A2SG:Adaptive and Asymmetric Surrogate Gradients for Training Deep Spiking Neural Networks
Pith reviewed 2026-06-28 20:14 UTC · model grok-4.3
The pith
Adaptive and asymmetric surrogate gradients reduce gradient variation in deep spiking neural networks and connect lower variation to flatter loss minima.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
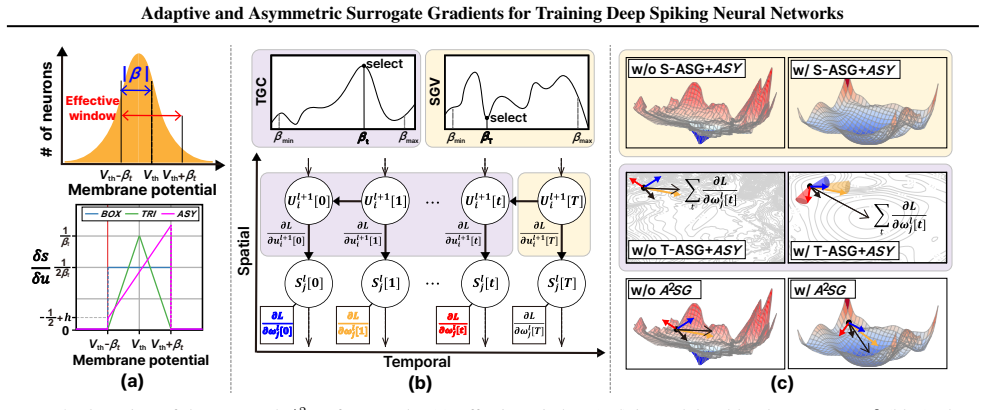
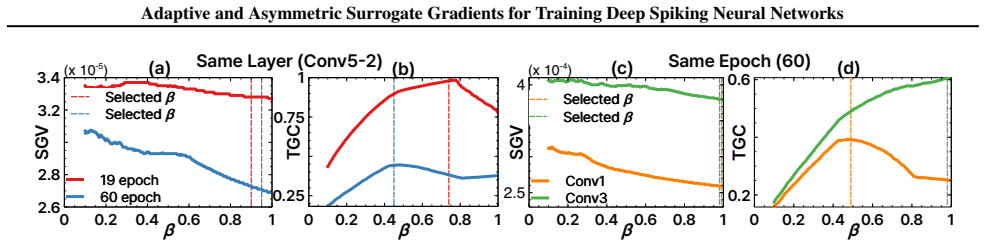
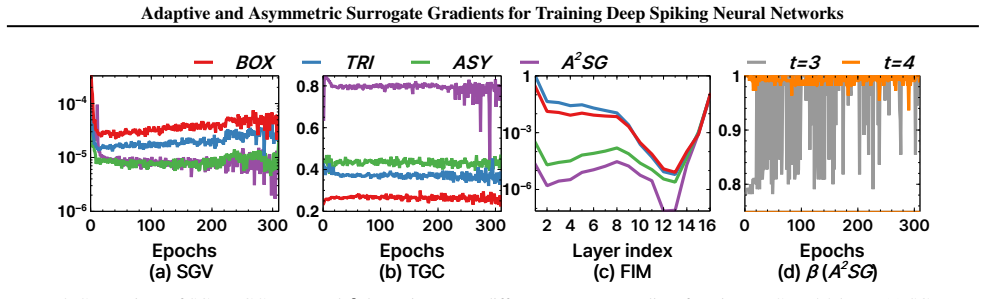
The central claim is that asymmetric surrogate gradients, by assigning larger values to neurons with higher membrane potentials, yield provably lower gradient variation than symmetric surrogates, and that local gradient variation is directly connected to loss-landscape curvature; therefore A2SG promotes convergence to flatter minima, improves generalization, and provides a reliable training method for deep SNNs on classification and segmentation tasks.
What carries the argument
The A2SG framework of adaptive spatio-temporal window adjustment combined with asymmetric gradient assignment based on membrane potential, plus the proven link between local gradient variation and loss-landscape curvature.
If this is right
- A2SG applies uniformly to CNN-based and Transformer-based spiking architectures.
