Deterministic Integrity Gates for LLM-Assisted Clinical Manuscript Preparation: An Auditable Biomedical Informatics Architecture
Pith reviewed 2026-06-27 16:09 UTC · model grok-4.3
The pith
Deterministic integrity gates paired with LLM generation create an auditable verification trail for clinical manuscripts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that resolving each integrity question with the cheapest sufficient mechanism—a deterministic check where one suffices—yields an auditable, re-executable trail that exposes the evidence needed to check an LLM-assisted manuscript.
What carries the argument
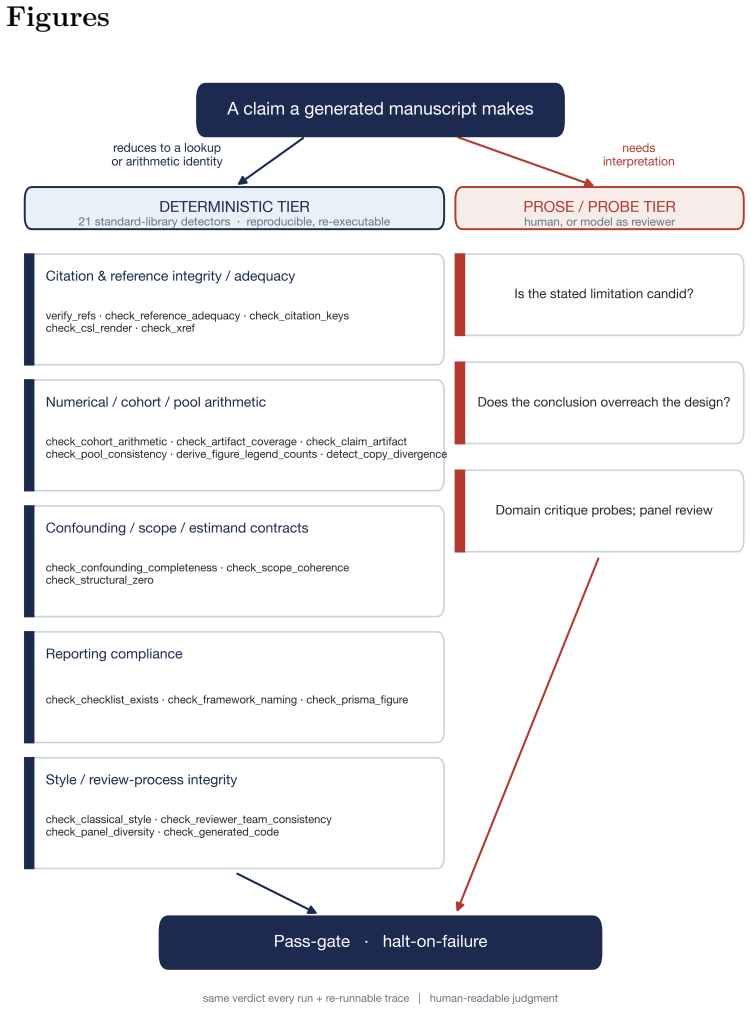
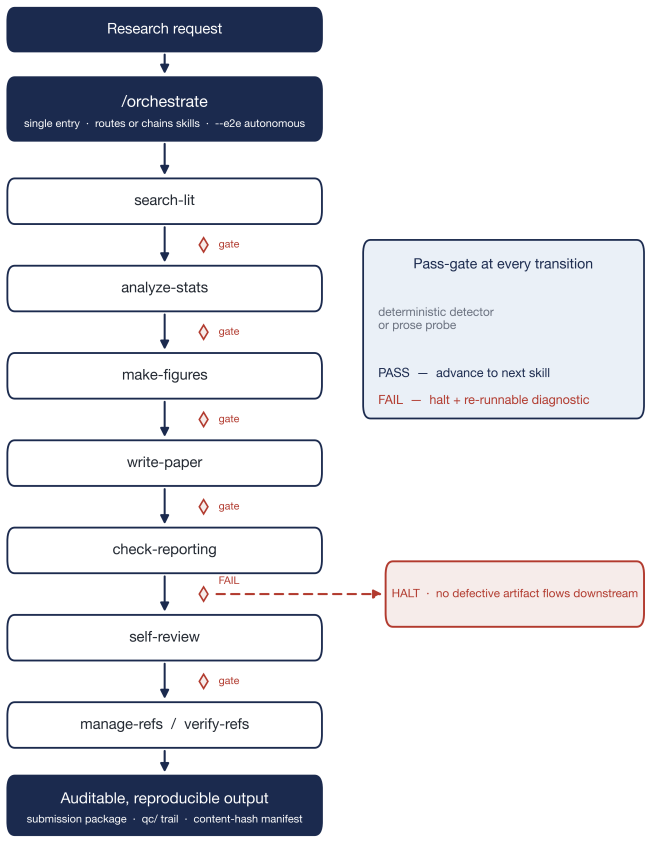
The integrity-gate taxonomy that decomposes the workflow into self-contained skills and applies halt-on-failure at each stage transition, using deterministic checks for 21 of the 43 skills.
