Benchmarking and Exploring the Capabilities of LLMs for Attack Investigations
Pith reviewed 2026-06-27 13:09 UTC · model grok-4.3
The pith
AuditBench evaluates LLMs on four security log investigation tasks across 50 scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AuditBench consists of system audit logs collected from Linux and Windows machines and spans over 50 different security investigation scenarios, including both malicious and benign activity. Using this benchmark, five frontier LLMs are evaluated on four log-investigation tasks that incident response teams commonly perform, ranging from triaging alerts generated by detectors to identifying persistence mechanisms on compromised systems. The analysis shows how LLM performance and error profiles vary according to different design choices such as differences in model size, data representation, prompt construction, and specific investigation tasks, while also characterizing the quality of the expl
What carries the argument
AuditBench, a benchmark dataset of Linux and Windows system audit logs spanning 50+ security scenarios for testing LLMs on four incident-response tasks.
If this is right
- LLM performance on security log analysis depends on choices like model size, data representation, and prompt construction.
- Models produce explanations of varying quality and commit distinct error types that differ by task.
- Practitioners gain concrete guidance on when and how to apply LLMs in security operations.
- Future work can target the specific weaknesses identified in current model behavior on these tasks.
Where Pith is reading between the lines
- Benchmarks of this form could be extended to other log types such as network or application logs to test broader LLM utility.
- Error profiles could guide the design of hybrid systems that combine LLMs with rule-based detectors for better reliability.
- Longitudinal testing on evolving attack techniques would reveal whether current performance holds as threats change.
Load-bearing premise
The 50+ scenarios and four tasks in AuditBench are representative of the actual challenges and data distributions that incident response teams encounter in production environments.
What would settle it
Measure how often the same LLMs reach correct conclusions on a fresh collection of audit logs drawn directly from real production security incidents, compared against expert human analysts.
Figures
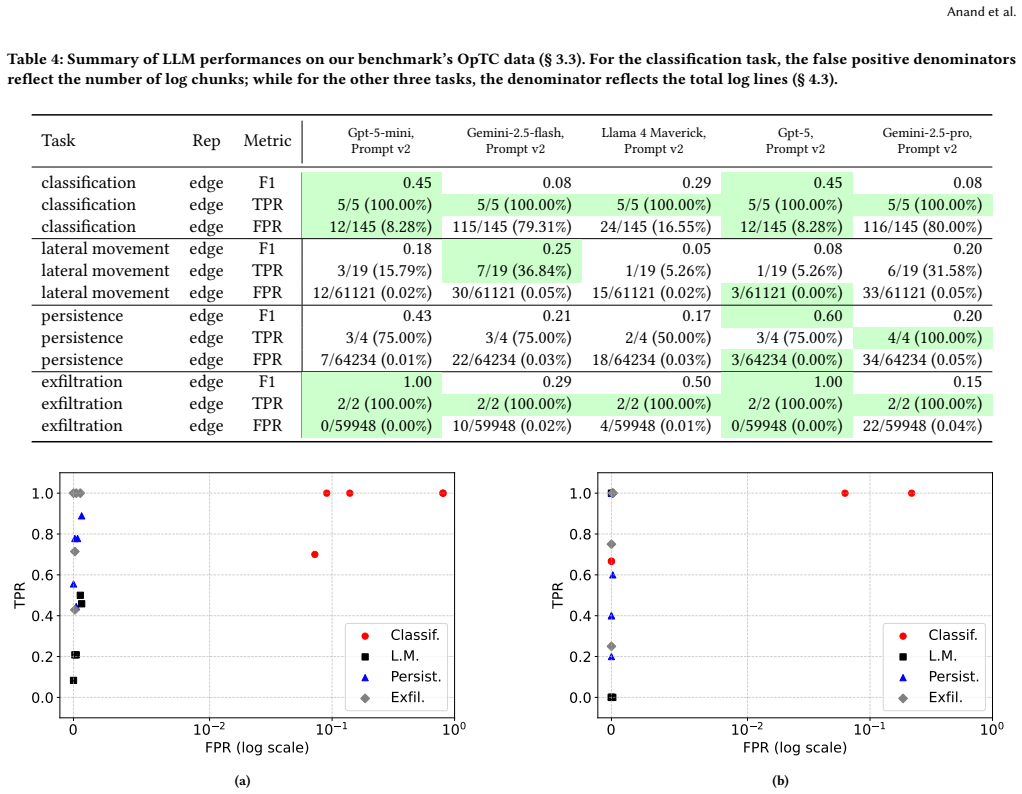
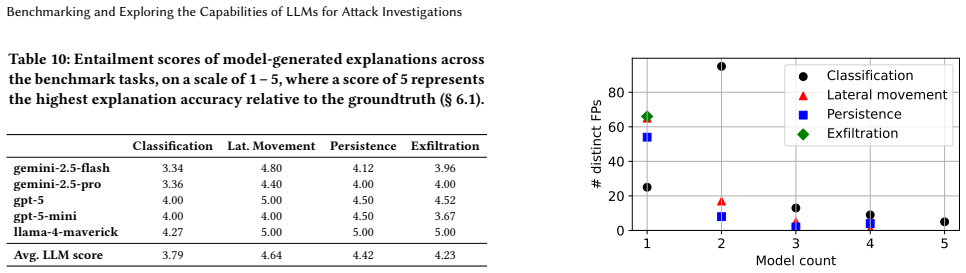
read the original abstract
