Fusing Satellite Imagery and Planimetric Maps for Cross-View Localization
Pith reviewed 2026-06-27 16:42 UTC · model grok-4.3
The pith
Integrating satellite imagery with planimetric maps via a fusion module reduces mean cross-view localization error by 30.13%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
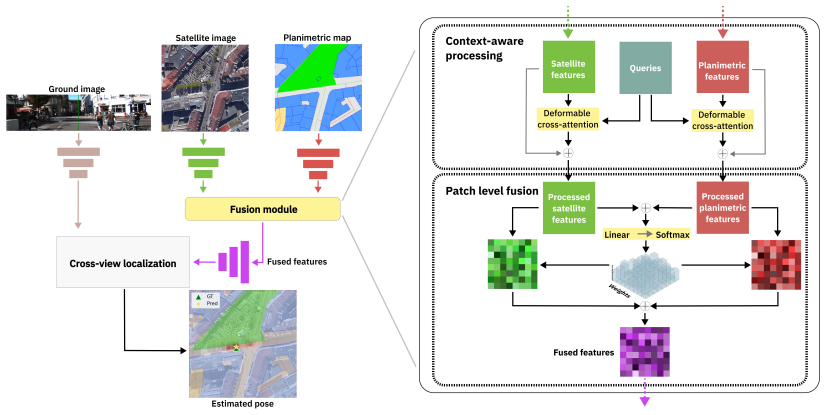
The central claim is that a fusion module comprising cross-modal conditioning, which makes each modality's encoding aware of the other, and a patch-level fusion rule that governs the granularity of information exchange, can be added to standard encoders; when satellite imagery and planimetric maps are supplied to this module, the resulting system improves state-of-the-art single-modality methods and reduces mean localization error by 30.13 percent while adaptively selecting the more informative modality.
What carries the argument
Fusion module of cross-modal conditioning and patch-level fusion rule that augments standard encoders to exchange information between satellite imagery and planimetric maps.
If this is right
- Standard single-modality encoders can be augmented with the module to reach higher accuracy without redesign.
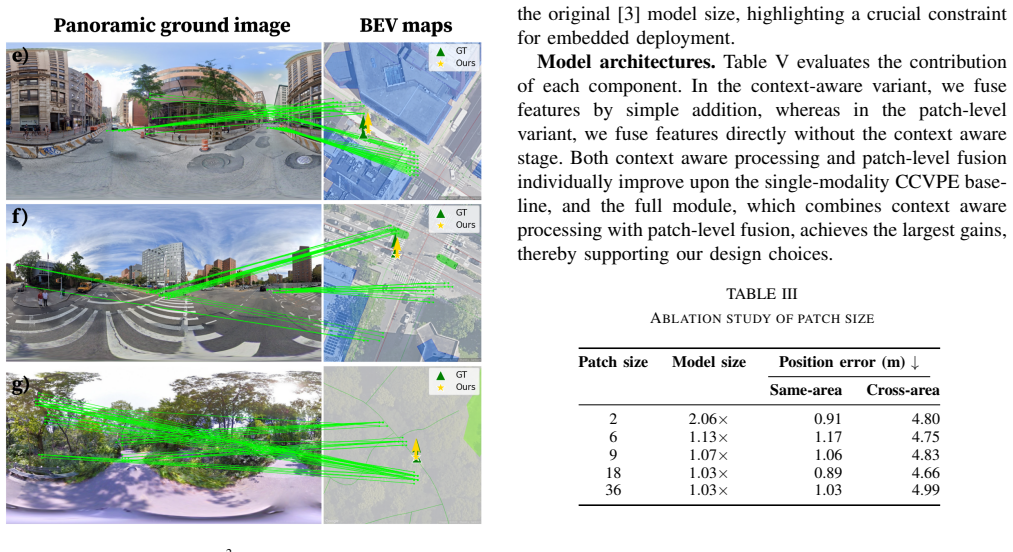
- The system improves performance by adaptively favoring satellite detail or map annotations depending on the scene.
- Accuracy holds in regions occluded by foliage because planimetric maps remain informative where satellite views are blocked.
- The approach yields state-of-the-art results on cross-view localization benchmarks.
Where Pith is reading between the lines
- The same conditioning and patch-fusion pattern could be tested on other pairs of visual and symbolic aerial data.
- Navigation pipelines that already ingest both satellite tiles and OpenStreetMap layers could adopt the module for immediate gains.
- Seasonal or weather-varied test sets would show whether the adaptive selection continues to help when both modalities degrade together.
