Proposal Refinement for Few-Shot Object Detection
Pith reviewed 2026-06-27 17:24 UTC · model grok-4.3
The pith
Rebalancing region proposals between novel and base classes improves few-shot object detection by 1 to 6 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
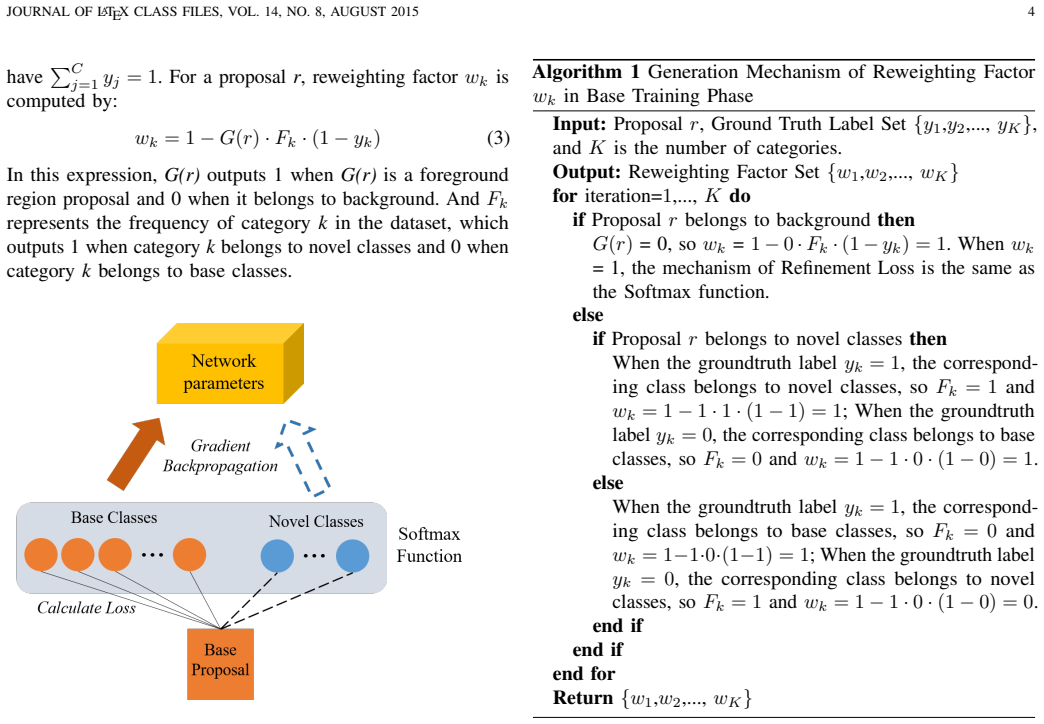
