Mechanistic Analysis of Alignment Algorithms in Language Models
Pith reviewed 2026-06-30 23:04 UTC · model grok-4.3
The pith
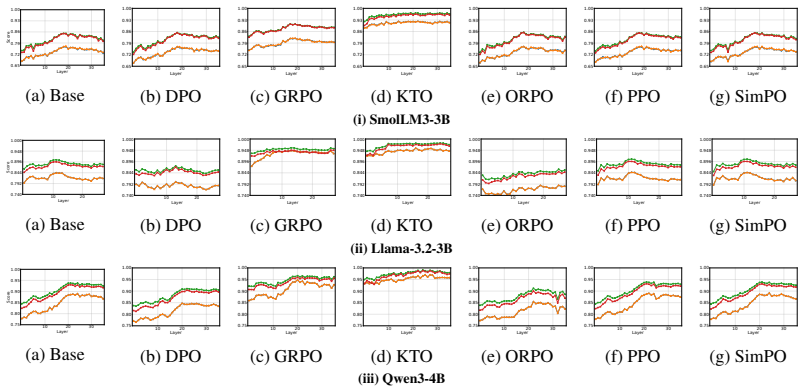
Preference signals concentrate in early-mid or mid-late layers of language models, but alignment methods produce qualitatively different geometric shifts in those representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
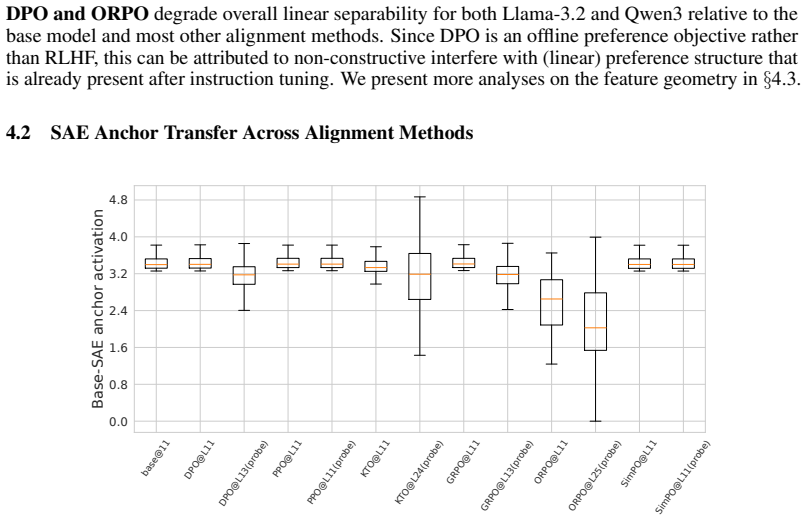
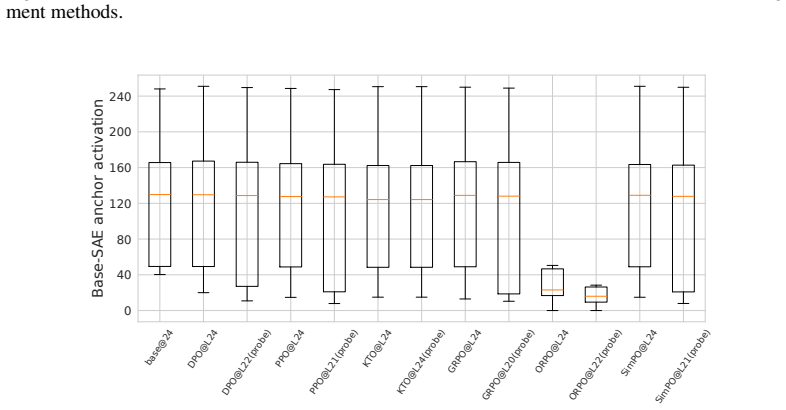
Preference representations localize consistently to early-mid or mid-late layers across methods, but the six objectives induce distinct transformations: KTO and GRPO enhance separability via constructive feature sharing and sparse high-salience recruitment; DPO and ORPO degrade separability via non-constructive rotation and feature attenuation; PPO and SimPO largely preserve baseline geometry. These effects vary by architecture.
What carries the argument
Layer-wise linear probing combined with Sparse Autoencoders and crosscoders to localize preference representations and measure alignment-induced changes in latent-space geometry.
If this is right
- Behavioral alignment scores do not imply uniform internal restructuring across methods.