Load-bearing premise
The cross-modal conditioning and patch-level fusion can be plugged into standard encoders and the test datasets capture conditions where the two modalities are reliably complementary.
What would settle it
Run the fused model and the best single-modality baseline on a new dataset where satellite and map data supply no complementary information, such as uniformly clear scenes lacking annotations; if the fused error is not lower, the central claim fails.
Figures



read the original abstract
Current cross-view localization methods predominantly rely on satellite imagery as the aerial modality. Although recent work explores planimetric maps (e.g., OpenStreetMap tiles), these approaches often lag in performance. Yet both modalities are widely available and possess complementary properties. Satellite images are closer to ground-level camera imagery, offering finer detail, whereas planimetric maps contain annotated objects (e.g., streetlamps) and remain informative in areas where the ground is occluded, such as by foliage. Despite this, only one prior work provides an end-to-end method to fuse the two modalities, and it does not demonstrate their potential within state-of-the-art methods. To combine the strengths of both modalities, we propose a new fusion module that augments standard encoders and demonstrates that integrating satellite imagery with planimetric maps improves state-of-the-art single-modality methods. The module comprises (i) cross-modal conditioning, which processes each modality's encoding with awareness of the other, and (ii) a patch-level fusion rule that controls the granularity of information exchange. We achieve state-of-the-art results, reducing the mean localization error by 30.13\%. Qualitatively, the fusion adaptively selects the more informative modality, improving overall accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fusion module to integrate satellite imagery and planimetric maps for cross-view localization. The module consists of cross-modal conditioning (to process each modality's encoding with awareness of the other) and a patch-level fusion rule (to control granularity of information exchange and adaptively select the more informative modality). It claims this augments standard encoders and improves state-of-the-art single-modality methods, achieving a 30.13% reduction in mean localization error.
Significance. If the empirical results hold with proper validation, the work would be significant for demonstrating the complementary value of two widely available modalities in cross-view localization, particularly for robustness under occlusion (e.g., foliage), where prior fusion work is limited to a single end-to-end method that does not integrate with SOTA encoders.
major comments (3)
- [Abstract] Abstract: The central claim of a 30.13% reduction in mean localization error is presented without reference to experimental protocol, datasets used, baselines compared, statistical tests, ablation studies isolating the fusion components, or dataset statistics on modality complementarity (e.g., occlusion regimes). This prevents assessment of whether the reported gain is attributable to the proposed module.
- [Method] The manuscript supplies no equations, pseudocode, or detailed derivation for the cross-modal conditioning mechanism or the patch-level fusion rule, leaving the technical implementation and its claimed 'parameter-free' or adaptive properties unevaluable.
- [Experiments] No ablation results, qualitative examples, or dataset statistics are referenced to confirm that the test splits contain regimes where satellite imagery is occluded while planimetric maps supply annotated objects, which is required for the complementarity assumption to support the performance claim.
minor comments (2)
- [Introduction] The abstract states that 'only one prior work provides an end-to-end method to fuse the two modalities' but does not cite that work or contrast the proposed module against it in detail.
- Notation for the fusion module components (e.g., how patch-level exchange is implemented) is not introduced or clarified in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a 30.13% reduction in mean localization error is presented without reference to experimental protocol, datasets used, baselines compared, statistical tests, ablation studies isolating the fusion components, or dataset statistics on modality complementarity (e.g., occlusion regimes). This prevents assessment of whether the reported gain is attributable to the proposed module.
Authors: We agree that the abstract would benefit from additional context. In the revision we will expand it to reference the cross-view localization benchmarks, the single-modality SOTA baselines, and note that ablations, statistical validation, and occlusion-regime analysis appear in the experiments section. revision: yes
-
Referee: [Method] The manuscript supplies no equations, pseudocode, or detailed derivation for the cross-modal conditioning mechanism or the patch-level fusion rule, leaving the technical implementation and its claimed 'parameter-free' or adaptive properties unevaluable.
Authors: The method section describes the two components in detail. To make the implementation fully reproducible we will add the corresponding equations and pseudocode for cross-modal conditioning and the patch-level fusion rule, explicitly highlighting the parameter-free and adaptive properties. revision: yes
-
Referee: [Experiments] No ablation results, qualitative examples, or dataset statistics are referenced to confirm that the test splits contain regimes where satellite imagery is occluded while planimetric maps supply annotated objects, which is required for the complementarity assumption to support the performance claim.
