Brain-Prompt Injection: A Route-Safety Audit for BCI-LLM Agents
Pith reviewed 2026-06-27 16:13 UTC · model grok-4.3
The pith
A Route-Safety Audit Contract with provenance and split-conformal confirmation blocks brain-prompt injection routes in BCI-LLM agents at zero false-accept rate under acquisition isolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
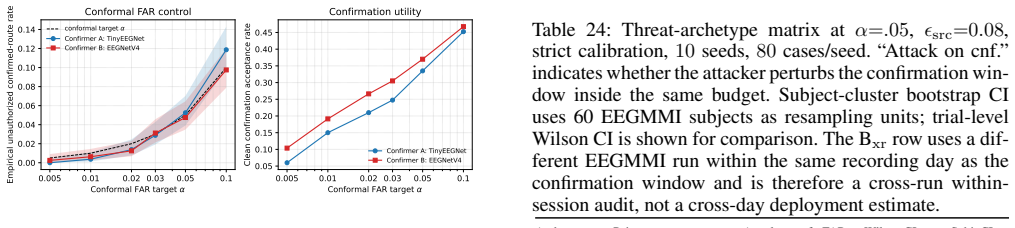
Provenance blocks C2 routes at probability 0.000; agreement-plus-provenance routes C3 flips at probability 1.000; confirmation-plus-provenance routes them at probability 0.000. The conformal frontier reaches FAR 0.000 at clean utility 0.150 for alpha=.005 and FAR 0.119 at clean utility 0.452 for alpha=.10 under acquisition isolation; an attacker-controllable confirmation channel breaks the bound to approximately 1. Mediation and confirmation reduce risk but are not intent certificates.
What carries the argument
The Route-Safety Audit Contract, a minimal log schema with denominator hierarchy and endpoint specification, together with the C3 attacked-dependence decomposition that separates observable routing terms from decoder internals.
If this is right
- Provenance alone is sufficient to block all C2 routes.
- Agreement combined with provenance routes every C3 flip.
- Confirmation combined with provenance routes every C3 flip at zero probability.
- Split-conformal calibration on the confirmation channel yields zero FAR at 15 percent clean utility for alpha equal to 0.005 under isolation.
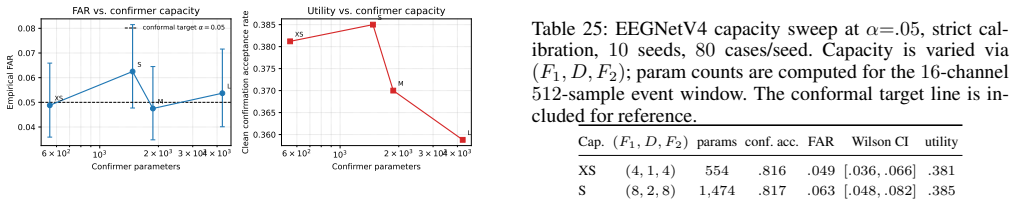
- Within-regime saturation holds across TinyEEGNet and EEGNetV4 architectures.
Where Pith is reading between the lines
- The same audit contract could be applied to other neural signal modalities if equivalent confirmation channels exist.
- Subject-cluster bootstrap results suggest the reported intervals generalize across users without retraining per individual.
- If the confirmation channel remains attacker-controllable, the entire conformal bound collapses regardless of the audit schema.
- The decomposition implies that adding more observable fields to the log schema could further tighten the separation between C2 and C3 terms.
Load-bearing premise
The audit log schema and C3 attacked-dependence decomposition capture exactly the observable information that controls routing decisions, independent of decoder internals.
What would settle it
Running the same conformal calibration after giving the attacker direct control over the confirmation channel and checking whether the false-accept rate reaches approximately 1, violating the reported bound.
Figures
read the original abstract
BCI-to-agent pipelines turn decoded neural activity into an authorization channel for tool-use agents, exposing a new attack surface we call \emph{brain-prompt injection}: signal-side perturbations, context-only injections, and adaptive dual-decoder attacks can all change the routed action while EEG-side or text-side monitors remain blind. Route safety in this stack depends on what the audit log can observe, not on decoder accuracy or agreement alone. We define a Route-Safety Audit Contract: a minimal log schema, denominator hierarchy, and endpoint specification, and prove an audit-schema separation theorem together with a C3 attacked-dependence decomposition; clean agreement and marginal robustness do not identify the joint term that controls C3 routing. As a calibration layer on top of the contract, we apply split-conformal calibration to a non-oracle EEG confirmation channel and report the resulting false-accept frontier under an explicit threat-archetype matrix. We instantiate the contract on EEGMMI native left/right command-control over 5{,}400 events, harmless tool stubs, and seed/case denominators. Provenance blocks C2 routes ($0.000$); agreement-plus-provenance routes C3 flips ($1.000$); confirmation-plus-provenance routes them ($0.000$). The conformal frontier reaches FAR $0.000$ at clean utility $0.150$ for $\alpha=.005$ and FAR $0.119$ at clean utility $0.452$ for $\alpha=.10$ under acquisition isolation; an attacker-controllable confirmation channel breaks the bound to $\approx\!1$. Subject-cluster bootstrap confirms these intervals on $60$ subjects; cross-architecture (TinyEEGNet, EEGNetV4) and capacity-sweep results show within-regime saturation. Mediation and confirmation reduce risk; they are not intent certificates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a new attack surface called brain-prompt injection in BCI-LLM agent pipelines. It defines a Route-Safety Audit Contract with a minimal log schema and proves an audit-schema separation theorem along with a C3 attacked-dependence decomposition. Using split-conformal calibration on a non-oracle EEG confirmation channel and experiments on the EEGMMI dataset with 5,400 events, it reports that provenance blocks C2 routes at rate 0.000, agreement-plus-provenance routes C3 flips at 1.000, confirmation-plus-provenance at 0.000, and conformal prediction achieves FAR 0.000 at clean utility 0.150 for alpha=0.005 under acquisition isolation.
