Envision4D: Envisioning Visual Futures via Feed-forward 4D Gaussian Splatting for Autonomous Driving
Pith reviewed 2026-06-27 13:46 UTC · model grok-4.3
The pith
Envision4D infers future camera poses through iterative denoising to enable accurate feed-forward extrapolation of dynamic driving scenes without pose supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
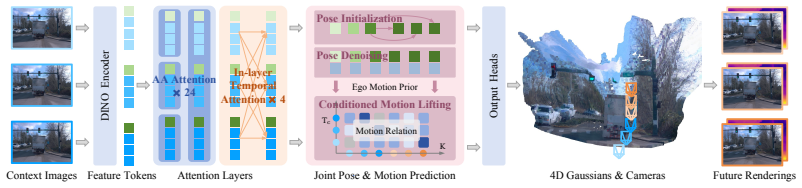
Envision4D is a fully self-supervised feed-forward framework for pose-free future extrapolation that introduces a Future Pose Prediction module to infer future camera parameters via iterative denoising, employs In-layer Temporal Attention and Conditioned Motion Lifting to handle non-linear dynamics as relational mappings, and applies a Progressive Training Strategy to prevent error accumulation during unsupervised motion learning.
What carries the argument
Future Pose Prediction module that infers future camera parameters via an iterative denoising process, combined with In-layer Temporal Attention and Conditioned Motion Lifting inside a 4D Gaussian Splatting backbone.
If this is right
- Future view synthesis improves under large camera displacements compared with interpolation-based methods.
- The framework operates without any future pose supervision or explicit motion priors.
- Non-linear scene dynamics are captured through relational mappings rather than simplified assumptions.
- Progressive training reduces error buildup during unsupervised learning of motion.
- State-of-the-art results are reported on standard future view synthesis benchmarks for autonomous driving.
Where Pith is reading between the lines
- The same denoising-based pose prediction could be tested on non-driving dynamic scenes such as pedestrian crowds or indoor robot navigation.
- Replacing the 4D Gaussian representation with other 3D scene encodings might reveal whether the gains come mainly from the pose module or the full pipeline.
- If the method scales to longer time horizons, it could supply predicted scene states directly to downstream motion planners without separate trajectory forecasting.
- The progressive training schedule may generalize to other self-supervised extrapolation tasks where error accumulation is the main failure mode.
Load-bearing premise
The iterative denoising process can reliably recover accurate future camera poses from past observations alone, even with large displacements and no future pose labels or strong motion priors.
What would settle it
Run the model on a held-out driving sequence containing camera displacements twice as large as any seen during training and measure whether the predicted future poses produce view synthesis errors that exceed those of a simple linear extrapolation baseline.
Figures


read the original abstract
Forecasting the future evolution of dynamic scenes is crucial in autonomous driving. However, existing feed-forward paradigms are primarily designed for interpolation. When extended to future extrapolation, they suffer from ghosting artifacts under large displacements and are constrained by simplified motion assumptions or strict future priors. To overcome these challenges, we propose Envision4D, a fully self-supervised feed-forward framework for pose-free future extrapolation. Specifically, we introduce a