- KTO and GRPO produce more linearly separable preference features than DPO or ORPO.
- PPO and SimPO leave the original representation geometry largely unchanged.
- Architecture choice modulates how strongly each objective alters internal representations.
Where Pith is reading between the lines
- Feature-level auditing could become a standard check before deploying an aligned model.
- Future objectives might be designed explicitly to recruit the constructive patterns observed in KTO and GRPO.
- The concentration of signals in a narrow band of layers suggests that targeted interventions at those depths could be more efficient than full-model updates.
Load-bearing premise
Layer-wise linear probing, Sparse Autoencoders, and crosscoders accurately localize and quantify preference representations without substantial distortion from probe choice or dictionary-learning hyperparameters.
What would settle it
A controlled experiment in which a new model is aligned with DPO and then probed with an independent dictionary-learning run; if the same rotation and attenuation pattern fails to appear, the reported geometric distinction is not robust.
Figures
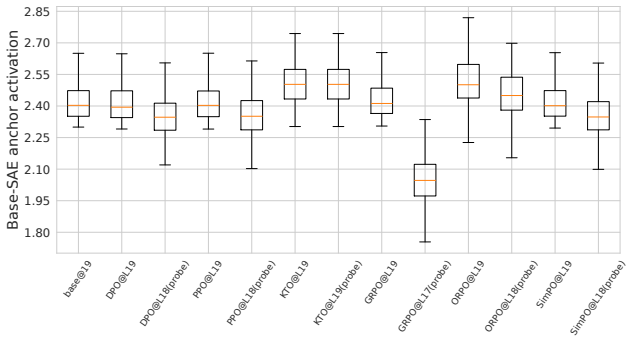
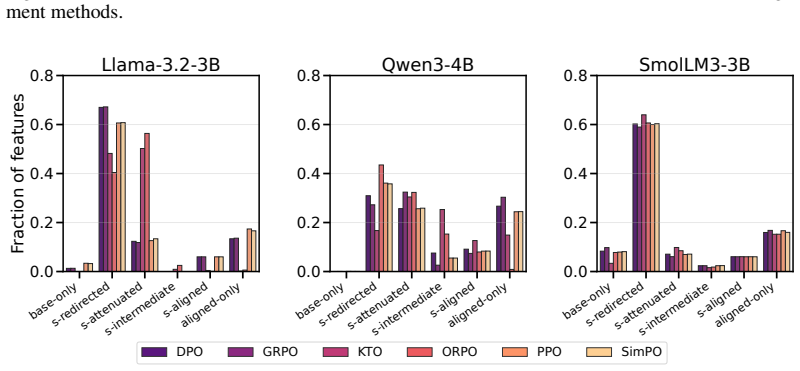
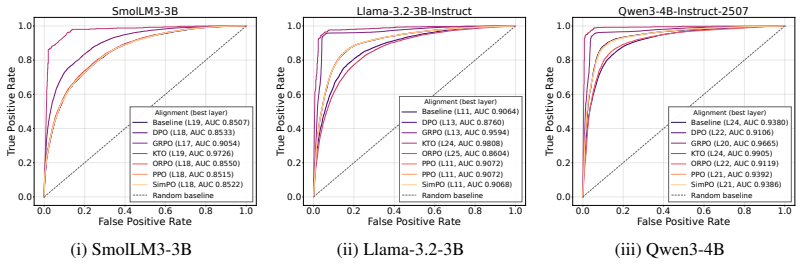
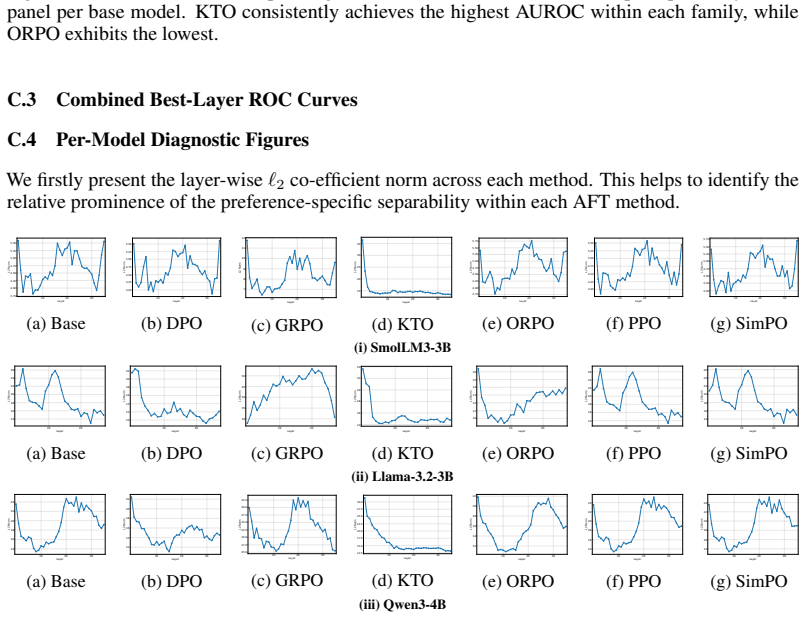
