Annealed Entropic Allocation for Ranking and Selection
Pith reviewed 2026-06-29 05:08 UTC · model grok-4.3
The pith
Annealed entropic allocation replaces the hard maximin large-deviation objective with an annealed weighted soft-min surrogate for smoother adaptive sampling in ranking and selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose annealed entropic allocation, an adaptive sampling policy based on an annealed, weighted soft-min formulation of static budget allocation. We replace the maximin large-deviation rate objective with a weighted log-sum-exp surrogate that blends challenger-specific pairwise scores through soft-min weights, avoiding hard switching when several challengers are nearly active. To capture tail behavior beyond the leading exponent, the surrogate incorporates saddlepoint prefactors from refined pairwise tail asymptotics. Because these corrections are subexponential, decreasing the annealing temperature with the budget preserves the same first-order target allocation. For the static problem,
What carries the argument
the annealed weighted soft-min (log-sum-exp) surrogate that blends pairwise large-deviation scores with saddlepoint prefactors to produce a continuous target-allocation map
If this is right
- Soft-min weights concentrate on active challengers as the annealing temperature decreases.
- The induced target-allocation map remains continuous when the weights are held fixed.
- Uniform convergence of the surrogate to the hard minimum holds for the static allocation problem.
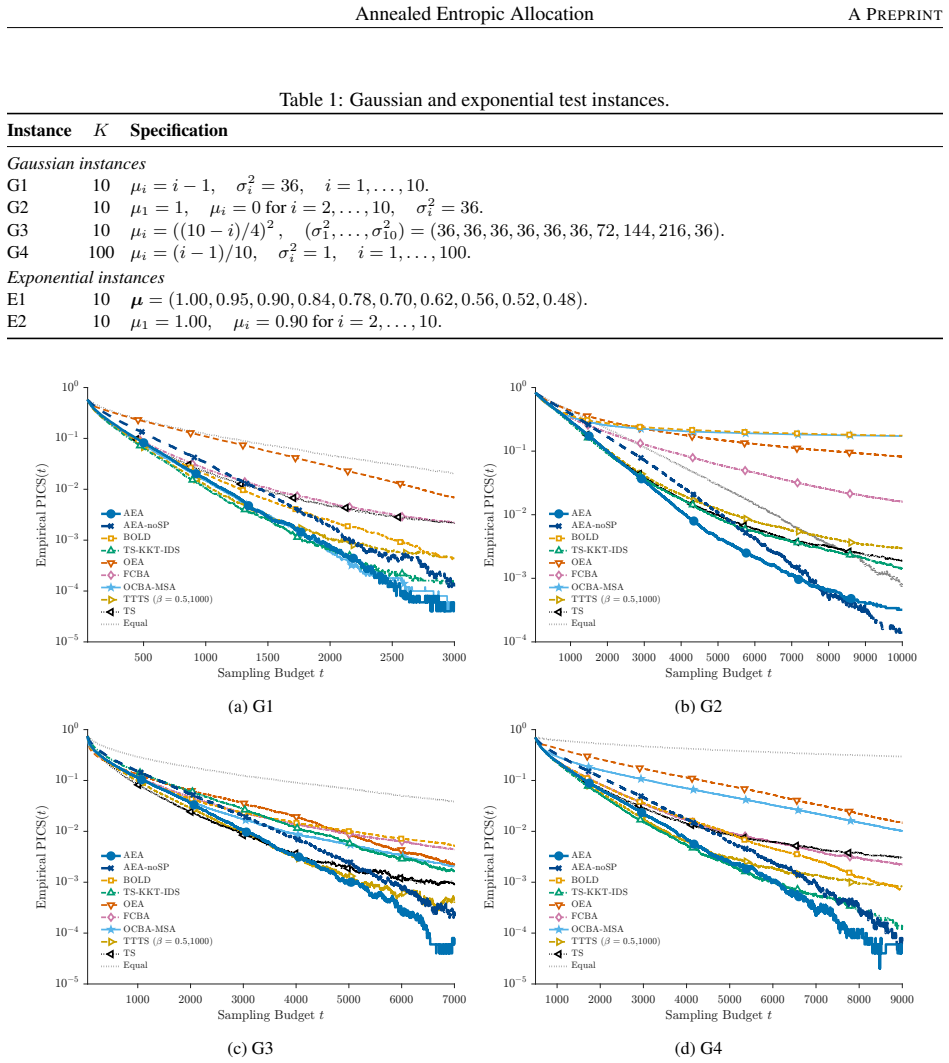
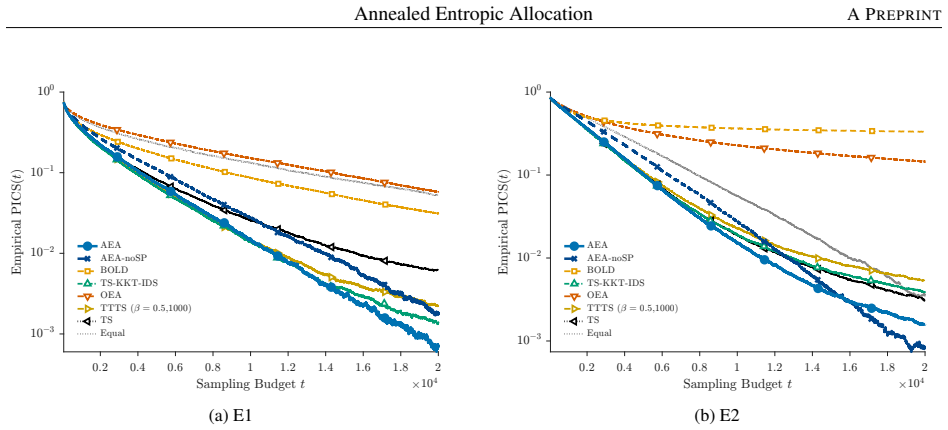
- The no-saddlepoint ablation is strongest in symmetric Gaussian and exponential slippage settings.
- Including saddlepoint weighting improves performance when the problem is heterogeneous or asymmetric.
Where Pith is reading between the lines
- The continuity of the allocation map under fixed weights may support stable implementations when the set of challengers changes over time.
- Because the first-order allocation is preserved under annealing, the same policy could be applied to problems with slowly varying budgets without recalibrating the target.
- The subexponential correction property suggests the framework could extend to other tail approximations beyond saddlepoint without altering the leading allocation.
Load-bearing premise
The saddlepoint prefactors are subexponential, so lowering the annealing temperature with growing budget leaves the first-order target allocation unchanged.
What would settle it
A static-problem simulation in which soft-min weights fail to concentrate on the active challengers as the temperature is lowered would disprove the claimed concentration and convergence.
Figures
read the original abstract
We propose annealed entropic allocation, an adaptive sampling policy based on an annealed, weighted soft-min formulation of static budget allocation. We replace the maximin large-deviation rate objective with a weighted log-sum-exp surrogate that blends challenger-specific pairwise scores through soft-min weights, avoiding hard switching when several challengers are nearly active. To capture tail behavior beyond the leading exponent, the surrogate incorporates saddlepoint prefactors from refined pairwise tail asymptotics. Because these corrections are subexponential, decreasing the