- Training reaches flatter minima that improve generalization on both static and event-based datasets.
- Accuracy gains appear together with lower energy consumption during inference.
- The same surrogate-gradient design addresses both spatial variation and temporal inconsistency in one framework.
- The method supplies a general solution for the surrogate-gradient problem in deep SNNs.
Where Pith is reading between the lines
- The variation-curvature link could be tested as a general principle for surrogate gradients outside spiking networks.
- Asymmetric assignment based on membrane potential might be combined with other sharpness-aware optimizers.
- The adaptive window mechanism could be ported to other temporally structured models such as recurrent networks.
- Flatter-minima convergence might translate to better robustness under distribution shift in neuromorphic hardware.
Load-bearing premise
The assumption that asymmetric gradients reflect neuronal dynamics and provably yield lower variation than symmetric surrogates is required for the variation-curvature connection and the generalization benefit to follow.
What would settle it
A direct measurement of loss-landscape curvature (for example via Hessian trace or sharpness metrics) on networks trained with A2SG versus standard symmetric surrogates, checking whether lower variation indeed produces flatter minima and whether that flatness accounts for the observed accuracy gains.
Figures


read the original abstract
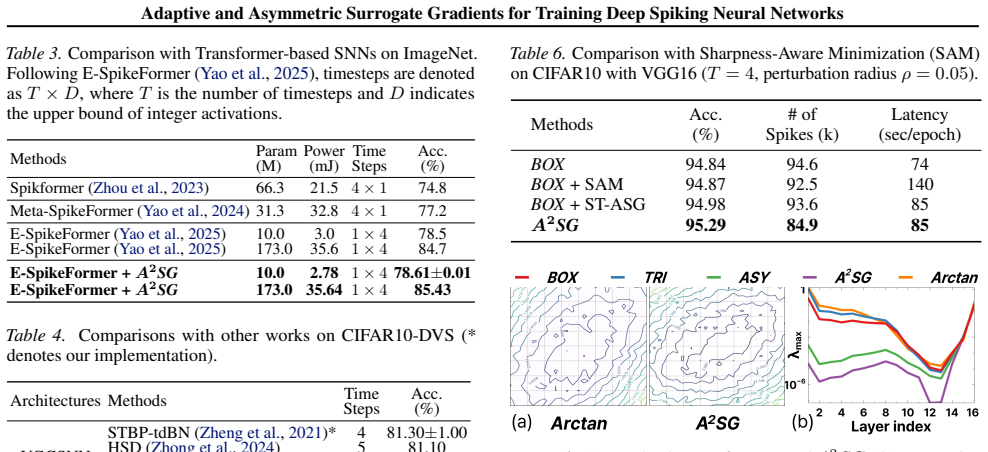
Training deep spiking neural networks (SNNs) remains challenging due to sharp loss landscapes and temporal inconsistency caused by surrogate gradients. To address these challenges, we propose a unified framework: adaptive and asymmetric surrogate gradients A2SG. The adaptive gradients adjust an effective window for spatio-temporal adaptation, reducing spatial gradient variation and maintaining directional consistency of gradients over time. The asymmetric gradients reflect neuronal dynamics by assigning larger gradients to neurons with higher membrane potentials, and we prove that they yield lower variation than symmetric surrogates. Our analysis further establishes a direct connection between local gradient variation and the curvature of the loss landscape, providing a principled explanation for how A2SG promotes convergence to flatter minima and improves generalization. We conduct extensive experiments on diverse models, including CNN-based and Transformer-based SNNs, across various tasks such as image classification using both static and neuromorphic datasets, as well as segmentation. The results demonstrate that A2SG consistently improves accuracy and energy efficiency, establishing it as a general and reliable solution for training deep SNNs. Our code is available at https://github.com/KIST-NCL/A2SG.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes A2SG, a unified framework of adaptive and asymmetric surrogate gradients for training deep SNNs. Adaptive gradients adjust an effective spatio-temporal window to reduce spatial variation while preserving temporal directional consistency. Asymmetric gradients assign larger values to higher membrane potentials and are claimed to provably yield lower variation than symmetric surrogates. The authors further assert a direct link between local gradient variation and loss-landscape curvature that explains convergence to flatter minima and better generalization. Experiments on CNN- and Transformer-based SNNs for static/neuromorphic image classification and segmentation report consistent gains in accuracy and energy efficiency, with code released.