This paper presents AuditBench, a new benchmark dataset for evaluating the capabilities of LLMs at investigating security-related system audit logs. We design and use this benchmark to explore the performance of LLMs on four log-investigation tasks that incident response teams commonly perform, ranging from triaging alerts generated by detectors to identifying persistence mechanisms on compromised systems. AuditBench consists of system audit logs collected from Linux and Windows machines, and spans over 50 different security investigation scenarios, including both malicious and benign activity. Using our benchmark, we evaluate and analyze the performance of five frontier LLMs at analyzing audit logs for attack investigations. Our analysis illuminates how LLM performance and error profiles vary according to different design choices, such as differences in model size, data representation, prompt construction, and specific investigation tasks. Additionally, we characterize the quality of the explanations produced by LLMs and the types of errors that models make across our benchmark. Collectively, our work provides a foundation for assessing the capabilities of LLMs for investigating security logs, novel insights for practitioners using LLMs in security operations, and important directions for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AuditBench, a benchmark of system audit logs from Linux and Windows machines spanning over 50 security investigation scenarios (malicious and benign), and uses it to evaluate five frontier LLMs on four incident-response tasks (alert triaging to persistence-mechanism identification). It analyzes how performance and error profiles vary with model size, data representation, prompt construction, and task, characterizes explanation quality, and claims to supply a foundation for LLM assessment in security logs plus practitioner insights.
Significance. If the scenarios prove representative of production IR distributions and ground truth is rigorously established, the benchmark and error analysis would supply a useful empirical foundation for LLM evaluation in security operations and concrete directions for prompt/model improvements. The current lack of validation evidence against real corpora substantially reduces the strength of those claims.
major comments (2)
- [Abstract; benchmark design paragraph] Abstract and benchmark-design section: the central claim that AuditBench supplies 'a foundation for assessing the capabilities of LLMs for investigating security logs' and 'novel insights for practitioners' rests on the 50+ scenarios being representative of real incident-response data distributions. No quantitative comparison (event-type histograms, alert density, persistence-mechanism prevalence, etc.) to any production IR corpus, nor expert validation of realism, is described; without this the reported performance numbers and error profiles cannot be assumed to generalize.
