The Confident Liar: Diagnosing Multi-Agent Debate with Log-Probabilities and LLM-as-Judge
Pith reviewed 2026-06-27 13:39 UTC · model grok-4.3
The pith
In multi-agent debate, a Constructor's token-level confidence predicts externally judged reasoning quality twice as strongly as an Auditor's.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
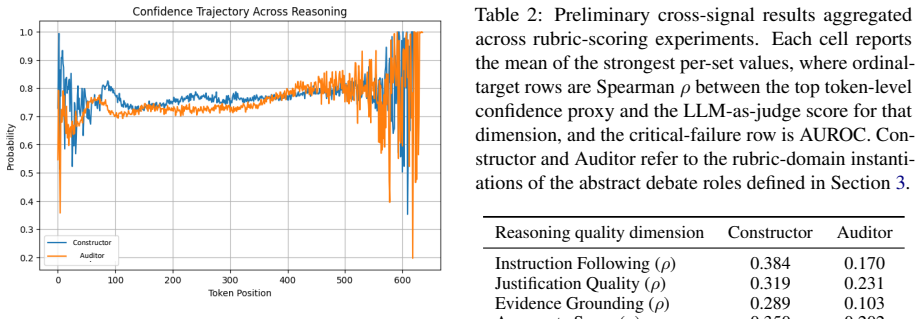
Across three domains the work measures how token-level log-probability distributions over reasoning tokens relate to LLM-as-judge scores on instruction following, justification quality, evidence grounding, and a critical-failure flag. In the rubric-scoring domain the data show a four-phase confidence trajectory together with a substantial role asymmetry: confidence correlates with judged reasoning quality roughly twice as strongly for the Constructor as for the Auditor, and confidence-based detection of critical reasoning failures reaches AUROC 0.804 for the Constructor versus 0.634 for the Auditor.
What carries the argument
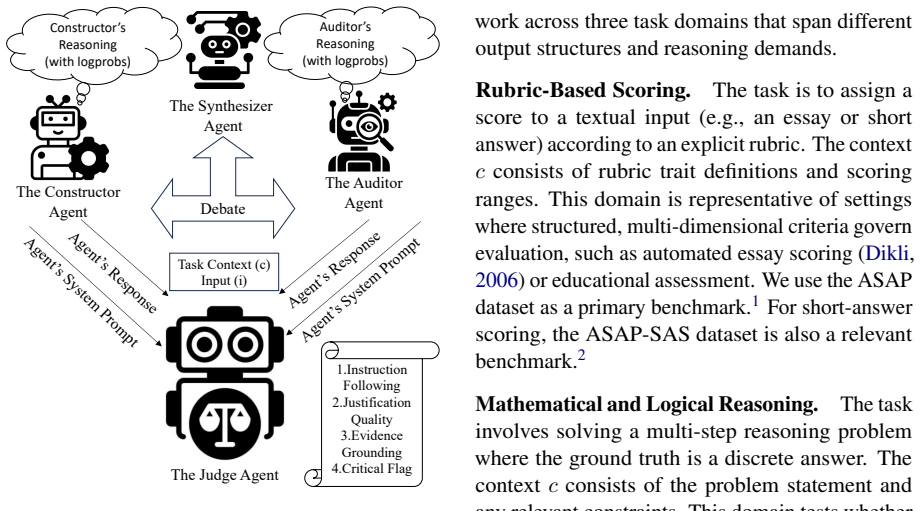
Two-agent debate architecture pairing a Constructor that generates answers with an Auditor that critiques them, scored by an LLM-as-judge rubric on instruction following, justification quality, evidence grounding, and critical-failure flag, compared against token-level log-probabilities.
If this is right
- Confidence can serve as a more trustworthy detector of flawed reasoning steps when emitted by the Constructor role.
- Different monitoring or weighting rules may be needed for each agent because their confidence-quality alignment differs markedly.
- The observed four-phase confidence trajectory supplies a potential diagnostic signature that future debate runs can check against.