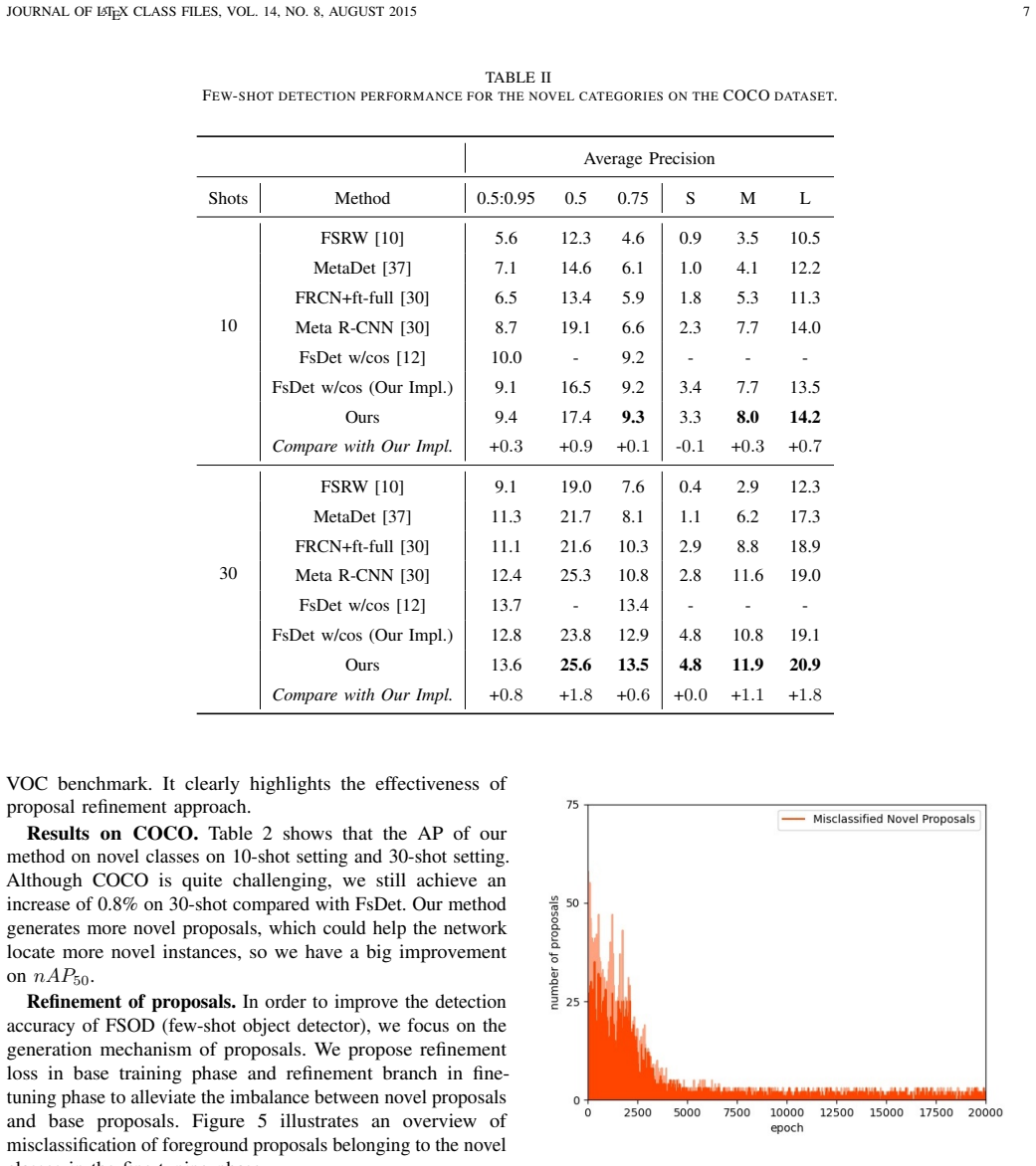
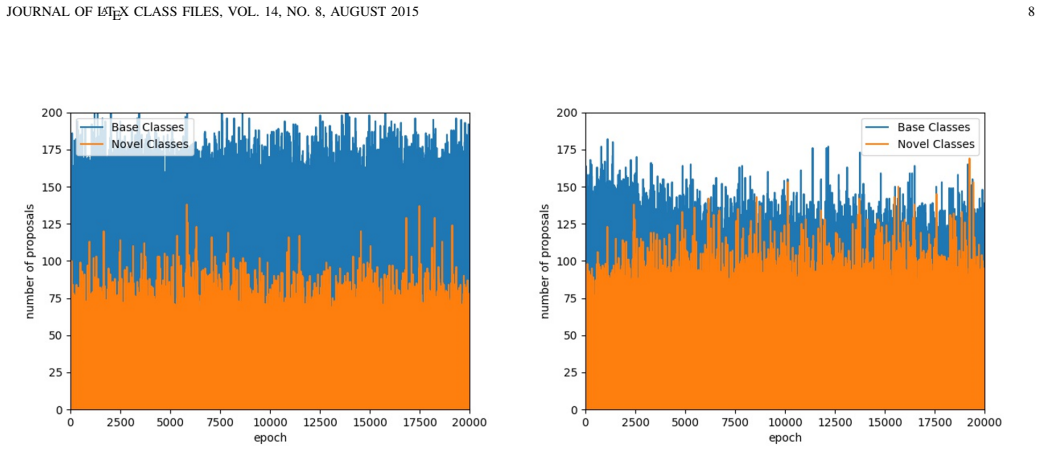
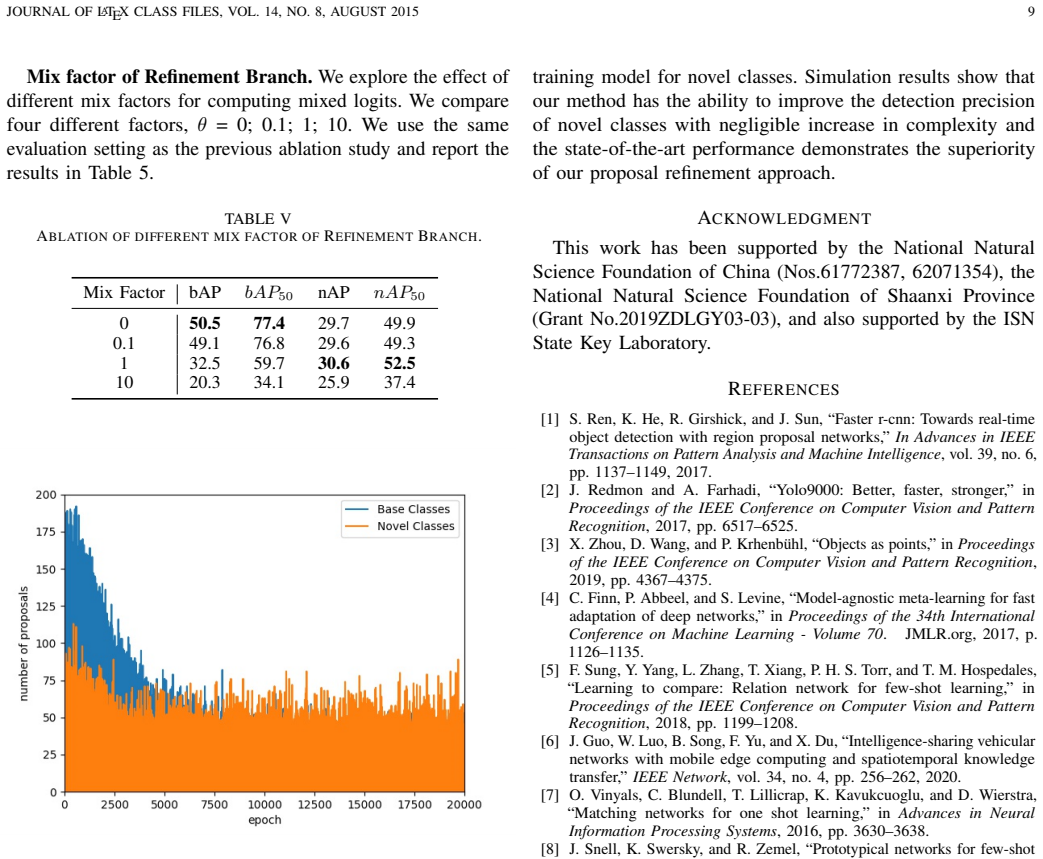
The central claim is that the unbalanced distribution of region proposals between novel and base classes is the key bottleneck in few-shot object detection, and that a proposal refinement approach consisting of a refinement loss applied during base training plus a refinement branch added to the RPN in the fine-tuning phase can rebalance this distribution, producing 1 percent to 6 percent gains on current benchmarks while leaving inference time unchanged.