- [Abstract] Abstract: the description of the evaluation supplies no information on how the 50+ scenarios were validated, how ground truth labels were established, what statistical controls or inter-annotator agreement measures were applied, or any quantitative performance numbers. This omission makes the data-to-claim link unverifiable from the provided text.
minor comments (1)
- [Abstract] Abstract states the benchmark 'spans over 50 different security investigation scenarios' but does not indicate the exact count, task distribution, or balance between malicious and benign cases; adding these figures would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the benchmark's validation and the abstract's content. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract; benchmark design paragraph] Abstract and benchmark-design section: the central claim that AuditBench supplies 'a foundation for assessing the capabilities of LLMs for investigating security logs' and 'novel insights for practitioners' rests on the 50+ scenarios being representative of real incident-response data distributions. No quantitative comparison (event-type histograms, alert density, persistence-mechanism prevalence, etc.) to any production IR corpus, nor expert validation of realism, is described; without this the reported performance numbers and error profiles cannot be assumed to generalize.
Authors: We agree that the absence of quantitative comparisons to production corpora limits the strength of generalizability claims. Production security logs are typically not publicly shareable due to privacy and operational security reasons. The scenarios in AuditBench were constructed based on publicly documented attack techniques from sources such as MITRE ATT&CK and common system behaviors, with the goal of covering a diverse set of investigation tasks. We will revise the benchmark design section to provide additional details on the scenario generation process and any internal validation steps performed. However, direct quantitative matching to real corpora is not feasible without access to such data. revision: partial
-
Referee: [Abstract] Abstract: the description of the evaluation supplies no information on how the 50+ scenarios were validated, how ground truth labels were established, what statistical controls or inter-annotator agreement measures were applied, or any quantitative performance numbers. This omission makes the data-to-claim link unverifiable from the provided text.
Authors: The abstract is intended as a concise summary and does not include full methodological details, which are elaborated in the body of the paper. Ground truth labels were established by the authors through controlled execution of known malicious and benign activities in isolated environments, ensuring deterministic labels based on the scenario definitions. No inter-annotator agreement was required as the labels derive from the experimental setup rather than subjective judgment. Quantitative performance numbers are reported in the evaluation section. We will update the abstract to briefly reference the scenario validation approach and include example performance metrics to better link data to claims. revision: yes
- Direct quantitative comparison of AuditBench scenarios to proprietary production IR corpora due to lack of public access to such datasets.
Circularity Check
No circularity: empirical benchmark with independent dataset and measurements
full rationale
