Capacity, Not Format: Rethinking Structured Reasoning Failures
Pith reviewed 2026-06-27 16:32 UTC · model grok-4.3
The pith
Structured output formats degrade reasoning only in models operating near their capacity limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
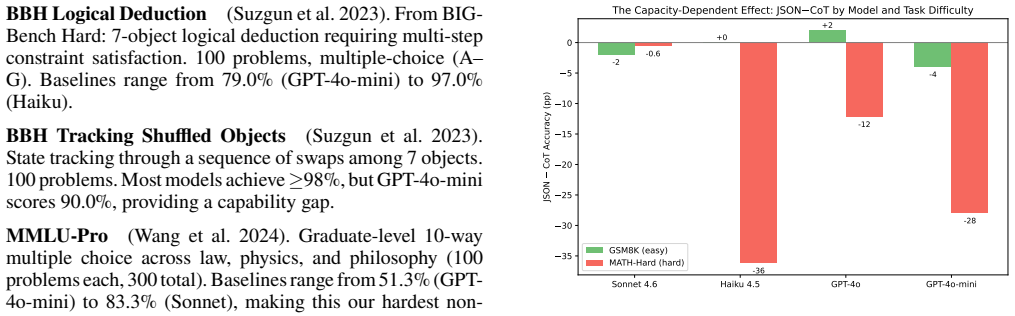
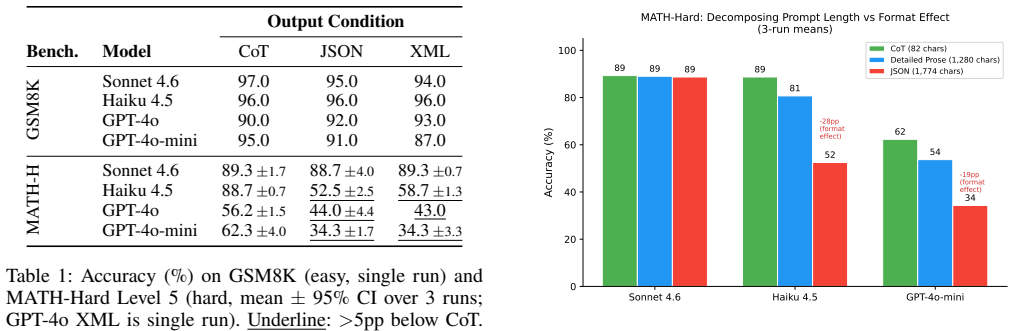
Structured formats are capacity-dependent. Models with sufficient headroom absorb JSON constraints without degradation, as seen when Sonnet maintains 88.7% on MATH-Hard under JSON versus 89.3% under CoT. In contrast, models near their limits drop sharply: Haiku loses 36.2 percentage points largely from truncation under standard budgets, while GPT-4o-mini loses 28.0 points even with extended budgets that eliminate truncation. The penalty scales with schema complexity and is not explained by prompt length. A delayed-structure ablation that lets the model reason freely before formatting recovers most of the lost accuracy.
What carries the argument
information-matched prose controls combined with a four-level schema complexity gradient that isolate format effects across models and benchmarks
If this is right
- Models with headroom can adopt structured output without accuracy loss on the tested benchmarks.
- Models near capacity limits suffer either truncation or direct resource competition when forced to format.
- The accuracy penalty increases reliably with the number of required fields and nesting depth.
- Allowing unrestricted reasoning before applying structure restores most of the lost performance.
Where Pith is reading between the lines
- Prompting strategies could dynamically switch between free-form and structured modes based on estimated remaining capacity for a given task.
- Training objectives that explicitly reward both reasoning quality and format adherence might reduce the observed capacity competition.
- Evaluation suites for new models should report structured versus unstructured accuracy as a function of task difficulty to surface capacity headroom.
Load-bearing premise
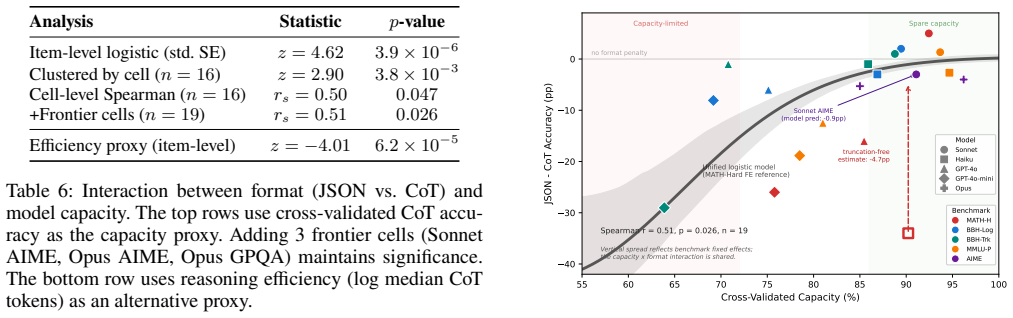
The prose controls and schema gradient successfully separate format-specific costs from prompt length and other confounds.