Future Pose Prediction module that infers future camera parameters via an iterative denoising process. Furthermore, to capture non-linear dynamics, we propose In-layer Temporal Attention and employ Conditioned Motion Lifting, which transforms the highly uncertain extrapolation process into robust relational mappings. Finally, a Progressive Training Strategy is utilized to stabilize unsupervised motion learning against error accumulation. Extensive experiments demonstrate that Envision4D achieves state-of-the-art performance, significantly outperforming existing methods in future view synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
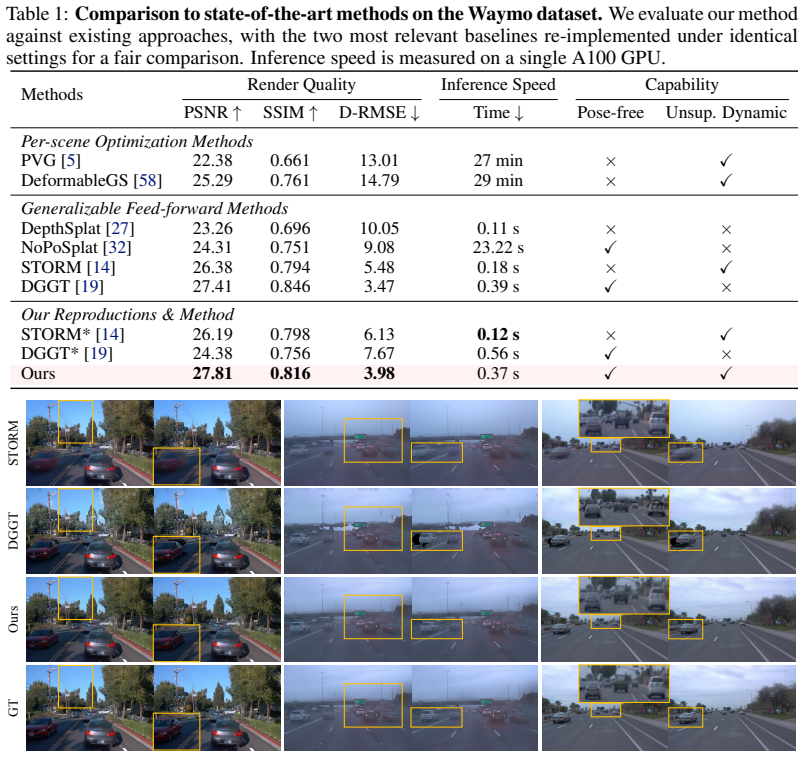
Summary. The paper proposes Envision4D, a fully self-supervised feed-forward framework for pose-free future extrapolation in dynamic driving scenes using 4D Gaussian Splatting. Key components include a Future Pose Prediction module that infers future camera parameters via iterative denoising (without future-pose supervision), In-layer Temporal Attention and Conditioned Motion Lifting to handle non-linear dynamics, and a Progressive Training Strategy to mitigate error accumulation. The central claim is that these enable reliable future view synthesis under large displacements, achieving state-of-the-art performance over existing methods.
Significance. If the core claims hold, the work would be significant for autonomous driving applications by providing a feed-forward approach to future scene synthesis that avoids simplified motion assumptions and strong priors. The self-supervised design and focus on extrapolation (rather than interpolation) address practical gaps in current 4D reconstruction methods. However, the absence of direct validation for the unsupervised pose module limits assessment of whether gains stem from the proposed components or other factors.
major comments (1)
- [§3.2] §3.2: The Future Pose Prediction module is presented as the key enabler for unsupervised future camera parameter inference via iterative denoising, yet only downstream view-synthesis metrics are reported. No table, figure, or ablation quantifies pose accuracy (e.g., translation/rotation error vs. held-out future ground truth) or demonstrates robustness under large displacements typical in driving scenes. This is load-bearing for the SOTA claim, as improvements could arise from In-layer Temporal Attention, Conditioned Motion Lifting, or training artifacts rather than reliable pose extrapolation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will revise the paper accordingly to provide direct validation of the Future Pose Prediction module.
read point-by-point responses
-
Referee: [§3.2] §3.2: The Future Pose Prediction module is presented as the key enabler for unsupervised future camera parameter inference via iterative denoising, yet only downstream view-synthesis metrics are reported. No table, figure, or ablation quantifies pose accuracy (e.g., translation/rotation error vs. held-out future ground truth) or demonstrates robustness under large displacements typical in driving scenes. This is load-bearing for the SOTA claim, as improvements could arise from In-layer Temporal Attention, Conditioned Motion Lifting, or training artifacts rather than reliable pose extrapolation.