If this is right
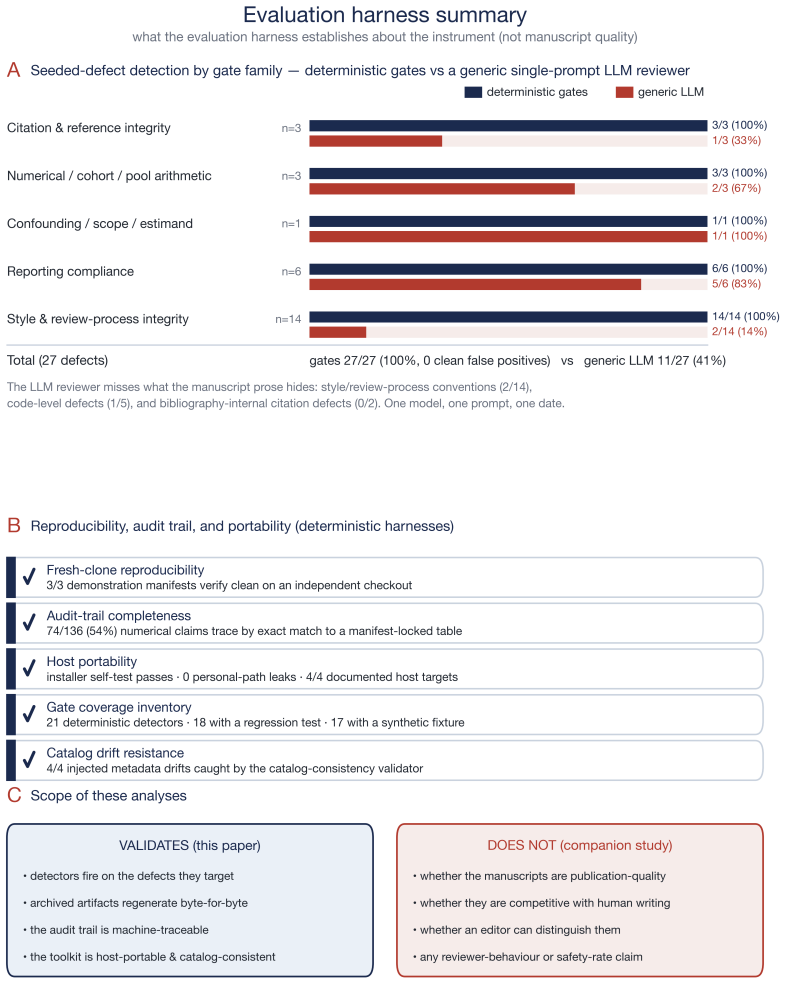
- Across three public-dataset pipelines every content-hash manifest verified clean and the gates surfaced real defects.
- On 27 identical injected defects the deterministic gates detected all 27 with no false positives on the matched clean fixtures.
- A single-prompt LLM reviewer detected only 11 of the 27 defects, missing those in code, bibliography, and style.
- The architecture provides feasibility and reproducibility evidence rather than a claim of human-competitive quality.
Where Pith is reading between the lines
- Similar deterministic verification layers could be developed for non-clinical domains where LLMs assist in technical writing.
- Applying the toolkit to a larger set of real LLM-generated manuscripts could test if the seeded defects represent typical error distributions.
- Integration with autonomous research agents might reduce the need for post-hoc human review in manuscript production.
Load-bearing premise
That the cheapest sufficient mechanism for each integrity question can be identified in advance as either a deterministic re-executable check or a prose-level probe, and that the seeded-defect ablation adequately represents real defects.
What would settle it
Observing a clinical manuscript prepared with LLMs that passes all deterministic gates but contains a fabricated citation or unmet reporting guideline item that affects the paper's validity.
