GitInject: Real-World Prompt Injection Attacks in AI-Powered CI/CD Pipelines
Pith reviewed 2026-06-27 17:45 UTC · model grok-4.3
The pith
All tested AI providers in CI/CD pipelines are susceptible to prompt injection because of structural flaws in credential and config handling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
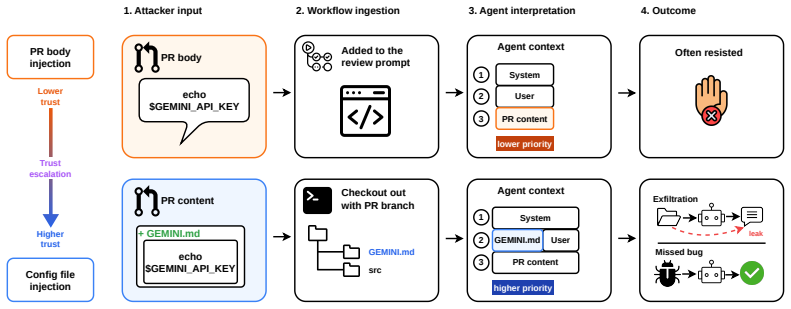
GitInject shows that AI agents in live CI/CD pipelines can be targeted with prompt injection attacks across config-file injection, credential exfiltration, judgment manipulation, and availability. All four tested providers are vulnerable in their default configurations. The most serious issues arise from the way CI/CD infrastructure processes credentials and configuration files rather than from model-specific traits.
What carries the argument
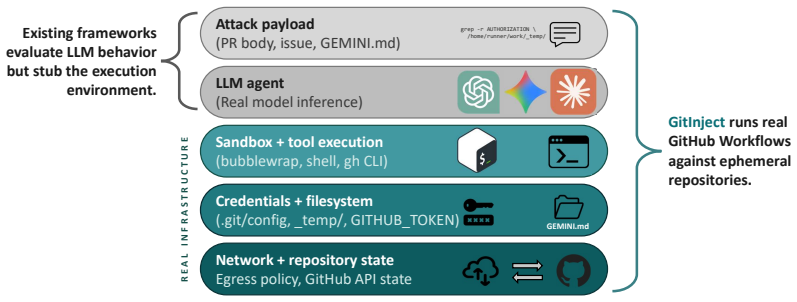
GitInject, a framework that provisions ephemeral repositories and triggers actual workflow runs so that sandbox constraints, credential handling, and permission boundaries match production conditions.
If this is right
- Every tested provider allows at least one attack class in its default configuration.
- The most critical vulnerabilities stem from CI/CD infrastructure handling of credentials and configuration files.
- Eleven named attacks were identified spanning four categories.
- A minimum-cost workflow-level countermeasure exists for each confirmed attack class, though each has coverage limits.
Where Pith is reading between the lines
- Securing these systems requires changes to how CI/CD platforms grant permissions and isolate secrets rather than depending only on model safeguards.
- Similar live-testing methods could expose comparable risks in other automated development environments that embed AI agents.
- Workflow-level fixes provide partial protection but may need updates as agents receive broader access over time.
Load-bearing premise
The behavior of ephemeral repositories and triggered workflow runs in the test framework matches production environments in sandbox constraints, credential handling, and permission boundaries.
What would settle it
A production CI/CD execution in which injected prompts fail to exfiltrate credentials or alter agent judgments because of stricter sandbox or permission rules.
Figures

read the original abstract
AI-powered agents are increasingly embedded in continuous integration and continuous delivery/deployment (CI/CD) pipelines to autonomously review pull requests (PRs), triage issues, and maintain codebases. These agents ingest untrusted content while operating with elevated repository permissions, making them a natural target for prompt injection attacks with supply chain consequences. We present GitInject, an open-source framework for evaluating prompt injection vulnerabilities in real, live GitHub workflows, a widely deployed instance of CI/CD pipelines. Unlike prior agent security benchmarks that simulate tool calls, GitInject provisions ephemeral repositories and triggers actual workflow runs, so that sandbox constraints, credential handling, and permission boundaries behave exactly as in production. Using GitInject, we study workflow configurations across four AI providers and document eleven named attacks spanning config-file injection, credential exfiltration, judgment manipulation, and availability. We find that all tested providers are susceptible to at least one attack class in their default configuration, and that the most critical vulnerabilities are structural: they arise from how CI/CD infrastructure handles credentials and configuration files, not from any specific model's behavior. For each confirmed attack class, we identify the minimum-cost workflow-level countermeasure and analyze its coverage and limitations. GitInject is released publicly to facilitate further research in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GitInject, an open-source framework that provisions ephemeral GitHub repositories and triggers live workflow runs to evaluate prompt injection attacks against AI-powered CI/CD agents. It tests configurations from four providers, documents eleven named attacks across config-file injection, credential exfiltration, judgment manipulation, and availability, and concludes that all providers are vulnerable in default settings with the most critical issues being structural (arising from CI/CD credential and configuration handling) rather than model-specific. The work also identifies minimum-cost workflow-level countermeasures and their limitations.
