FlexPath: Learned Semantic Path Priors for Image-Based Planning
Pith reviewed 2026-06-27 16:39 UTC · model grok-4.3
The pith
FlexPath learns a task-independent spatial prior over feasible paths from images then adapts it to new objectives using only differentiable shape objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
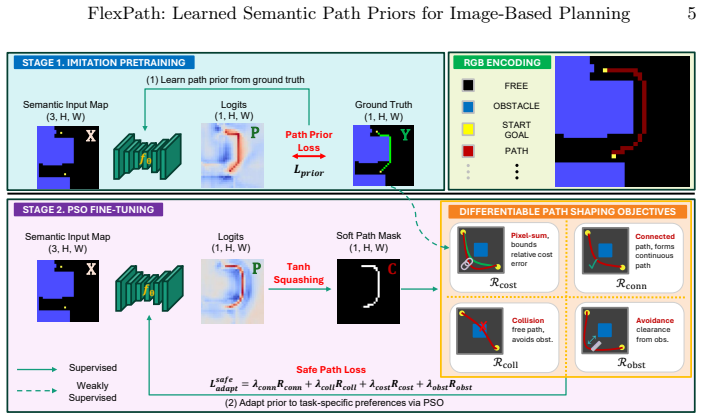
FlexPath decouples feasibility from preference by acquiring a task-independent spatial prior over feasible paths from visual map inputs through imitation learning, then adapting this prior to task-specific criteria using differentiable Path Shape Objectives without relearning path structure.
What carries the argument
differentiable Path Shape Objectives (PSOs) that adapt the learned spatial prior toward task-specific criteria at the objective level
If this is right
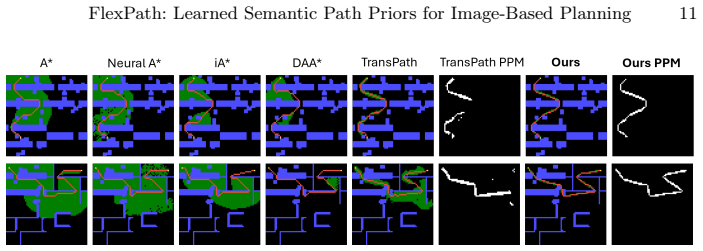
- Search effort on TMP drops 14.3 percent versus TransPath for shortest-path planning while average path cost also decreases.
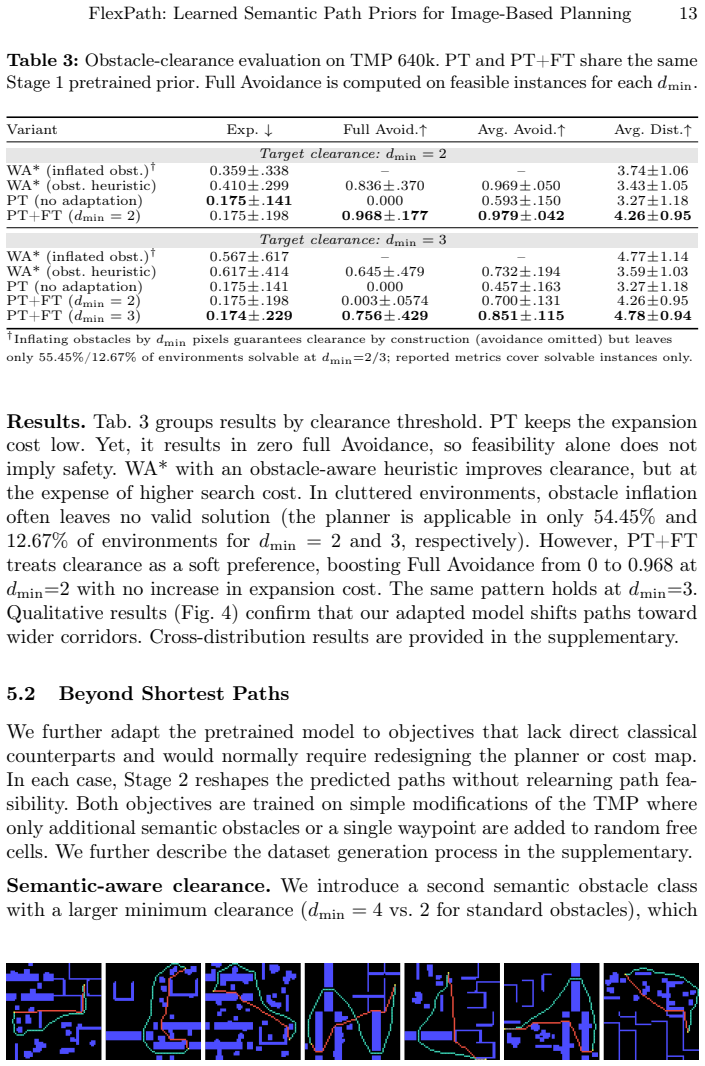
- The same model achieves 96.8 percent full obstacle avoidance at minimum clearance distance 2 with low search cost.