What carries the argument
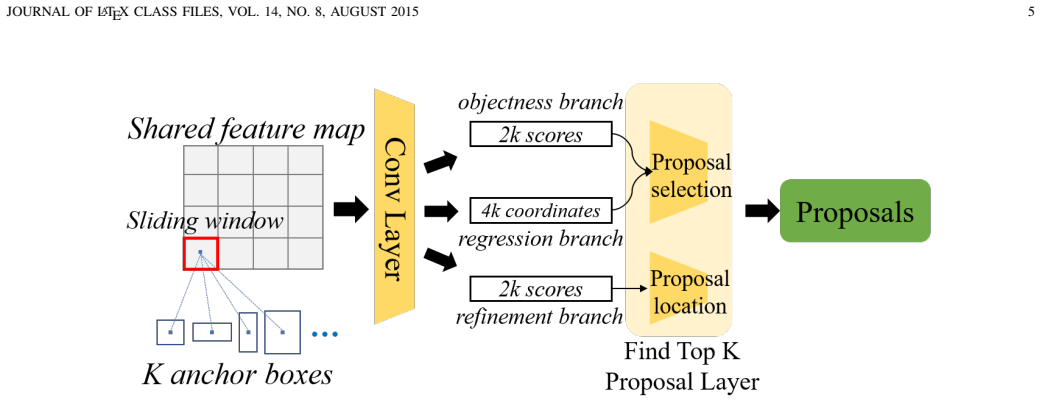
The proposal refinement mechanism that combines a refinement loss for base training with an auxiliary refinement branch for the RPN in fine-tuning.
If this is right
- The model becomes more sensitive to novel classes already during base-class training.
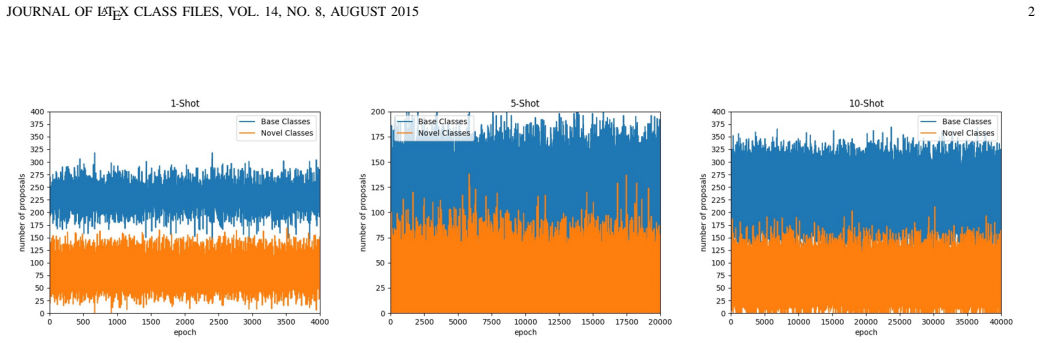
- The RPN generates a higher fraction of proposals belonging to novel classes during fine-tuning.
- Overall detection accuracy on novel classes rises while base-class performance is preserved.
- The gains appear on multiple standard few-shot object detection benchmarks without any added inference cost.
Where Pith is reading between the lines
- The same rebalancing idea might transfer to other detection settings where proposal imbalance arises, such as long-tailed class distributions.
- One could test whether the refinement branch can remain active at inference time without harming speed or accuracy.
- The work implies that future few-shot detectors might benefit from treating proposal generation as a separate optimization target rather than relying only on the classification head.
Load-bearing premise
The performance bottleneck in few-shot object detection is the unbalanced distribution of region proposals between novel and base classes.
What would settle it
An experiment that measures proposal counts before and after the refinement steps and shows no increase in the share of novel-class proposals, or that shows the reported accuracy gains vanish when the refinement components are removed.