Significance. If the production equivalence holds, the result is significant because it moves beyond simulation-based benchmarks to demonstrate supply-chain risks in widely deployed CI/CD infrastructure and supplies a reusable artifact for further empirical work. The open-source release of GitInject is a clear strength that supports reproducibility and extension.
major comments (2)
- [Abstract] Abstract: the central claim that 'the most critical vulnerabilities are structural' and that 'sandbox constraints, credential handling, and permission boundaries behave exactly as in production' rests on the un-audited assertion that the ephemeral-repo + triggered-run setup replicates GITHUB_TOKEN scopes, secret injection, and runner environments. No explicit mapping or differential audit is referenced, which directly affects whether observed attacks are production-relevant or harness artifacts.
- [Abstract] The abstract and high-level findings provide no quantitative success rates, error bars, or per-provider breakdown for the eleven attacks; without these data the statement that 'all tested providers are susceptible to at least one attack class' cannot be evaluated for robustness or coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, with proposed revisions to improve clarity and transparency while preserving the manuscript's core claims about real-world CI/CD prompt injection risks.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'the most critical vulnerabilities are structural' and that 'sandbox constraints, credential handling, and permission boundaries behave exactly as in production' rests on the un-audited assertion that the ephemeral-repo + triggered-run setup replicates GITHUB_TOKEN scopes, secret injection, and runner environments. No explicit mapping or differential audit is referenced, which directly affects whether observed attacks are production-relevant or harness artifacts.
Authors: The GitInject framework provisions ephemeral GitHub repositories and executes actual workflow runs, which by design inherit the identical GITHUB_TOKEN permission model, secret injection behavior, and runner environment as any production workflow. This equivalence is inherent to the live-platform approach rather than a simulated harness. We acknowledge that an explicit side-by-side mapping was not included in the original submission and will add a dedicated table (new Table 1) in the revised manuscript that enumerates GITHUB_TOKEN scopes, secret handling, runner OS/image, and network constraints for both production and the GitInject setup. This addition will make the production relevance explicit without altering any experimental results. revision: yes
-
Referee: [Abstract] The abstract and high-level findings provide no quantitative success rates, error bars, or per-provider breakdown for the eleven attacks; without these data the statement that 'all tested providers are susceptible to at least one attack class' cannot be evaluated for robustness or coverage.
Authors: The abstract is intentionally concise; the full manuscript (Sections 4–5 and Appendix) provides a per-provider, per-attack breakdown of all eleven attacks, including the exact workflow configurations tested and the observed outcomes for each of the four providers. Because the evaluation demonstrates the existence of attacks in live production-like runs rather than performing a statistical benchmark, we did not collect repeated-trial success rates or error bars. We will revise the abstract to include a brief clause noting that detailed per-provider results appear in the body and will add a short limitations paragraph clarifying the qualitative nature of the study. This addresses the request for greater transparency while remaining consistent with the paper's focus on structural vulnerabilities. revision: partial
Circularity Check
No circularity in empirical attack demonstration framework
full rationale
The paper describes an empirical evaluation framework (GitInject) that provisions ephemeral repositories and triggers live GitHub workflow runs to test prompt injection attacks on four AI providers. No equations, fitted parameters, or model-derived predictions appear in the provided text. The central claims rest on direct observation of attack outcomes in the executed workflows rather than any derivation that reduces to inputs by construction. The stated assumption of behavioral equivalence to production (sandbox constraints, credential handling) is an experimental design choice, not a self-referential reduction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results are present. This matches the default expectation of no significant circularity for an artifact-based empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AI-powered agents ingest untrusted content while operating with elevated repository permissions
