Massive Open-Vocabulary Keyword Spotting
Pith reviewed 2026-06-27 11:44 UTC · model grok-4.3
The pith
A feature compression method enables open-vocabulary keyword spotting on massive databases with up to 128 times less memory while matching uncompressed recall without model fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The system stores features with a memory footprint up to 128 times smaller than a comparable baseline and allows users to process massive databases while remaining open-vocabulary. Without fine-tuning the speech recognition model, the system achieves a comparable entity recall as uncompressed solutions, even in languages not seen during training.
What carries the argument
A feature compression method that reduces the storage size of keyword representations while retaining the information needed for accurate matching.
If this is right
- Users can maintain open-vocabulary keyword spotting on glossaries far larger than a few hundred terms without creating a computational bottleneck.
- The same compressed storage works for languages absent from the original training data.
- Entity recall stays comparable to full-size baselines without any retraining of the speech recognition model.
Where Pith is reading between the lines
- The reduced memory footprint could allow the technique to run on edge devices with strict storage limits.
- Combining the compressed store with existing contextual biasing methods might further improve accuracy on rare or specialized terms.
Load-bearing premise
The compression step preserves enough distinguishing information in the stored features that recall on large vocabularies does not fall below the level achieved by uncompressed storage.
What would settle it
A direct comparison on a large open-vocabulary test set in which the compressed system shows substantially lower entity recall than the uncompressed baseline.
Figures


read the original abstract
Automatic speech recognition systems have been shown to under-perform when it comes to transcribing words rarely seen in the training data, namely specialized terminology. Open-vocabulary keyword spotting, combined with contextual biasing, has been shown to mitigate this issue. However, existing systems can only handle glossaries of a few hundred terms without becoming an infeasible bottleneck. We propose a system that stores features with a memory footprint up to 128 times smaller than a comparable baseline and allows users to process massive databases while remaining open-vocabulary. Without fine-tuning the speech recognition model, our system achieves a comparable entity recall as uncompressed solutions, even in languages not seen during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a feature compression scheme for open-vocabulary keyword spotting that reduces memory footprint by up to 128× relative to baselines while preserving entity recall comparable to uncompressed systems. The approach requires no fine-tuning of the underlying ASR model and is claimed to generalize to languages unseen during training, enabling processing of massive glossaries without becoming a computational bottleneck.
Significance. If the empirical claims are substantiated, the work would remove a key scalability barrier in contextual biasing for ASR, allowing practical use of very large open-vocabulary glossaries. The reported cross-lingual generalization without retraining would be a notable strength.
major comments (1)
- [Abstract] Abstract: the central claims of 'comparable entity recall' and 'memory footprint up to 128 times smaller' are stated without any quantitative results, baseline systems, datasets, evaluation metrics, or error analysis. This absence is load-bearing because the entire contribution rests on these empirical assertions.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below, noting that the manuscript body contains the requested empirical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'comparable entity recall' and 'memory footprint up to 128 times smaller' are stated without any quantitative results, baseline systems, datasets, evaluation metrics, or error analysis. This absence is load-bearing because the entire contribution rests on these empirical assertions.
Authors: Abstracts are intentionally concise summaries and conventionally omit specific numbers, baselines, datasets, metrics, and error analysis; those elements appear in the main text (experimental setup, results tables, and analysis sections). The manuscript reports concrete entity-recall figures matching the uncompressed baseline, a measured 128× memory reduction, the exact datasets and metrics used, and cross-lingual results on unseen languages, all without ASR fine-tuning. We therefore see no need to expand the abstract itself. revision: no
Circularity Check
No significant circularity; empirical result only
full rationale
The paper presents an empirical system for open-vocabulary keyword spotting via feature compression, claiming up to 128× memory reduction with comparable recall on seen and unseen languages without ASR fine-tuning. No mathematical derivations, equations, or parameter-fitting steps are described that would reduce a claimed prediction to its own inputs by construction. The central claims rest on experimental comparisons to baselines rather than any self-referential definition, fitted-input prediction, or self-citation chain. This is the expected non-finding for a purely systems/empirical contribution with no load-bearing theoretical steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Automatic speech recognition (ASR) is a task where spoken language is transcribed into text. It is crucial in several ap- plications, from virtual assistants to live captions in various domains [1, 2]. The Whisper [3] models, which are encoder- decoder models, are some of the most popular speech founda- tion models for ASR, and recent works h...
Pith/arXiv arXiv 2026
-
[2]
Methodology 2.1. Baseline for OV-KWS The OV-KWS system from CB-Whisper [10] is based on two modules.(1)A transformer-based audio encoder from a Whis- per model that encodes each audio as embeddings inR l×f×h , wherelis the number of selected transformer layers from which representations are extracted,fis the number of frames, and his the hidden dimension....
-
[3]
Datasets 3.1.1
Experimental setup 3.1. Datasets 3.1.1. Training data The training data for our models was extracted from the Mul- tilingual Librispeech (MLS) corpus [16], derived from read au- diobooks. As it is an imbalanced dataset, we reused [11]’s code- base to prepare 25 h of training data for six languages: English, French, German, Polish, Portuguese, and Spanish....