Significance. If the central results hold, the work offers a structured approach to auditing route safety in BCI-to-agent systems, providing empirical evidence on the effectiveness of log-based provenance, agreement, and confirmation in blocking attacks, along with conformal bounds on false accept rates. The subject-cluster bootstrap and cross-architecture validation add robustness to the empirical findings.
major comments (2)
- The C3 attacked-dependence decomposition and separation theorem are introduced without derivation steps or proof details in the provided abstract, making it difficult to assess whether they are independently grounded or potentially circular with the audit observables.
- The reported blocking rates (e.g., provenance blocks C2 routes (0.000)) and conformal frontier depend on the assumption that the audit log schema captures the observable information controlling routing decisions independent of decoder internals. The manuscript states this explicitly, but if unlogged decoder states affect routing, the decomposition would miss the controlling term, undermining the claims.
minor comments (1)
- The abstract contains a formatting artifact '5{,}400' which should be clarified as 5,400 events.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below, providing clarifications on the derivations and assumptions while indicating planned revisions.
read point-by-point responses
-
Referee: The C3 attacked-dependence decomposition and separation theorem are introduced without derivation steps or proof details in the provided abstract, making it difficult to assess whether they are independently grounded or potentially circular with the audit observables.
Authors: The full manuscript derives the audit-schema separation theorem and C3 attacked-dependence decomposition from the minimal log schema and denominator hierarchy in the sections immediately following the Route-Safety Audit Contract definition. These establish that clean agreement and marginal robustness fail to identify the joint term controlling C3 routing, using observable separation properties that do not reference decoder internals. The reasoning is not circular, as it begins from the contract's explicit observables. We will add a concise proof sketch to the revised introduction or appendix to improve accessibility beyond the abstract. revision: yes
-
Referee: The reported blocking rates (e.g., provenance blocks C2 routes (0.000)) and conformal frontier depend on the assumption that the audit log schema captures the observable information controlling routing decisions independent of decoder internals. The manuscript states this explicitly, but if unlogged decoder states affect routing, the decomposition would miss the controlling term, undermining the claims.
Authors: The Route-Safety Audit Contract is defined strictly on the observable log schema, and the separation theorem applies conditional on that schema capturing the routing decisions. The manuscript repeatedly emphasizes that route safety depends on audit-log observables rather than decoder accuracy or internals. The threat model and empirical results (including the 0.000 blocking rates and conformal bounds) are conditioned on this logged information; attacks that evade the log fall outside the contract by construction. We will add an explicit discussion of this boundary condition and its implications for the decomposition in the revised manuscript. revision: yes
Circularity Check
C3 attacked-dependence decomposition and separation theorem co-defined with audit contract
specific steps
-
self definitional
[Abstract]
"We define a Route-Safety Audit Contract: a minimal log schema, denominator hierarchy, and endpoint specification, and prove an audit-schema separation theorem together with a C3 attacked-dependence decomposition; clean agreement and marginal robustness do not identify the joint term that controls C3 routing."
The theorem and decomposition are derived directly from the audit contract defined in the same sentence; the reported route-blocking rates are presented as consequences of this decomposition, which assumes by definition that the log observables fully determine C3 routing independent of decoder internals.
full rationale
The paper introduces the Route-Safety Audit Contract and immediately proves the separation theorem plus C3 decomposition from it in the same work. The headline empirical claims (provenance blocks C2 at 0.000; agreement+provenance routes C3 flips at 1.000) are then interpreted exclusively through that decomposition, which by construction treats the proposed log fields as capturing all routing controls. This reduces the interpretive step to the definitions themselves rather than an independent grounding. No external verification or machine-checked theorem is cited; the assumption that unlogged decoder states do not modulate routing is baked into the schema.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (1)
- domain assumption Route safety is determined by what the audit log can observe rather than decoder accuracy or agreement alone.