annealing temperature with the budget preserves the same first-order target allocation. For the static problem, we prove uniform convergence to the hard minimum, concentration of soft-min weights on active challengers, and continuity of the induced target-allocation map under fixed weights. Experiments show that the proposed methods are consistently competitive: the no-saddlepoint ablation performs best in symmetric Gaussian and exponential slippage settings, while saddlepoint weighting can help in heterogeneous or asymmetric cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes annealed entropic allocation, an adaptive sampling policy for ranking and selection that replaces the maximin large-deviation rate objective with an annealed, weighted log-sum-exp surrogate blending challenger-specific pairwise scores via soft-min weights and incorporating saddlepoint prefactors from refined tail asymptotics. For the static problem with fixed weights the authors prove uniform convergence to the hard minimum, concentration of soft-min weights on active challengers, and continuity of the induced target-allocation map. They assert that because the saddlepoint corrections are subexponential, decreasing the annealing temperature with the budget preserves the same first-order target allocation. Experiments indicate the methods are consistently competitive, with the no-saddlepoint ablation strongest in symmetric Gaussian and exponential slippage settings.
Significance. If the adaptive extension holds, the approach could supply a theoretically grounded, smooth alternative to hard-switching allocation rules that handles near-active challengers without abrupt changes. The static-case proofs and use of refined asymptotics constitute concrete strengths.
major comments (1)
- [Abstract] Abstract: the central justification for the adaptive policy—that 'because these corrections are subexponential, decreasing the annealing temperature with the budget preserves the same first-order target allocation'—is asserted without an explicit rate, bound, or argument showing the subexponential remainder remains negligible under the joint limit of temperature decreasing with total budget. The listed proofs (uniform convergence to the hard minimum, concentration of soft-min weights, continuity of the allocation map) are stated to apply only to the static problem with fixed weights.
minor comments (1)
- The abstract states that experiments show competitive performance but supplies no information on the number of replications, error bars, or specific baselines; a brief reference to the relevant tables or figures would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the positive aspects of the static-case analysis. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central justification for the adaptive policy—that 'because these corrections are subexponential, decreasing the annealing temperature with the budget preserves the same first-order target allocation'—is asserted without an explicit rate, bound, or argument showing the subexponential remainder remains negligible under the joint limit of temperature decreasing with total budget. The listed proofs (uniform convergence to the hard minimum, concentration of soft-min weights, continuity of the allocation map) are stated to apply only to the static problem with fixed weights.