Figures

read the original abstract
Few-shot object detection has gained widely attention in recent years. Some excellent algorithms have been proposed to handle this task. However, most of these algorithms rely on the performance of few-shot classification. Unlike previous attempts, our work focuses on the problem of unbalanced distribution of region proposals between the novel classes and the base classes. In order to alleviate this unbalanced distribution, we propose the proposal refinement approach for different training phases. Specifically, refinement loss is designed for the base training phase to enhance sensitivity of the model to novel classes, and refinement branch is introduced as an auxiliary branch for RPN (Region Proposal Networks) to generate more novel proposals in the fine-tuning phase. By rebalancing the proposal distribution, the proposed approach outperforms the baselines methods by roughly 1\%$\sim$6\% on current benchmarks without increasing any inference time. Through extensive experiments, we prove that we establish a new state-of-the-art method for the few-shot object detection task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the central bottleneck in few-shot object detection is the unbalanced distribution of RPN proposals between novel and base classes. It introduces a refinement loss applied during base-class training (intended to increase sensitivity to future novel classes) together with an auxiliary refinement branch added to the RPN only in the fine-tuning stage; the combined changes are said to rebalance proposals, yielding 1–6 % gains over baselines on standard benchmarks while leaving inference time unchanged and establishing a new state of the art.
Significance. If the reported gains prove robust, statistically significant, and attributable to the proposed components rather than uncontrolled factors, the work would supply a lightweight, inference-free addition to existing few-shot detectors. The absence of any inference overhead is a practical strength. However, the current manuscript supplies neither the mechanistic account nor the experimental controls needed to evaluate whether those gains are real or reproducible.
major comments (2)
- [Abstract] Abstract (and the corresponding description of the base-training phase): the refinement loss is asserted to 'enhance sensitivity of the model to novel classes' during base training, yet base training uses only base-class data. No concrete mechanism, regularizer, or auxiliary signal is supplied that could produce this effect without either leaking novel-class information or relying on an unstated general property whose transfer to unseen classes is not guaranteed. This directly undermines the central rebalancing premise.
- [Abstract] Abstract and experimental reporting: the claimed 1–6 % gains are presented without any mention of statistical significance, number of runs, ablation of the refinement loss versus the refinement branch, or controls for proposal-generation hyperparameters. Without these, the attribution of performance change to the proposed rebalancing cannot be verified and the soundness of the empirical claim remains low.
minor comments (2)
- Typos and phrasing: 'gained widely attention' should read 'gained wide attention'; 'baselines methods' should read 'baseline methods'.
- The abstract states that the method 'establishes a new state-of-the-art' but does not name the exact prior methods or the precise metric values that are surpassed; a table or explicit comparison in the main text is needed for this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and commit to revisions that strengthen the presentation of the method and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the corresponding description of the base-training phase): the refinement loss is asserted to 'enhance sensitivity of the model to novel classes' during base training, yet base training uses only base-class data. No concrete mechanism, regularizer, or auxiliary signal is supplied that could produce this effect without either leaking novel-class information or relying on an unstated general property whose transfer to unseen classes is not guaranteed. This directly undermines the central rebalancing premise.
Authors: We agree that the abstract is too concise and does not articulate the mechanism. The refinement loss is a class-agnostic auxiliary term applied to the RPN that encourages higher recall on object-like regions regardless of semantic category; because base and novel classes share low-level visual statistics, this improves proposal coverage for novel instances at fine-tuning time. To resolve the concern we will expand both the abstract and Section 3 with the exact loss formulation and a short justification of its transfer property. revision: yes
-
Referee: [Abstract] Abstract and experimental reporting: the claimed 1–6 % gains are presented without any mention of statistical significance, number of runs, ablation of the refinement loss versus the refinement branch, or controls for proposal-generation hyperparameters. Without these, the attribution of performance change to the proposed rebalancing cannot be verified and the soundness of the empirical claim remains low.
