LatticeBridge: Rare-Event Sequential Inference for Faithful Structured Sequence Synthesis
Pith reviewed 2026-07-05 03:51 UTC · model glm-5.2
The pith
Particle decoder lifts structured text constraint satisfaction from near-zero to 76%
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central object is the twisted SMC bridge: a particle filter over token sequences where each particle carries both a language-model hidden state and an automaton state tracking progress toward containing all required anchor phrases. The proposal distribution at each step combines the base model's next-token distribution with two multiplicative factors — an exponential distance-reduction reward (favoring tokens that move closer to full acceptance) and a source-support score (favoring tokens that begin phrases attested in the input). Particles are resampled when effective sample size drops, and periodically split so that compute is reallocated toward trajectories with lower remaining autom{
What carries the argument
Twisted SMC proposal combining base LM logits with automaton-distance reward and source-support factor; KMP-style surface automata over character-level token emissions; multilevel splitting for rare-acceptance regimes; effective sample size diagnostics; compact GRU prefix language model as shared proposal across all decoders
If this is right
- If the rare-event framing is correct, any autoregressive generation task with conjunctive hard constraints (factuality in summarization, schema compliance in data-to-text, safety filters) could benefit from treating decoding as particle-based inference rather than likelihood maximization.
- The surface automaton representation decouples constraint compilation from the decoder, so new constraint types could be added by writing new automata rather than retraining the model.
- The source-intrusion diagnostic — detecting when a decoder borrows values from other instances — is a generalizable faithfulness metric applicable beyond this paper's benchmarks.
- The separation of proposal model from inference procedure suggests that inference-layer improvements should be measured under a fixed base model, isolating what the decoder contributes versus what the model already knows.
Load-bearing premise
All four decoders share a compact 2-layer GRU with a 384-dimensional hidden state as the base proposal model. The claim that the SMC bridge improves constraint satisfaction is measured relative to this specific weak model. A substantially stronger base model — say, a large transformer — might satisfy anchors more readily under standard decoding, which could narrow or erase the advantage the particle decoder shows here.
What would settle it
Run the same four-decoder comparison with a transformer base model of comparable or larger scale on the same three benchmarks. If greedy or beam decoding already achieves high exact-anchor satisfaction, the SMC advantage would shrink, suggesting the rare-event framing is an artifact of the weak base model rather than a structural property of constrained generation.
Figures
read the original abstract
Structured sequence generation often requires a model to satisfy several input-derived constraints in a single output. Standard decoding methods may assign high probability to fluent continuations while placing low mass on continuations that realize all required anchors jointly. We study this regime as a rare-event sequential inference problem. LatticeBridge combines a compact prefix language model, instance-compiled surface automata, and a twisted sequential Monte Carlo (SMC) decoder with resampling, multilevel splitting, and a source-support proposal term derived from instance-provided phrases. The constraint representation is compiled from each input instance and does not rely on manually curated lexical classes. On 2,610 attainable validation tasks spanning CommonGen, E2E NLG, and WikiBio, the particle decoder improves exact anchor satisfaction and mean anchor coverage over greedy, beam-filtered, and best-of-k ancestral baselines under a shared proposal model. Since exact anchor satisfaction alone does not rule out unsupported attribute substitutions, the evaluation reports required-anchor coverage, source coverage, source-intrusion diagnostics, overlap, runtime, and particle statistics jointly. The benchmark characterizes the faithfulness-overlap-latency frontier under a fixed proposal model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LatticeBridge, a twisted sequential Monte Carlo (SMC) decoder for structured sequence generation. The method compiles instance-derived anchor phrases into surface automata, uses a compact GRU-based prefix language model as a shared proposal, and applies a twisted proposal with resampling, multilevel splitting, and a source-support term to improve exact anchor satisfaction. The system is evaluated on 2,610 attainable validation tasks across CommonGen, E2E NLG, and WikiBio, comparing against greedy, beam-filtered, and best-of-k ancestral baselines under the same proposal model. The paper reports multi-dimensional diagnostics including success rate, coverage, source coverage, source intrusion, ROUGE-L, runtime, ESS, and acceptance mass. Code and benchmark files are released.
