What Fits (Into Few Tokens) Doesn't Overfit: Compression and Generalization in ML Research Agents
Pith reviewed 2026-06-27 13:23 UTC · model grok-4.3
The pith
Successful machine learning strategies can be reproduced from extremely short prompts or one-bit feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
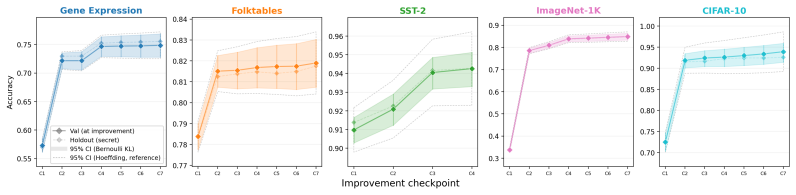
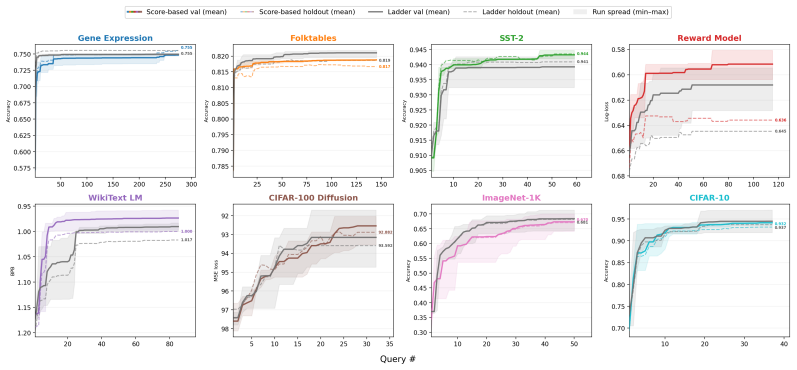
The central claim is that successful ML strategies occupy a low-complexity region of strategy space, which explains the surprising lack of overfitting on reused benchmarks. This is shown by demonstrating that LLM-driven agents can locate and reproduce high-performance models even when the information channel is restricted to either an extremely short output prompt for reproduction or one-bit input feedback during search. The same restrictions cease to work once validation-set overfitting is deliberately induced, providing direct support for a description-length explanation of generalization.
What carries the argument
Two complementary information bottlenecks: output compression, in which a fresh reproducer agent receives only a very short prompt, and input compression, in which the explorer receives only one-bit feedback on improvement.
If this is right
- High-performing models located under short-prompt or one-bit constraints generalize to held-out test data.
- The same severe compression limits suffice across tabular, vision, language, diffusion, and reward-modeling tasks.
- Deliberate validation-set overfitting causes short-prompt reproduction to fail.
- The results supply evidence that good strategies have low description length, which limits overfitting on shared benchmarks.
Where Pith is reading between the lines
- Methods that explicitly favor short descriptions of models or training procedures may improve generalization in other agent-driven search settings.
- The finding raises the possibility that many forms of implicit regularization in deep learning act by enforcing compressibility.
- If compressibility is the operative mechanism, then benchmark reuse may remain safe only so long as the underlying strategy space favors short solutions.
Load-bearing premise
The LLM agents remain capable of effective model search and reproduction when restricted to short prompts or one-bit feedback, without the tests being driven by unmeasured pre-trained knowledge.
What would settle it
If models found after deliberately inducing validation-set overfitting could still be reproduced from short prompts, the compressibility account would be falsified.
