are parameterized as MLPs, how they are optimized jointly with the dynamics model, or how the projection is computed in practice.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that the method 'accurately reconstructs and predicts dynamics, achieving an R² score above 0.99 with as few as 32 basis functions' on large-scale SPH simulations with fragmentation, but supplies no information whatsoever on the training procedure for the neural basis functions, the form of the latent dynamics model, validation splits, error bars, or sensitivity to basis count; without these, the central empirical claim cannot be evaluated.
Authors: We agree the abstract is too brief to support evaluation of the central claim. The manuscript body details the neural basis training via reconstruction on projected states, the latent dynamics as evolution within the coefficient space, held-out simulation validation, and basis-count sensitivity. We will revise the abstract to incorporate a concise statement on training/validation and add error bars to the reported R² values. revision: yes
-
Referee: [Abstract] Abstract and method description: The framework assumes that even after fragmentation the instantaneous state remains well-approximated by a fixed low-dimensional linear span of the learned basis functions whose coefficients evolve inside that span; the manuscript provides no analysis or counter-example addressing whether independent rigid-body motions and deformations of spatially disconnected fragments can be captured without the required dimensionality growing with the number of fragments.
Authors: The referee correctly notes the absence of explicit analysis on dimensionality scaling with fragment count. Our experiments show that 32 bases suffice for R² > 0.99 on fragmentation cases, providing empirical support that the fixed span captures the required modes. We will add a discussion paragraph addressing the assumption, including a simple counter-example with disconnected fragments to illustrate that independent motions remain representable if they lie in the learned span. revision: partial
Circularity Check
No circularity; empirical validation stands independent of inputs
full rationale
The paper defines a linear-subspace representation via neural basis functions and reports experimental R² > 0.99 on SPH data as evidence. No derivation step equates a claimed prediction to a fitted parameter by construction, invokes a self-citation as the sole justification for a uniqueness claim, or renames an input as an output. The low-dimensional subspace assumption is tested directly on fragmentation cases rather than smuggled in via prior work or self-definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of basis functions =
32
axioms (2)
- domain assumption Lagrangian particle system state can be treated as a function whose evolution is a trajectory in Hilbert space
- domain assumption A linear subspace spanned by learned neural basis functions suffices for accurate state approximation and dynamics
Reference graph
Works this paper leans on
-
[1]
Machine Learning for Fluid Mechanics