Authors: The referee correctly identifies missing experimental controls. In the revised manuscript we will report mean and standard deviation over five random seeds, include paired t-tests for significance, add an ablation table that isolates the refinement loss from the auxiliary branch, and document the exact RPN hyperparameters used across all baselines and our method. revision: yes
Circularity Check
No significant circularity; empirical additions evaluated externally
full rationale
The paper describes an empirical proposal refinement method consisting of a refinement loss (base training) and auxiliary branch (fine-tuning) to address RPN proposal imbalance between base and novel classes. No equations, fitted parameters, or derivation steps are presented in the provided text that would reduce any claimed prediction or result to the inputs by construction. Performance is reported as measured gains (1-6%) on external benchmarks, with no self-citation load-bearing premises, uniqueness theorems, or ansatzes invoked. The method is presented as a self-contained addition whose value is assessed via standard few-shot detection benchmarks, satisfying the condition for a non-circular finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”In Advances in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137–1149, 2017
2017
-
[2]
Yolo9000: Better, faster, stronger,
J. Redmon and A. Farhadi, “Yolo9000: Better, faster, stronger,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6517–6525
2017
-
[3]
Objects as points,
X. Zhou, D. Wang, and P. Krhenb¨uhl, “Objects as points,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4367–4375
2019
-
[4]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProceedings of the 34th International Conference on Machine Learning - Volume 70. JMLR.org, 2017, p. 1126–1135
2017
-
[5]
Learning to compare: Relation network for few-shot learning,
F. Sung, Y . Yang, L. Zhang, T. Xiang, P. H. S. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1199–1208
2018
-
[6]
Intelligence-sharing vehicular networks with mobile edge computing and spatiotemporal knowledge transfer,
J. Guo, W. Luo, B. Song, F. Yu, and X. Du, “Intelligence-sharing vehicular networks with mobile edge computing and spatiotemporal knowledge transfer,”IEEE Network, vol. 34, no. 4, pp. 256–262, 2020
2020
-
[7]
Matching networks for one shot learning,
O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” inAdvances in Neural Information Processing Systems, 2016, pp. 3630–3638
2016
-
[8]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” inAdvances in Neural Information Processing Systems, 2017, pp. 4077–4087
2017
-
[9]
D2n4: A discriminative deep nearest neighbor neural network for few-shot space target recognition,
X. Yang, X. Nan, and B. Song, “D2n4: A discriminative deep nearest neighbor neural network for few-shot space target recognition,”IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 5, pp. 3667–3676, 2020
2020
-
[10]
Few-shot object detection via feature reweighting,
B. Kang, Z. Liu, X. Wang, F. Yu, J. Feng, and T. Darrell, “Few-shot object detection via feature reweighting,” inProceedings of the IEEE International Conference on Computer Vision, 2019, pp. 8419–8428
2019
-
[11]
Repmet: Representative-based metric learning for classification and few-shot object detection,
L. Karlinsky, J. Shtok, S. Harary, E. Schwartz, A. Aides, R. Feris, R. Giryes, and A. M. Bronstein, “Repmet: Representative-based metric learning for classification and few-shot object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 5192–5201
2019
-
[12]
Frustratingly simple few-shot object detection,
X. Wang, T. Huang, T. Darrell, J. Gonzalez, and F. Yu, “Frustratingly simple few-shot object detection,”arXiv preprint arXiv:2003.06957, 2020
arXiv 2003
-
[13]
The pascal visual object classes challenge 2009 (voc2009) results,
M. Everingham, “The pascal visual object classes challenge 2009 (voc2009) results,” inhttp://www.pascal- etwork.org/challenges/VOC/voc2009/workshop/index.html, 2007
2009
-
[14]
Microsoft coco: Common objects in context,
T. Y . Lin, M. Maire, S. Belongie, J. Hays, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inECCV, 2014
2014
-
[15]
Overcoming classifier imbalance for long-tail object detection with balanced group softmax,
Y . Li, T. Wang, B. Kang, S. Tang, C. Wang, J. Li, and J. Feng, “Overcoming classifier imbalance for long-tail object detection with balanced group softmax,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 988–10 997
