Visual Prompting Meets Feature Reconstruction-Based Anomaly Detection with Dual-Teacher Supervision
Pith reviewed 2026-06-27 17:21 UTC · model grok-4.3
The pith
Visual prompting for object isolation combined with dual-teacher adaptation and diffusion augmentation improves anomaly detection by 3.5 points on the AeBAD dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
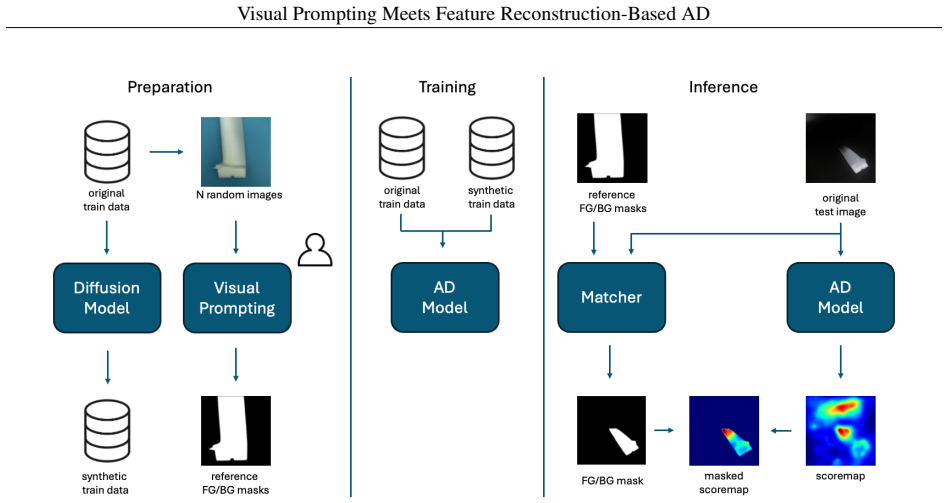
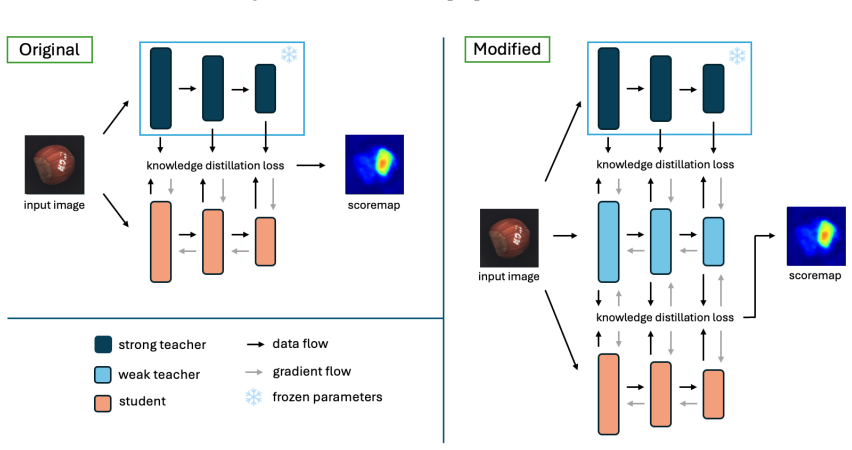
By integrating a visual prompting pipeline that isolates objects using foreground-background masking, unfreezing the teacher in student-teacher models to improve domain adaptability, and leveraging diffusion-generated synthetic images for data augmentation, the Masked Multiscale Reconstruction model achieves a 3.5 percentage point improvement over the previous state-of-the-art on the AeBAD dataset.
What carries the argument
The visual prompting pipeline for foreground-background masking that isolates the object of interest, together with the mechanism for unfreezing the teacher and the diffusion-based augmentation strategy.
If this is right
- Anomaly detection methods can now handle datasets with significant variations in object placement and conditions, extending usability beyond controlled environments like MVTec.
- The improvements on AeBAD demonstrate that these modifications allow reconstruction-based approaches to maintain high performance under real-world violations of foundational assumptions.