Significance. If the variation-reduction proof and the variation-to-curvature connection are rigorously established, the work would supply a principled design principle for surrogate gradients in SNNs, directly addressing the sharp landscapes and temporal inconsistency that hinder deep SNN training. Reproducibility via the public repository strengthens the contribution for the neuromorphic-computing community.
major comments (2)
- [Analysis section (and abstract)] The abstract and analysis assert that asymmetric gradients 'provably yield lower variation than symmetric surrogates' and establish a 'direct connection' to loss curvature, yet no derivation steps, inequality, or membrane-potential statistics are supplied; without these the load-bearing claims that variation reduction explains flatter minima cannot be verified.
- [Theoretical analysis] The weakest assumption—that larger gradients for higher membrane potentials reflect neuronal dynamics and strictly reduce variation—remains untested against actual SNN membrane-potential distributions; if the inequality fails under realistic statistics the generalization benefit does not follow.
minor comments (2)
- [Experiments] Dataset details, statistical controls (e.g., multiple random seeds, error bars), and hyper-parameter tables are referenced in the abstract but not visible in the supplied text; these should be added for reproducibility.
- [Method] Notation for the adaptive window and the precise definition of 'effective window' should be introduced with an equation before the claims about reduced spatial variation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical claims. We address the points below and will strengthen the analysis section accordingly.
read point-by-point responses
-
Referee: [Analysis section (and abstract)] The abstract and analysis assert that asymmetric gradients 'provably yield lower variation than symmetric surrogates' and establish a 'direct connection' to loss curvature, yet no derivation steps, inequality, or membrane-potential statistics are supplied; without these the load-bearing claims that variation reduction explains flatter minima cannot be verified.
Authors: We acknowledge that the manuscript presents the claims but does not supply the full derivation steps or explicit inequalities. In the revised version we will insert the complete proof of lower variation for the asymmetric case (including the specific inequality and the membrane-potential statistics invoked) together with the step-by-step derivation that links local gradient variation to loss-landscape curvature. This will make both assertions directly verifiable from the text. revision: yes
-
Referee: [Theoretical analysis] The weakest assumption—that larger gradients for higher membrane potentials reflect neuronal dynamics and strictly reduce variation—remains untested against actual SNN membrane-potential distributions; if the inequality fails under realistic statistics the generalization benefit does not follow.
Authors: The asymmetry is motivated by the integrate-and-fire dynamics in which neurons nearer threshold exert greater influence on the spike output. To address the concern directly, the revision will add an empirical verification that extracts membrane-potential histograms from the trained SNNs on the reported datasets and confirms that the variation-reduction inequality holds under those observed distributions. revision: yes
Circularity Check
No circularity; claims rest on stated proofs and analysis without reduction to fitted inputs or self-citations
full rationale
The abstract states that asymmetric gradients 'yield lower variation than symmetric surrogates' via a proof and that analysis 'establishes a direct connection' to loss-landscape curvature. No equations, fitted parameters, or self-citations are supplied that would make these claims reduce by construction to the method definition itself. The derivation chain is presented as independent mathematical analysis rather than a renaming, ansatz smuggling, or input-called-prediction. This matches the default expectation of a self-contained paper with no detectable circular steps from the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural Networks , volume=
Networks of spiking neurons: the third generation of neural network models , author=. Neural Networks , volume=. 1997 , publisher=
1997
-
[2]
arXiv , year=
Great power, great responsibility: Recommendations for reducing energy for training language models , author=. arXiv , year=
-
[3]
Neural Networks , volume=
Deep learning in spiking neural networks , author=. Neural Networks , volume=. 2019 , publisher=
2019
-
[4]
Advances in Neural Information Processing Systems , volume=
Deep residual learning in spiking neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Spiking deep residual networks , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2021 , publisher=
2021
-
[6]
IEEE Access , volume=
Towards fast and accurate object detection in bio-inspired spiking neural networks through Bayesian optimization , author=. IEEE Access , volume=. 2020 , publisher=