Steven L. Brunton, Bernd R. Noack, and Petros Koumoutsakos. “Machine Learning for Fluid Mechanics”. In:Annual Review of Fluid Mechanics52.1 (Jan. 2020), pp. 477–508.issn: 1545-4479.doi:10.1146/annurev-fluid- 010719- 060214.url:http://dx.doi.org/10.1146/annurev- fluid- 010719-060214
-
[2]
Peter Yichen Chen et al.CROM: Continuous Reduced-Order Modeling of PDEs Using Implicit Neural Representations. 2023. arXiv:2206 . 02607 [cs.LG].url:https://arxiv.org/abs/2206.02607
arXiv 2023
-
[3]
Peter Yichen Chen et al.Model reduction for the material point method via an implicit neural representation of the deformation map. 2023. arXiv: 2109.12390 [cs.LG].url:https://arxiv.org/abs/2109.12390
arXiv 2023
-
[4]
Ricky T. Q. Chen et al.Neural Ordinary Differential Equations. 2019. arXiv:1806.07366 [cs.LG].url:https://arxiv.org/abs/1806.07366
Pith/arXiv arXiv 2019
-
[5]
An Accurate SPH Scheme for Hypervelocity Impact Modeling
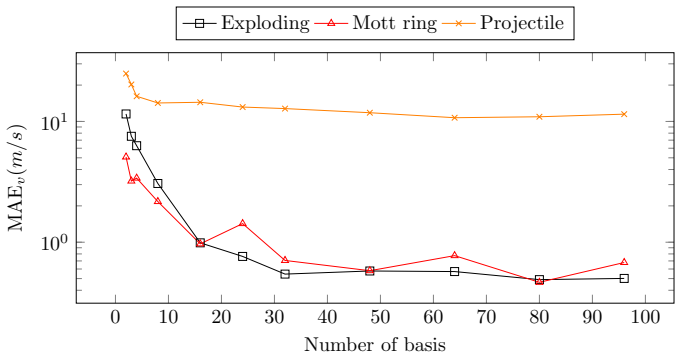
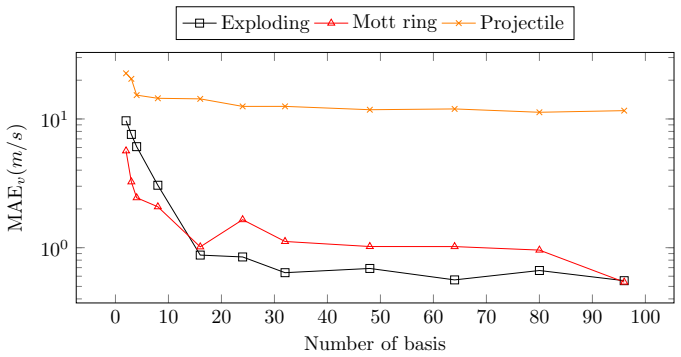
Anthony Coll´ e et al. “An Accurate SPH Scheme for Hypervelocity Impact Modeling”. In:2019 15th Hypervelocity Impact Symposium. HVIS2019. American Society of Mechanical Engineers, Apr. 2019.doi:10 . 1115 / hvis2019-078.url:http://dx.doi.org/10.1115/HVIS2019-078. 16 0 10 20 30 40 50 60 70 80 90 100 100 101 Number of basis MAEv(m/s) Exploding Mott ring Proj...
-
[6]
Splinecnn: Fast geometric deep learning with continu- ous b-spline kernels
Matthias Fey et al. “Splinecnn: Fast geometric deep learning with continu- ous b-spline kernels”. In:Proceedings of the IEEE conference on computer vision and pattern recognition. 2018, pp. 869–877
2018
-
[7]
Latent-space Dynamics for Reduced Deformable Simulation
Lawson Fulton et al. “Latent-space Dynamics for Reduced Deformable Simulation”. en. In:Computer Graphics Forum38.2 (May 2019), pp. 379– 391.issn: 0167-7055, 1467-8659.doi:10.1111/cgf.13645.url:https: / / onlinelibrary . wiley . com / doi / 10 . 1111 / cgf . 13645(visited on 08/18/2025)
-
[8]
Smoothed particle hydrody- namics: theory and application to non-spherical stars
Robert A Gingold and Joseph J Monaghan. “Smoothed particle hydrody- namics: theory and application to non-spherical stars”. In:Monthly notices of the royal astronomical society181.3 (1977), pp. 375–389
1977
-
[9]
David Ha, Andrew Dai, and Quoc V. Le.HyperNetworks. 2016. arXiv: 1609.09106 [cs.LG].url:https://arxiv.org/abs/1609.09106
Pith/arXiv arXiv 2016
-
[10]
Zhongkai Hao et al.Physics-Informed Machine Learning: A Survey on Problems, Methods and Applications. 2022.doi:10.48550/ARXIV.2211. 08064.url:https://arxiv.org/abs/2211.08064
-
[11]
Tyler Ingebrand, Adam J. Thorpe, and Ufuk Topcu.Function Encoders: A Principled Approach to Transfer Learning in Hilbert Spaces. 2025. arXiv: 2501.18373 [cs.LG].url:https://arxiv.org/abs/2501.18373
arXiv 2025
-
[12]
Recent Advances and Applications of Machine Learning in Experimental Solid Mechanics: A Review
Hanxun Jin, Enrui Zhang, and Horacio D. Espinosa. “Recent Advances and Applications of Machine Learning in Experimental Solid Mechanics: A Review”. In:Applied Mechanics Reviews75.6 (July 2023).issn: 2379- 0407.doi:10.1115/1.4062966.url:http://dx.doi.org/10.1115/1. 4062966. 17 Train R2 Test R2 Dataset Basis (K) Exploding 2 98.1098 (±0.1578) 98.5908 (±0.086...
