MARCH: Model-Assisted Reinforcement Learning for the Perceptive Control of Humanoids over Sparse Footholds
Pith reviewed 2026-06-27 13:26 UTC · model grok-4.3
The pith
Model-assisted RL produces safe vision-only humanoid locomotion over sparse footholds by distilling from a privileged teacher guided by simplified-model references.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the three-step model-assisted procedure—generating safe references from simplified models, training a privileged teacher via CLF rewards around those references, and distilling to a vision student—yields physically grounded locomotion that improves sample efficiency, reduces curriculum complexity, produces smoother behavior, and reaches stepping-stone performance comparable to model-free baselines, with successful real-robot deployment.
What carries the argument
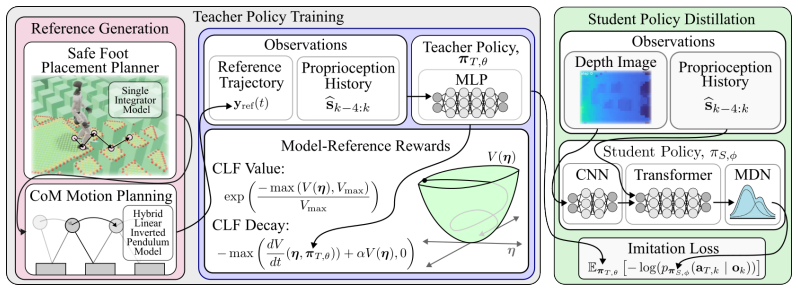
The three-step model-assisted RL framework that builds a CLF reward from safe reference trajectories generated by simplified models, trains a privileged teacher policy, and distills it to a vision-based student.
If this is right
- Training requires fewer samples than pure model-free RL on the same task.
- The method avoids the need for elaborate staged curricula to discover precise foot placements.
- Locomotion trajectories become smoother while retaining comparable success rates on stepping stones.
- The distilled vision policy can be deployed directly on hardware such as the Unitree G1 without additional fine-tuning.
- The same reference-generation plus distillation pattern can be applied to other constrained locomotion problems.
Where Pith is reading between the lines
- The framework may extend to terrains with moving footholds if the simplified models are updated accordingly.
- Policy distillation from privileged simulation information could reduce the sim-to-real gap for other perception-heavy robot tasks.
- The approach implies that hybrid model-RL methods can be tuned primarily through the choice of reference model rather than reward shaping alone.
Load-bearing premise
Simplified models produce reference trajectories that stay safe and useful enough to shape the CLF reward so the teacher's behavior transfers to the vision-only student without large performance loss.
What would settle it
Run the vision-only student policy on the same sparse-foothold courses used for the teacher and model-free baselines; if the student shows markedly higher fall rates or lower success than the baselines, the transfer claim fails.
Figures


read the original abstract
Perceptive bipedal locomotion over sparse terrain remains a difficult challenge: model-based methods are precise but brittle to uncertainty, while model-free methods are robust but struggle to discover the precise, constrained motions required for safety-critical locomotion where small errors can cause catastrophic failures. We propose a model-assisted reinforcement learning (RL) framework that combines both perspectives in three steps: (1) generate a safe reference trajectory using simplified models; (2) train a privileged teacher policy guided by a control Lyapunov function (CLF) reward built around the safe reference trajectory; and (3) distill the teacher into a vision-based student policy. We show that this model-assistance procedure produces physically grounded locomotion, improving sample efficiency, reducing the need for a complex learning curriculum, and achieving smoother locomotion behavior alongside stepping stone performance comparable to model-free baselines. We validate our approach in simulation and demonstrate successful deployment on a Unitree G1 humanoid robot navigating sparse footholds with lateral constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MARCH, a three-step model-assisted RL framework for perceptive bipedal locomotion over sparse footholds. It generates safe reference trajectories from simplified models, trains a privileged teacher policy using a control Lyapunov function (CLF) reward constructed around those references, and distills the teacher into a vision-only student policy. The authors claim the procedure yields physically grounded locomotion with improved sample efficiency, reduced need for complex curricula, smoother behavior, stepping-stone performance comparable to model-free baselines, and successful real-robot deployment on a Unitree G1 humanoid.
Significance. If the quantitative claims hold, the work offers a practical hybrid route between brittle model-based planning and sample-inefficient model-free RL for safety-critical locomotion. Demonstrating that simplified-model references can safely shape a CLF reward and that the resulting teacher transfers to a vision student without catastrophic degradation would be a useful contribution to humanoid control under perceptual constraints.