Authors: We agree that quantifying the accuracy of the predicted future poses would strengthen the claims regarding the module's contribution. Although the framework is trained without future-pose supervision and the primary evaluation metric is view synthesis quality, the datasets used (e.g., nuScenes) contain ground-truth future camera parameters that can be used for post-hoc evaluation. In the revised manuscript, we will add a dedicated ablation table reporting translation and rotation errors of the predicted poses versus held-out ground truth, stratified by displacement magnitude. We will also include qualitative trajectory visualizations and an ablation isolating the pose module's impact. These additions will confirm that the SOTA gains stem from reliable unsupervised pose extrapolation rather than other components. revision: yes
Circularity Check
No circularity; new architecture with independent components
full rationale
The paper describes a feed-forward framework with explicitly introduced modules (Future Pose Prediction via iterative denoising, In-layer Temporal Attention, Conditioned Motion Lifting, Progressive Training Strategy) for self-supervised future extrapolation. No equations, claims, or steps in the provided text reduce outputs to inputs by construction, rename fitted parameters as predictions, or rely on load-bearing self-citations. Performance is asserted via experiments rather than definitional equivalence, satisfying the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Yan, Z. Xu, H. Lin, H. Jin, H. Guo, Y . Wang, K. Zhan, X. Lang, H. Bao, X. Zhou, et al. Streetcrafter: Street view synthesis with controllable video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 822–832, 2025
2025
-
[2]
Q. Song, Q. Hu, C. Zhang, Y . Chen, and R. Huang. Divide and conquer: Improving multi- camera 3d perception with 2d semantic-depth priors and input-dependent queries.IEEE Trans- actions on Image Processing, 33:897–909, 2024
2024
-
[3]
Y . Yan, H. Lin, C. Zhou, W. Wang, H. Sun, K. Zhan, X. Lang, X. Zhou, and S. Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173. Springer, 2024
2024
-
[4]
Z. Chen, J. Yang, J. Huang, R. De Lutio, J. M. Esturo, B. Ivanovic, O. Litany, Z. Goj- cic, S. Fidler, M. Pavone, et al. Omnire: Omni urban scene reconstruction.arXiv preprint arXiv:2408.16760, 2024
arXiv 2024
-
[5]
Y . Chen, C. Gu, J. Jiang, X. Zhu, and L. Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering.International Journal of Computer Vision, 134 (3):83, 2026
2026
-
[6]
S. Wang, Z. Yu, X. Jiang, S. Lan, M. Shi, N. Chang, J. Kautz, Y . Li, and J. M. Alvarez. Om- nidrive: A holistic llm-agent framework for autonomous driving with 3d perception, reasoning and planning.arXiv preprint arXiv:2405.01533, 1(2):3, 2024
arXiv 2024
-
[7]
H. Fu, D. Zhang, Z. Zhao, J. Cui, D. Liang, C. Zhang, D. Zhang, H. Xie, B. Wang, and X. Bai. Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24823–24834, 2025
2025
-
[8]
X. Zhou, X. Han, F. Yang, Y . Ma, V . Tresp, and A. Knoll. Opendrivevla: Towards end-to- end autonomous driving with large vision language action model. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 13782–13790, 2026
2026
-
[9]
J. Hur, C. Herrmann, S. Peng, P. Henzler, Z. Ma, T. Zickler, and D. Sun. Ufo-4d: Unposed feedforward 4d reconstruction from two images.arXiv preprint arXiv:2602.24290, 2026
arXiv 2026
- [10]
-
[11]
Y . Hu, C. Cheng, S. Yu, X. Guo, and H. Wang. Vggt4d: Mining motion cues in visual geometry transformers for 4d scene reconstruction.arXiv preprint arXiv:2511.19971, 2025
arXiv 2025
-
[12]
Z. He, J. Li, G. Li, X. Chen, J. Tang, S. Zhang, Z. Jin, F. Cai, B. Li, J. Pu, et al. Dynam- icvggt: Learning dynamic point maps for 4d scene reconstruction in autonomous driving.arXiv preprint arXiv:2603.08254, 2026
arXiv 2026
-
[13]