- Internal confidence and external judge scores may align with final task accuracy in role-specific ways that current end-to-end metrics overlook.
Where Pith is reading between the lines
- If the asymmetry persists, debate pipelines could route final answers through the higher-confidence Constructor output when the Auditor's signal is weak.
- Extending the same log-probability versus rubric comparison to the mathematical-reasoning and factual-QA domains could reveal whether the four-phase pattern and role gap are domain-general.
- Systems might add a lightweight confidence filter that pauses or restarts debate rounds when the Constructor's signal drops below a threshold tied to the observed AUROC.
Load-bearing premise
The LLM-as-judge rubric scores supply an independent and valid external yardstick for reasoning quality that can be compared directly to the model's own token log-probabilities.
What would settle it
Re-running the rubric-scoring experiments and finding that the correlation between Constructor log-probabilities and judge scores is not reliably larger than the Auditor correlation, or that the AUROC gap for critical-failure detection shrinks below statistical significance.
Figures





read the original abstract
Multi-agent debate systems are typically evaluated only on whether the final answer is correct, overlooking the quality of the intermediate reasoning that debate is designed to produce. This paper studies the relationship between three signals in multi-agent debate: token-level log-probability distributions over reasoning tokens, LLM-as-judge rubric scores assigned to those tokens, and final task accuracy. We examine whether internal confidence signals predict externally evaluated reasoning quality, and whether either signal aligns with task correctness, across three domains: rubric-based scoring, mathematical reasoning, and factual question answering. Our framework pairs a two-agent debate architecture -- a Constructor and an Auditor -- with an LLM-as-judge that scores each agent's reasoning along instruction following, justification quality, and evidence grounding, together with a critical-failure flag. Experiments in the rubric-scoring domain reveal a consistent four-phase confidence trajectory and a substantial role asymmetry: confidence aligns with judged reasoning quality roughly twice as strongly for the Constructor as for the Auditor, and confidence-based detection of critical reasoning failures is markedly more reliable for the Constructor (AUROC 0.804) than for the Auditor (0.634). These findings motivate the broader cross-domain investigation proposed in this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the relationship between token-level log-probability distributions over reasoning tokens, LLM-as-judge rubric scores (instruction following, justification quality, evidence grounding, critical-failure flag), and final task accuracy in a two-agent debate setup (Constructor and Auditor). It reports a consistent four-phase confidence trajectory in the rubric-scoring domain along with a role asymmetry: log-prob confidence aligns roughly twice as strongly with judged reasoning quality for the Constructor, and confidence-based detection of critical reasoning failures yields AUROC 0.804 for the Constructor versus 0.634 for the Auditor. The work motivates extending the analysis to mathematical reasoning and factual QA domains.
Significance. If the LLM-as-judge rubric scores prove to be a valid independent measure of reasoning quality, the reported asymmetries and four-phase pattern would provide a concrete diagnostic tool for intermediate reasoning in multi-agent debate that goes beyond final-answer accuracy. The explicit pairing of internal confidence signals with external rubric evaluation and the cross-role comparison constitute a clear, falsifiable contribution that could inform the design of more reliable debate protocols.
major comments (2)
- [Abstract] Abstract: The reported AUROC values (0.804 vs 0.634) and four-phase trajectory are presented as concrete experimental findings, yet the abstract supplies no description of the models, datasets, prompt templates, statistical tests, or controls used to obtain them. Without these details it is impossible to determine whether the asymmetry is robust or an artifact of post-hoc analysis choices.
- [Abstract] Abstract (and implied experimental sections): The central claim that confidence-based detection is markedly more reliable for the Constructor rests on the LLM-as-judge rubric scores constituting an independent external measure of reasoning quality. No human inter-annotator agreement, correlation with downstream task accuracy beyond the final answer, or ablation against surface features already captured by log-probs is mentioned, leaving the 2× alignment difference and AUROC gap vulnerable to judge bias.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the manuscript to improve transparency while acknowledging the scope of our current validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported AUROC values (0.804 vs 0.634) and four-phase trajectory are presented as concrete experimental findings, yet the abstract supplies no description of the models, datasets, prompt templates, statistical tests, or controls used to obtain them. Without these details it is impossible to determine whether the asymmetry is robust or an artifact of post-hoc analysis choices.