major comments (2)
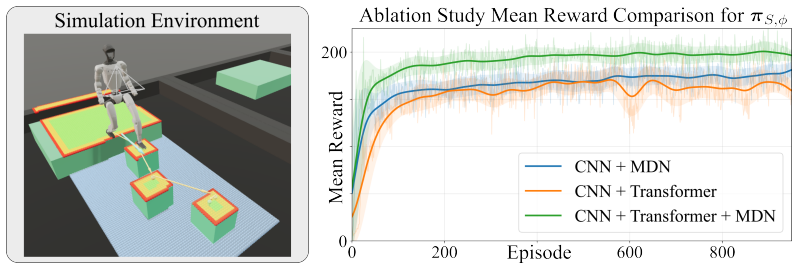
- [Abstract] Abstract: the central claims of 'improving sample efficiency,' 'reducing the need for a complex learning curriculum,' and 'achieving smoother locomotion behavior' are asserted without any numerical metrics, training curves, ablation results, or statistical comparisons. These assertions are load-bearing for the paper's contribution and must be supported by concrete data (e.g., sample counts to reach a success threshold, curriculum stage counts, or smoothness metrics such as jerk or torque variance) in the results section.
- [Abstract, §3] Abstract and §3 (method): the claim that simplified-model references remain 'safe and useful' when used to construct the CLF reward is stated without reported analysis of model mismatch, reference feasibility under uncertainty, or failure cases where the reference leads the teacher into unsafe states. A quantitative assessment of reference quality (e.g., tracking error or safety violation rate) is required to substantiate the three-step pipeline.
minor comments (1)
- [Abstract] The abstract mentions 'lateral constraints' on the footholds but does not define how these constraints are encoded in either the simplified model or the CLF reward; this notation should be clarified in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to provide the requested quantitative support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'improving sample efficiency,' 'reducing the need for a complex learning curriculum,' and 'achieving smoother locomotion behavior' are asserted without any numerical metrics, training curves, ablation results, or statistical comparisons. These assertions are load-bearing for the paper's contribution and must be supported by concrete data (e.g., sample counts to reach a success threshold, curriculum stage counts, or smoothness metrics such as jerk or torque variance) in the results section.
Authors: The results section includes training curves and comparisons that support these claims, but we agree that the abstract lacks specific numbers. We will update the abstract to include concrete metrics from our experiments, such as the number of environment steps to reach a success threshold and smoothness metrics like torque variance, along with statistical comparisons to baselines. revision: yes
-
Referee: [Abstract, §3] Abstract and §3 (method): the claim that simplified-model references remain 'safe and useful' when used to construct the CLF reward is stated without reported analysis of model mismatch, reference feasibility under uncertainty, or failure cases where the reference leads the teacher into unsafe states. A quantitative assessment of reference quality (e.g., tracking error or safety violation rate) is required to substantiate the three-step pipeline.
Authors: We acknowledge that a detailed quantitative assessment of the reference quality is not present in the current manuscript. We will add this analysis, reporting tracking errors, feasibility under uncertainty, and safety violation rates, to support the safety and usefulness of the simplified-model references in the CLF reward construction. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description outline a standard three-step teacher-student distillation pipeline (simplified-model reference generation, privileged teacher training with CLF reward, vision-student distillation) without any equations, fitted parameters, or self-citations that reduce claimed performance metrics or derivations to their own inputs by construction. No load-bearing step equates a prediction to a fitted input or imports uniqueness via self-citation chains. The central claims rest on empirical validation in simulation and hardware rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nguyen, A
Q. Nguyen, A. Hereid, J. W. Grizzle, A. D. Ames, and K. Sreenath. 3d dynamic walking on stepping stones with control barrier functions. In2016 IEEE 55th Conference on Decision and Control (CDC), pages 827–834. IEEE, 2016
2016
-
[2]
Csomay-Shanklin, R
N. Csomay-Shanklin, R. K. Cosner, M. Dai, A. J. Taylor, and A. D. Ames. Episodic learning for safe bipedal locomotion with control barrier functions and projection-to-state safety. In Proceedings of the 3rd Conference on Learning for Dynamics and Control, volume 144 of Proceedings of Machine Learning Research, pages 1041–1053. PMLR, 07 – 08 June 2021. URL...