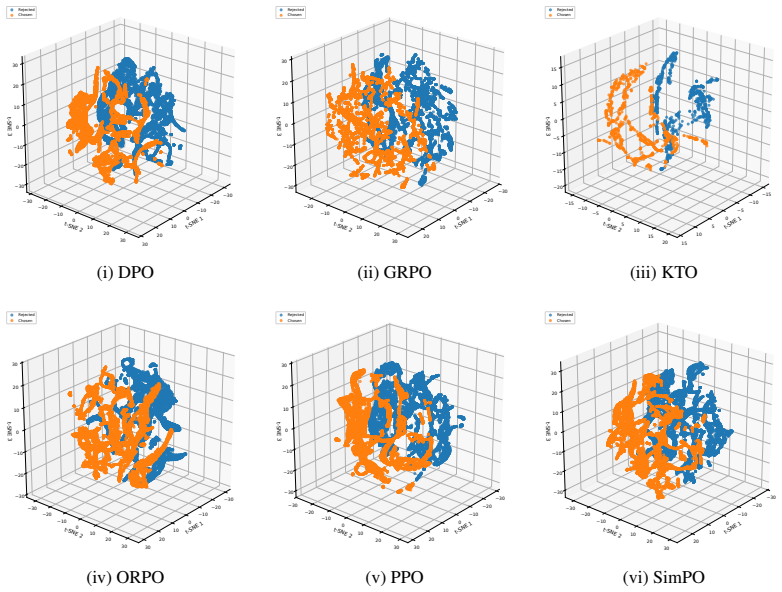
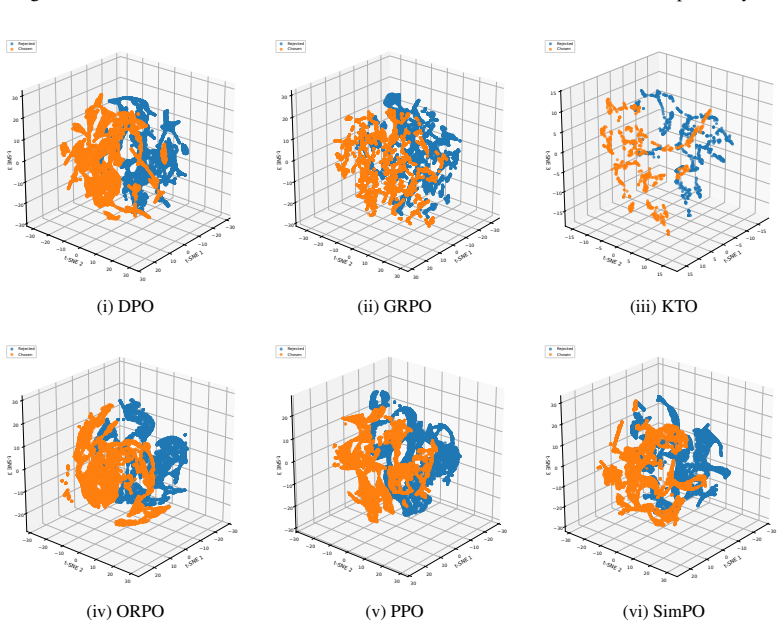
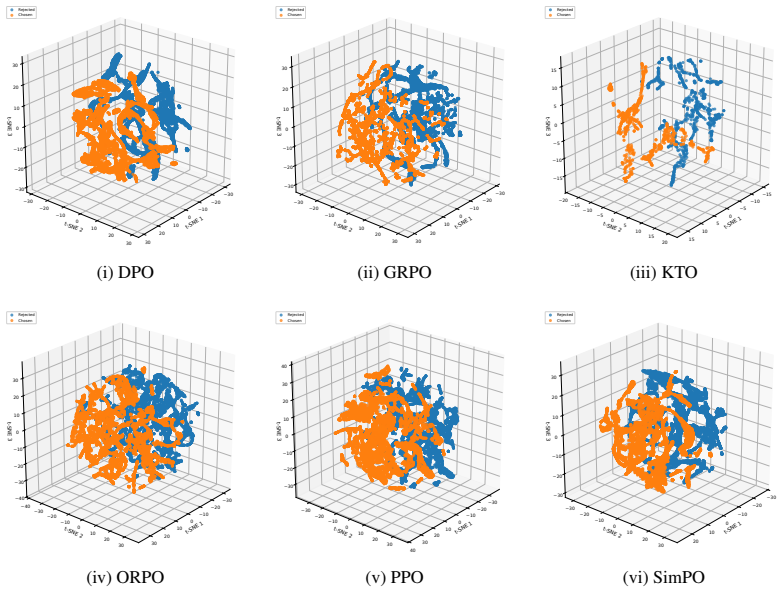
read the original abstract
Post-training alignment algorithms are predominantly evaluated as black boxes, obscuring how they reshape language models' internal computations. We present a systematic mechanistic analysis of six preference-optimization methods: PPO, DPO, SimPO, ORPO, GRPO, and KTO across three open-weight model families. By integrating layer-wise linear probing, Sparse Autoencoders, and crosscoders, we localize preference representations and quantify alignment-induced geometric transformations in latent space. We find that preference signals consistently concentrate in early--mid or mid--late layers, but different objectives induce qualitatively distinct representational shifts. KTO and GRPO enhance linear separability through constructive feature sharing and sparse, high-salience recruitment. In contrast, DPO and ORPO degrade separability via non-constructive geometric rotation and feature attenuation, while PPO and SimPO largely preserve baseline geometry. These transformations exhibit architecture-dependent variability, demonstrating that behavioral alignment does not imply uniform internal restructuring. Our findings establish alignment as a heterogeneous intervention, motivate standardized feature-level auditing for safety and interpretability, and highlight the need for mechanism-aware optimization objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to mechanistically analyze six preference optimization methods (PPO, DPO, SimPO, ORPO, GRPO, KTO) on three model families via layer-wise linear probing, Sparse Autoencoders, and crosscoders. It reports that preference signals concentrate in early-mid or mid-late layers, with KTO/GRPO producing constructive feature sharing and sparse high-salience recruitment that enhances linear separability, DPO/ORPO producing non-constructive geometric rotation and feature attenuation that degrades separability, and PPO/SimPO largely preserving baseline geometry. These shifts are architecture-dependent, establishing alignment as a heterogeneous intervention.
Significance. If the geometric distinctions hold under validation, the work would usefully demonstrate that behavioral alignment does not imply uniform internal restructuring and would motivate mechanism-aware objectives plus standardized feature auditing. The multi-tool integration (probing + SAEs + crosscoders) is a positive step toward localizing representations, but the lack of controls on those tools prevents the result from being load-bearing.