- Integrating visual prompting with existing feature reconstruction models like MMR provides a pathway to enhance other anomaly detection frameworks.
- Using synthetic images from diffusion models helps mitigate the scarcity of anomalous samples in training data.
Where Pith is reading between the lines
- The masking step may enable application to multi-object scenes if extended appropriately.
- Similar adaptations could benefit other computer vision tasks facing domain shifts, such as object detection in varied environments.
- Further gains might come from combining this with other backbones beyond MMR.
- Validation on additional real-world anomaly datasets would strengthen the case for generalizability.
Load-bearing premise
The foreground-background masking produced by the visual prompting pipeline reliably isolates the object of interest even under the viewpoint, scale, and illumination changes present in AeBAD.
What would settle it
A set of AeBAD images where the visual prompting masking incorrectly includes background or excludes parts of the object, resulting in no improvement or worse performance compared to the baseline without prompting.
Figures

read the original abstract
Recent Anomaly Detection methods achieve perfect detection and segmentation scores on well-established datasets, such as MVTec. However, many of these methods face challenges when foundational assumptions - such as consistent object scale, viewpoint, background, illumination, and centered placement - are violated. Those variations that occur render anomaly detection methods unusable in many real-world scenarios. To address these limitations, we introduce three key contributions: (1) a visual prompting pipeline that isolates objects using foreground-background masking; (2) a mechanism for unfreezing the teacher in student-teacher models to improve domain adaptability; and (3) a data augmentation strategy leveraging diffusion-generated synthetic images to enhance anomaly detection performance. We achieve a 3.5 percentage point improvement over the previous state-of-the-art on the challenging AeBAD dataset by using the Masked Multiscale Reconstruction (MMR) model as our backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a visual prompting pipeline for foreground-background masking, combined with unfreezing the teacher in student-teacher models and diffusion-based data augmentation, yields a 3.5 percentage point improvement over prior state-of-the-art on the AeBAD anomaly detection dataset when using the Masked Multiscale Reconstruction (MMR) backbone. The approach targets real-world violations of assumptions such as consistent scale, viewpoint, background, illumination, and centered placement.