2020
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Spiking-yolo: spiking neural network for energy-efficient object detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Neuromorphic Computing and Engineering , volume=
Beyond classification: Directly training spiking neural networks for semantic segmentation , author=. Neuromorphic Computing and Engineering , volume=. 2022 , publisher=
2022
-
[9]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Spike2former: Efficient spiking transformer for high-performance image segmentation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[10]
International Conference on Learning Representations , year=
Spikformer: When Spiking Neural Network Meets Transformer , author=. International Conference on Learning Representations , year=
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Scaling spike-driven transformer with efficient spike firing approximation training , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2025 , publisher=
2025
-
[12]
International Conference on Learning Representations , year=
Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips , author=. International Conference on Learning Representations , year=
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Reducing ann-snn conversion error through residual membrane potential , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
, author=
Signed Neuron with Memory: Towards Simple, Accurate and High-Efficient ANN-SNN Conversion. , author=. IJCAI , pages=
-
[15]
Frontiers in Neuroscience , volume=
Spatio-temporal backpropagation for training high-performance spiking neural networks , author=. Frontiers in Neuroscience , volume=. 2018 , publisher=
2018
-
[16]
IEEE Signal Processing Magazine , volume=
Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks , author=. IEEE Signal Processing Magazine , volume=. 2019 , publisher=
2019
-
[17]
Advances in Neural Information Processing Systems , volume=
Differentiable spike: Rethinking gradient-descent for training spiking neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the International Joint Conference on Artificial Intelligence , pages=
Learnable surrogate gradient for direct training spiking neural networks , author=. Proceedings of the International Joint Conference on Artificial Intelligence , pages=
-
[19]
Neural Networks , volume=
Directly training temporal Spiking Neural Network with sparse surrogate gradient , author=. Neural Networks , volume=. 2024 , publisher=
2024
-
[20]
Frontiers in Neuroscience , volume=
Backpropagation with sparsity regularization for spiking neural network learning , author=. Frontiers in Neuroscience , volume=. 2022 , publisher=
2022
-
[21]
Pattern Recognition , volume=
Improving stability and performance of spiking neural networks through enhancing temporal consistency , author=. Pattern Recognition , volume=. 2025 , publisher=
2025
-
[22]
International Conference on Learning Representations , year=
Rethinking Spiking Neural Networks from an Ensemble Learning Perspective , author=. International Conference on Learning Representations , year=
-
[23]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Towards memory-and time-efficient backpropagation for training spiking neural networks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
International Conference on Learning Representations , year=
Which layer is learning faster? a systematic exploration of layer-wise convergence rate for deep neural networks , author=. International Conference on Learning Representations , year=
-
[25]
International conference on machine learning , pages=
The impact of neural network overparameterization on gradient confusion and stochastic gradient descent , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[26]
Advances in neural information processing systems , volume=
Visualizing the loss landscape of neural nets , author=. Advances in neural information processing systems , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Im-loss: information maximization loss for spiking neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Rmp-loss: Regularizing membrane potential distribution for spiking neural networks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Membrane potential batch normalization for spiking neural networks , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[30]
International Conference on Learning Representations , year=
Temporal Efficient Training of Spiking Neural Network via Gradient Re-weighting , author=. International Conference on Learning Representations , year=
-
[31]
The Twelfth International Conference on Learning Representations , year=
TAB: Temporal Accumulated Batch normalization in spiking neural networks , author=. The Twelfth International Conference on Learning Representations , year=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
FSTA-SNN: Frequency-Based Spatial-Temporal Attention Module for Spiking Neural Networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Going deeper with directly-trained larger spiking neural networks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[34]