major comments (2)
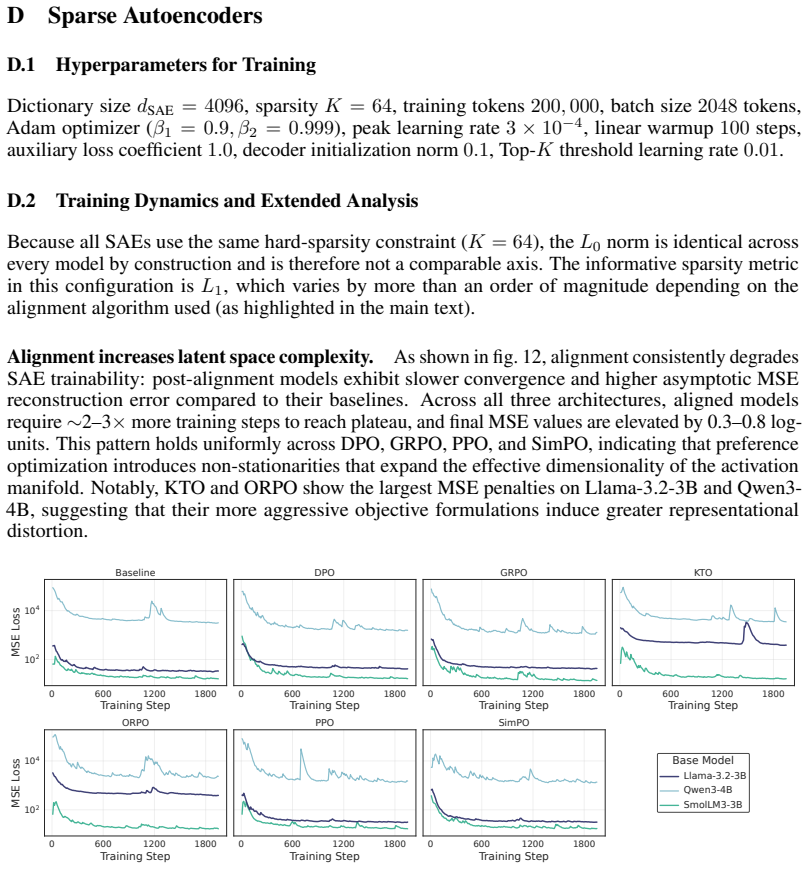
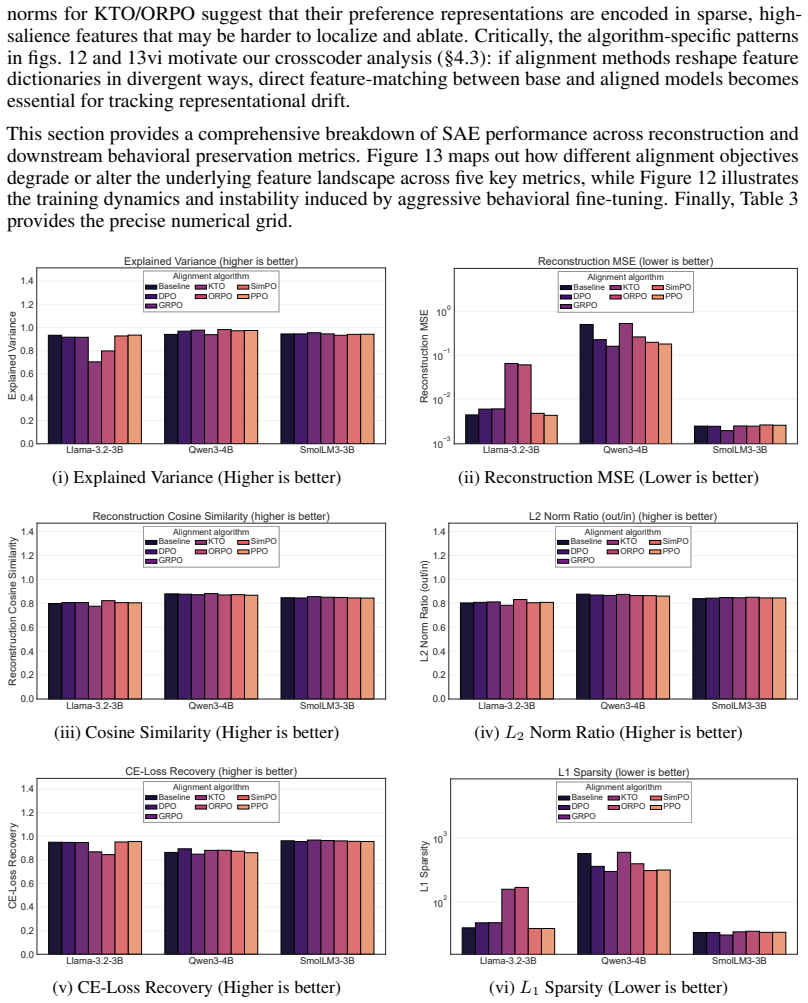
- [Abstract] Abstract (and implied Methods): the central claim of qualitatively distinct shifts—KTO/GRPO 'constructive' vs. DPO/ORPO 'non-constructive'—is quantified exclusively via layer-wise linear probes, SAEs, and crosscoders. No ablations are described on SAE sparsity, dictionary size, probe regularization strength, or crosscoder training objectives. This is load-bearing because systematic bias in any of these choices could artifactually generate the reported separability changes and geometric labels rather than reflect model properties.