work page doi:10.1115/1.4062966.url:http://dx.doi.org/10.1115/1 2023
-
[13]
Krishna Kumar and Joseph Vantassel.GNS: A generalizable Graph Neural Network-based simulator for particulate and fluid modeling. 2022. arXiv: 2211.10228 [cs.LG].url:https://arxiv.org/abs/2211.10228
arXiv 2022
-
[14]
Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders
Kookjin Lee and Kevin Carlberg.Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. arXiv:1812.08373 [cs]. June 2019.doi:10.48550/arXiv.1812.08373.url:http://arxiv. org/abs/1812.08373(visited on 08/18/2025)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.08373.url:http://arxiv 2019
-
[15]
Yunzhu Li et al.Learning Particle Dynamics for Manipulating Rigid Bod- ies, Deformable Objects, and Fluids. 2019. arXiv:1810.01566 [cs.LG]. url:https://arxiv.org/abs/1810.01566
Pith/arXiv arXiv 2019
-
[16]
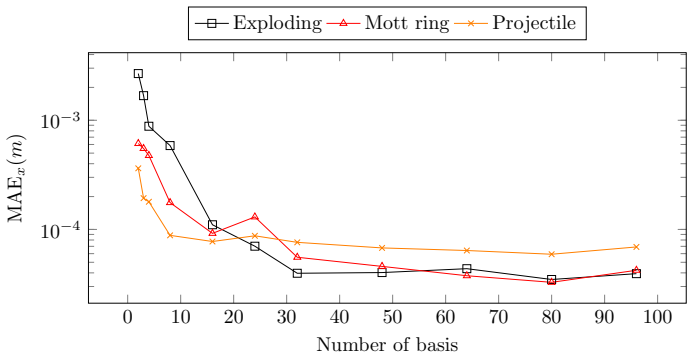
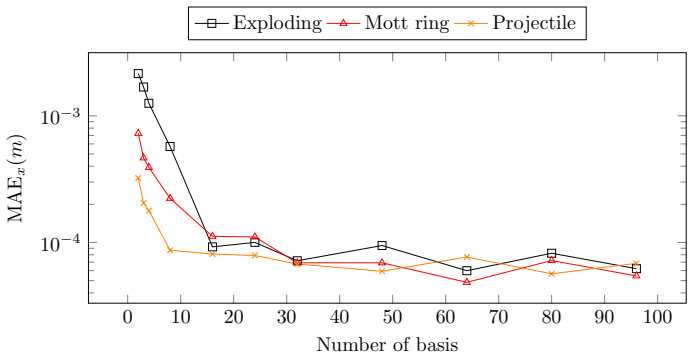
Damian Mrowca et al.Flexible Neural Representation for Physics Predic- tion. 2018. arXiv:1806.08047 [cs.AI].url:https://arxiv.org/abs/ 1806.08047. 18 0 10 20 30 40 50 60 70 80 90 100 10−4 10−3 Number of basis MAEx(m) Exploding Mott ring Projectile Figure 6: MAE x by number of basis functions across different datasets on dy- namic learning task
Pith/arXiv arXiv 2018
-
[17]
Alvaro Sanchez-Gonzalez et al.Graph networks as learnable physics en- gines for inference and control. 2018. arXiv:1806.01242 [cs.LG].url: https://arxiv.org/abs/1806.01242
Pith/arXiv arXiv 2018
-
[18]
Spnets: Differentiable fluid dynamics for deep neural networks
Connor Schenck and Dieter Fox. “Spnets: Differentiable fluid dynamics for deep neural networks”. In:Conference on Robot Learning. PMLR. 2018, pp. 317–335
2018
-
[19]
A particle method for history- dependent materials
D. Sulsky, Z. Chen, and H. L. Schreyer. “A particle method for history- dependent materials”. In:Computer Methods in Applied Mechanics and Engineering118.1 (1994), pp. 179–196.issn: 0045-7825.doi:https : / / doi . org / 10 . 1016 / 0045 - 7825(94 ) 90112 - 0.url:https : / / www . sciencedirect.com/science/article/pii/0045782594901120
arXiv 1994
-
[20]
Lagrangian Fluid Simulation with Contin- uous Convolutions
Benjamin Ummenhofer et al. “Lagrangian Fluid Simulation with Contin- uous Convolutions”. In:International Conference on Learning Represen- tations. 2020.url:https://openreview.net/forum?id=B1lDoJSYDH
2020
-
[21]
Yuan Yin et al.Continuous PDE Dynamics Forecasting with Implicit Neu- ral Representations. 2023. arXiv:2209.14855 [cs.LG].url:https:// arxiv.org/abs/2209.14855. 19 0 10 20 30 40 50 60 70 80 90 100 100 101 Number of basis MAEv(m/s) Exploding Mott ring Projectile Figure 7: MAE v by number of basis functions across different datasets on dy- namic learning ta...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.