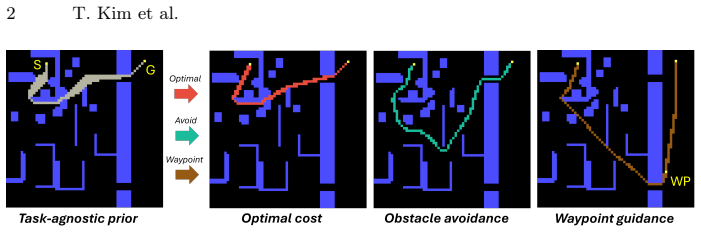
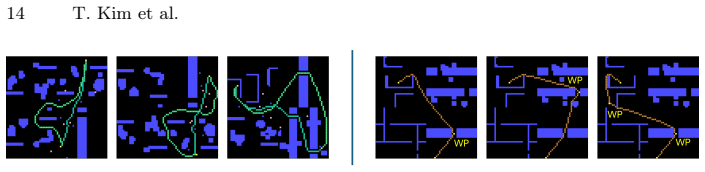
- Objective-level adaptation alone produces semantic-aware avoidance and waypoint guidance.
- Strong zero-shot generalization holds across three unseen domains.
- The learned prior remains compatible with classical planners at inference time.
Where Pith is reading between the lines
- A robotics system could switch between planning criteria in real time by swapping only the objective function.
- The separation of prior and objective may reduce data needs when new cost functions appear after initial training.
- Because the prior is image-based and task-independent, it could transfer to other visual navigation settings with minimal additional labels.
Load-bearing premise
The spatial prior learned in stage one stays general enough that differentiable PSOs in stage two can reshape it for new objectives without any retraining of path feasibility.
What would settle it
Training a single-stage model on shortest-path data only and testing it directly on a clearance objective without any PSO adaptation; if performance collapses relative to the two-stage version, the decoupling claim is falsified.
Figures
read the original abstract
Recent learning-based path planners use neural networks to process visual map representations and approximate heuristics for classical search algorithms, yielding near-optimal paths with reduced search effort. However, these methods are tied to the shortest-path objective implicit in their supervision, which limits their flexibility to accommodate alternative criteria. We introduce FlexPath, a two-stage framework that decouples feasibility from preference. In Stage 1, we use imitation learning to acquire a task-independent spatial prior over feasible paths from visual map inputs. In Stage 2, differentiable Path Shape Objectives (PSOs) adapt this prior toward task-specific criteria without relearning path structure, requiring only efficient objective-level adaptation. A single pretrained model can be adapted to multiple objectives. For shortest-path planning, FlexPath reduces search effort on TMP by 14.3% compared to the state-of-the-art TransPath, while also finding lower-cost paths on average and demonstrating strong zero-shot generalization across three unseen domains. For obstacle clearance with minimum clearance distance 2, it achieves 96.8% full obstacle avoidance while maintaining low search cost. The framework further extends to semantic-aware avoidance and waypoint guidance via objective-level adaptation, and remains compatible with classical planners at inference time. Data and code are available at https://github.com/FraunhoferIVI/FlexPath.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlexPath, a two-stage framework for image-based path planning. Stage 1 applies imitation learning to acquire a task-independent spatial prior over feasible paths from visual map inputs. Stage 2 uses differentiable Path Shape Objectives (PSOs) to adapt the prior to task-specific criteria (shortest-path, obstacle clearance, semantic avoidance, waypoint guidance) without retraining the core model. Reported results include a 14.3% reduction in search effort versus TransPath on TMP for shortest paths, lower average costs, 96.8% full avoidance for clearance distance 2, strong zero-shot generalization to three unseen domains, and compatibility with classical planners at inference. Code and data are released.