-
[4]
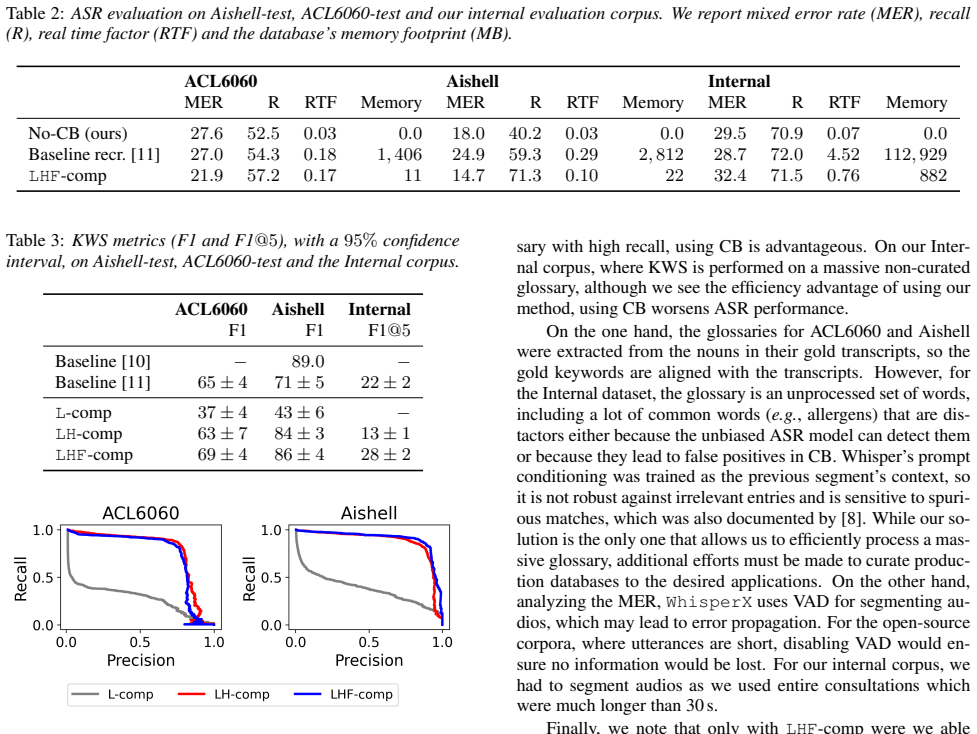
Keyword-spotting experiments The performance of our OV-KWS model and the baselines is in Table 3
Experimental Results 4.1. Keyword-spotting experiments The performance of our OV-KWS model and the baselines is in Table 3. All evaluations were out-of-domain for ours and [11]’s models, unlike for [10] in Aishell. The model which produces the smallest embeddings,LHF-comp, achieves a com- parable performance to the best-performing model on Aishell, even t...
-
[5]
Given a biasing list of domain-specific terms, from the tail word distribution, it steers generation to include them
Conclusion Contextual biasing is an effective technique to improve the qual- ity of ASR systems in specialized domains. Given a biasing list of domain-specific terms, from the tail word distribution, it steers generation to include them. Open-vocabulary keyword spotting aids in ensuring concise biasing lists, with terms that appear in the input query. Thi...
-
[6]
Acknowledgments This research was supported by the Portuguese Recovery and Resilience Plan through project C645008882-00000055 (i.e., the Center For Responsible AI)
-
[7]
We used Claude Code (Opus 4.8) for the integration of the codebase we produced (without any generative AI) with the existing codebase for publication
Generative AI Use Disclosure All references were obtained via Google Scholar search, and we studied them ourselves. We used Claude Code (Opus 4.8) for the integration of the codebase we produced (without any generative AI) with the existing codebase for publication. No new code was generated, and manually reviewed it to ensure that. The entirety of this p...