Authors: We agree that the abstract asserts preservation of the first-order target allocation for the adaptive policy without supplying an explicit rate or bound on the joint limit (temperature decreasing with budget) and that the listed proofs apply only to the static problem. In the revised manuscript we will qualify the relevant sentence in the abstract and insert a short remark in Section 3 clarifying that the adaptive policy is motivated heuristically by the subexponential character of the saddlepoint corrections together with the static convergence results; a rigorous treatment of the joint limit is left for future work. This change makes the scope of the current claims explicit. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper derives its annealed entropic allocation from a weighted soft-min surrogate of the maximin large-deviation objective, augmented by saddlepoint prefactors, then proves uniform convergence to the hard minimum, soft-min concentration, and continuity of the allocation map for the static fixed-weight case. The adaptive extension rests on the separate assertion that subexponential corrections remain negligible under a decreasing temperature schedule; this assertion is not shown to be equivalent to the input by construction, nor does any step reduce via self-definition, fitted-parameter renaming, or load-bearing self-citation. The listed proofs are independent of the target adaptive result, satisfying the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi:10.1145/502109.502111. Stephen E. Chick and Koichiro Inoue. New Two-Stage and Sequential Procedures for Selecting the Best Simulated System.Operations Research, 49(5):732–743,
-
[2]
doi:10.1287/opre.49.5.732.10615. Stephen E. Chick, Jürgen Branke, and Christian Schmidt. Sequential sampling to myopically maximize the expected value of information.INFORMS Journal on Computing, 22(1):71–80,
-
[3]
doi:10.1287/ijoc.1090.0327. Peter I. Frazier, Warren B. Powell, and Savas Dayanik. A knowledge-gradient policy for sequential information collection.SIAM Journal on Control and Optimization, 47(5):2410–2439,
-
[4]
doi:10.1137/070693424. Chun-Hung Chen and Loo Hay Lee.Stochastic Simulation Optimization: An Optimal Computing Budget Allocation. World Scientific, Singapore,
-
[5]
doi:10.1142/7437. P. Glynn and S. Juneja. A large deviations perspective on ordinal optimization. In2004 Winter Simulation Conference, page 585,
-
[6]
Siyang Gao, Weiwei Chen, and Leyuan Shi
doi:10.1109/WSC.2004.1371364. Siyang Gao, Weiwei Chen, and Leyuan Shi. A new budget allocation framework for the expected opportunity cost. Operations Research, 65(3):787–803, June
-
[7]
Xinbo Shi, Yijie Peng, and Bruno Tuffin
doi:10.1287/opre.2016.1581. Xinbo Shi, Yijie Peng, and Bruno Tuffin. Finite budget allocation improvement in ranking and selection. In2024 Winter Simulation Conference, pages 477–488,
-
[8]
doi:10.1109/WSC63780.2024.10838856. Ye Chen and Ilya O. Ryzhov. Balancing optimal large deviations in sequential selection.Management Science, 69(6): 3457–3473,
-
[9]
doi:10.1287/mnsc.2022.4527. Chao Qin and Wei You. Dual-directed algorithm design for efficient pure exploration.Operations Research, 0(0):1–24,
-
[10]
11 Annealed Entropic AllocationA PREPRINT Xinyu Liu, Chao Qin, and Wei You
doi:10.1287/opre.2023.0590. 11 Annealed Entropic AllocationA PREPRINT Xinyu Liu, Chao Qin, and Wei You. Pure exploration via frank-wolfe self-play,
-
[11]
Amir Dembo and Ofer Zeitouni.Large Deviations Techniques and Applications
URL https://arxiv.org/ abs/2509.19901. Amir Dembo and Ofer Zeitouni.Large Deviations Techniques and Applications. Stochastic Modelling and Applied Probability. Springer Berlin Heidelberg,
-
[12]
ISBN 9783642033117. doi:10.1007/978-3-642-03311-7. Daniel Russo. Simple Bayesian algorithms for best-arm identification.Operations Research, 68(6):1625–1647,
-
[13]
doi:10.1287/opre.2019.1911. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.