Figures
read the original abstract
As autonomous research agents and AI co-scientist systems push large language models (LLMs) from drafting toward end-to-end manuscript production, the bottleneck shifts from generation to verification. Fluent LLM output can hide fabricated citations, numbers that drift from source tables, and unmet reporting-guideline items; existing tools generate without verifying, and self-critique inherits the blind spots that produce confident fabrication. We describe an architecture pairing generation with verification, resting on three principles: decompose the workflow into self-contained skills, gate every stage transition with halt-on-failure, and resolve each integrity question with the cheapest sufficient mechanism, a deterministic, re-executable check where one suffices and a prose-level probe only where interpretation is unavoidable. This determinism-where-possible split, organized as an integrity-gate taxonomy, is the core contribution. It is realized as MedSci Skills, an open-source toolkit of 43 skills with a 21-detector deterministic tier, evaluated on three public-dataset pipelines (STARD, PRISMA, STROBE) and a seeded-defect ablation. Across the three pipelines every content-hash manifest verified clean and the gates surfaced real defects; on 27 identical injected defects the deterministic gates detected all 27 with no false positives on the matched clean fixtures, whereas a single-prompt LLM reviewer detected 11, its misses in code, bibliography, and style defects the prose hides. Determinism-where-possible verification yields an auditable, re-executable trail that exposes the evidence a human needs to check an LLM-assisted manuscript: feasibility and reproducibility evidence, not a claim of human-competitive quality, which a separate blinded study addresses. MedSci Skills is MIT-licensed and archived (v3.8.0).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a determinism-where-possible integrity-gate architecture for LLM-assisted clinical manuscript preparation. It decomposes workflows into 43 skills (21 deterministic detectors) organized as an integrity-gate taxonomy, with halt-on-failure gates at stage transitions. The approach is implemented in the open-source MedSci Skills toolkit and evaluated on STARD, PRISMA, and STROBE public-dataset pipelines plus a seeded-defect ablation, reporting that all content-hash manifests verified clean, all 27 identical injected defects were detected with zero false positives on clean fixtures, and the deterministic tier outperformed a single-prompt LLM reviewer (which detected only 11). The central claim is that this yields an auditable, re-executable verification trail focused on feasibility and reproducibility evidence.
Significance. If the evaluation generalizes, the work provides a concrete, open-source mechanism for verifiable integrity in AI-assisted biomedical writing, addressing fabrication risks that self-critique cannot reliably catch. Strengths include the use of public datasets, explicit seeding independent of system design, MIT licensing, and the emphasis on re-executable checks over prose-level probes where possible.
major comments (2)
- [Abstract / evaluation] Abstract and evaluation description: The seeded-defect ablation relies on 27 identical injected defects rather than a diverse sample drawn from actual LLM outputs. This choice is load-bearing for the claim that the 21-detector tier yields a reliable auditable trail, because the reported perfect detection and zero false positives may not extend to subtler, context-dependent defects (e.g., fabricated citations or unmet guideline items) that arise in real LLM-assisted manuscripts.
- [Methods] Methods / pipeline details: Exact implementations of the 21 deterministic detectors, the content-hash manifest verification procedure, and the three public-dataset pipelines are not described at a level that permits independent reproduction or assessment of why the deterministic tier detected all seeded defects while the LLM reviewer missed code, bibliography, and style issues.
minor comments (1)
- [Abstract] The abstract states that a separate blinded study addresses human-competitive quality; this distinction should be cross-referenced explicitly in the evaluation section to avoid conflating feasibility evidence with performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract / evaluation] Abstract and evaluation description: The seeded-defect ablation relies on 27 identical injected defects rather than a diverse sample drawn from actual LLM outputs. This choice is load-bearing for the claim that the 21-detector tier yields a reliable auditable trail, because the reported perfect detection and zero false positives may not extend to subtler, context-dependent defects (e.g., fabricated citations or unmet guideline items) that arise in real LLM-assisted manuscripts.
Authors: The seeded-defect ablation uses 27 identical injected defects to provide a controlled, reproducible test of the deterministic detectors on specific, verifiable integrity issues (e.g., missing code, bibliography, or style elements), demonstrating perfect detection and zero false positives on matched clean fixtures. This supports the architecture's goal of an auditable, re-executable trail for defects amenable to deterministic checks. The manuscript does not claim these results extend to all subtler or context-dependent defects, which fall outside deterministic verification and are addressed via complementary LLM review and human oversight. The public-dataset pipeline evaluations provide additional evidence of feasibility. We therefore see no need to alter the evaluation design. revision: no
-
Referee: [Methods] Methods / pipeline details: Exact implementations of the 21 deterministic detectors, the content-hash manifest verification procedure, and the three public-dataset pipelines are not described at a level that permits independent reproduction or assessment of why the deterministic tier detected all seeded defects while the LLM reviewer missed code, bibliography, and style issues.