Significance. The paper addresses a well-defined problem (rare-event structured sequence synthesis) with a clean mathematical formulation connecting twisted SMC to constrained decoding. The surface automaton design that operates over emitted string fragments rather than tokenizer tokens is a practical contribution that addresses tokenization mismatch. The multi-dimensional evaluation (source coverage, source intrusion, ESS, acceptance mass) goes beyond simple success-rate reporting and is commendable. The release of code, benchmark files, and diagnostics artefacts supports reproducibility. The framing of the coverage–fidelity–latency operating frontier under a fixed proposal model is a useful experimental design choice that isolates the inference mechanism from model scale.
major comments (3)
- §5.2 and Table 3: The twisted proposal q_t (Eq. in §5.2) includes two constraint-aware components — the distance-to-acceptance twist exp{τΔ_t} and the source-support term exp{βψ_x(y_t)} — that directly inject constraint information during generation. The baselines (greedy, beam filter, best-of-16) receive no such constraint-awareness during generation; they only apply constraints post-hoc via the selection key in §16. No ablation is reported that separates the SMC resampling/splitting machinery (the novel methodological contribution) from these constraint-aware proposal terms. Without such an ablation — for example, ancestral sampling from the twisted proposal without resampling or splitting, or SMC without the source-support term — it is not possible to determine whether the particle system itself is responsible for the observed gains (e.g., CommonGen success 0.000 → 0.758) or whether a
- §4.1: The benchmark construction retains only phrases 'attested in at least one reference surface for the same instance.' This attainability criterion means the evaluation set is filtered to remove examples where exact-match satisfaction would be impossible. The paper states this prevents impossible labels, but it also means the reported success rates are measured on a positively filtered subset. The size and characteristics of the filtered-out portion (and how it differs across datasets) are not reported. This is load-bearing for the central claim because the success rates in Table 3 are conditional on this pre-filtering, and the reader cannot assess how representative the 2,610 tasks are of the original validation splits.
- §5.2, source-support term ψ_x: The source-support proposal factor biases toward tokens that begin source phrases, and the source coverage metric (SCov, §11) measures the fraction of source phrases present in the output. Since ψ_x is derived from the same phrase inventory P(x) used to compute SCov, there is a structural coupling between the proposal and one of the reported evaluation metrics. The paper does report independent metrics (exact anchor satisfaction, source intrusion) that are not directly optimized by ψ_x, which mitigates this concern. However, the paper should explicitly acknowledge this coupling and discuss whether the source-coverage gains are meaningful given that the proposal is designed to improve exactly this quantity.
minor comments (9)
- §5.2, Eq. for ψ_x(v): The expression 'log e ν_x(v) − log|V| − 1' is unclear. It appears to be a log-density ratio between the empirical phrase-initial measure and uniform, but the notation is ambiguous. Please clarify the formula.
- Table 3: The source intrusion values for CommonGen (0.226) and WikiBio (6.332) are mentioned in §11 but not reported in Table 3 itself. Including them in the table would make the comparison self-contained.
- §8: The hardware specification is mentioned ('Apple Silicon using the Metal backend (mps)') but the specific chip (e.g., M1, M2) is not stated. Since runtime is a reported metric, the exact hardware should be specified.
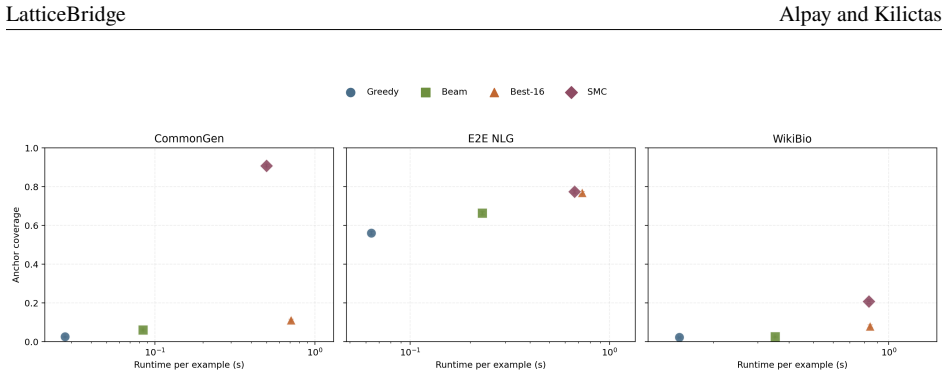
- §9, Figure 1: The figure is described as a 'coverage-runtime frontier' but the axes and data series are not clearly specified in the caption. Readers need to know what each axis represents and what each point/line corresponds to.