Authors: The experiments section already contains ablation studies isolating the fusion components and qualitative examples of adaptive modality selection. We will add explicit dataset statistics (e.g., occlusion coverage per split) and further tables confirming the presence of complementary regimes to strengthen the supporting evidence. revision: yes
Circularity Check
No circularity; empirical performance claim with no derivations or self-referential reductions
full rationale
The paper describes an empirical fusion module (cross-modal conditioning + patch-level fusion) plugged into encoders and reports a measured 30.13% error reduction on test data. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The central claim is an experimental outcome on external datasets, not a quantity forced by construction from the method's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gnss vulnerabilities and existing solutions: A review of the literature,
J. Zidan, E. I. Adegoke, E. Kampert, S. A. Birrell, C. R. Ford, and M. D. Higgins, “Gnss vulnerabilities and existing solutions: A review of the literature,”IEEE Access, vol. 9, pp. 153 960–153 976, 2021
2021
-
[2]
Improving accuracy of gnss devices in urban canyons,
B. Ben-Moshe, E. Elkin, H. Levi, and A. Weissman, “Improving accuracy of gnss devices in urban canyons,” 01 2011
2011
-
[3]
Loc 2: Interpretable Cross-View Local- ization via Depth-Lifted Local Feature Matching,
Z. Xia, C. Xu, and A. Alahi, “Loc 2: Interpretable Cross-View Local- ization via Depth-Lifted Local Feature Matching,”arXiv e-prints, p. arXiv:2509.09792, Sept. 2025
-
[4]
Pidloc: Cross-view pose optimization network inspired by pid con- trollers,
W. Lee, J. Park, D. Hong, C. Sung, Y . Seo, D. Kang, and H. Myung, “Pidloc: Cross-view pose optimization network inspired by pid con- trollers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 21 981–21 990
2025
-
[5]
Fgˆ2: Fine-grained cross-view localization by fine-grained feature matching,
Z. Xia and A. Alahi, “Fgˆ2: Fine-grained cross-view localization by fine-grained feature matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 6362–6372
2025
-
[6]
Planet dump retrieved from https://planet.osm.org ,
OpenStreetMap contributors, “Planet dump retrieved from https://planet.osm.org ,” https://www.openstreetmap.org, 2017
2017
-
[7]
Combining openstreetmap with satellite imagery to enhance cross-view geo-localization,
Y . Hu, Y . Liu, and B. Hui, “Combining openstreetmap with satellite imagery to enhance cross-view geo-localization,”Sensors, vol. 25, no. 1, 2025
2025
-
[8]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” 2021. [Online]. Available: https://arxiv.org/abs/2010.04159
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Bev- former: Learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bev- former: Learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 47, no. 03, pp. 2020–2036, 2025
2020
-
[10]
Vigor: Cross-view image geo- localization beyond one-to-one retrieval,
S. Zhu, T. Yang, and C. Chen, “Vigor: Cross-view image geo- localization beyond one-to-one retrieval,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 3640–3649
2021
-
[11]
Visual cross-view metric localization with dense uncertainty estimates,
Z. Xia, O. Booij, M. Manfredi, and J. F. P. Kooij, “Visual cross-view metric localization with dense uncertainty estimates,” inComputer Vision - ECCV 2022, vol. 13699, 2022, pp. 90–106
2022
-
[12]
Convolutional cross-view pose estimation,
Z. Xia, O. Booij, and J. F. P. Kooij, “Convolutional cross-view pose estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3813–3831, 2024
2024
-
[13]
Slicematch: Geometry-guided aggregation for cross-view pose estimation,
T. Lentsch, Z. Xia, H. Caesar, and J. F. P. Kooij, “Slicematch: Geometry-guided aggregation for cross-view pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 17 225–17 234
2023
-
[14]
F. Fervers, S. Bullinger, C. Bodensteiner, M. Arens, and R. Stiefelhagen, “C-bev: Contrastive bird’s eye view training for cross-view image retrieval and 3-dof pose estimation,” 2023. [Online]. Available: https://arxiv.org/abs/2312.08060
-
[15]
Uncertainty-aware vision-based metric cross-view geolocalization,
F. Florian, B. Sebastian, B. Christoph, A. Michael, and S. Rainer, “Uncertainty-aware vision-based metric cross-view geolocalization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 21 621–21 631
2023
-
[16]
Snap: Self-supervised neural maps for visual positioning and semantic un- derstanding,