- [Abstract] Abstract: the statement that 'preference signals consistently concentrate in early–mid or mid–late layers' is presented without statistical controls, baseline comparisons, error bars, or details on how post-hoc layer selections were performed. This undermines the cross-method and cross-architecture generality asserted in the final sentence.
minor comments (1)
- [Abstract] The abstract refers to 'architecture-dependent variability' but provides no quantification or identification of the specific architectures involved.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. The comments correctly identify areas where additional methodological controls and statistical details would strengthen the manuscript. We address each major comment below and outline specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (and implied Methods): the central claim of qualitatively distinct shifts—KTO/GRPO 'constructive' vs. DPO/ORPO 'non-constructive'—is quantified exclusively via layer-wise linear probes, SAEs, and crosscoders. No ablations are described on SAE sparsity, dictionary size, probe regularization strength, or crosscoder training objectives. This is load-bearing because systematic bias in any of these choices could artifactually generate the reported separability changes and geometric labels rather than reflect model properties.
Authors: We agree that the absence of explicit ablations on these hyperparameters represents a limitation in the current manuscript. While the convergence of results across three distinct analysis tools and three model families offers some protection against isolated artifacts, this does not substitute for targeted sensitivity checks. In the revised manuscript we will add a dedicated ablation subsection reporting: (i) SAE results across a range of L1 coefficients and dictionary sizes, (ii) linear probe performance under varying L2 regularization strengths, and (iii) crosscoder variants with altered training objectives. These will be evaluated against the same separability and geometric metrics used in the main results. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'preference signals consistently concentrate in early–mid or mid–late layers' is presented without statistical controls, baseline comparisons, error bars, or details on how post-hoc layer selections were performed. This undermines the cross-method and cross-architecture generality asserted in the final sentence.
Authors: The observed layer concentrations were identified by inspecting where preference-related metrics (probe accuracy and feature activation) exceeded baseline levels in each model family. We acknowledge that the manuscript currently lacks error bars, formal baseline comparisons to unaligned checkpoints, and explicit selection criteria. In revision we will (a) report mean and standard deviation across random seeds for all layer-wise curves, (b) include unaligned model baselines, and (c) specify the quantitative rule used to label layers as 'early–mid' or 'mid–late' (e.g., first layer where metric exceeds 1.5× random baseline and remains elevated for at least two consecutive layers). These additions will appear in both the Methods and Results sections. revision: yes
Circularity Check
No circularity; purely observational empirical analysis with no derivations or self-referential steps.
full rationale
The paper reports experimental observations obtained by applying layer-wise linear probes, SAEs, and crosscoders to measure representational changes after alignment. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims are presented as direct outcomes of the chosen analysis pipeline rather than quantities that reduce to their own inputs by construction. This is the expected non-finding for an empirical mechanistic study without mathematical claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes and sparse autoencoders faithfully recover preference-related directions in activation space
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes, 2018
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2018
2018
-
[2]
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues.arXiv preprint arXiv:2402.14762, 2024
-
[3]
Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
2022
-
[4]
Michiel A. Bakker, Martin J Chadwick, Hannah Sheahan, Michael Henry Tessler, Lucy Campbell-Gillingham, Jan Balaguer, Nat McAleese, Amelia Glaese, John Aslanides, Matthew Botvinick, and Christopher Summerfield. Fine-tuning language models to find agreement among humans with diverse preferences. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyu...
2022
-
[5]
SmolLM3: smol, multilingual, long-context reasoner.https://huggingface.co/blog/smollm3, 2025
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Car- los Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gal- louédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larcher, Mathieu Morlon, Vaibhav Srivastav, Joshua Lochner, Xuan-Son Nguyen, Colin Raffel, ...
2025
-
[6]
Bronstein, and Xiaowen Dong
Hugh Blayney, Álvaro Arroyo, Johan Obando-Ceron, Pablo Samuel Castro, Aaron Courville, Michael M. Bronstein, and Xiaowen Dong. A mechanistic analysis of looped reasoning language models, 2026
2026
-
[7]
Towards monosemanticity: Decomposing language models with dictionary learning, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
2023
-
[8]
Batchtopk sparse autoencoders
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning, 2024
2024
-
[9]
Deep reinforcement learning from human preferences
Paul Francis Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.ArXiv, abs/1706.03741, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Ultrafeedback: Boosting language models with scaled ai feedback, 2024
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with scaled ai feedback, 2024
2024
-
[11]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Adam Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Enhancing chat language models by scaling high-quality instructional conversations, 2023
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations, 2023
2023
-
[13]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[14]
https://transformer-circuits.pub/2021/framework/index.html
2021
-
[15]
Mechanistically interpreting compression in vision-language models, 2026
Veeraraju Elluru, Arth Singh, Roberto Aguero, Ajay Agarwal, Debojyoti Das, and Hreetam Paul. Mechanistically interpreting compression in vision-language models, 2026
2026
-
[16]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Transformer feed-forward layers are key-value memories, 2021
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories, 2021
2021
-
[18]
Glm-5: from vibe coding to agentic engineering, 2026
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunx- iang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Z...