- §6 and Appendix A.2: The prefix model architecture (256-dim embedding, 384-dim GRU, 2 layers) is compact. The paper should briefly discuss whether this model has sufficient capacity for the three datasets, perhaps by reporting perplexity or comparing against a known baseline model on these datasets.
- §7.1, Table 1: The training record counts (14,000 / 16,000 / 20,000) appear to be subsets of the full training splits. The selection criterion for these subsets is not stated.
- §14.2: The identity separating variance sources is useful, but the paper could briefly discuss the practical implications of setting τ=λ (which makes the first term vanish) — specifically, whether this choice is theoretically motivated or empirically tuned.
- Appendix D: The qualitative examples are helpful. It would be useful to add 1–2 failure cases where twisted SMC does not improve over baselines, to give a balanced picture.
- References: Several 2025–2026 arXiv preprints are cited (e.g., Chan et al., 2026; Reddy et al., 2026; Su et al., 2026). Please verify these are correctly attributed and that DOIs or stable identifiers are included where available.
Simulated Author's Rebuttal
We thank the referee for a careful and constructive report. The three major comments are well-taken. Comment 1 (ablation separating SMC machinery from constraint-aware proposal terms) is correct and we will add the requested ablation. Comment 2 (attainability filtering transparency) is correct and we will report the filtered-out portion sizes and characteristics. Comment 3 (coupling between source-support proposal factor and SCov metric) is a fair observation; we will add an explicit discussion of this coupling and note the mitigating evidence from independent metrics. All three points require revision.
read point-by-point responses
-
Referee: §5.2 and Table 3: The twisted proposal includes constraint-aware components (distance-to-acceptance twist and source-support term) that the baselines lack. No ablation separates the SMC resampling/splitting machinery from these proposal terms. Without such an ablation, it is unclear whether the particle system or the proposal shaping drives the gains.
Authors: The referee is correct that the current manuscript does not include an ablation isolating the SMC resampling/splitting machinery from the constraint-aware proposal terms (exp{τΔ_t} and exp{βψ_x}). This is a genuine gap in the experimental design. We will add the requested ablation in the revised manuscript, specifically: (1) ancestral sampling from the twisted proposal q_t without resampling or splitting, (2) SMC with resampling and splitting but with the source-support term removed (β=0), and (3) SMC with resampling and splitting but with both constraint-aware proposal terms removed (τ=0, β=0), reducing the proposal to the base model p_θ. This will allow readers to decompose the contribution of the particle system from the proposal shaping. We note that the importance weight correction in §14.2 already provides some analytical separation: when τ=λ, the distance-twist term cancels in the incremental weight, so the remaining correction is the source-support compensation plus the normalizer. However, this analytical argument is not a substitute for the empirical ablation, and we agree the ablation should have been in the original submission. revision: yes
-
Referee: §4.1: The attainability criterion retains only phrases attested in at least one reference surface, filtering the evaluation to a positively selected subset. The size and characteristics of the filtered-out portion are not reported, making it impossible to assess how representative the 2,610 tasks are of the original validation splits.