The paper constructs a new benchmark (AuditBench) from Linux/Windows audit logs across 50+ scenarios and measures LLM performance on four explicit tasks. No equations, fitted parameters, derivations, or self-citation chains appear in the abstract or described structure. Central claims rest on direct empirical results from the new data rather than reducing to prior inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Siraaj Akhtar, Saad Khan, and Simon Parkinson. 2025. LLM-based event log analysis techniques: A survey.arXiv preprint arXiv:2502.00677(2025)
arXiv 2025
-
[2]
Bushra A Alahmadi, Louise Axon, and Ivan Martinovic. 2022. 99% false positives: A qualitative study of {SOC} analysts’ perspectives on security alarms. In31st USENIX Security Symposium (USENIX Security’22). 2783–2800
2022
-
[3]
Bushra A Alahmadi, Louise Axon, and Ivan Martinovic. 2022. 99% false positives: A qualitative study of {SOC} analysts’ perspectives on security alarms. In31st USENIX Security Symposium (USENIX Security 22). 2783–2800
2022
-
[4]
Crispin Almodovar, Fariza Sabrina, Sarvnaz Karimi, and Salahuddin Azad. 2022. Can language models help in system security? investigating log anomaly detec- tion using bert. InProceedings of the 20th Annual Workshop of the Australasian Language Technology Association. 139–147
2022
-
[5]
Anthropic. 2025. Effective Context Engineering for AI Agents. https://www.anth ropic.com/engineering/effective-context-engineering-for-ai-agents. Accessed: November 1, 2025
2025
-
[6]
Sidahmed Benabderrahmane, Petko Valtchev, James Cheney, and Talal Rahwan
-
[7]
In2025 13th International Symposium on Digital Forensics and Security (ISDFS)
APT-LLM: Embedding-Based Anomaly Detection of Cyber Advanced Persistent Threats Using Large Language Models. In2025 13th International Symposium on Digital Forensics and Security (ISDFS). IEEE, 1–6
-
[8]
Tristan Bilot, Baoxiang Jiang, Zefeng Li, Nour El Madhoun, Khaldoun Al Agha, Anis Zouaoui, and Thomas Pasquier. 2025. Sometimes Simpler is Better: A Comprehensive Analysis of {State-of-the-Art} {Provenance-Based} Intrusion Detection Systems. In34th USENIX Security Symposium (USENIX Security 25). 7193–7212
2025
-
[9]
CrowdStrike Blog. 2023. Introducing Charlotte AI, CrowdStrike’s Generative AI Security Analyst: Ushering in the Future of AI-Powered Cybersecurity. https: //www.crowdstrike.com/en-us/blog/crowdstrike-introduces-charlotte-ai-to- deliver-generative-ai-powered-cybersecurity
2023
-
[10]
Red Canary. 2025. Atomic Red Team. https://www.atomicredteam.io/. [Online; accessed 28-April-2025]
2025
-
[11]
Zijun Cheng, Qiujian Lv, Jinyuan Liang, Yan Wang, Degang Sun, Thomas Pasquier, and Xueyuan Han. 2024. Kairos: Practical intrusion detection and investigation using whole-system provenance. In2024 IEEE Symposium on Secu- rity and Privacy (SP). IEEE, 3533–3551
2024
-
[12]
CMU Information Security Office. 2025. CMU Incident Response Procedure. https://www.cmu.edu/iso/governance/procedures/IRPlan.html
2025
-
[13]
MITRE Corporation. 2025. MITRE ATT&CK. https://attack.mitre.org/
2025
-
[14]
Tianyu Cui, Shiyu Ma, Ziang Chen, Tong Xiao, Chenyu Zhao, Shimin Tao, Yilun Liu, Shenglin Zhang, Duoming Lin, Changchang Liu, et al . 2025. LogEval: A comprehensive benchmark suite for LLMs in log analysis.Empirical Software Engineering30, 6 (2025), 173
2025
-
[15]
Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. InMachine learning challenges workshop. Springer, 177–190
2005
-
[16]
DARPA / Five Directions. 2020. Operationally Transparent Cyber (OpTC) Data Release. https://github.com/FiveDirections/OpTC-data
2020
-
[17]
DARPA I2O. 2020. DARPA Transparent Computing Data Release. https://github .com/darpa-i2o/Transparent-Computing
2020
-
[18]
Roman Daszczyszak, Dan Ellis, Steve Luke, and Sean Whitley. 2019. TTP-based hunting.MITRE Corp, McLean V A, Tech. Rep(2019)