Y . Yang, L. Fan, Z. Shi, J. Peng, F. Wang, and Z. Zhang. Neoverse: Enhancing 4d world model with in-the-wild monocular videos.arXiv preprint arXiv:2601.00393, 2026
arXiv 2026
-
[14]
J. Yang, J. Huang, Y . Chen, Y . Wang, B. Li, Y . You, A. Sharma, M. Igl, P. Karkus, D. Xu, et al. Storm: Spatio-temporal reconstruction model for large-scale outdoor scenes.arXiv preprint arXiv:2501.00602, 2024
arXiv 2024
-
[15]
J. Wang, H. Che, Y . Chen, Z. Yang, L. Goli, S. Manivasagam, and R. Urtasun. Flux4d: Flow- based unsupervised 4d reconstruction.arXiv preprint arXiv:2512.03210, 2025
Pith/arXiv arXiv 2025
-
[16]
C. Lin, Y . Lin, P. Pan, Y . Yu, T. Hu, H. Yan, K. Fragkiadaki, and Y . Mu. Movies: Motion-aware 4d dynamic view synthesis in one second.arXiv preprint arXiv:2507.10065, 2025. 9
arXiv 2025
-
[17]
X. Fei, W. Zheng, Y . Duan, W. Zhan, M. Tomizuka, K. Keutzer, and J. Lu. Driv3r: Learning dense 4d reconstruction for autonomous driving.arXiv preprint arXiv:2412.06777, 2024
arXiv 2024
-
[18]
S. Miao, S. Li, P. Wang, D. Bai, B. Liu, Y . Wang, A. Geiger, and Y . Liao. Evolsplat4d: Efficient volume-based gaussian splatting for 4d urban scene synthesis.arXiv preprint arXiv:2601.15951, 2026
arXiv 2026
-
[19]
X. Chen, Z. Xiong, Y . Chen, G. Li, N. Wang, H. Luo, L. Chen, H. Sun, B. Wang, G. Chen, et al. Dggt: Feedforward 4d reconstruction of dynamic driving scenes using unposed images. arXiv preprint arXiv:2512.03004, 2025
arXiv 2025
-
[20]
Z. Wu, Q. Yan, X. Yi, L. Wang, and R. Liao. Streamsplat: Towards online dynamic 3d recon- struction from uncalibrated video streams.arXiv preprint arXiv:2506.08862, 2025
arXiv 2025
-
[21]
H. Yu, K. Xiao, J. Wang, R. Hao, Y . Huang, G. Hu, H. Qin, B. Jing, Y . Bo, and P. Luo. Recon- drive: Fast feed-forward 4d gaussian splatting for autonomous driving scene reconstruction. arXiv preprint arXiv:2603.07552, 2026
arXiv 2026
-
[22]
Z. Xu, Z. Li, Z. Dong, X. Zhou, R. Newcombe, and Z. Lv. 4dgt: Learning a 4d gaussian transformer using real-world monocular videos.arXiv preprint arXiv:2506.08015, 2025
arXiv 2025
-
[23]
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai. Mvs- plat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean conference on computer vision, pages 370–386. Springer, 2024
2024
-
[24]
Z. Yu, A. Chen, B. Huang, T. Sattler, and A. Geiger. Mip-splatting: Alias-free 3d gaussian splatting. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 19447–19456, 2024
2024
-
[25]
Szymanowicz, C
S. Szymanowicz, C. Rupprecht, and A. Vedaldi. Splatter image: Ultra-fast single-view 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10208–10217, 2024
2024
-
[26]
Jiang, Y
L. Jiang, Y . Mao, L. Xu, T. Lu, K. Ren, Y . Jin, X. Xu, M. Yu, J. Pang, F. Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
2025
-
[27]
H. Xu, S. Peng, F. Wang, H. Blum, D. Barath, A. Geiger, and M. Pollefeys. Depthsplat: Connecting gaussian splatting and depth. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16453–16463, 2025
2025
-
[28]
G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, W. Liu, Q. Tian, and X. Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20310–20320, 2024
2024
-
[29]
Li, S.-S
D. Li, S.-S. Huang, Z. Lu, X. Duan, and H. Huang. St-4dgs: Spatial-temporally consistent 4d gaussian splatting for efficient dynamic scene rendering. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[30]
Q. Song, C. Li, H. Lin, S. Peng, and R. Huang. Adgaussian: Generalizable gaussian splatting for autonomous driving with multi-modal inputs.arXiv preprint arXiv:2504.00437, 2025
arXiv 2025
-
[31]
H. Li, Y . Gao, C. Wu, D. Zhang, Y . Dai, C. Zhao, H. Feng, E. Ding, J. Wang, and J. Han. Ggrt: Towards pose-free generalizable 3d gaussian splatting in real-time. InEuropean Conference on Computer Vision, pages 325–341. Springer, 2024
2024
-
[32]