Authors: The referee is correct that the attainability filtering is load-bearing for interpreting the reported success rates and that the manuscript does not currently report the size or characteristics of the filtered-out portion. We will add a table reporting, for each dataset, the original validation split size, the number of retained attainable tasks, the number filtered out, and basic characteristics of the filtered-out examples (e.g., mean source phrase count, mean reference length). We will also add an explicit statement in §4.1 and §7.2 that all reported success rates are conditional on this pre-filtering. We agree that without this information the reader cannot assess representativeness. One point of clarification we will add: the attainability filter requires that at least one anchor phrase from the source appears in at least one reference surface for the same instance — it does not require that all source phrases appear in references, so the filter is less aggressive than it might initially appear. Nevertheless, the referee's concern about positive selection is valid, and the revised manuscript will make the filtering scope and its consequences fully transparent. revision: yes
-
Referee: §5.2, source-support term ψ_x: There is a structural coupling between the source-support proposal factor (which biases toward tokens beginning source phrases) and the source coverage metric SCov (which measures the fraction of source phrases present in the output), since both are derived from the same phrase inventory P(x). The paper should explicitly acknowledge this coupling and discuss whether the source-coverage gains are meaningful given the proposal is designed to improve exactly this quantity.
Authors: The referee correctly identifies a structural coupling: the source-support term ψ_x is derived from the same phrase inventory P(x) used to compute SCov, so the proposal is partially optimized for a quantity that appears in the evaluation. We will add an explicit acknowledgment of this coupling in the revised manuscript, likely in §5.2 or §11. We note that the manuscript already provides mitigating evidence: (1) the primary success metric is exact anchor satisfaction over the selected anchor subset, not SCov; (2) SCov is reported as a diagnostic over the full source phrase inventory, not just the anchor subset used in the proposal; (3) source intrusion (Intr) is computed over a different vocabulary (content terms from the evaluation subset minus the current instance's terms) and is not directly optimized by ψ_x; and (4) on E2E, twisted SMC actually has lower SCov than best-of-16 ancestral sampling (0.525 vs. 0.628), which would not be expected if the coupling were driving the metric. These points argue that the SCov gains are not purely an artifact of the coupling, but we agree the coupling should be discussed explicitly rather than left for the reader to infer. revision: yes
Circularity Check
Minor overlap between source-support proposal and source-coverage diagnostic; central claim has independent grounding
full rationale
The paper's central claim—that twisted SMC with resampling, splitting, and a source-support proposal improves exact anchor satisfaction over baselines—is not circular. The primary metric (exact anchor satisfaction, §3 Eq. A) is defined by whether selected anchor phrases appear in the output, and the method's distance-to-acceptance twist exp{τΔ_t} (§5.1) uses automaton geometry to reward progress toward acceptance. This is standard method design: a constrained decoder is built to satisfy constraints, then evaluated on constraint satisfaction. The SMC framework, Feynman-Kac formulation, and multilevel splitting are drawn from external, well-established literature (Del Moral 2004; Cerou and Guyader 2007; Naesseth et al. 2019; Zhao et al. 2024). No self-citations are load-bearing. The theoretical derivation (§13–14) transparently acknowledges that the exact Doob harmonic function is intractable and uses deterministic surrogates, rather than smuggling in an ansatz via citation. The one area of partial overlap is that the source-support term ψ_x (§5.2) biases the proposal toward tokens starting source phrases from P(x), while source coverage SCov (§11) measures the fraction of P(x) phrases present in the output. However, source coverage is explicitly a secondary diagnostic, not the primary claim, and the primary metric (exact anchor satisfaction) is driven by the automaton-distance twist, not the source-support term. The paper is transparent that ψ_x 'biases the proposal toward tokens that can start source-supported phrases.' This overlap is minor and does not reduce the central result to its inputs by construction. The absence of an ablation isolating SMC machinery from the source-support term is a valid confound concern (correctness/ablation risk), but it is not circularity: the method's components are defined independently of the evaluation metric, and the comparison against baselines that share the same proposal model and selection key (§16) provides genuine empirical content. Score 2 reflects the minor source-support/source-coverage overlap without rising to a level where any prediction is forced by construction or self-citation chain.
Axiom & Free-Parameter Ledger
free parameters (6)
- lambda (bridge strength) =
2.0
- tau (distance-twist coefficient) =
2.0
- beta (source-support scale) =
0.4
- rho (ESS threshold) =
0.5
- splitting interval =
12
- elite fraction =
0.2
axioms (3)
- domain assumption The exact Doob h-transform is intractable due to the continuous recurrent hidden state.