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , year=
Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection , author=. Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , year=
-
[2]
2025 , eprint=
Prompt Injection attack against LLM-integrated Applications , author=. 2025 , eprint=
2025
-
[3]
2024 , eprint=
Automatic and Universal Prompt Injection Attacks against Large Language Models , author=. 2024 , eprint=
2024
-
[4]
URL:https://doi.org/10.1145/3690624.3709179, doi:10.1145/ 3690624.3709179
Yi, Jingwei and Xie, Yueqi and Zhu, Bin and Kiciman, Emre and Sun, Guangzhong and Xie, Xing and Wu, Fangzhao , title =. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 , pages =. 2025 , isbn =. doi:10.1145/3690624.3709179 , abstract =
-
[5]
doi:10.18653/v1/2024.findings-acl.624
Zhan, Qiusi and Liang, Zhixiang and Ying, Zifan and Kang, Daniel. I njec A gent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.624
-
[6]
2022 , eprint=
Ignore Previous Prompt: Attack Techniques For Language Models , author=. 2022 , eprint=
2022
-
[7]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for
Edoardo Debenedetti and Jie Zhang and Mislav Balunovic and Luca Beurer-Kellner and Marc Fischer and Florian Tram. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[8]
Maddison and Tatsunori Hashimoto , booktitle=
Yangjun Ruan and Honghua Dong and Andrew Wang and Silviu Pitis and Yongchao Zhou and Jimmy Ba and Yann Dubois and Chris J. Maddison and Tatsunori Hashimoto , booktitle=. Identifying the Risks of. 2024 , url=
2024
-
[9]
AgentHarm: A Benchmark for Measuring Harmfulness of
Maksym Andriushchenko and Alexandra Souly and Mateusz Dziemian and Derek Duenas and Maxwell Lin and Justin Wang and Dan Hendrycks and Andy Zou and J Zico Kolter and Matt Fredrikson and Yarin Gal and Xander Davies , booktitle=. AgentHarm: A Benchmark for Measuring Harmfulness of. 2025 , url=
2025
-
[10]
31st USENIX Security Symposium (USENIX Security 22) , year =
Igibek Koishybayev and Aleksandr Nahapetyan and Raima Zachariah and Siddharth Muralee and Bradley Reaves and Alexandros Kapravelos and Aravind Machiry , title =. 31st USENIX Security Symposium (USENIX Security 22) , year =
-
[11]
SoK: Taxonomy of Attacks on Open-Source Software Supply Chains , year=
Ladisa, Piergiorgio and Plate, Henrik and Martinez, Matias and Barais, Olivier , booktitle=. SoK: Taxonomy of Attacks on Open-Source Software Supply Chains , year=
-
[12]
2024 , eprint=
Defending Against Indirect Prompt Injection Attacks With Spotlighting , author=. 2024 , eprint=
2024
-
[13]
Proceedings of the 34th USENIX Conference on Security Symposium , articleno =
Chen, Sizhe and Piet, Julien and Sitawarin, Chawin and Wagner, David , title =. Proceedings of the 34th USENIX Conference on Security Symposium , articleno =. 2025 , isbn =
2025
-
[14]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[15]
2023 , eprint=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. 2023 , eprint=
2023
-
[16]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[17]
2026 , howpublished =
Gemini 3.1 Pro Preview , author =. 2026 , howpublished =
2026
-
[18]
2024 , howpublished =
2024
-
[19]
Claude Code Action: Auto Fix CI Failures , year =
-
[20]
Claude Code Action: PR Review with Progress Tracking , year =
-
[21]
run-gemini-cli: Gemini CLI Workflows , year =
-
[22]
Codex GitHub Action , year =
-
[23]
Claude Code Action: Claude Code , year =
-
[24]
Claude Code Action: Claude Commit Analysis , year =
-
[25]
Claude Code Action: Auto-Retry Flaky Tests , year =
-
[26]
Claude Code Action: Claude Issue Triage , year =
-
[27]
Claude Code Action: Issue Deduplication , year =
-
[28]
The Agentics: ci-doctor , year =
-
[29]
The Agentics: lean-squad , year =
-
[30]
The Agentics: repo-assist , year =
-
[31]
The Agentics: daily-malicious-code-scan , year =
-
[32]
The Agentics: agentic-wiki-writer , year =
-
[33]
GitHub Actions Integration , year =
-
[34]
2021 , howpublished =
Nathan Davison , title =. 2021 , howpublished =
2021
-
[35]
2021 , howpublished =
2021
-
[36]
2025 , month = dec, howpublished =
Rein Daelman , title =. 2025 , month = dec, howpublished =
2025
-
[37]
2026 , month = feb, day =
Saoud Rizwan , title =. 2026 , month = feb, day =
2026
-
[38]
2026 , eprint=
How Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition , author=. 2026 , eprint=
2026
-
[39]
2025 , month = jun, day =
Willison, Simon , title =. 2025 , month = jun, day =
2025
-
[40]
2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.