Significance. If the performance delta is robust and attributable to the proposed components, the work could meaningfully extend anomaly detection to less constrained industrial settings. The multi-component design (masking + dual-teacher + synthetic augmentation) offers a concrete path for improving generalization beyond saturated benchmarks like MVTec.
major comments (1)
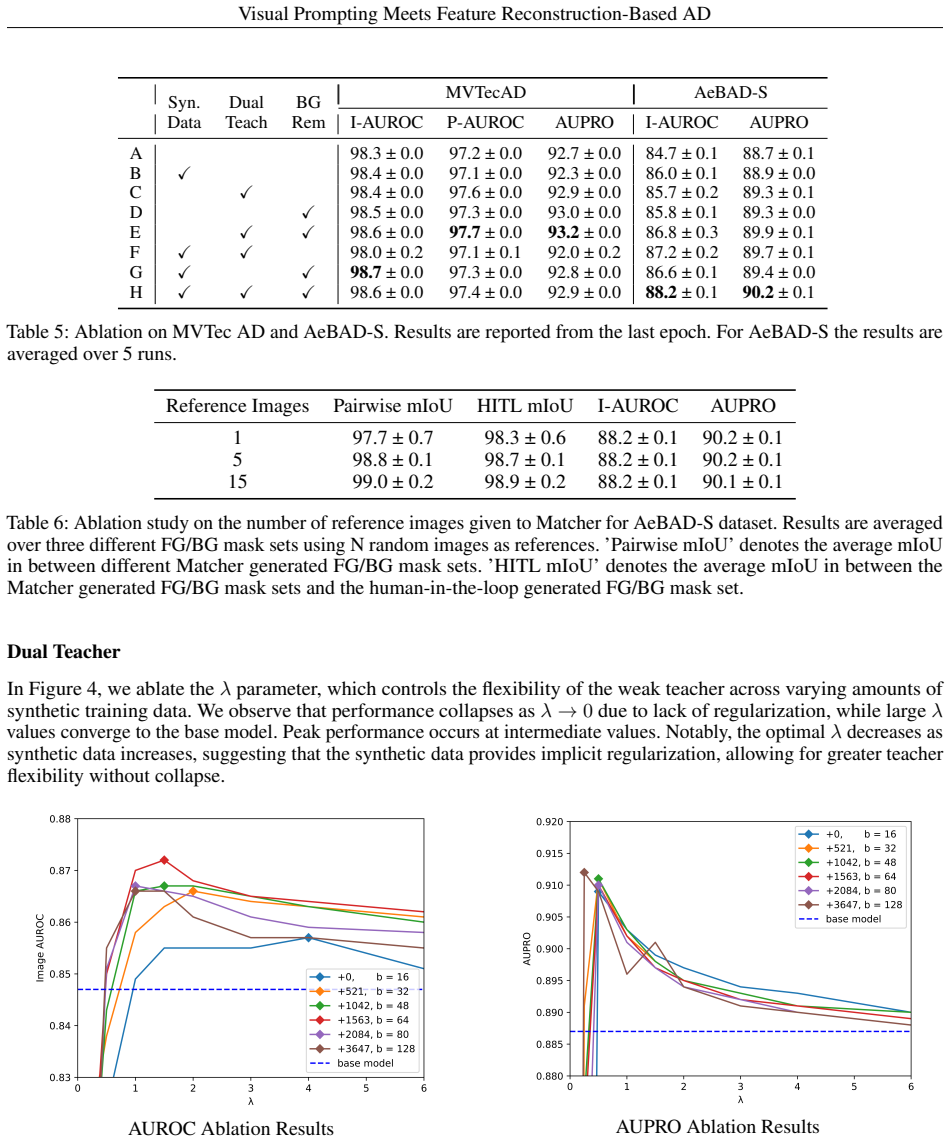
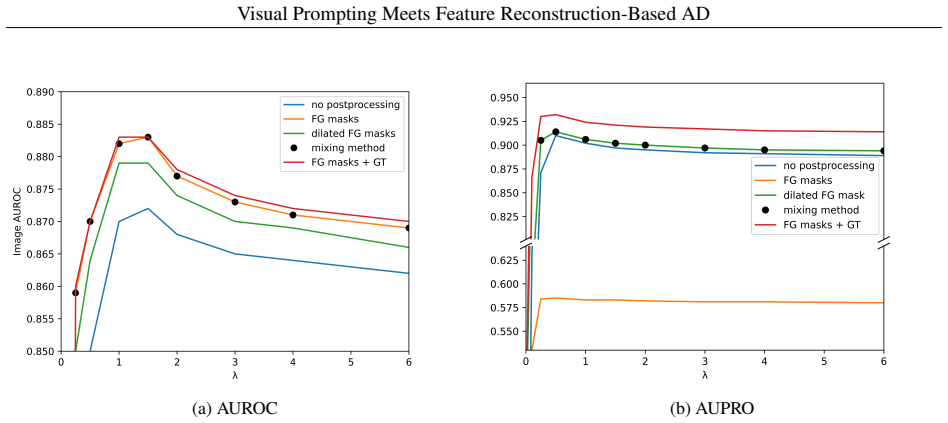
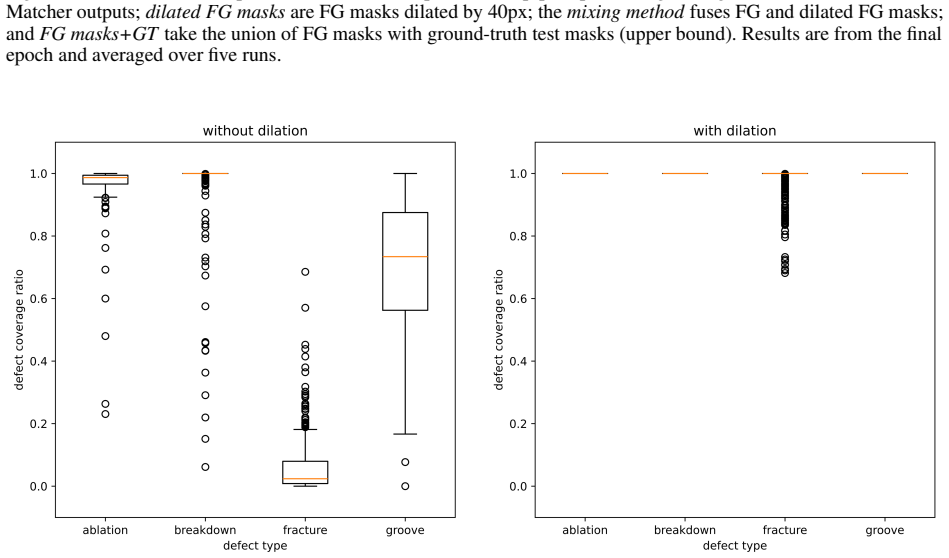
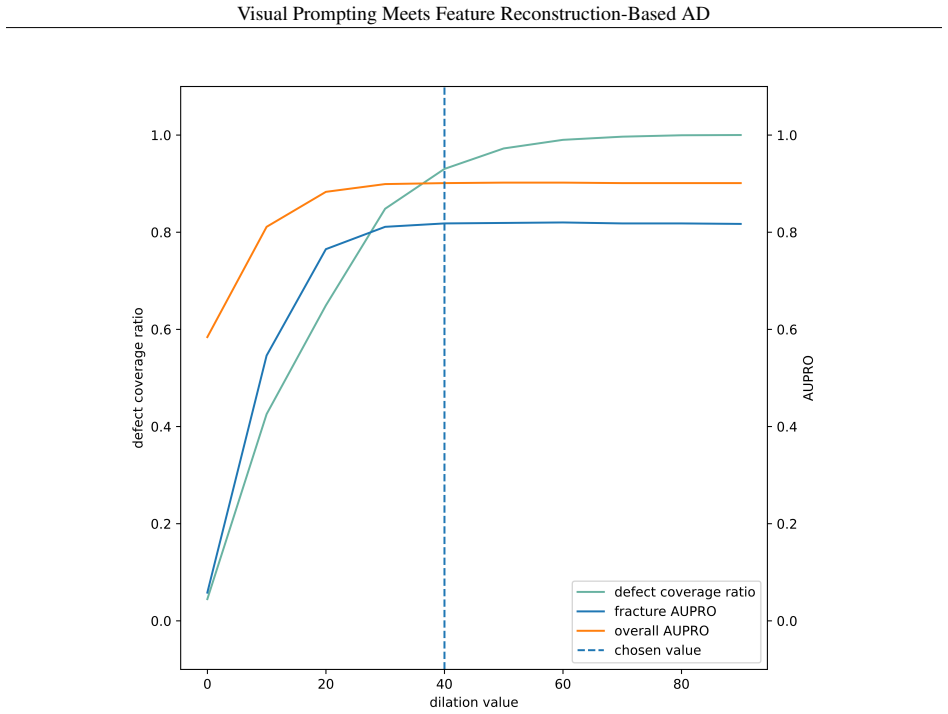
- [Experiments / Method (visual prompting pipeline)] The headline 3.5 pp gain on AeBAD is presented as resulting from the visual prompting pipeline's foreground-background masks. However, the manuscript provides no quantitative mask-quality evaluation (e.g., IoU or pixel accuracy against any reference) and no qualitative failure-case analysis on AeBAD images exhibiting the very viewpoint/scale/illumination shifts the method claims to handle. Without such evidence, the contribution of the masking step cannot be isolated from the MMR backbone or the diffusion augmentation.
minor comments (2)
- [Method (dual-teacher supervision)] Clarify the exact implementation of 'unfreezing the teacher' (e.g., which layers, learning-rate schedule, and loss terms are affected) with a diagram or pseudocode; the abstract description is too high-level to reproduce.