- domain assumption Attainability criterion: retaining only phrases attested in at least one reference surface prevents impossible exact-match labels.
- domain assumption A compact GRU model is a sufficient proposal model for isolating the inference mechanism.
invented entities (2)
-
Surface automaton product state
independent evidence
-
Source-support proposal factor (psi_x)
independent evidence
Reference graph
Works this paper leans on
-
[1]
Constrainedsamplingforlanguagemodelsshouldbeeasy: Anmcmcperspective.arXiv preprint arXiv:2506.05754,
Emmanuel Anaya Gonzalez, Sairam Vaidya, Kanghee Park, Ruyi Ji, Taylor Berg-Kirkpatrick, and Loris D’Antoni. Constrainedsamplingforlanguagemodelsshouldbeeasy: Anmcmcperspective.arXiv preprint arXiv:2506.05754,
-
[2]
O’Donnell, Ryan Cotterell, and Tim Vieira
Robin Shing Moon Chan, Tianyu Liu, Samuel Kiegeland, Clemente Pasti, Jacob Hoover Vigly, Timothy J. O’Donnell, Ryan Cotterell, and Tim Vieira. Ensembling language models with sequential monte carlo. arXiv preprint arXiv:2603.05432,
-
[3]
A*-decoding: Token-efficient inference scaling.arXiv preprint arXiv:2505.13672,
Giannis Chatziveroglou. A*-decoding: Token-efficient inference scaling.arXiv preprint arXiv:2505.13672,
-
[4]
Sooyeon Kim, Giung Nam, Byoungwoo Park, and Juho Lee. Improving constrained language generation via self-distilled twisted sequential monte carlo.arXiv preprint arXiv:2507.02315,
-
[5]
Automata-based constraints for language model decoding.arXiv preprint arXiv:2407.08103,
Terry Koo, Frederick Liu, and Luheng He. Automata-based constraints for language model decoding.arXiv preprint arXiv:2407.08103,
-
[6]
Neural Text Generation from Structured Data with Application to the Biography Domain
15 LatticeBridge Alpay and Kilictas Remi Lebret, David Grangier, and Michael Auli. Generating text from structured data with application to the biography domain.arXiv preprint arXiv:1603.07771,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Datasets: A community library for natural language processing
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, et al. Datasets: A community library for natural language processing. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, page...
work page 2021
-
[8]
Commongen: A constrained text generation challenge for generative commonsense reasoning
Bill Yuchen Lin, Wangchunshu Zhou, Ming Shen, Pei Zhou, Chandra Bhagavatula, Yejin Choi, and Xiang Ren. Commongen: A constrained text generation challenge for generative commonsense reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1823–1840,
work page 2020
-
[9]
Thinking Before Constraining: A Unified Decoding Framework for Large Language Models
Ngoc Trinh Hung Nguyen, Alonso Silva, Laith Zumot, Liubov Tupikina, Armen Aghasaryan, and Mehwish Alam. Thinking before constraining: A unified decoding framework for large language models.arXiv preprint arXiv:2601.07525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
The Hidden Cost of Structured Generation in LLMs: Draft-Conditioned Constrained Decoding
Avinash Reddy, Thayne T. Walker, James S. Ide, and Amrit Singh Bedi. Draft-conditioned constrained decoding for structured generation in llms.arXiv preprint arXiv:2603.03305,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Zhengyang Su, Isay Katsman, Yueqi Wang, Ruining He, Lukasz Heldt, Raghunandan Keshavan, Shao-Chuan Wang, Xinyang Yi, Mingyan Gao, Onkar Dalal, Lichan Hong, Ed Chi, and Ningren Han. Vectorizing the trie: Efficient constrained decoding for llm-based generative retrieval on accelerators.arXiv preprint arXiv:2602.22647,
-
[12]
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, and Dong Yu. Step- by-step reasoning for math problems via twisted sequential monte carlo.arXiv preprint arXiv:2410.01920,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.