Authors: We agree that greater detail on the detector implementations, manifest verification, and pipelines would improve reproducibility. In the revised manuscript we will expand the Methods section with additional specifications, pseudocode outlines for the 21 detectors, and explicit descriptions of the content-hash procedure and the three public-dataset pipelines to clarify the observed performance differences. revision: yes
Circularity Check
No significant circularity; evaluation independent of design choices
full rationale
The paper describes an architecture and open-source toolkit evaluated on public datasets (STARD, PRISMA, STROBE) plus an explicitly seeded-defect ablation using 27 injected defects. No equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked as load-bearing for any derivation or uniqueness claim. The deterministic tier and detection results are not reduced by construction to quantities defined by the authors' prior choices; the evaluation fixtures are independent. This is a standard non-circular systems paper whose central claims rest on external public data and controlled injections rather than self-referential definitions or fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal large language models in medical imaging: Current state and future directions
Nam Y, Kim DY, Kyung S, Seo J, Song JM, Kwon J, et al. Multimodal large language models in medical imaging: Current state and future directions. Korean Journal of Radiology. 2025;26:900. https://doi.org/10.3348/kjr.2025.0599
-
[2]
The diffusion of large language models in published academic articles
Siler K. The diffusion of large language models in published academic articles. Proceedings of the National Academy of Sciences. 2026;123:e2605754123. https://doi.org/10.1073/pnas.2605754123
-
[3]
Walters and Esther Isabelle Wilder
Walters WH, Wilder EI. Fabrication and errors in the bibliographic citations generated by ChatGPT. Scientific Reports. 2023;13. https://doi.org/10.1038/s41598-023-41032-5
-
[4]
Simera I, Moher D, Hoey J, Schulz KF, Altman DG. The EQUATOR network and reporting guidelines: Helping to achieve high standards in reporting health research studies. Maturitas. 2009;63:4–6. https://doi.org/10.1016/j.maturitas.2009.03.011
-
[5]
Collins GS, Moons KGM, Dhiman P, Riley RD, Beam AL, Van Calster B, et al. TRIPOD+AI statement: Updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ. 2024;e078378. https://doi.org/10.1136/bmj-2023-078378
-
[6]
Checklist for artificial intelligence in medical imaging (CLAIM): 2024 update
Tejani AS, Klontzas ME, Gatti AA, Mongan JT, Moy L, Park SH, et al. Checklist for artificial intelligence in medical imaging (CLAIM): 2024 update. Radiology: Artificial Intelligence. 2024;6. https://doi.org/10.1148/ryai.240300
-
[7]
McInnes MDF, Moher D, Thombs BD, McGrath TA, Bossuyt PM, and the PRISMA-DTA Group, et al. Preferred reporting items for a systematic review and meta-analysis of diagnostic test accuracy studies. JAMA. 2018;319:388. https://doi.org/10.1001/jama.2017.19163
-
[8]
Self-refine: Iterative refinement with self-feedback
Madaan A, Tandon N, Gupta P, Hallinan S, Gao L, Wiegreffe S, et al. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems (NeurIPS). 2023
2023
-
[9]
Reflexion: Language agents with verbal reinforcement learning
Shinn N, Cassano F, Berman E, Gopinath A, Narasimhan K, Yao S. Reflexion: Language agents with verbal reinforcement learning. Advances in neural information processing systems (NeurIPS). 2023
2023
-
[10]
Large language models cannot self-correct reasoning yet
Huang J, Chen X, Mishra S, Zheng HS, Yu A W, Song X, et al. Large language models cannot self-correct reasoning yet. International conference on learning representations (ICLR). 2024
2024
-
[12]
STARD 2015: An updated list of essential items for reporting diagnostic accuracy studies
Bossuyt PM, Reitsma JB, Bruns DE, Gatsonis CA, Glasziou PP, Irwig L, et al. STARD 2015: An updated list of essential items for reporting diagnostic accuracy studies. BMJ. 2015;h5527. https://doi.org/10.1136/bmj.h5527
-
[13]
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. The 18 PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ. 2021;n71. https://doi.org/10.1136/bmj.n71
-
[14]
Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement. BMJ. 2015;350:g7594–4. https://doi.org/10.1136/bmj.g7594