Significance. If the decoupling of feasibility from preference holds and the prior remains adaptable, the approach would allow a single pretrained model to support multiple planning objectives via lightweight objective-level tuning, which is a meaningful advance over methods tied to a single implicit objective. The public release of code and data is a clear strength for verification and extension.
major comments (3)
- [§3.1] §3.1 (Stage 1 imitation learning): the description of the spatial prior does not specify the distribution or generation method of the expert trajectories used for supervision. If these experts are produced by shortest-path algorithms (e.g., A*), the learned distribution already encodes a length preference, which would make the subsequent PSO adaptation correct a biased rather than neutral prior and undermine the central decoupling claim.
- [§4.1, Table 2] §4.1 and Table 2 (shortest-path results): the 14.3% search-effort reduction and lower-cost claim are presented as point estimates without reported standard deviations, number of independent runs, or statistical significance tests; this is load-bearing for the comparison to TransPath and the generalization statements.
- [§4.3] §4.3 (zero-shot generalization): the three unseen domains are described only at a high level; it is unclear whether they differ in map topology, sensor characteristics, or only in objective, which directly affects whether the results demonstrate structural adaptability of the Stage-1 prior via PSOs alone.
minor comments (2)
- [Abstract] The abstract states that the framework 'remains compatible with classical planners at inference time,' but the exact interface (e.g., how the adapted prior is injected into A* or other search) is only sketched; a short pseudocode block would improve clarity.
- [§3.2] Notation for the PSO parameters (e.g., the weighting vector w in the objective) is introduced without an explicit table summarizing all tunable scalars across the four tasks; this would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make the indicated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Stage 1 imitation learning): the description of the spatial prior does not specify the distribution or generation method of the expert trajectories used for supervision. If these experts are produced by shortest-path algorithms (e.g., A*), the learned distribution already encodes a length preference, which would make the subsequent PSO adaptation correct a biased rather than neutral prior and undermine the central decoupling claim.
Authors: We agree that explicit details on expert trajectory generation are needed to substantiate the task-independent claim. The experts are generated via a randomized feasible-path sampler that produces collision-free trajectories without optimizing any preference (length or otherwise). We will revise §3.1 to fully describe the sampling procedure and confirm the absence of objective-specific bias in the prior. revision: yes
-
Referee: [§4.1, Table 2] §4.1 and Table 2 (shortest-path results): the 14.3% search-effort reduction and lower-cost claim are presented as point estimates without reported standard deviations, number of independent runs, or statistical significance tests; this is load-bearing for the comparison to TransPath and the generalization statements.
Authors: We acknowledge the need for statistical rigor. The results derive from multiple runs, but variance was not reported. In revision we will add standard deviations, state the number of independent runs, and include significance tests (e.g., paired t-tests) for the Table 2 comparisons. revision: yes
-
Referee: [§4.3] §4.3 (zero-shot generalization): the three unseen domains are described only at a high level; it is unclear whether they differ in map topology, sensor characteristics, or only in objective, which directly affects whether the results demonstrate structural adaptability of the Stage-1 prior via PSOs alone.
Authors: We will expand §4.3 with concrete details. The domains differ in map topology (distinct layouts and obstacle densities) and sensor characteristics (noise models and resolutions), while the objective matches the training distribution. This clarifies that the results reflect structural adaptability of the prior via PSOs. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper presents a two-stage framework where Stage 1 uses imitation learning on visual inputs to learn a spatial prior, and Stage 2 applies differentiable PSOs for adaptation. No equations, self-citations, or fitted parameters are shown in the abstract or description that reduce predictions or uniqueness claims to inputs by construction. Empirical comparisons to TransPath and zero-shot results are presented as independent evaluations. The central decoupling is asserted via the framework design rather than derived from self-referential definitions or prior self-citations that bear the load. This is a standard non-finding for papers whose claims rest on external benchmarks and implementation details not reducible to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The International Journal of Robotics Research35, 224 – 243 (2014) FlexPath: Learned Semantic Path Priors for Image-Based Planning 15
Aine, S., Swaminathan, S., Narayanan, V., Hwang, V., Likhachev, M.: Multi- heuristic A*. The International Journal of Robotics Research35, 224 – 243 (2014) FlexPath: Learned Semantic Path Priors for Image-Based Planning 15
2014
-
[2]
In: 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS ’24)
Ansel, J., Yang, E., He, H., Gimelshein, N., Jain, A., Voznesensky, M., Bao, B., Bell, P., Berard, D., Burovski, E., Chauhan, G., Chourdia, A., Constable, W., Desmaison, A., DeVito, Z., Ellison, E., Feng, W., Gong, J., Gschwind, M., Hirsh, B., Huang, S., Kalambarkar, K., Kirsch, L., Lazos, M., Lezcano, M., Liang, Y., Liang, J., Lu, Y., Luk, C., Maher, B.,...