Authors: We agree that the abstract should supply sufficient experimental context. The revised abstract now includes a concise description of the models used for debate and judging, the rubric-scoring domain in which the four-phase trajectory and AUROC results were obtained, the cross-domain motivation, and the statistical measures (AUROC for critical-failure detection). These additions allow readers to assess the reported asymmetry without immediate reference to the full text. revision: yes
-
Referee: [Abstract] Abstract (and implied experimental sections): The central claim that confidence-based detection is markedly more reliable for the Constructor rests on the LLM-as-judge rubric scores constituting an independent external measure of reasoning quality. No human inter-annotator agreement, correlation with downstream task accuracy beyond the final answer, or ablation against surface features already captured by log-probs is mentioned, leaving the 2× alignment difference and AUROC gap vulnerable to judge bias.
Authors: We acknowledge this limitation. The LLM-as-judge serves as a proxy measure in the present work. In revision we have (1) added explicit reporting of correlations between rubric scores and final task accuracy, (2) inserted a limitations subsection that notes the absence of human inter-annotator agreement and the potential for judge bias, and (3) discussed why the observed role asymmetry is unlikely to arise solely from surface features captured by log-probabilities, given its consistency across domains. A full human validation study and surface-feature ablation lie outside the current scope but are noted as future work. revision: partial
Circularity Check
No circularity: purely observational experimental comparisons
full rationale
The paper reports direct experimental measurements of three signals (token log-probabilities, LLM-as-judge rubric scores on four dimensions, and final accuracy) across debate roles without any equations, parameter fitting presented as prediction, self-definitional constructs, or load-bearing self-citations. The four-phase trajectory and Constructor/Auditor asymmetries are stated as observed patterns from the data, not quantities derived from or equivalent to the inputs by construction. The LLM-as-judge rubric is used as an external proxy but is not internally defined in terms of the log-probabilities being compared, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-as-judge rubric scores constitute a reliable external ground truth for reasoning quality independent of the model's own log-probabilities.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2026 , eprint=
LLM Multi-Agent Systems: Challenges and Open Problems , author=. 2026 , eprint=
2026
-
[9]
2025 , eprint=
PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving , author=. 2025 , eprint=
2025
-
[10]
2023 , eprint=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. 2023 , eprint=
2023
-
[11]
2023 , eprint=
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. 2023 , eprint=
2023
-
[12]
Astronomy and Computing , keywords =
Scott A. Crossley and Perpetual Baffour and L. Burleigh and Jules King , keywords =. A large-scale corpus for assessing source-based writing quality: ASAP 2.0 , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.asw.2025.100954 , url =
-
[13]
The Journal of Technology, Learning and Assessment , author=
An Overview of Automated Scoring of Essays , volume=. The Journal of Technology, Learning and Assessment , author=. 2006 , month=
2006
-
[14]
Austin Pack and Alex Barrett and Juan Escalante , keywords =. Large language models and automated essay scoring of English language learner writing: Insights into validity and reliability , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.caeai.2024.100234 , url =
-
[15]
doi:10.5281/zenodo.17196206 , url =
Keramati, Ali and Warschauer, Mark , title =. doi:10.5281/zenodo.17196206 , url =
-
[16]
2025 , eprint=
Talk Isn't Always Cheap: Understanding Failure Modes in Multi-Agent Debate , author=. 2025 , eprint=
2025
-
[17]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[18]
2025 , eprint=
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
Self-Evaluating LLMs for Multi-Step Tasks: Stepwise Confidence Estimation for Failure Detection , author=. 2025 , eprint=
2025
-
[20]
2nd AI for Math Workshop @ ICML 2025 , year=
Scalable Best-of-N Selection for Large Language Models via Self-Certainty , author=. 2nd AI for Math Workshop @ ICML 2025 , year=
2025
-
[21]
Can Large Language Models Be an Alternative to Human Evaluations?