International Conference on Machine Learning , volume =
Enhancing adversarial robustness in SNNs with sparse gradients , author =. International Conference on Machine Learning , volume =. 2024 , publisher =
2024
-
[35]
ICML 2023 Workshop on Differentiable Almost Everything: Differentiable Relaxations, Algorithms, Operators, and Simulators , year=
Efficient Surrogate Gradients for Training Spiking Neural Networks , author=. ICML 2023 Workshop on Differentiable Almost Everything: Differentiable Relaxations, Algorithms, Operators, and Simulators , year=
2023
-
[36]
Statistics & probability letters , volume=
A weighted central limit theorem , author=. Statistics & probability letters , volume=. 2006 , publisher=
2006
-
[37]
2020 57th ACM/IEEE design automation conference (DAC) , pages=
T2FSNN: deep spiking neural networks with time-to-first-spike coding , author=. 2020 57th ACM/IEEE design automation conference (DAC) , pages=. 2020 , organization=
2020
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Spikingbert: Distilling bert to train spiking language models using implicit differentiation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Enhancing training of spiking neural network with stochastic latency , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[40]
Journal of Machine Learning Research , volume=
New insights and perspectives on the natural gradient method , author=. Journal of Machine Learning Research , volume=
-
[41]
International Conference on Learning Representations , year =
On large-batch training for deep learning: Generalization gap and sharp minima , author =. International Conference on Learning Representations , year =
-
[42]
Journal of Statistical Mechanics: Theory and Experiment , volume=
Entropy-sgd: Biasing gradient descent into wide valleys , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2019 , publisher=
2019
-
[43]
International Conference on Machine Learning , year =
Entropy‑SGD optimizes the prior of a PAC‑Bayes bound: Generalization properties of Entropy‑SGD and data‑dependent priors , author =. International Conference on Machine Learning , year =
-
[44]
Neural Computation , volume=
Flat minima , author=. Neural Computation , volume=. 1997 , publisher=
1997
-
[45]
Neural Computation , year=
Universal statistics of fisher information in deep neural networks , author=. Neural Computation , year=
-
[46]
IEEE transactions on pattern analysis and machine intelligence , volume=
Approximate fisher information matrix to characterize the training of deep neural networks , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2018 , publisher=
2018
-
[47]
International Conference on Machine Learning , pages=
Fisher sam: Information geometry and sharpness aware minimisation , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[48]
International Conference on Machine Learning , volume=
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density , author=. International Conference on Machine Learning , volume=. 2019 , publisher=
2019
-
[49]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Scene parsing through ade20k dataset , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[50]
Frontiers in Neuroscience , volume=
Cifar10-dvs: an event-stream dataset for object classification , author=. Frontiers in Neuroscience , volume=. 2017 , publisher=
2017
-
[51]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[52]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[53]
Advances in Neural Information Processing Systems , volume=
Take a shortcut back: Mitigating the gradient vanishing for training spiking neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Proceedings of the International Joint Conference on Artificial Intelligence , publisher =
Adaptive Gradient Learning for Spiking Neural Networks by Exploiting Membrane Potential Dynamics , author =. Proceedings of the International Joint Conference on Artificial Intelligence , publisher =. 2025 , month =
2025
-
[55]
SIAM review , volume=
First-order perturbation theory for eigenvalues and eigenvectors , author=. SIAM review , volume=. 2020 , publisher=
2020
-
[56]
Advances in Neural Information Processing Systems , volume=
Formalizing generalization and adversarial robustness of neural networks to weight perturbations , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Deep directly-trained spiking neural networks for object detection , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[58]
International Conference on Machine Learning , articleno =
Xing, Xingrun and Zhang, Zheng and Ni, Ziyi and Xiao, Shitao and Ju, Yiming and Fan, Siqi and Wang, Yequan and Zhang, Jiajun and Li, Guoqi , title =. International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[59]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Cutmix: Regularization strategy to train strong classifiers with localizable features , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[60]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