- [Experiments] The abstract states the improvement is 'by using the MMR model as our backbone' yet does not report an ablation that isolates MMR alone versus MMR + proposed pipeline on AeBAD.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We address the major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments / Method (visual prompting pipeline)] The headline 3.5 pp gain on AeBAD is presented as resulting from the visual prompting pipeline's foreground-background masks. However, the manuscript provides no quantitative mask-quality evaluation (e.g., IoU or pixel accuracy against any reference) and no qualitative failure-case analysis on AeBAD images exhibiting the very viewpoint/scale/illumination shifts the method claims to handle. Without such evidence, the contribution of the masking step cannot be isolated from the MMR backbone or the diffusion augmentation.
Authors: We agree that quantitative mask-quality metrics and qualitative failure-case analysis would provide stronger isolation of the visual prompting pipeline's contribution. In the revised manuscript, we will add IoU and pixel-accuracy evaluations against manually annotated reference masks on a representative subset of AeBAD images, along with qualitative visualizations of successful and failure cases under viewpoint, scale, and illumination variations. These additions will directly address the concern and clarify the masking step's role relative to the MMR backbone and diffusion augmentation. Our existing ablation results already show incremental gains from each component, but we will expand the discussion to make this attribution more explicit. revision: yes
Circularity Check
No circularity: empirical gains on public benchmark
full rationale
The paper reports measured performance deltas on the public AeBAD dataset after applying a visual-prompting mask, teacher unfreezing, and diffusion augmentation to an existing MMR backbone. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs appear in the supplied text. The 3.5 pp improvement is an external measurement, not a definitional identity or statistical artifact of the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger
doi:10.1109/TII.2016.2641472. Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad — a comprehensive real-world dataset for unsupervised anomaly detection. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9584–9592,
-
[2]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
doi:10.1109/CVPR.2019.00982. 10 Visual Prompting Meets Feature Reconstruction-Based AD Qiyu Chen, Huiyuan Luo, Chengkan Lv, and Zhengtao Zhang. A unified anomaly synthesis strategy with gradient ascent for industrial anomaly detection and localization,
-
[3]
Hanxi Li, Jingqi Wu, Lin Yuanbo Wu, Hao Chen, Deyin Liu, Mingwen Wang, and Peng Wang
URL https://arxiv.org/abs/2407.09359. Hanxi Li, Jingqi Wu, Lin Yuanbo Wu, Hao Chen, Deyin Liu, Mingwen Wang, and Peng Wang. Industrial anomaly detection and localization using weakly-supervised residual transformers,
-
[4]
Donghyeong Kim, Chaewon Park, Suhwan Cho, and Sangyoun Lee
URL https://arxiv.org/abs/2301.12082. Donghyeong Kim, Chaewon Park, Suhwan Cho, and Sangyoun Lee. Fapm: Fast adaptive patch memory for real-time industrial anomaly detection. InICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5,
arXiv 2023
-
[5]
doi:10.1109/ICASSP49357.2023.10096400. Vitjan Zavrtanik, Matej Kristan, and Danijel Skoˇcaj. Draem – a discriminatively trained reconstruction embedding for surface anomaly detection, 2021a. URL https://arxiv.org/abs/2108.07610. Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization,
-
[6]
Yiyuan Yang, Chaoli Zhang, Tian Zhou, Qingsong Wen, and Liang Sun
URL https://arxiv.org/abs/2104.04015. Yiyuan Yang, Chaoli Zhang, Tian Zhou, Qingsong Wen, and Liang Sun. Dcdetector: Dual attention contrastive representation learning for time series anomaly detection. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’23, page 3033–3045, New York, NY , USA,
-
[7]
Association for Computing Machinery. ISBN 9798400701030. doi:10.1145/3580305.3599295. URL https://doi.org/10.1145/ 3580305.3599295. Jeeho Hyun, Sangyun Kim, Giyoung Jeon, Seung Hwan Kim, Kyunghoon Bae, and Byung Jun Kang. Reconpatch: Contrastive patch representation learning for industrial anomaly detection. InProceedings of the IEEE/CVF Winter Conference...