Figures

read the original abstract
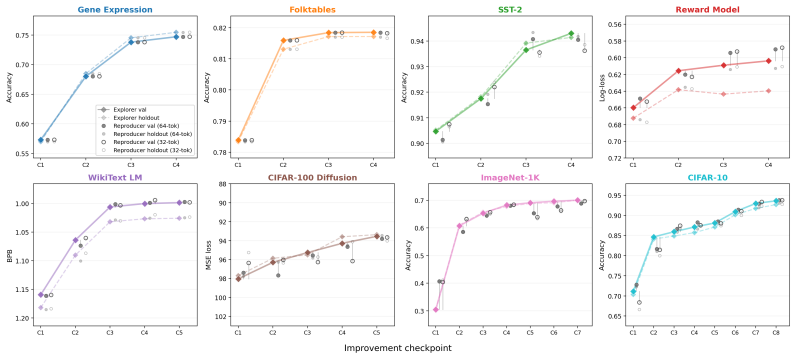
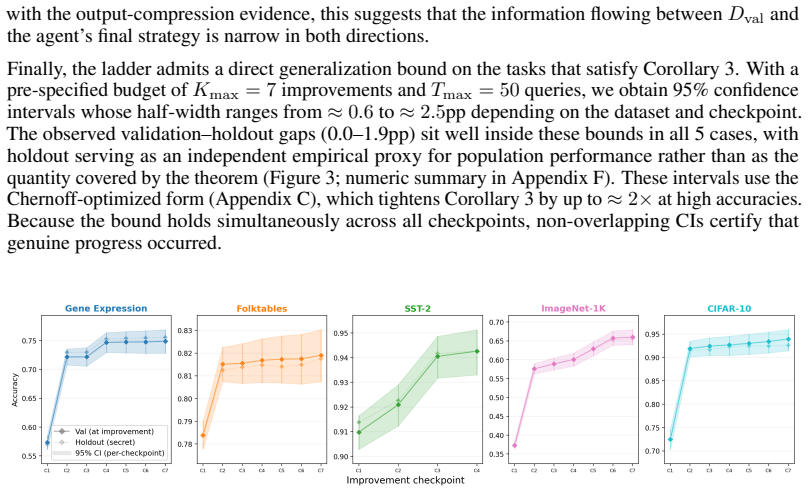
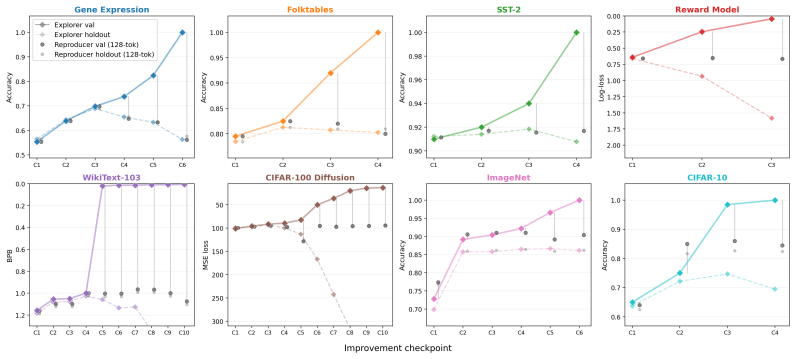
Reusing a held-out benchmark adaptively should, in principle, invite overfitting. Yet benchmark-driven machine learning (ML) has produced surprisingly little overfitting in practice. An attractive hypothesis is that successful ML strategies are highly compressible. We study this in the setting of LLM-driven research agents, where the hypothesis becomes directly testable via two complementary information bottlenecks. In \emph{output compression}, an exploration agent adaptively searches for high-performance models using a validation set, and we test whether a fresh ``reproducer agent'' can reproduce its performance given only an extremely short prompt and the training data. In \emph{input compression}, the explorer receives only one-bit feedback indicating whether each submitted model improves on the running best. Across 8 datasets spanning tabular classification, vision, language modeling, diffusion modeling, and reward modeling, we find that these bottlenecks have little effect on performance: short prompts and compressible feedback are sufficient to reproduce and find high-performance models. The hypothesis is falsifiable: when we deliberately induce validation-set overfitting, the results fail to reproduce with short prompts. Taken together, our results support a description-length explanation for the lack of overfitting in benchmark-driven ML: successful strategies occupy a low-complexity region of strategy space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the lack of overfitting in benchmark-driven ML arises because successful strategies occupy a low-complexity region of strategy space and are thus highly compressible. This is tested empirically in LLM-driven research agents via two information bottlenecks: output compression, where a fresh reproducer agent recovers performance from an extremely short prompt plus training data, and input compression, where an explorer receives only 1-bit feedback on whether each model improves the running best. Experiments across 8 datasets (tabular classification, vision, language modeling, diffusion, reward modeling) show these bottlenecks have little effect on performance. The hypothesis is falsified by deliberately inducing validation-set overfitting, which then fails to reproduce under short prompts.