-
[8]
Speech technology for healthcare: Opportunities, challenges, and state of the art,
S. Latif, J. Qadir, A. Qayyum, M. Usama, and S. Younis, “Speech technology for healthcare: Opportunities, challenges, and state of the art,”IEEE Reviews in Biomedical Engineering, vol. 14, pp. 342–356, 2020
2020
-
[9]
ASR in classroom today: Automatic visualization of conceptual network in science classrooms,
D. Caballero, R. Araya, H. Kronholm, J. Viiri, A. Mansikkaniemi, S. Lehesvuori, T. Virtanen, and M. Kurimo, “ASR in classroom today: Automatic visualization of conceptual network in science classrooms,” inECTEL. Springer, 2017
2017
-
[10]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inICML, 2023
2023
-
[11]
OWSM v3. 1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer,
Y . Peng, J. Tian, W. Chen, S. Arora, B. Yan, Y . Sudo, M. Shakeel, K. Choi, J. Shi, X. Changet al., “OWSM v3. 1: Better and Faster Open Whisper-Style Speech Models based on E-Branchformer,” inInterspeech, 2024
2024
-
[12]
LLM-based Generative Error Correction for Rare Words with Synthetic Data and Phonetic Context,
N. Yamashita, M. Yamamoto, H. Kokubo, and Y . Kawaguchi, “LLM-based Generative Error Correction for Rare Words with Synthetic Data and Phonetic Context,” inInterspeech, 2025
2025
-
[13]
Minimising biasing word errors for contextual asr with the tree-constrained pointer gener- ator,
G. Sun, C. Zhang, and P. C. Woodland, “Minimising biasing word errors for contextual asr with the tree-constrained pointer gener- ator,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 345–354, 2022
2022
-
[14]
Implement- ing contextual biasing in gpu decoder for online asr,
I. Nigmatulina, S. Madikeri, E. Villatoro-Tello, P. Motlicek, J. Zuluaga-Gomez, K. Pandia, and A. Ganapathiraju, “Implement- ing contextual biasing in gpu decoder for online asr,” inInter- speech, 2023
2023
-
[15]
Contextual biasing speech recognition in speech-enhanced large language model,
X. Gong, A. Lv, Z. Wang, and Y . Qian, “Contextual biasing speech recognition in speech-enhanced large language model,” in Interspeech, 2024
2024
-
[16]
Keyword-Guided Adaptation of Automatic Speech Recogni- tion,
A. Shamsian, A. Navon, N. Glazer, G. Hetz, and J. Keshet, “Keyword-Guided Adaptation of Automatic Speech Recogni- tion,” inInterspeech, 2024
2024
-
[17]
CB-whisper: Contextual biasing whisper using open-vocabulary keyword-spotting,
Y . Li, Y . Li, M. Zhang, C. Su, J. Yu, M. Piao, X. Qiao, M. Ma, Y . Zhao, and H. Yang, “CB-whisper: Contextual biasing whisper using open-vocabulary keyword-spotting,” inLREC-COLING, 2024
2024
-
[18]
Adding User Feedback To Enhance CB-Whisper,
R. Monteiro, “Adding User Feedback To Enhance CB-Whisper,” inInterspeech, 2024
2024
-
[19]
Matching Latent Encoding for Audio-Text based Keyword Spotting,
K. Nishu, M. Cho, and D. Naik, “Matching Latent Encoding for Audio-Text based Keyword Spotting,” inInterspeech, 2023
2023
-
[20]
Learning audio-text agreement for open-vocabulary keyword spotting,
H.-K. Shin, H. Han, D. Kim, S.-W. Chung, and H.-G. Kang, “Learning audio-text agreement for open-vocabulary keyword spotting,” inInterspeech, 2022
2022
-
[21]
Failing forward: Improving generative error correction for asr with synthetic data and retrieval augmentation,
S. Ghosh, M. S. Rasooli, M. Levit, P. Wang, J. Xue, D. Manocha, and J. Li, “Failing forward: Improving generative error correction for asr with synthetic data and retrieval augmentation,” inACL, 2025
2025
-
[22]
From softmax to sparsemax: A sparse model of attention and multi-label classification,
A. Martins and R. Astudillo, “From softmax to sparsemax: A sparse model of attention and multi-label classification,” inICML, 2016
2016
-
[23]
MLS: A Large-Scale Multilingual Dataset for Speech Research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A Large-Scale Multilingual Dataset for Speech Research,” inInterspeech, 2020
2020
-
[24]
spaCy: Industrial-strength NLP, “spaCy,” https://spacy.io/models, accessed: 2026-02-28
2026
-
[25]
edge-tts,
Rany, “edge-tts,” https://github.com/rany2/edge-tts, accessed: 2026-02-22
2026
-
[26]
AIShell-1: An open- source mandarin speech corpus and a speech recognition base- line,
H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “AIShell-1: An open- source mandarin speech corpus and a speech recognition base- line,” inO-COCOSDA, 2017
2017
-
[27]
Evaluating multilingual speech translation under realistic conditions with resegmentation and terminology,
E. Salesky, K. Darwish, M. Al-Badrashiny, M. Diab, and J. Niehues, “Evaluating multilingual speech translation under realistic conditions with resegmentation and terminology,” in IWSLT, 2023
2023
-
[28]
Cat ´alogos sem ˆanticos da sa ´ude (seman- tic health catalogues),
P. M. of Health, “Cat ´alogos sem ˆanticos da sa ´ude (seman- tic health catalogues),” https://www.ctc.min-saude.pt/category/ catalogos/, 2022, accessed: 2026-02-21
2022
-
[29]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inIEEE conference on Computer Vision and Pattern Recognition, 2016
2016
-
[30]
WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,”Inter- speech, 2023
2023
-
[31]
Confidence intervals for evaluation in ma- chine learning,
L. Ferrer and P. Riera, “Confidence intervals for evaluation in ma- chine learning,” https://github.com/luferrer/ConfidenceIntervals, accessed: 2026-02-22
2026
-
[32]
A general method applicable to the search for similarities in the amino acid sequence of two proteins,
S. B. Needleman and C. D. Wunsch, “A general method applicable to the search for similarities in the amino acid sequence of two proteins,”Journal of molecular biology, vol. 48, no. 3, pp. 443– 453, 1970
1970
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.