B. Ye, S. Liu, H. Xu, X. Li, M. Pollefeys, M.-H. Yang, and S. Peng. No pose, no prob- lem: Surprisingly simple 3d gaussian splats from sparse unposed images.arXiv preprint arXiv:2410.24207, 2024. 10
arXiv 2024
-
[33]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual ge- ometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[34]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[35]
Q. Wang, V . Ye, H. Gao, W. Zeng, J. Austin, Z. Li, and A. Kanazawa. Shape of motion: 4d reconstruction from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9660–9672, 2025
2025
- [36]
-
[37]
A. C. Asiimwe and C. V ondrick. 4d gaussian splatting as a learned dynamical system.arXiv preprint arXiv:2512.19648, 2025
arXiv 2025
- [38]
-
[39]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[40]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
Pith/arXiv arXiv 2022
-
[41]
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. En- glish, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[42]
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang. Visual autoregressive modeling: Scal- able image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
2024
-
[43]
S. Gao, J. Yang, L. Chen, K. Chitta, Y . Qiu, A. Geiger, J. Zhang, and H. Li. Vista: A general- izable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024
2024
-
[44]
T. Wu, S. Yang, R. Po, Y . Xu, Z. Liu, D. Lin, and G. Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
arXiv 2025
-
[45]
Y . Liu, K. Zhang, Y . Li, Z. Yan, C. Gao, R. Chen, Z. Yuan, Y . Huang, H. Sun, J. Gao, et al. Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177, 2024
Pith/arXiv arXiv 2024
-
[46]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[47]
A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
Pith/arXiv arXiv 2025
-
[48]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 11
Pith/arXiv arXiv 2025
- [49]
-
[50]
Y . Dai, F. Jiang, C. Wang, M. Xu, and Y . Qi. Fantasyworld: Geometry-consistent world modeling via unified video and 3d prediction.arXiv preprint arXiv:2509.21657, 2025
arXiv 2025
-
[51]
H. Wu, D. Wu, T. He, J. Guo, Y . Ye, Y . Duan, and J. Bian. Geometry forcing: Mar- rying video diffusion and 3d representation for consistent world modeling.arXiv preprint arXiv:2507.07982, 2025
Pith/arXiv arXiv 2025
-
[52]
F. Baldassarre, M. Szafraniec, B. Terver, V . Khalidov, F. Massa, Y . LeCun, P. Labatut, M. Seitzer, and P. Bojanowski. Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468, 2025
arXiv 2025
-
[53]
Karypidis, I
E. Karypidis, I. Kakogeorgiou, S. Gidaris, and N. Komodakis. Dino-foresight: Looking into the future with dino.Advances in Neural Information Processing Systems, 38:163779–163811, 2026
2026
-
[54]
X. Sun, S. Wang, F. Zhang, L. Liu, C. Jia, Z. Song, Z. Huang, and Y . Luo. Vggt-world: Trans- forming vggt into an autoregressive geometry world model.arXiv preprint arXiv:2603.12655, 2026
arXiv 2026
-
[55]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[56]
Zhang, Z
K. Zhang, Z. Tang, X. Hu, X. Pan, X. Guo, Y . Liu, J. Huang, L. Yuan, Q. Zhang, X.-X. Long, et al. Epona: Autoregressive diffusion world model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27220–27230, 2025
2025
-
[57]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[58]
Z. Yang, X. Gao, W. Zhou, S. Jiao, Y . Zhang, and X. Jin. Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20331–20341, 2024
2024
-
[59]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
2020
-
[60]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[61]
V . Ye, R. Li, J. Kerr, M. Turkulainen, B. Yi, Z. Pan, O. Seiskari, J. Ye, J. Hu, M. Tancik, and A. Kanazawa. gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 2025. 12 A Implementation Details Model Architecture.In our model, each Gaussian primitive is parameterized asG={µ, r, s, c, α}, whereµ∈R 3 denotes the 3D ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.