2019
-
[19]
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. 2024. {PentestGPT}: Evaluating and harnessing large language models for automated penetration testing. In33rd USENIX Security Symposium (USENIX Security 24). 847–864
2024
-
[20]
Feng Dong, Shaofei Li, Peng Jiang, Ding Li, Haoyu Wang, Liangyi Huang, Xusheng Xiao, Jiedong Chen, Xiapu Luo, Yao Guo, et al. 2023. Are we there yet? an industrial viewpoint on provenance-based endpoint detection and response tools. InACM Conference on Computer and Communications Security
2023
-
[21]
Ashish Gehani and Dawood Tariq. 2012. SPADE: support for provenance auditing in distributed environments. InInternational Middleware Conference
2012
-
[22]
Google Developers. 2025. Prompting Strategies. https://ai.google.dev/gemini- api/docs/prompting-strategies. Accessed: November 1, 2025
2025
-
[23]
Wei Guan, Jian Cao, Shiyou Qian, Jianqi Gao, and Chun Ouyang. 2024. Logllm: Log-based anomaly detection using large language models.arXiv preprint arXiv:2411.08561(2024)
arXiv 2024
-
[24]
Haixuan Guo, Shuhan Yuan, and Xintao Wu. 2021. Logbert: Log anomaly detec- tion via bert. In2021 international joint conference on neural networks (IJCNN). IEEE, 1–8
2021
-
[25]
Xueyuan Han, Thomas Pasquier, Adam Bates, James Mickens, and Margo Seltzer
-
[26]
InNetwork and Distributed System Security Symposium (NDSS’20)
Unicorn: Runtime provenance-based detector for advanced persistent threats. InNetwork and Distributed System Security Symposium (NDSS’20). 1–19
-
[27]
Jia He, Mukund Rungta, David Koleczek, Arshdeep Sekhon, Franklin X Wang, and Sadid Hasan. 2024. Does prompt formatting have any impact on llm performance? arXiv preprint arXiv:2411.10541(2024)
arXiv 2024
-
[28]
IBM. 2025. IBM QRadar. https://www.ibm.com/products/qradar
2025
-
[29]
Muhammad Adil Inam, Yinfang Chen, Akul Goyal, Jason Liu, Jaron Mink, Noor Michael, Sneha Gaur, Adam Bates, and Wajih Ul Hassan. 2023. SoK: History is a Vast Early Warning System: Auditing the Provenance of System Intrusions . In IEEE Symposium on Security and Privacy (SP)
2023
-
[30]
Zian Jia, Yun Xiong, Yuhong Nan, Yao Zhang, Jinjing Zhao, and Mi Wen. 2024. {MAGIC}: Detecting advanced persistent threats via masked graph representa- tion learning. In33rd USENIX Security Symposium (USENIX Security 24). 5197– 5214
2024
-
[31]
Gavin Jones, Dimitrios Kasimatis, Nikolaos Pitropakis, Richard Macfarlane, and William J Buchanan. 2025. Analysing the role of LLMs in cybersecurity incident management.International Journal of Information Security24, 6 (2025), 1–14
2025
-
[32]
Diana Kramer, Lambert Rosique, Ajay Narotam, Elie Bursztein, Patrick Gage Kelley, Kurt Thomas, and Allison Woodruff. 2025. Integrating large language models into security incident response. InTwenty-First Symposium on Usable Privacy and Security (SOUPS 2025). 133–148
2025
-
[33]
Hwiwon Lee, Ziqi Zhang, Hanxiao Lu, and Lingming Zhang. 2025. SEC-bench: Automated Benchmarking of LLM Agents on Real-World Software Security Tasks. arXiv preprint arXiv:2506.11791(2025)
arXiv 2025
-
[34]
Chenyu Li, Zhengjia Zhu, Jiyan He, and Xiu Zhang. 2025. RedChronos: A Large Language Model-Based Log Analysis System for Insider Threat Detection in Enterprises.arXiv preprint arXiv:2503.02702(2025)
arXiv 2025
-
[35]
Lei Lin, Jiayi Fu, Pengli Liu, Qingyang Li, Yan Gong, Junchen Wan, Fuzheng Zhang, Zhongyuan Wang, Di Zhang, and Kun Gai. 2023. Just ask one more time! self-agreement improves reasoning of language models in (almost) all scenarios. arXiv preprint arXiv:2311.08154(2023)
arXiv 2023
-
[36]