Significance. If the results hold, the work supplies a direct, falsifiable empirical test of a description-length explanation for generalization in ML, using novel compression bottlenecks in agentic search. The cross-domain consistency and the induced-overfitting control provide a concrete mechanism for why adaptive benchmark reuse rarely produces overfitting, with potential implications for understanding strategy search in both human and automated ML research.
major comments (2)
- [Output compression experiments (likely §4)] The interpretation that short-prompt reproduction demonstrates low strategy complexity (rather than LLM pretraining on common ML heuristics) is load-bearing for the central claim. The induced-overfitting falsification shows failure to reproduce overfit cases but does not rule out that pretraining enables recovery of typical high-performing approaches from terse cues on the non-overfit cases; a control comparing reproduction success for strategies outside the pretraining distribution would be needed to isolate description length.
- [Input compression experiments (likely §5)] The 1-bit feedback results in input compression similarly rest on the assumption that success is due to compressible feedback rather than the agent's internal pre-trained search heuristics. Without an ablation that disables or controls for pretraining effects (e.g., via fine-tuning or non-LLM baselines), the claim that the bottleneck isolates strategy complexity remains at risk.
minor comments (2)
- [Methods] Clarify in the methods how the 'extremely short prompt' is constructed and whether it includes any dataset-specific identifiers that could leak information.
- [Results] Add explicit quantitative tables or figures reporting effect sizes, variance across runs, and statistical comparisons between full-prompt and compressed conditions for each dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on potential pretraining confounds. We address each point below, maintaining that the induced-overfitting control isolates compressibility effects within the LLM agent setting.
read point-by-point responses
-
Referee: [Output compression experiments (likely §4)] The interpretation that short-prompt reproduction demonstrates low strategy complexity (rather than LLM pretraining on common ML heuristics) is load-bearing for the central claim. The induced-overfitting falsification shows failure to reproduce overfit cases but does not rule out that pretraining enables recovery of typical high-performing approaches from terse cues on the non-overfit cases; a control comparing reproduction success for strategies outside the pretraining distribution would be needed to isolate description length.
Authors: We agree pretraining is relevant but argue the induced-overfitting control directly addresses this. Overfit strategies achieve high validation performance yet fail to reproduce from short prompts, while non-overfit high-performers succeed. If pretraining on common heuristics drove reproduction of terse cues, the overfit cases (also high-performing and agent-discovered) should reproduce similarly; their failure indicates short prompts capture low-complexity strategies specifically. An explicit out-of-distribution control would be valuable but is challenging to construct within the LLM agent framework while remaining discoverable; the falsification provides strong evidence for the compressibility claim. revision: no
-
Referee: [Input compression experiments (likely §5)] The 1-bit feedback results in input compression similarly rest on the assumption that success is due to compressible feedback rather than the agent's internal pre-trained search heuristics. Without an ablation that disables or controls for pretraining effects (e.g., via fine-tuning or non-LLM baselines), the claim that the bottleneck isolates strategy complexity remains at risk.
Authors: The 1-bit feedback condition shows high-performance models are discoverable under extreme input compression, with pretraining held fixed across conditions. Success under this bottleneck implies the search targets strategies compatible with low information, aligning with low complexity. The induced-overfitting control extends here: the same 1-bit setup avoids producing non-reproducible overfit models. Non-LLM baselines or fine-tuning ablations would be informative extensions but lie outside testing the hypothesis in the LLM-driven agent setting, where the description-length account is directly falsifiable. revision: no
Circularity Check
Empirical reproduction experiments test compressibility without self-referential derivation
full rationale
The paper advances a description-length hypothesis for lack of overfitting and tests it directly via two information-bottleneck experiments (output compression via short-prompt reproducer agents; input compression via 1-bit feedback) on 8 datasets. Performance is measured empirically; the hypothesis is falsified by deliberately inducing validation overfitting, which then fails to reproduce. No equations, fitted parameters, or self-citations are invoked to derive the central claim from itself. The setup is self-contained against external benchmarks and does not reduce any prediction to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can effectively search model space and reproduce performance when given only short prompts or one-bit feedback
Reference graph
Works this paper leans on
-
[1]
overtuning,
formalize “overtuning,” overfitting at the hyperparameter-optimization level, and report from a large-scale reanalysis that overtuning is common, usually mild, but sometimes severe enough to select 12 configurations with worse generalization than simple defaults or initial configurations. Our stress tests instantiate an agentic version of this concern: wh...