-
[15]
Sounderajah V, Ashrafian H, Golub RM, Shetty S, De Fauw J, Hooft L, et al. Developing a reporting guideline for artificial intelligence-centred diagnostic test accuracy studies: The STARD- AI protocol. BMJ Open. 2021;11:e047709. https://doi.org/10.1136/bmjopen-2020-047709
-
[16]
Agent skills specification
Agent Skills. Agent skills specification. https://agentskills.io/specification; 2025
2025
-
[17]
Towards end-to-end automation of ai research.Nature, 651(8107):914–919, March 2026
Lu C, Lu C, Lange RT, Yamada Y, Hu S, Foerster J, et al. Towards end-to-end automation of AI research. Nature. 2026;651:914–9. https://doi.org/10.1038/s41586-026-10265-5
-
[18]
Gottweis J, Weng W-H, Daryin A, Tu T, Sirkovic P, Myaskovsky A, et al. Accelerating scientific discovery with co-scientist. Nature. 2026; https://doi.org/10.1038/s41586-026-10644-y
-
[19]
Engineering AI co-scientists for statistical genetics applications
Zhao B. Engineering AI co-scientists for statistical genetics applications. Nature Genetics. 2026;58:236–9. https://doi.org/10.1038/s41588-025-02487-6
-
[20]
Exploring the role of large language models in the scientific method: From hypothesis to discovery
Zhang Y, Khan SA, Mahmud A, Yang H, Lavin A, Levin M, et al. Exploring the role of large language models in the scientific method: From hypothesis to discovery. npj Artificial Intelligence. 2025;1. https://doi.org/10.1038/s44387-025-00019-5
-
[21]
Chelli M, Descamps J, Lavoué V, Trojani C, Azar M, Deckert M, et al. Hallucination rates and reference accuracy of ChatGPT and bard for systematic reviews: Comparative analysis. Journal of Medical Internet Research. 2024;26:e53164. https://doi.org/10.2196/53164
-
[22]
Topaz M, Roguin N, Gupta P, Zhang Z, Peltonen L-M. Fabricated citations: An audit across 2·5 million biomedical papers. The Lancet. 2026;407:1779–81. https://doi.org/10.1016/S0140- 6736(26)00603-3
-
[23]
RobotReviewer: Evaluation of a system for automati- cally assessing bias in clinical trials
Marshall IJ, Kuiper J, Wallace BC. RobotReviewer: Evaluation of a system for automati- cally assessing bias in clinical trials. Journal of the American Medical Informatics Association. 2016;23:193–201. https://doi.org/10.1093/jamia/ocv044
-
[24]
RARR : Researching and Revising What Language Models Say, Using Language Models
Gao L, Dai Z, Pasupat P, Chen A, Chaganty AT, Fan Y, et al. RARR: Researching and revising what language models say, using language models. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers). 2023. p. 16477–508. https://doi.org/10.18653/v1/2023.acl-long.910
-
[25]
Rebedea T, Dinu R, Sreedhar MN, Parisien C, Cohen J. NeMo guardrails: A toolkit for controllable and safe LLM applications with programmable rails. Proceedings of the 2023 conference on empirical methods in natural language processing: System demonstrations. 2023. p. 431–45. https://doi.org/10.18653/v1/2023.emnlp-demo.40 19
-
[26]
Wilkinson MD, Dumontier M, Aalbersberg IjJ, Appleton G, Axton M, Baak A, et al. The F AIR guiding principles for scientific data management and stewardship. Scientific Data. 2016;3. https://doi.org/10.1038/sdata.2016.18
-
[27]
FORCE11 Software Citation Working Group
Smith AM, Katz DS, Niemeyer KE, FORCE11 Software Citation Working Group. Software citation principles. PeerJ Computer Science. 2016;2:e86. https://doi.org/10.7717/peerj-cs.86
-
[28]
Park SH, Suh CH, Lee JH, Kahn CE, Moy L. Minimum reporting items for clear evaluation of accuracy reports of large language models in healthcare (MI-CLEAR-LLM). Korean Journal of Radiology. 2024;25:865. https://doi.org/10.3348/kjr.2024.0843
-
[29]
AI-induced never-skilling in medical education
Ke Y, Jin L, Ong JCL, Thirunavukarasu AJ, Car J, Cheung CY, et al. AI-induced never-skilling in medical education. Nature Medicine. 2026; https://doi.org/10.1038/s41591-026-04438-y
-
[30]
Park CY, Matsumoto S, Park HS, Oh Y, Lee J. When to stop decomposing: LLM-assisted quality gates for functional decomposition in systems engineering. IEEE Access. 2026;14:57427–43. https://doi.org/10.1109/ACCESS.2026.3683195 20 Figures Figure 1. Integrity-gate taxonomy . Each integrity question a generated manuscript raises is routed by whether it reduces...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.