Randaugment: Practical automated data augmentation with a reduced search space , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops , pages=
-
[61]
International Conference on Learning Representations , year=
mixup: Beyond Empirical Risk Minimization , author=. International Conference on Learning Representations , year=
-
[62]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Incorporating learnable membrane time constant to enhance learning of spiking neural networks , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[63]
International Conference on Machine Learning , year=
Training high performance spiking neural network by temporal model calibration , author=. International Conference on Machine Learning , year=
-
[64]
Neural Networks , volume=
Self-architectural knowledge distillat1ion for spiking neural networks , author=. Neural Networks , volume=. 2024 , publisher=
2024
-
[65]
Proceedings of the 32nd ACM international conference on multimedia , pages=
Towards low-latency event-based visual recognition with hybrid step-wise distillation spiking neural networks , author=. Proceedings of the 32nd ACM international conference on multimedia , pages=
-
[66]
International Conference on Learning Representations , year =
Sharpness-Aware Minimization for Efficiently Improving Generalization , author =. International Conference on Learning Representations , year =
-
[67]
and Sengupta, A
Bal, M. and Sengupta, A. Spikingbert: Distilling bert to train spiking language models using implicit differentiation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 10998--11006, 2024
2024
-
[68]
Entropy-sgd: Biasing gradient descent into wide valleys
Chaudhari, P., Choromanska, A., Soatto, S., LeCun, Y., Baldassi, C., Borgs, C., Chayes, J., Sagun, L., and Zecchina, R. Entropy-sgd: Biasing gradient descent into wide valleys. Journal of Statistical Mechanics: Theory and Experiment, 2019 0 (12): 0 124018, 2019
2019
-
[69]
D., Zoph, B., Shlens, J., and Le, Q
Cubuk, E. D., Zoph, B., Shlens, J., and Le, Q. V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp.\ 702--703, 2020
2020
-
[70]
Imagenet: A large-scale hierarchical image database
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp.\ 248--255. IEEE, 2009
2009
-
[71]
Temporal efficient training of spiking neural network via gradient re-weighting
Deng, S., Li, Y., Zhang, S., and Gu, S. Temporal efficient training of spiking neural network via gradient re-weighting. In International Conference on Learning Representations, 2022
2022
-
[72]
Deep residual learning in spiking neural networks
Fang, W., Yu, Z., Chen, Y., Huang, T., Masquelier, T., and Tian, Y. Deep residual learning in spiking neural networks. Advances in Neural Information Processing Systems, 34: 0 21056--21069, 2021 a
2021
-
[73]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks
Fang, W., Yu, Z., Chen, Y., Masquelier, T., Huang, T., and Tian, Y. Incorporating learnable membrane time constant to enhance learning of spiking neural networks. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 2661--2671, 2021 b
2021
-
[74]
Sharpness-aware minimization for efficiently improving generalization
Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. Sharpness-aware minimization for efficiently improving generalization. In International Conference on Learning Representations, 2021
2021
-
[75]
An investigation into neural net optimization via hessian eigenvalue density
Ghorbani, B., Krishnan, S., and Xiao, Y. An investigation into neural net optimization via hessian eigenvalue density. In International Conference on Machine Learning, volume 97, pp.\ 2232--2241. PMLR, 2019
2019
-
[76]
Greenbaum, A., Li, R.-c., and Overton, M. L. First-order perturbation theory for eigenvalues and eigenvectors. SIAM review, 62 0 (2): 0 463--482, 2020
2020
-
[77]
Im-loss: information maximization loss for spiking neural networks
Guo, Y., Chen, Y., Zhang, L., Liu, X., Wang, Y., Huang, X., and Ma, Z. Im-loss: information maximization loss for spiking neural networks. Advances in Neural Information Processing Systems, 35: 0 156--166, 2022
2022
-
[78]
Rmp-loss: Regularizing membrane potential distribution for spiking neural networks
Guo, Y., Liu, X., Chen, Y., Zhang, L., Peng, W., Zhang, Y., Huang, X., and Ma, Z. Rmp-loss: Regularizing membrane potential distribution for spiking neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 17391--17401, 2023 a
2023
-
[79]
Membrane potential batch normalization for spiking neural networks
Guo, Y., Zhang, Y., Chen, Y., Peng, W., Liu, X., Zhang, L., Huang, X., and Ma, Z. Membrane potential batch normalization for spiking neural networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 19420--19430, 2023 b
2023
-
[80]
Take a shortcut back: Mitigating the gradient vanishing for training spiking neural networks
Guo, Y., Chen, Y., Hao, Z., Peng, W., Jie, Z., Zhang, Y., Liu, X., and Ma, Z. Take a shortcut back: Mitigating the gradient vanishing for training spiking neural networks. Advances in Neural Information Processing Systems, 37: 0 24849--24867, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.