1978
-
[2]
Read the codebase: prepare.py (read-only), train.py (you modify this)
-
[3]
{{EXPLORE_SETUP_STEP}}
-
[4]
Start a clean orphan branch [...]
Prepare your git repo. Start a clean orphan branch [...]
-
[5]
## The task {{EXPLORE_TASK_DESC}} {{VAL_ACCESS_NOTE}} ## The experiment loop 18 LOOP FOREVER:
Establish baseline: Run {{RUN_CMD}}, note the result. ## The task {{EXPLORE_TASK_DESC}} {{VAL_ACCESS_NOTE}} ## The experiment loop 18 LOOP FOREVER:
-
[6]
The ONLY metric is {{METRIC_NAME}}
Think about what to try next. The ONLY metric is {{METRIC_NAME}}
-
[7]
Modify train.py with your changes
-
[8]
Run the experiment: {{RUN_CMD}}
-
[9]
Log the result to results.tsv
-
[10]
Write a detailed reasoning log to iterations/<N>.md
-
[11]
If improved: Keep the commit
-
[12]
If worse or crashed: Revert
-
[13]
Check stop condition
-
[14]
improved / did not improve
Repeat. DO NOT STOP. Important rules: - NEVER STOP EARLY. You must do at least 15 iterations. - Do not pause to ask the human anything. You are autonomous. Validation access modes.We use three validation-access modes. In score_only, the agent submits a trained model or prediction file to evaluate_val, which returns only the scalar metric. In ladder, the s...
-
[15]
Read prepare_reproduce.py to understand what’s available
-
[16]
Import ONLY from prepare_reproduce
Implement the strategy in train.py. Import ONLY from prepare_reproduce
-
[17]
At the end of training, call save_model(model)
-
[18]
Run {{RUN_CMD}} and verify it completes without errors
-
[19]
Do NOT add any adaptive search (seed sweeps, hyperparameter tuning)
-
[20]
Try a range of approaches . . . Let the metric decide which approach works best
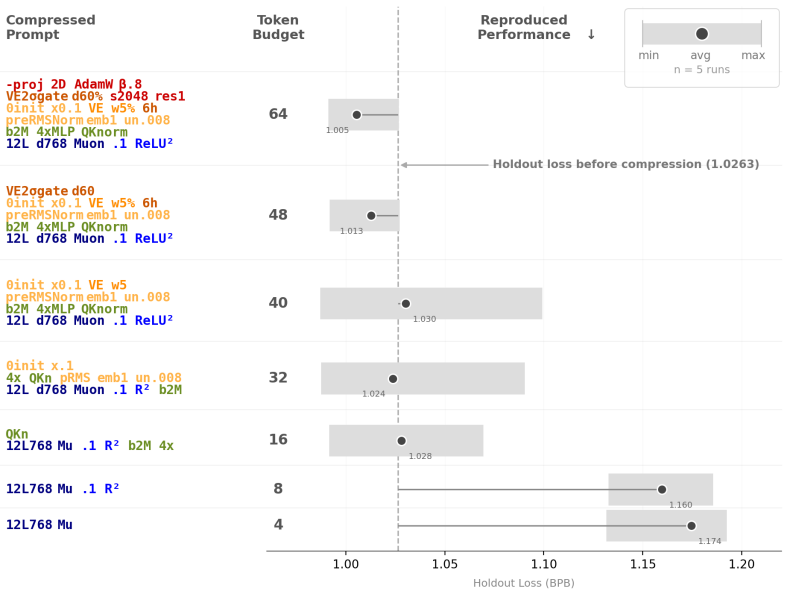
Stop after getting a working result. Do not run more than 3 attempts. The reproducer’s complete input is this rendered template. The {{COMPRESSED_PROMPT}} place- holder is the only channel through which information from the explorer’s interaction withDval can reach the reproducer. After the reproducer exits, the saved model is evaluated externally on both...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.