2021
-
[3]
Grandia, A
R. Grandia, A. J. Taylor, A. D. Ames, and M. Hutter. Multi-layered safety for legged robots via control barrier functions and model predictive control. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 8352–8358. IEEE, 2021
2021
-
[4]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust per- ceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62), 2022
2022
-
[5]
Q. Ben, B. Xu, K. Li, F. Jia, W. Zhang, J. Wang, J. Wang, D. Lin, and J. Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains, 2025. URLhttps://arxiv.org/abs/2511.14625
arXiv 2025
- [6]
-
[7]
K. Li, Z. Olkin, Y . Yue, and A. D. Ames. Clf-rl: Control lyapunov function guided rein- forcement learning.IEEE Robotics and Automation Letters, 11(3):3230–3237, 2026. doi: 10.1109/LRA.2026.3653329
-
[8]
M. Dai, W. D. Compton, J. Li, L. Yang, and A. D. Ames. Walk the planc: Physics-guided rl for agile humanoid locomotion on constrained footholds.arXiv preprint arXiv:2601.06286, 2026
arXiv 2026
-
[9]
C. M. Bishop. Mixture density networks. Copyright © 1994, Christopher M. Bishop. This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (https://creativecommons.org/licenses/by-nc-nd/4.0/)., 1994. URL https://publications.aston.ac.uk/id/eprint/373/
1994
-
[10]
Q. Nguyen and K. Sreenath. Safety-critical control for dynamical bipedal walking with precise footstep placement.IF AC-PapersOnLine, 48(27):147–154, 2015. ISSN 2405-8963. doi:https: //doi.org/10.1016/j.ifacol.2015.11.167. Analysis and Design of Hybrid Systems ADHS
-
[11]
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada. Control barrier functions: theory and applications. In2019 18th European Control Conference (ECC), pages 3420–3431, 2019. doi:10.23919/ECC.2019.8796030
-
[12]
Grandia, F
R. Grandia, F. Jenelten, S. Yang, F. Farshidian, and M. Hutter. Perceptive locomotion through nonlinear model-predictive control.IEEE Transactions on Robotics, 39(5):3402–3421, 2023
2023
-
[13]
Zhuang, S
Z. Zhuang, S. Yao, and H. Zhao. Humanoid parkour learning. In P. Agrawal, O. Kroemer, and W. Burgard, editors,Proceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 1975–1991. PMLR, 06–09 Nov 2025. URLhttps://proceedings.mlr.press/v270/zhuang25a.html
1975
-
[14]
Cheng, K
X. Cheng, K. Shi, A. Agarwal, and D. Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450,
-
[15]
doi:10.1109/ICRA57147.2024.10610200
-
[16]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. InConference on robot learning, pages 403–415. PMLR, 2023
2023
-
[17]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal locomo- tion over challenging terrain.Science Robotics, 5(47), 2020
2020
-
[18]
H. Duan, A. Malik, J. Dao, A. Saxena, K. Green, J. Siekmann, A. Fern, and J. Hurst. Sim-to- real learning of footstep-constrained bipedal dynamic walking. In2022 International Confer- ence on Robotics and Automation (ICRA), pages 10428–10434. IEEE, 2022
2022
-
[19]
J. Sun, G. Han, P. Sun, W. Zhao, J. Cao, J. Wang, Y . Guo, and Q. Zhang. Dpl: Depth- only perceptive humanoid locomotion via realistic depth synthesis and cross-attention terrain reconstruction, 2025. URLhttps://arxiv.org/abs/2510.07152
arXiv 2025
-
[20]
W. Sun, B. Cao, L. Chen, Y . Su, Y . Liu, Z. Xie, and H. Liu. Learning perceptive humanoid locomotion over challenging terrain. In2025 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 6571–6578, 2025. doi:10.1109/IROS60139.2025. 11247685
-
[21]
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao. Hiking in the wild: A scalable perceptive parkour framework for humanoids, 2026. URLhttps://arxiv.org/abs/2601.07718
arXiv 2026
-
[22]
Artstein
Z. Artstein. Stabilization with relaxed controls.Nonlinear Analysis: Theory, Methods & Applications, 7(11):1163–1173, 1983
1983
- [23]
-
[24]
Janwani, V
N. Janwani, V . Madabushi, and M. Tucker. Navigait: Navigating dynamically feasible gait libraries using deep reinforcement learning, 2026. URLhttps://arxiv.org/abs/2510. 11542
2026
-
[25]
X. Xiong and A. Ames. 3-d underactuated bipedal walking via h-lip based gait synthesis and stepping stabilization.IEEE Transactions on Robotics, 38(4):2405–2425, 2022. doi: 10.1109/TRO.2022.3150219
-
[26]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[27]
K. J. ˚Astr¨om and R. Murray.Feedback systems: An introduction for scientists and engineers. Princeton University Press, 2021
2021
-
[28]
A. D. Ames, K. Galloway, K. Sreenath, and J. W. Grizzle. Rapidly exponentially stabiliz- ing control lyapunov functions and hybrid zero dynamics.IEEE Transactions on Automatic Control, 59(4):876–891, 2014
2014
-
[29]
E. D. Sontag and Y . Wang. On characterizations of the input-to-state stability property.Systems & Control Letters, 24(5):351–359, 1995
1995
-
[30]
Zakka, Q
K. Zakka, Q. Liao, B. Yi, L. L. Lay, K. Sreenath, and P. Abbeel. mjlab: A lightweight framework for gpu-accelerated robot learning, 2026. URLhttps://arxiv.org/abs/2601. 22074
2026
-
[31]
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026– 5033, 2012. doi:10.1109/IROS.2012.6386109
-
[32]
C. Schwarke, M. Mittal, N. Rudin, D. Hoeller, and M. Hutter. Rsl-rl: A learning library for robotics research, 2025. URLhttps://arxiv.org/abs/2509.10771. 9 Appendix 9.1 Artificial Intelligence Acknowledgement The authors acknowledge the use of artificial intelligence (AI) technologies in the preparation of this paper. Specifically, large language models w...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.