What would settle it
Observing comparable performance drops under JSON even in models with large headroom on information-matched tasks would falsify the capacity-dependence claim.
Figures
read the original abstract
Prior work treats structured output as a reasoning tax, but this framing is incomplete: the cost of formatting depends strongly on a model's spare capacity. Using information-matched prose controls and a four-level schema complexity gradient, we separate format-specific effects from prompt-length confounds across 4 models and 5 benchmarks with 0% parse failures on successfully generated responses. We find that structured formats are capacity-dependent. Models with sufficient headroom absorb JSON constraints without degradation (Sonnet: $88.7\pm4.0$% JSON vs. $89.3\pm1.7$% CoT on MATH-Hard). In contrast, formats severely degrade models operating near their limits through two distinct mechanisms. First, under standard token budgets, Haiku drops 36.2pp ($p < 0.0001$) largely due to truncation. Second, even with extended budgets eliminating truncation, GPT-4o-mini drops 28.0pp ($p < 0.001$), revealing pure capacity competition independent of token exhaustion. This format penalty scales with schema complexity (McNemar $p < 0.0001$) and cannot be explained by prompt length alone. Furthermore, these results qualify claims of frontier model immunity: on AIME competition math, Opus 4.7 drops from 96.2% to 91.0% under JSON ($-5.3$pp; the displayed percentages are independently rounded, exact difference is $7/133 = 5.26$pp $\approx 5.3$pp). A delayed-structure ablation -- reasoning freely before formatting -- recovers most of the lost accuracy (3-run mean: 80--87%), supporting the capacity competition mechanism. The practical implication is not to avoid structured output, but to match it to capacity: when a model is near its limits, think first, format later.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that structured output formats like JSON impose a capacity-dependent cost on LLMs rather than an inherent reasoning tax. Using information-matched prose controls and a four-level schema complexity gradient across 4 models and 5 benchmarks, it shows high-capacity models absorb JSON without degradation (e.g., Sonnet 88.7% JSON vs 89.3% CoT on MATH-Hard), while lower-capacity models suffer large drops (Haiku 36.2pp due to truncation; GPT-4o-mini 28.0pp even with extended budgets), with the penalty scaling by schema complexity (McNemar p<0.0001) and a delayed-structure ablation recovering most accuracy (80-87%).
Significance. If the results hold, the work reframes structured reasoning failures around capacity competition rather than format, with practical implications for deployment (think first, format later). Strengths include the multi-model/multi-benchmark design, statistical tests, ablation, and explicit handling of parse failures and rounding details, providing falsifiable empirical evidence that qualifies claims of frontier model immunity.
major comments (2)
- [Abstract/Experimental Design] Abstract/Experimental Design: The central claim that penalties reflect capacity competition (not format-specific planning) depends on information-matched prose controls successfully isolating effects. The abstract describes the matching and schema gradient but provides no details on verification of equivalent output planning or constraint satisfaction loads, leaving open whether JSON imposes additional demands that interact with capacity (as noted in the stress-test concern).
- [Results (GPT-4o-mini)] Results (GPT-4o-mini): The 28.0pp drop (p<0.001) with extended budgets is load-bearing evidence for 'pure capacity competition independent of token exhaustion.' Without explicit description of budget extension implementation, confirmation that truncation was eliminated across all cases, and full controls for other variables, this distinction is difficult to assess from the provided summary.
minor comments (2)
- [Abstract] Abstract: The parenthetical on exact difference calculation (7/133 = 5.26pp) for Opus is precise; retain and expand in main text for transparency.
- [Abstract] Abstract: Specify the 5 benchmarks and exact four-level schema complexities to support replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity of our experimental controls and implementation details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract/Experimental Design] Abstract/Experimental Design: The central claim that penalties reflect capacity competition (not format-specific planning) depends on information-matched prose controls successfully isolating effects. The abstract describes the matching and schema gradient but provides no details on verification of equivalent output planning or constraint satisfaction loads, leaving open whether JSON imposes additional demands that interact with capacity (as noted in the stress-test concern).
Authors: The full manuscript (Section 3.2 and Appendix A) details the information-matching procedure, including manual verification on a 200-sample subset for equivalent planning demands and automated constraint-satisfaction checks. We agree the abstract is too concise on this point and will revise it to briefly reference the verification steps while adding an explicit paragraph on load-equivalence testing in the methods section. revision: yes
-
Referee: [Results (GPT-4o-mini)] Results (GPT-4o-mini): The 28.0pp drop (p<0.001) with extended budgets is load-bearing evidence for 'pure capacity competition independent of token exhaustion.' Without explicit description of budget extension implementation, confirmation that truncation was eliminated across all cases, and full controls for other variables, this distinction is difficult to assess from the provided summary.