P.-E. Sarlin, E. Trulls, M. Pollefeys, J. Hosang, and S. Lynen, “Snap: Self-supervised neural maps for visual positioning and semantic un- derstanding,” inAdvances in Neural Information Processing Systems, vol. 36. Curran Associates, Inc., 2023, pp. 7697–7729
2023
-
[17]
Learning dense flow field for highly-accurate cross-view camera localization,
Z. Song, z. xianghui, J. Lu, and Y . Shi, “Learning dense flow field for highly-accurate cross-view camera localization,” inAdvances in Neural Information Processing Systems, vol. 36. Curran Associates, Inc., 2023, pp. 70 612–70 625
2023
-
[18]
Fine-grained cross- view geo-localization using a correlation-aware homography estima- tor,
X. Wang, R. Xu, Z. Cui, Z. Wan, and Y . Zhang, “Fine-grained cross- view geo-localization using a correlation-aware homography estima- tor,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[19]
View consistent purification for accurate cross-view localization,
S. Wang, Y . Zhang, A. Perincherry, A. V ora, and H. Li, “View consistent purification for accurate cross-view localization,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 8163–8172
2023
-
[20]
Franklin, J
G. Franklin, J. Powell, and A. Emami-Naeini,Feedback Control Of Dynamic Systems, 01 1994
1994
-
[21]
Orienternet: Visual localization in 2d public maps with neural match- ing,
P.-E. Sarlin, D. DeTone, T.-Y . Yang, A. Avetisyan, J. Straub, T. Mal- isiewicz, S. R. Bul `o, R. Newcombe, P. Kontschieder, and V . Balntas, “Orienternet: Visual localization in 2d public maps with neural match- ing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 21 632–21 642
2023
-
[22]
Maplocnet: Coarse-to-fine feature registration for visual re- localization in navigation maps,
H. Wu, Z. Zhang, S. Lin, X. Mu, Q. Zhao, M. Yang, and T. Qin, “Maplocnet: Coarse-to-fine feature registration for visual re- localization in navigation maps,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 13 198–13 205
2024
-
[23]
Y . Liao, X. Chen, S. Kang, J. Li, Z. Dong, H. Fan, and B. Yang, “Osm- loc: Single image-based visual localization in openstreetmap with geometric and semantic guidances,”arXiv preprint arXiv:2411.08665, 2024
-
[24]
Lalaloc: Latent layout localisation in dynamic, unvisited environ- ments,
H. Howard-Jenkins, J.-R. Ruiz-Sarmiento, and V . A. Prisacariu, “Lalaloc: Latent layout localisation in dynamic, unvisited environ- ments,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 10 107–10 116
2021
-
[25]
Laser: Latent space rendering for 2d visual localization,
Z. Min, N. Khosravan, Z. Bessinger, M. Narayana, S. B. Kang, E. Dunn, and I. Boyadzhiev, “Laser: Latent space rendering for 2d visual localization,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 11 112–11 121
2022
-
[26]
Lalaloc++: Global floor plan comprehension for layout localisation in unvisited environments,
H. Howard-Jenkins and V . A. Prisacariu, “Lalaloc++: Global floor plan comprehension for layout localisation in unvisited environments,” 2022
2022
-
[27]
F 3loc: Fusion and filtering for floorplan localization,
C. Chen, R. Wang, C. V ogel, and M. Pollefeys, “F 3loc: Fusion and filtering for floorplan localization,”CVPR, 2024
2024
-
[28]
City-level aerial geo-localization based on map matching network,
Y . Tang, J. Zhang, J. Gong, Y . Li, and B. Yang, “City-level aerial geo-localization based on map matching network,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 229, pp. 65–77, 2025
2025
-
[29]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,”ICLR, 2021
2021
-
[30]
Unibev: Multi- modal 3d object detection with uniform bev encoders for robustness against missing sensor modalities,
S. Wang, H. Caesar, L. Nan, and J. F. P. Kooij, “Unibev: Multi- modal 3d object detection with uniform bev encoders for robustness against missing sensor modalities,” in2024 IEEE Intelligent V ehicles Symposium (IV), 2024, pp. 2776–2783
2024
-
[31]
Boosting 3- dof ground-to-satellite camera localization accuracy via geometry- guided cross-view transformer,
Y . Shi, F. Wu, A. Perincherry, A. V ora, and H. Li, “Boosting 3- dof ground-to-satellite camera localization accuracy via geometry- guided cross-view transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 21 516–21 526
2023
-
[32]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”International Journal of Robotics Research (IJRR), 2013
2013
-
[33]
Accurate 3-dof camera geo-localization via ground-to-satellite image matching,
Y . Shi, X. Yu, L. Liu, D. Campbell, P. Koniusz, and H. li, “Accurate 3-dof camera geo-localization via ground-to-satellite image matching,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PP, pp. 1–16, 07 2022
2022
-
[34]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.