-
[8]
Destseg: Segmentation guided denoising student-teacher for anomaly detection, 2023b
Xuan Zhang, Shiyu Li, Xi Li, Ping Huang, Jiulong Shan, and Ting Chen. Destseg: Segmentation guided denoising student-teacher for anomaly detection, 2023b. URL https://arxiv.org/abs/2211.11317. Hanqiu Deng and Xingyu Li. Anomaly detection via reverse distillation from one-class embedding. InProceedings of the IEEE/CVF Conference on Computer Vision and Patt...
-
[9]
Jia Guo, Shuai Lu, Lize Jia, Weihang Zhang, and Huiqi Li
URL https://arxiv.org/abs/2303.14535. Jia Guo, Shuai Lu, Lize Jia, Weihang Zhang, and Huiqi Li. Recontrast: Domain-specific anomaly detection via contrastive reconstruction,
-
[10]
Jonathan Ho, Ajay Jain, and Pieter Abbeel
URL https://arxiv.org/abs/2306.02602. Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models,
-
[11]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
URL https://arxiv.org/abs/ 2006.11239. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models,
Pith/arXiv arXiv 2006
-
[12]
Ximiao Zhang, Min Xu, and Xiuzhuang Zhou
URL https://arxiv.org/abs/2112.10752. Ximiao Zhang, Min Xu, and Xiuzhuang Zhou. Realnet: A feature selection network with realistic synthetic anomaly for anomaly detection,
-
[13]
Julian Wyatt, Adam Leach, Sebastian M
URL https://arxiv.org/abs/2403.05897. Julian Wyatt, Adam Leach, Sebastian M. Schmon, and Chris G. Willcocks. Anoddpm: Anomaly detection with denoising diffusion probabilistic models using simplex noise. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 649–655,
-
[14]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
doi:10.1109/CVPRW56347.2022.00080. Matthew Baugh, James Batten, Johanna P. Müller, and Bernhard Kainz. Zero-shot anomaly detection with pre-trained segmentation models,
-
[15]
Han Xiao, Kashif Rasul, and Roland V ollgraf
URL https://arxiv.org/abs/2306.09269. Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747,
-
[16]
Fre: A fast method for anomaly detection and segmentation.arXiv preprint arXiv:2211.12650,
Ibrahima Ndiour, Nilesh Ahuja, Utku Genc, and Omesh Tickoo. Fre: A fast method for anomaly detection and segmentation.arXiv preprint arXiv:2211.12650,
-
[17]
doi:10.1109/CVPR.2009.5206848. Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything,
-
[18]
Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, and Chunhua Shen
URL https://arxiv.org/abs/2304.02643. Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, and Chunhua Shen. Matcher: Segment anything with one shot using all-purpose feature matching,
-
[19]
URL https://arxiv.org/abs/2305.13310. Thomas Frick, Cezary Skura, Filip M Janicki, Roy Assaf, Niccolo Avogaro, Daniel Caraballo, Yagmur G Cinar, Brown Ebouky, Ioana Giurgiu, Takayuki Katsuki, Piotr Kluska, Cristiano Malossi, Haoxiang Qiu, Tomoya Sakai, Florian Scheidegger, Andrej Simeski, Daniel Yang, Andrea Bartezzaghi, and Mattia Rigotti. Interactive im...
-
[20]
URL https://arxiv.org/abs/2304.07193. Hannah M. Schlüter, Jeremy Tan, Benjamin Hou, and Bernhard Kainz. Natural synthetic anomalies for self-supervised anomaly detection and localization,
-
[21]
Vitjan Zavrtanik, Matej Kristan, and Danijel Sko ˇcaj
URL https://arxiv.org/abs/2109.15222. Vitjan Zavrtanik, Matej Kristan, and Danijel Sko ˇcaj. Reconstruction by inpainting for visual anomaly detection. Pattern Recognition, 112:107706, 2021b. ISSN 0031-3203. doi:https://doi.org/10.1016/j.patcog.2020.107706. URL https://www.sciencedirect.com/science/article/pii/S0031320320305094. Jonathan Pirnay and Keng C...
-
[22]
URL https://arxiv.org/abs/2405.09933. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.