2020
-
[16]
Decoupling representation and classifier for long-tailed recognition,
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y . Kalantidis, “Decoupling representation and classifier for long-tailed recognition,”arXiv preprint arXiv:1910.09217, 2019
arXiv 1910
-
[17]
Trust-aware recommendation based on heterogeneous multi-relational graphs fusion,
J. Guo, Y . Zhou, P. Zhang, B. Song, and C. Chen, “Trust-aware recommendation based on heterogeneous multi-relational graphs fusion,” Information Fusion, vol. 74, pp. 87–95, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1566253521000671 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 10
2021
-
[18]
Self- supervised learning for few-shot image classification,
D. Chen, Y . Chen, Y . Li, F. Mao, Y . He, and H. Xue, “Self- supervised learning for few-shot image classification,”arXiv preprint arXiv:1911.06045, 2019
arXiv 1911
-
[19]
Feature pyramid networks for object detection,
T. Lin, P. Doll ´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 936–944
2017
-
[20]
Cascade r-cnn: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6154–6162
2018
-
[21]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 2, pp. 386–397, 2020
2020
-
[22]
Fast r-cnn,
R. Girshick, “Fast r-cnn,” inProceedings of the IEEE International Conference on Computer Vision, 2015, pp. 1440–1448
2015
-
[23]
Cornernet: Detecting objects as paired keypoints,
H. Law and J. Deng, “Cornernet: Detecting objects as paired keypoints,” International Journal of Computer Vision, p. 642–656, 2020
2020
-
[24]
Focal loss for dense object detection,
T. Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 2, pp. 318–327, 2020
2020
-
[25]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 779–788
2016
-
[26]
Yolov3: An incremental improvement,
J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,”arXiv preprint arXiv:1804.02767, 2018
Pith/arXiv arXiv 2018
-
[27]
Rich feature hierarchies for accurate object detection and semantic segmentation,
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 580–587
2014
-
[28]
Few-shot learning as domain adaptation: Algorithm and analysis,
J. Guan, Z. Lu, T. Xiang, and J. R. Wen, “Few-shot learning as domain adaptation: Algorithm and analysis,”arXiv preprint arXiv:2002.02050, 2020
arXiv 2002
-
[29]
Lstd: A low-shot transfer detector for object detection,
H. Chen, Y . Wang, G. Wang, and Y . Qiao, “Lstd: A low-shot transfer detector for object detection,” inProceedings of the 32th AAAI Conference on Artificial Intelligence, 2018
2018
-
[30]
Meta r- cnn: Towards general solver for instance-level low-shot learning,
X. Yan, Z. Chen, A. Xu, X. Wang, X. Liang, and L. Lin, “Meta r- cnn: Towards general solver for instance-level low-shot learning,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 9576–9585
2019
-
[31]
Incremental few-shot object detection,
J.-M. P ´erez-R´ua, X. Zhu, T. M. Hospedales, and T. Xiang, “Incremental few-shot object detection,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 13 843–13 852
2020
-
[32]
Few-shot object detection with attention-rpn and multi-relation detector,
Q. Fan, W. Zhuo, C.-K. Tang, and Y .-W. Tai, “Few-shot object detection with attention-rpn and multi-relation detector,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 4012–4021
2020
-
[33]
Multi-scale positive sample refinement for few-shot object detection,
J. Wu, S. Liu, D. Huang, and Y . Wang, “Multi-scale positive sample refinement for few-shot object detection,” inComputer Vision – ECCV
-
[34]
Springer International Publishing, 2020, pp. 456–472
2020
-
[35]
Equalization loss for long-tailed object recognition,
J. Tan, C. Wang, B. Li, Q. Li, W. Ouyang, C. Yin, and J. Yan, “Equalization loss for long-tailed object recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 659–11 668
2020
-
[36]
Efficient non-maximum suppression,
A. Neubeck and L. Van Gool, “Efficient non-maximum suppression,” in Proceedings of the 18th International Conference on Pattern Recognition, vol. 3, 2006, pp. 850–855
2006
-
[37]
The pascal visual object classes challenge: A retrospective,
M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,”International Journal of Computer Vision, vol. 111, no. 1, pp. 98–136, 2015
2015
-
[38]
Meta-learning to detect rare objects,
Y . Wang, D. Ramanan, and M. Hebert, “Meta-learning to detect rare objects,” inProceedings of the IEEE International Conference on Computer Vision, 2019, pp. 9924–9933
2019
-
[39]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.