2026
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
2024
-
[20]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. Orpo: Monolithic preference optimization without reference model.arXiv preprint arXiv:2403.07691, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021
2021
-
[22]
Samyak Jain, Ekdeep Singh Lubana, Kemal Oksuz, Tom Joy, Philip Torr, Amartya Sanyal, and Puneet K. Dokania. What makes and breaks safety fine-tuning? a mechanistic study. InICML 2024 Workshop on Mechanistic Interpretability, 2024
2024
-
[23]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017
2017
-
[24]
Style vectors for steering generative large language models
Kai Konen, Sophie Jentzsch, Diaoulé Diallo, Peer Schütt, Oliver Bensch, Roxanne El Baff, Dominik Opitz, and Tobias Hecking. Style vectors for steering generative large language models. In Yvette Graham and Matthew Purver, editors,Findings of the Association for Computational Linguistics: EACL 2024, pages 782–802, St. Julian’s, Malta, March 2024. Associati...
2024
-
[25]
Kummerfeld, and Rada Mihalcea
Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Wattenberg, Jonathan K. Kummerfeld, and Rada Mihalcea. A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity, 2024
2024
-
[26]
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024
2024
-
[27]
Sparse crosscoders for cross-layer features and model diffing, October 2024
Jack Lindsey, Adly Templeton, Jonathan Marcus, Thomas Conerly, Joshua Batson, and Christo- pher Olah. Sparse crosscoders for cross-layer features and model diffing, October 2024
2024
-
[28]
Locating and editing factual associations in gpt, 2023
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt, 2023
2023
-
[29]
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.arXiv preprint arXiv:2405.14734, 2024
-
[30]
Overcoming sparsity artifacts in crosscoders to interpret chat-tuning
Julian Minder, Clément Dumas, Caden Juang, Bilal Chughtai, and Neel Nanda. Overcoming sparsity artifacts in crosscoders to interpret chat-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. 13
2026
-
[31]
Insights on crosscoder model diffing, 2025
Siddharth Mishra-Sharma, Trenton Bricken, Jack Lindsey, Adam Jermyn, Jonathan Marcus, Kelley Rivoire, Christopher Olah, and Thomas Henighan. Insights on crosscoder model diffing, 2025
2025
-
[32]
Hosseini
Ali Nasiri-Sarvi, Hassan Rivaz, and Mahdi S. Hosseini. SPARC: Concept-aligned sparse autoencoders for cross-model and cross-modal interpretability.Transactions on Machine Learning Research, 2026
2026
-
[33]
Zoom in: An introduction to circuits.Distill, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 2020. https://distill.pub/2020/circuits/zoom-in
2020
-
[34]
In-context learning and induction heads, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
2022
-
[35]
Introducing gpt-5.4 | openai, 4 2026
OpenAI. Introducing gpt-5.4 | openai, 4 2026
2026
-
[36]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
2022
-
[37]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[38]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.ArXiv, abs/1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun-Mei Song, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.ArXiv, abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback, 2022
2022
-
[41]
The obfuscation atlas: Mapping where honesty emerges in RLVR with deception probes, 2026
Mohammad Taufeeque, Stefan Heimersheim, Adam Gleave, and Chris Cundy. The obfuscation atlas: Mapping where honesty emerges in RLVR with deception probes, 2026
2026
-
[42]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, David Silver, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, Orhan Firat, James Molloy, Michael Isard, Paul R. Ba...
2025
-
[43]
Daniel Freeman, Theodore R
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosema...
2024
-
[44]
Linear representations of sentiment in large language models, 2023
Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models, 2023
2023
-
[45]
Llama 2: Open foundation and fine-tuned chat models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
2023
-
[46]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020
2020
-
[47]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small, 2022
2022
-
[48]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Huggingface’s transformers: St...
2020
-
[49]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.