Yilun Liu, Shimin Tao, Weibin Meng, Jingyu Wang, Wenbing Ma, Yuhang Chen, Yanqing Zhao, Hao Yang, and Yanfei Jiang. 2024. Interpretable online log analysis using large language models with prompt strategies. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 35–46
2024
-
[37]
Zeyang Ma, An Ran Chen, Dong Jae Kim, Tse-Hsun Chen, and Shaowei Wang
-
[38]
InProceedings of the IEEE/ACM 46th International Conference on Software Engineering
Llmparser: An exploratory study on using large language models for log parsing. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
-
[39]
Ashish Bharadwaj Madabhushana. 2021. Configure Linux system auditing with auditd. https://www.redhat.com/en/blog/configure-linux-auditing-auditd
2021
-
[40]
Microsoft. 2025. Process Monitor v4.01. https://learn.microsof t.com/en- us/sysinternals/downloads/procmon
2025
-
[41]
Microsoft Learn. 2025. Prompt engineering - Azure AI Foundry. https://learn. microsoft.com/en-us/azure/ai-foundry/openai/concepts/prompt-engineering. Accessed: November 1, 2025
2025
-
[42]
MITRE ATT&CK. 2025. eCAR - extended Cyber Analytics Repository Model. https://github.com/FiveDirections/OpTC-data/blob/master/ecar.md. [Online; accessed 28-April-2025]
2025
-
[43]
MITRE ATT&CK. 2025. MITRE Cyber Analytics Repository. https://car.mitre.or g/. [Online; accessed 28-April-2025]
2025
-
[44]
Alex Nelson, Sanjay Rekhi, Murugiah Souppaya, and Karen Scarfone. 2025. In- cident Response Recommendations and Considerations for Cybersecurity Risk Management.NIST SP 800-61r3(2025)
2025
-
[45]
NVIDIA. 2025. What is Chain of Thought (CoT) Prompting? https://www.nvid ia.com/en-us/glossary/cot-prompting/
2025
-
[46]
Thomas Pasquier, Xueyuan Han, Mark Goldstein, Thomas Moyer, David Eyers, Margo Seltzer, and Jean Bacon. 2017. Practical whole-system provenance capture. InSymposium on Cloud Computing
2017
-
[47]
Mati Ur Rehman, Hadi Ahmadi, and Wajih Ul Hassan. 2024. Flash: A compre- hensive approach to intrusion detection via provenance graph representation learning. In2024 IEEE Symposium on Security and Privacy (SP). IEEE, 3552–3570
2024
-
[48]
Microsoft Security. 2025. Microsoft Security Copilot. https://www.microsoft.co m/en-us/security/business/ai-machine-learning/microsoft-security-copilot
2025
-
[49]
Minghao Shao, Sofija Jancheska, Meet Udeshi, Brendan Dolan-Gavitt, Kimberly Milner, Boyuan Chen, Max Yin, Siddharth Garg, Prashanth Krishnamurthy, Far- shad Khorrami, et al. 2024. Nyu ctf bench: A scalable open-source benchmark dataset for evaluating llms in offensive security.Advances in Neural Information Processing Systems37 (2024), 57472–57498
2024
-
[50]
Chengyu Song, Linru Ma, Jianming Zheng, Jinzhi Liao, Hongyu Kuang, and Lin Yang. 2024. Audit-llm: Multi-agent collaboration for log-based insider threat detection.arXiv preprint arXiv:2408.08902(2024)
arXiv 2024
-
[51]
U.S. CISA. 2025. CISA Cybersecurity Incident Response. https://www.ci sa.gov/topics/cybersecurity- best- practices/organizations- and- cyber- safety/cybersecurity-incident-response
2025
-
[52]
Cybersecurity & Infrastructure Security Agency
U.S. Cybersecurity & Infrastructure Security Agency. 2021. Cybersecurity In- cident & Vulnerability Response Playbooks. https://www.cisa.gov/resources- tools/resources/federal- government- cybersecurity- incident- and- vulnerability-response-playbooks. Anand et al
2021
-
[53]
U.S. NIST. 2021. Cybersecurity Framework 1.1. https://www.nist.gov/cyberfram ework/getting-started/online-learning/five-functions
2021
-
[54]
U.S. NIST. 2025. Special Publication (SP) 800-61 Revision 3. https://csrc.nist.gov/ projects/incident-response
2025
-
[55]