invented entities (2)
-
brain-prompt injection
no independent evidence
-
C3 attacked-dependence decomposition
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy, pages 39--57, 2017
2017
-
[2]
Goldberger, Luis A
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. PhysioBank , PhysioToolkit , and PhysioNet : Components of a new research resource for complex physiologic signals. Circulation, 101(23):e215--e220, 2000
2000
-
[3]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you've signed up for: Compromising real-world LLM -integrated applications with indirect prompt injection. arXiv preprint arXiv:2302.12173, 2023
Pith/arXiv arXiv 2023
-
[4]
Lawhern, Amelia J
Vernon J. Lawhern, Amelia J. Solon, Nicholas R. Waytowich, Stephen M. Gordon, Chou P. Hung, and Brent J. Lance. EEGNet : A compact convolutional neural network for EEG -based brain--computer interfaces. Journal of Neural Engineering, 15(5):056013, 2018
2018
-
[5]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In International Conference on Learning Representations, 2018
2018
-
[6]
Metzger, Kaylo T
Sean L. Metzger, Kaylo T. Littlejohn, Alexander B. Silva, David A. Moses, Margaret P. Seaton, Ran Wang, Maximilian E. Dougherty, Jessie R. Liu, Peter Wu, Michael A. Berger, Irina Zhuravleva, Adelyn Tu-Chan, Karunesh Ganguly, Gopala K. Anumanchipalli, and Edward F. Chang. A high-performance neuroprosthesis for speech decoding and avatar control. Nature, 62...
2023
-
[7]
Berkay Celik, and Ananthram Swami
Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z. Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In IEEE European Symposium on Security and Privacy, pages 372--387, 2016
2016
-
[8]
ToolLLM : Facilitating large language models to master 16000+ real-world API s
Yujia Qin, Shengding Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM : Facilitating large language models to master 16000+ real-world API s. arXiv preprint arXiv:2307.16789, 2023
Pith/arXiv arXiv 2023
-
[9]
McFarland, Thilo Hinterberger, Niels Birbaumer, and Jonathan R
Gerwin Schalk, Dennis J. McFarland, Thilo Hinterberger, Niels Birbaumer, and Jonathan R. Wolpaw. BCI2000 : A general-purpose brain--computer interface system. IEEE Transactions on Biomedical Engineering, 51(6):1034--1043, 2004
2004
-
[10]
Toolformer : Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer : Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023
Pith/arXiv arXiv 2023
-
[11]
Ensemble adversarial training: Attacks and defenses
Florian Tram \`e r, Alexey Kurakin, Nicolas Papernot, Ian Goodfellow, Dan Boneh, and Patrick McDaniel. Ensemble adversarial training: Attacks and defenses. In International Conference on Learning Representations, 2018
2018
-
[12]
Jailbroken: How does LLM safety training fail? arXiv preprint arXiv:2307.02483, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? arXiv preprint arXiv:2307.02483, 2023
Pith/arXiv arXiv 2023
-
[13]
Willett, Donald T
Francis R. Willett, Donald T. Avansino, Leigh R. Hochberg, Jaimie M. Henderson, and Krishna V. Shenoy. High-performance brain-to-text communication via handwriting. Nature, 593:249--254, 2021
2021
-
[14]
Brandon Westover, and Jimeng Sun
Chaoqi Yang, M. Brandon Westover, and Jimeng Sun. BIOT : Biosignal transformer for cross-data learning in the wild. Advances in Neural Information Processing Systems, 36, 2023
2023
-
[15]
On the vulnerability of CNN classifiers in EEG -based BCI s
Xiao Zhang and Dongrui Wu. On the vulnerability of CNN classifiers in EEG -based BCI s. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 27(5):814--825, 2019
2019
-
[16]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[17]
Algorithmic Learning in a Random World
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer. Algorithmic Learning in a Random World. Springer, 2005
2005
-
[18]
Cand\` e s
Yaniv Romano, Evan Patterson, and Emmanuel J. Cand\` e s. Conformalized quantile regression. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[19]
Large brain model for learning generic representations with tremendous EEG data in BCI
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. Large brain model for learning generic representations with tremendous EEG data in BCI . In International Conference on Learning Representations (ICLR), Spotlight, 2024
2024
-
[20]
InjecAgent : Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent : Benchmarking indirect prompt injections in tool-integrated large language model agents. In Findings of the Association for Computational Linguistics: ACL 2024, pages 10471--10506, 2024
2024
-
[21]
AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi \'c , Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[22]
Benchmarking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Keegan Hines, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Benchmarking and defending against indirect prompt injection attacks on large language models. arXiv preprint arXiv:2312.14197, 2023
arXiv 2023
-
[23]
Brain-to-text decoding: A non-invasive approach via typing
Jarod L \'e vy, Mingfang Zacharias, Omar Chehab, Hubert Banville, Daoud Tabbal, Alexandre Defossez, and Jean-R \'e mi King. Brain-to-text decoding: A non-invasive approach via typing. arXiv preprint arXiv:2502.17480, 2025
arXiv 2025
-
[24]
Agent Security Bench ( ASB ): Formalizing and benchmarking attacks and defenses in LLM -based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent Security Bench ( ASB ): Formalizing and benchmarking attacks and defenses in LLM -based agents. arXiv preprint arXiv:2410.02644, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.