2024
-
[3]
Master’s thesis, TU Dresden and Fraunhofer IVI (Jan 2023)
Babu, H.: Reinforcement Learning Based Path Planning for Autonomous Flight. Master’s thesis, TU Dresden and Fraunhofer IVI (Jan 2023)
2023
-
[4]
arXiv preprint arXiv:2507.13491 (2025)
Banker, T., Mesbah, A.: Model-free reinforcement learning for model-based control: Towards safe, interpretable and sample-efficient agents. arXiv preprint arXiv:2507.13491 (2025)
-
[5]
In: Levine, S., Vanhoucke, V., Goldberg, K
Bhardwaj, M., Choudhury, S., Scherer, S.: Learning heuristic search via imitation. In: Levine, S., Vanhoucke, V., Goldberg, K. (eds.) Proceedings of the 1st Annual Conference on Robot Learning. Proceedings of Machine Learning Research, vol. 78, pp. 271–280. PMLR (13–15 Nov 2017)
2017
-
[6]
IEEE Robotics and Automation Letters10(12), 12987–12994 (Dec 2025)
Chen, X., Yang, F., Wang, C.: iA*: Imperative learning-based A* search for path planning. IEEE Robotics and Automation Letters10(12), 12987–12994 (Dec 2025)
2025
-
[7]
MIT press (2005)
Choset, H., Lynch, K.M., Hutchinson, S., Kantor, G., Burgard, W., Kavraki, L.E., Thrun, S.: Principles of robot motion: theory, algorithms, and implementations. MIT press (2005)
2005
-
[8]
In: International Joint Conference on Artificial Intelligence (2018)
Cohen, L., Greco, M., Ma, H., Hernández, C., Felner, A., Kumar, T.K.S., Koenig, S.: Anytime focal search with applications. In: International Joint Conference on Artificial Intelligence (2018)
2018
-
[9]
Journal of Artificial Intelligence Research39, 533–579 (Oct 2010)
Daniel, K., Nash, A., Koenig, S., Felner, A.: Theta*: Any-angle path planning on grids. Journal of Artificial Intelligence Research39, 533–579 (Oct 2010)
2010
-
[10]
In: 2018 second international conference on intelligent computing and control systems (ICICCS)
Das, S.D., Bain, V., Rakshit, P.: Energy optimized robot arm path planning us- ing differential evolution in dynamic environment. In: 2018 second international conference on intelligent computing and control systems (ICICCS). pp. 1267–1272. IEEE (2018)
2018
-
[11]
AAAI Workshop - Technical Report (01 2008)
Dolgov, D., Thrun, S., Montemerlo, M., Diebel, J.: Practical search techniques in path planning for autonomous driving. AAAI Workshop - Technical Report (01 2008)
2008
-
[12]
Machine Learning110(9), 2419–2468 (2021)
Dulac-Arnold, G., Levine, N., Mankowitz, D.J., Li, J., Paduraru, C., Gowal, S., Hester,T.:Challengesofreal-worldreinforcementlearning:definitions,benchmarks and analysis. Machine Learning110(9), 2419–2468 (2021)
2021
-
[13]
In: International Conference on Social Robotics
Fernández Coleto, N., Ruiz Ramírez, E., Haarslev, F., Bodenhagen, L.: Towards socially acceptable, human-aware robot navigation. In: International Conference on Social Robotics. pp. 578–587. Springer (2019)
2019
-
[14]
IEEE Transactions on Systems Science and Cyber- netics4(2), 100–107 (1968)
Hart, P.E., Nilsson, N.J., Raphael, B.: A formal basis for the heuristic determina- tion of minimum cost paths. IEEE Transactions on Systems Science and Cyber- netics4(2), 100–107 (1968)
1968
-
[15]
arXiv preprint arXiv:2412.12650 (2024)
Ji, Y., Yun, K., Liu, Y., Xie, Z., Liu, H.: Neural-network-driven reward prediction as a heuristic: Advancing q-learning for mobile robot path planning. arXiv preprint arXiv:2412.12650 (2024)
-
[16]
Sensors24(5), 1422 (2024) 16 T
Kabir, R., Watanobe, Y., Islam, M.R., Naruse, K.: Enhanced robot motion block of a-star algorithm for robotic path planning. Sensors24(5), 1422 (2024) 16 T. Kim et al
2024
-
[17]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Kirilenko, D., Andreychuk, A., Panov, A., Yakovlev, K.: Transpath: Learning heuristics for grid-based pathfinding via transformers. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 12436–12443 (2023)
2023
-
[18]
In: 2024 6th International Conference on Communications, Information System and Computer Engineering (CISCE)