Mark Vero, Niels Mündler, Victor Chibotaru, Veselin Raychev, Maximilian Baader, Nikola Jovanović, Jingxuan He, and Martin Vechev. 2025. BaxBench: Can LLMs generate correct and secure backends?arXiv preprint arXiv:2502.11844(2025)
arXiv 2025
-
[56]
Manfred Vielberth, Fabian Böhm, Ines Fichtinger, and Günther Pernul. 2020. Security Operations Center: A Systematic Study and Open Challenges.IEEE Access8 (2020)
2020
-
[57]
Dawei Wang, Geng Zhou, Xianglong Li, Yu Bai, Li Chen, Ting Qin, Jian Sun, and Dan Li. 2025. The Digital Cybersecurity Expert: How Far Have We Come?. In 2025 IEEE Symposium on Security and Privacy (S&P’25). IEEE, 3273–3290
2025
-
[58]
Lingzhi Wang, Xiangmin Shen, Weijian Li, Zhenyuan Li, R Sekar, Han Liu, and Yan Chen. 2025. Incorporating Gradients to Rules: Towards Lightweight, Adaptive Provenance-based Intrusion Detection. (2025)
2025
-
[59]
Su Wang, Zhiliang Wang, Tao Zhou, Hongbin Sun, Xia Yin, Dongqi Han, Han Zhang, Xingang Shi, and Jiahai Yang. 2022. Threatrace: Detecting and tracing host-based threats in node level through provenance graph learning.IEEE Transactions on Information Forensics and Security17 (2022), 3972–3987
2022
-
[60]
Zhun Wang, Tianneng Shi, Jingxuan He, Matthew Cai, Jialin Zhang, and Dawn Song. 2025. CyberGym: Evaluating AI Agents’ Cybersecurity Capabilities with Real-World Vulnerabilities at Scale.arXiv preprint arXiv:2506.02548(2025)
arXiv 2025
-
[61]
Wikipedia. 2025. F-score. https://en.wikipedia.org/wiki/F-score
2025
-
[62]
Yiran Wu, Mauricio Velazco, Andrew Zhao, Manuel Raúl Meléndez Luján, Srisuma Movva, Yogesh K Roy, Quang Nguyen, Roberto Rodriguez, Qingyun Wu, Michael Albada, et al. 2025. Excytin-bench: Evaluating llm agents on cyber threat investigation.arXiv preprint arXiv:2507.14201(2025)
Pith/arXiv arXiv 2025
-
[63]
Iyer, and Gang Wang
Limin Yang, Zhi Chen, Chenkai Wang, Zhenning Zhang, Sushruth Booma, Phuong Cao, Constantin Adam, Alexander Withers, Zbigniew Kalbarczyk, Ravis- hankar K. Iyer, and Gang Wang. 2024. True Attacks, Attack Attempts, or Benign Triggers? An Empirical Measurement of Network Alerts in a Security Operations Center. InUSENIX Security Symposium (USENIX Security’24)
2024
-
[64]
Andy K Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu, et al. 2025. BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems.arXiv preprint arXiv:2505.15216(2025)
arXiv 2025
-
[65]
Andy K Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Julian Jasper, et al
-
[66]
InThe Thirteenth International Conference on Learning Representations (ICLR’25)
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models. InThe Thirteenth International Conference on Learning Representations (ICLR’25)
-
[67]
Jie Zhang, Haoyu Bu, Hui Wen, Yongji Liu, Haiqiang Fei, Rongrong Xi, Lun Li, Yun Yang, Hongsong Zhu, and Dan Meng. 2025. When llms meet cybersecurity: A systematic literature review.Cybersecurity8, 1 (2025), 55
2025
-
[68]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems36 (2023), 46595–46623
2023
-
[69]
Aoxiao Zhong, Dengyao Mo, Guiyang Liu, Jinbu Liu, Qingda Lu, Qi Zhou, Jiesh- eng Wu, Quanzheng Li, and Qingsong Wen. 2024. Logparser-llm: Advancing efficient log parsing with large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4559–4570
2024
-
[70]
timestamp
Yuxuan Zhu, Antony Kellermann, Dylan Bowman, Philip Li, Akul Gupta, Adarsh Danda, Richard Fang, Conner Jensen, Eric Ihli, Jason Benn, et al. 2025. CVE-Bench: A Benchmark for AI Agents’ Ability to Exploit Real-World Web Application Vulnerabilities. InForty-second International Conference on Machine Learning (ICML’25). Open Science We will release all code ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.