Chiang, Cheng-Han and Lee, Hung-yi. Can Large Language Models Be an Alternative to Human Evaluations?. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.870
-
[22]
2025 , eprint=
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2025 , eprint=
2025
-
[23]
Automating Theory of Mind Assessment with a LLaMA-3-Powered Chatbot: Enhancing Faux Pas Detection in Autism , year=
Fallah, Avisa and Keramati, Ali and Nazari, Mohammad Ali and Mirfazeli, Fatemeh Sadat , booktitle=. Automating Theory of Mind Assessment with a LLaMA-3-Powered Chatbot: Enhancing Faux Pas Detection in Autism , year=
-
[24]
GPTS core: Evaluate as You Desire
Fu, Jinlan and Ng, See-Kiong and Jiang, Zhengbao and Liu, Pengfei. GPTS core: Evaluate as You Desire. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.365
-
[25]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[26]
2024 , eprint=
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets , author=. 2024 , eprint=
2024
-
[27]
Large Language Models are not Fair Evaluators
Wang, Peiyi and Li, Lei and Chen, Liang and Cai, Zefan and Zhu, Dawei and Lin, Binghuai and Cao, Yunbo and Kong, Lingpeng and Liu, Qi and Liu, Tianyu and Sui, Zhifang. Large Language Models are not Fair Evaluators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.ac...
-
[28]
2024 , eprint=
Evaluating Large Language Models at Evaluating Instruction Following , author=. 2024 , eprint=
2024
-
[29]
2023 , eprint=
CoAScore: Chain-of-Aspects Prompting for NLG Evaluation , author=. 2023 , eprint=
2023
-
[30]
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation
Saha, Swarnadeep and Levy, Omer and Celikyilmaz, Asli and Bansal, Mohit and Weston, Jason and Li, Xian. Branch-Solve-Merge Improves Large Language Model Evaluation and Generation. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi...
-
[31]
2024 , eprint=
PRD: Peer Rank and Discussion Improve Large Language Model based Evaluations , author=. 2024 , eprint=
2024
-
[32]
2023 , eprint=
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate , author=. 2023 , eprint=
2023
-
[33]
PRePair: Pointwise Reasoning Enhance Pairwise Evaluating for Robust Instruction-Following Assessments , doi =
Jeong, Hawon and Park, Chaehun and Hong, Jimin and Choo, Jaegul , year =. PRePair: Pointwise Reasoning Enhance Pairwise Evaluating for Robust Instruction-Following Assessments , doi =
-
[34]
R e IFE : Re-evaluating Instruction-Following Evaluation
Liu, Yixin and Shi, Kejian and Fabbri, Alexander and Zhao, Yilun and Wang, PeiFeng and Wu, Chien-Sheng and Joty, Shafiq and Cohan, Arman. R e IFE : Re-evaluating Instruction-Following Evaluation. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
-
[35]
Huang, Hui and Bu, Xingyuan and Zhou, Hongli and Qu, Yingqi and Liu, Jing and Yang, Muyun and Xu, Bing and Zhao, Tiejun. An Empirical Study of LLM -as-a-Judge for LLM Evaluation: Fine-tuned Judge Model is not a General Substitute for GPT -4. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.306
-
[36]
Calibration of pre-trained transformers
Desai, Shrey and Durrett, Greg. Calibration of Pre-trained Transformers. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.21
-
[37]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[38]
2024 , eprint=
Detecting Hallucinations in Large Language Model Generation: A Token Probability Approach , author=. 2024 , eprint=
2024
-
[39]
A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation
Liu, Tianyu and Zhang, Yizhe and Brockett, Chris and Mao, Yi and Sui, Zhifang and Chen, Weizhu and Dolan, Bill. A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.464
-
[40]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Manakul, Potsawee and Liusie, Adian and Gales, Mark. S elf C heck GPT : Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.557
-
[41]
doi: 10.18653/v1/2023.acl-long.546
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.