Liu, H., Shen, Y., Zhou, C., Zou, Y., Gao, Z., Wang, Q.: Td3 based collision free motion planning for robot navigation. In: 2024 6th International Conference on Communications, Information System and Computer Engineering (CISCE). pp. 247–250. IEEE (2024)
2024
-
[19]
IEEE Transactions on Intelligent Transportation Systems23(4), 3061–3073 (2022)
Liu, H., Li, X., Fan, M., Wu, G., Pedrycz, W., Nagaratnam Suganthan, P.: An autonomous path planning method for unmanned aerial vehicle based on a tan- gent intersection and target guidance strategy. IEEE Transactions on Intelligent Transportation Systems23(4), 3061–3073 (2022)
2022
-
[20]
Expert Systems with Applications227, 120254 (2023)
Liu, L., Wang, X., Yang, X., Liu, H., Li, J., Wang, P.: Path planning techniques for mobile robots: Review and prospect. Expert Systems with Applications227, 120254 (2023)
2023
-
[21]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
In: International Conference on Learning Representations (2017)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2017)
2017
-
[23]
In: 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems
Lu, D.V., Hershberger, D., Smart, W.D.: Layered costmaps for context-sensitive navigation. In: 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems. pp. 709–715 (2014)
2014
-
[24]
arXiv preprint arXiv:2507.15469 (2025)
Nguyen,T.T.,Nahavandi,S.,Razzak,I.,Nguyen,D.,Pham,N.T.,Nguyen,Q.V.H.: The emergence of deep reinforcement learning for path planning. arXiv preprint arXiv:2507.15469 (2025)
-
[25]
In: Koyejo, S., Mo- hamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L., Simens, M., Askell, A., Welinder, P., Christiano, P.F., Leike, J., Lowe, R.: Training language models to follow instructions with human feedback. In: Koyejo, S., Mo- hamed, S., Agarwal, A., ...
2022
-
[26]
IEEE Transactions on Pattern Analysis and Machine IntelligencePAMI-4(4), 392–399 (1982)
Pearl, J., Kim, J.H.: Studies in semi-admissible heuristics. IEEE Transactions on Pattern Analysis and Machine IntelligencePAMI-4(4), 392–399 (1982)
1982
-
[27]
Pohl, I.: Heuristic search viewed as path finding in a graph. Artif. Intell.1, 193–204 (1970)
1970
-
[28]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Di- rect preference optimization: Your language model is secretly a reward model. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Ad- vances in Neural Information Processing Systems. vol. 36, pp. 53728–53741. Curran Associates, Inc. (2023)
2023
-
[29]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Rajeswaran, A., Kumar, V., Gupta, A., Vezzani, G., Schulman, J., Todorov, E., Levine, S.: Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. arXiv preprint arXiv:1709.10087 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Robotics and Autonomous Systems174, 104630 (2024)
Reda, M., Onsy, A., Haikal, A.Y., Ghanbari, A.: Path planning algorithms in the autonomous driving system: A comprehensive review. Robotics and Autonomous Systems174, 104630 (2024)
2024
-
[31]
In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) Medical Image Computing and Computer-Assisted Intervention – MICCAI
-
[32]
pp. 234–241. Springer International Publishing, Cham (2015) FlexPath: Learned Semantic Path Priors for Image-Based Planning 17
2015
-
[33]
Pearson (2020)
Russell, S.J., Norvig, P.: Artificial Intelligence: A Modern Approach (4th Edition). Pearson (2020)
2020
-
[34]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
In: Field and Service Robotics (2017)
Shah, S., Dey, D., Lovett, C., Kapoor, A.: Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In: Field and Service Robotics (2017)
2017
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Silver, T., Allen, K., Tenenbaum, J., Kaelbling, L.: Residual policy learning. arXiv preprint arXiv:1812.06298 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
IEEE Transactions on Computational Intelligence and AI in Games4(2), 144–148 (2012)