Authors: The paper already reports 0% truncation and parse failures under extended budgets (Table 2), but we concur that the implementation protocol requires more explicit description. In revision we will add a dedicated methods subsection specifying the exact budget-doubling procedure, the two-stage generation process, per-run truncation verification (zero cases observed), and cross-references to the full variable controls in Appendix C. revision: yes
Circularity Check
No circularity: purely empirical comparisons with no derivations or self-referential reductions
full rationale
The paper reports direct experimental results across 4 models and 5 benchmarks using information-matched controls, schema gradients, and a delayed-structure ablation. All claims rest on observed accuracy deltas, McNemar tests, and truncation analysis rather than any equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain exists that could reduce outputs to inputs by construction. The central capacity-competition claim is supported by independent measurements (e.g., 28pp drop under extended budgets) and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Information-matched prose controls and schema complexity gradient isolate format effects from length confounds
Reference graph
Works this paper leans on
-
[1]
Banerjee, D.; Suresh, T.; Ugare, S.; Misailovic, S.; and Singh, G. 2025. CRANE : Reasoning with Constrained LLM Generation. In Proceedings of the International Conference on Machine Learning
2025
-
[2]
Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; Hesse, C.; and Schulman, J. 2021. Training Verifiers to Solve Math Word Problems. arXiv preprint arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[3]
Hendrycks, D.; Burns, C.; Kadavath, S.; Arora, A.; Basart, S.; Tang, E.; Song, D.; and Steinhardt, J. 2021. Measuring Mathematical Problem Solving With the MATH Dataset. In NeurIPS Datasets and Benchmarks
2021
-
[4]
B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; and Amodei, D
Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T. B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; and Amodei, D. 2020. Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361
Pith/arXiv arXiv 2020
-
[5]
Y.; D'Antoni, L.; and Berg-Kirkpatrick, T
Lee, I. Y.; D'Antoni, L.; and Berg-Kirkpatrick, T. 2026. The Format Tax. arXiv preprint arXiv:2604.03616
Pith/arXiv arXiv 2026
-
[6]
X.; Ngoc, H
Long, D. X.; Ngoc, H. N.; Sim, T.; Dao, H.; Joty, S.; Kawaguchi, K.; Chen, N. F.; and Kan, M.-Y. 2025. LLMs Are Biased Towards Output Formats! Systematically Evaluating and Mitigating Output Format Bias of LLMs . In Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics
2025
-
[7]
Ray, J. 2026. The Constraint Tax: Measuring Validity-Correctness Tradeoffs in Structured Outputs for Small Language Models. arXiv preprint arXiv:2605.26128
Pith/arXiv arXiv 2026
-
[8]
W.; Chowdhery, A.; Le, Q.; Chi, E.; Zhou, D.; and Wei, J
Suzgun, M.; Scales, N.; Sch \"a rli, N.; Gehrmann, S.; Tay, Y.; Chung, H. W.; Chowdhery, A.; Le, Q.; Chi, E.; Zhou, D.; and Wei, J. 2023. Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them. In Findings of the Association for Computational Linguistics: ACL 2023
2023
-
[9]
R.; Wu, C.-K.; Tsai, Y.-L.; Lin, C.-Y.; Lee, H.-y.; and Chen, Y.-N
Tam, Z. R.; Wu, C.-K.; Tsai, Y.-L.; Lin, C.-Y.; Lee, H.-y.; and Chen, Y.-N. 2024. Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track
2024
-
[10]
Wang, Y.; Ma, X.; Zhang, G.; Ni, Y.; Chandra, A.; Guo, S.; Ren, W.; Arulraj, A.; He, X.; Jiang, Z.; et al. 2024. MMLU-Pro : A More Robust and Challenging Multi-Task Language Understanding Benchmark. Advances in Neural Information Processing Systems, 37
2024
-
[11]
Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. 2022 a . Emergent Abilities of Large Language Models. Transactions on Machine Learning Research
2022
-
[12]
Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; and Zhou, D. 2022 b . Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems, 35
2022
-
[13]
Yang, L.; Yu, Z.; Cui, B.; and Wang, M. 2025. ReasonFlux : Hierarchical LLM Reasoning via Scaling Thought Templates. arXiv preprint arXiv:2502.06772
arXiv 2025
-
[14]
L.; Cao, Y.; and Narasimhan, K
Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T. L.; Cao, Y.; and Narasimhan, K. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In Advances in Neural Information Processing Systems, volume 36
2023
-
[15]
Yuan, H.; Zhao, Y.; Zhang, L.; Luo, W.; and Ma, Z. 2026. Quantifying the Impact of Structured Output Format on Large Language Models through Causal Inference. Findings of the European Chapter of the Association for Computational Linguistics
2026
-
[16]
Zhou, H. 2026. From Hallucination to Structure Snowballing: The Alignment Tax of Constrained Decoding in LLM Reflection. arXiv preprint arXiv:2604.06066
Pith/arXiv arXiv 2026
-
[17]
V.; Chi, E
Zhou, P.; Pujara, J.; Ren, X.; Chen, X.; Cheng, H.-T.; Le, Q. V.; Chi, E. H.; Zhou, D.; Mishra, S.; and Zheng, H. S. 2024. Self-Discover: Large Language Models Self-Compose Reasoning Structures. In Advances in Neural Information Processing Systems, volume 37
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.