Sturtevant, N.R.: Benchmarks for grid-based pathfinding. IEEE Transactions on Computational Intelligence and AI in Games4(2), 144–148 (2012)
2012
-
[39]
In: Proceedings of the AAAI conference on artificial intelligence
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI conference on artificial intelligence. vol. 31 (2017)
2017
-
[40]
IEEE Transactions on Intelligent Vehicles8(6), 3692–3711 (2023)
Teng, S., Hu, X., Deng, P., Li, B., Li, Y., Ai, Y., Yang, D., Li, L., Xuanyuan, Z., Zhu, F., Chen, L.: Motion planning for autonomous driving: The state of the art and future perspectives. IEEE Transactions on Intelligent Vehicles8(6), 3692–3711 (2023)
2023
-
[41]
Information Sciences739, 123149 (2026)
Thellier, E., Perrusquía, A., Tsourdos, A.: Scalable and generalizable path plan- ning for robotic navigation using transformer-based heuristic learning. Information Sciences739, 123149 (2026)
2026
-
[42]
In: 2023 IEEE International Conference on Robotics and Automation (ICRA)
Triest, S., Castro, M.G., Maheshwari, P., Sivaprakasam, M., Wang, W., Scherer, S.: Learning risk-aware costmaps via inverse reinforcement learning for off-road navigation. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 924–930 (2023)
2023
-
[43]
In: Neural Information Processing Systems (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Neural Information Processing Systems (2017)
2017
-
[44]
In: International Conference on Learning Rep- resentations
Vlastelica*, M., Paulus*, A., Musil, V., Martius, G., Rolínek, M.: Differentiation of blackbox combinatorial solvers. In: International Conference on Learning Rep- resentations. ICLR’20 (May 2020), *Equal Contribution
2020
-
[45]
Machine learning8(3), 279–292 (1992)
Watkins, C.J., Dayan, P.: Q-learning. Machine learning8(3), 279–292 (1992)
1992
-
[46]
Ocean Engineering284, 115208 (2023)
Wu, C., Yu, W., Li, G., Liao, W.: Deep reinforcement learning with dynamic windowapproachbasedcollisionavoidancepathplanningformaritimeautonomous surface ships. Ocean Engineering284, 115208 (2023)
2023
-
[47]
Autonomous Robots46(5), 569–597 (2022)
Xiao, X., Liu, B., Warnell, G., Stone, P.: Motion planning and control for mobile robot navigation using machine learning: a survey. Autonomous Robots46(5), 569–597 (2022)
2022
-
[48]
In: Neural Information Processing Systems (NeurIPS) (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. In: Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[49]
In: Zeng, N., Pachori, R.B., Wang, D
Xu, L., Zhang, W.: Survey on path planning based on deep reinforcement learning. In: Zeng, N., Pachori, R.B., Wang, D. (eds.) Proceedings of 2025 2nd International Conference on Machine Learning and Intelligent Computing. Proceedings of Ma- chine Learning Research, vol. 278, pp. 685–695. PMLR (25–27 Apr 2025)
2025
-
[50]
In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Xu, Z.: DAA*: Deep angular a star for image-based path planning. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 25284–25293 (October 2025) 18 T. Kim et al
2025
-
[51]
In: International conference on machine learning
Yonetani, R., Taniai, T., Barekatain, M., Nishimura, M., Kanezaki, A.: Path plan- ning using Neural A* search. In: International conference on machine learning. pp. 12029–12039. PMLR (2021)
2021
-
[52]
Neurocomputing608, 128423 (2024)
Zhang, Y., Zhao, W., Wang, J., Yuan, Y.: Recent progress, challenges and future prospects of applied deep reinforcement learning : A practical perspective in path planning. Neurocomputing608, 128423 (2024)
2024
-
[53]
Zhou, Q., Lian, Y., Wu, J., Zhu, M., Wang, H., Cao, J.: An optimized q-learning algorithm for mobile robot local path planning. Knowledge-Based Systems286, 111400 (2024) FlexPath: Learned Semantic Path Priors for Image-Based Planning 19 Supplementary Material Overview.This supplementary material provides details omitted from the main paper due to space co...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.