Hubs or Fringes: Pretraining Data Selection via Web Graph Centrality
Pith reviewed 2026-06-27 12:55 UTC · model grok-4.3
The pith
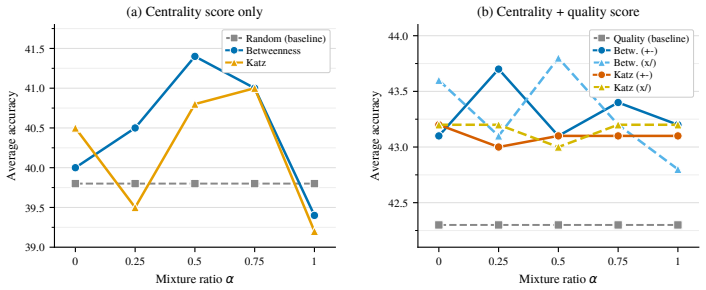
Mixing central and peripheral web hosts in pretraining data improves average performance to 41.4 percent across 23 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Central hosts in the web graph expose models to reusable abstractions while peripheral hosts supply specialized long-tail knowledge, and a balanced mixture of the two regions produces higher average performance on downstream tasks than uniform sampling from the full crawl.
What carries the argument
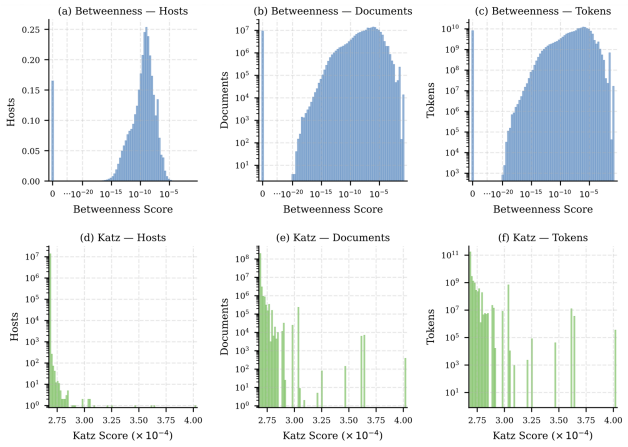
WebGraphMix, a framework that assigns structural centrality scores to hosts in the Common Crawl graph and uses those scores to set the sampling ratio between central and peripheral documents.
If this is right
- Central and peripheral regions encode complementary capabilities that combine to raise performance.
- A 1:1 mixture reaches 41.4 percent average accuracy compared with 39.8 percent for uniform sampling.
- Layering graph centrality on top of document-level quality classifiers produces a further gain to 43.8 percent.
- The method runs at web scale with no extra model training or downstream labels.
- The same approach works inside the DataComp-LM pipeline at both 400M and 1B parameter scales.
Where Pith is reading between the lines
- The same graph-based ratio could be applied to other large crawls whose host structure is already known.
- Future pipelines might treat graph position as one of several independent axes when constructing mixtures.
- If the orthogonality holds, adding more structural signals such as link patterns or domain age could yield additional gains.
- The finding suggests testing whether the optimal central-to-peripheral ratio changes with model size or total token count.
Load-bearing premise
Centrality scores on the host-level Common Crawl graph separate reusable abstractions from specialized knowledge in a way that improves training and is not already captured by content quality filters.
What would settle it
Train models at the same scale using only central hosts or only peripheral hosts and measure whether the average score across the 23 tasks drops below the uniform-sampling baseline of 39.8 percent.
Figures

read the original abstract
The performance of modern language models depends critically on pretraining data composition. Yet existing data selection methods rely on auxiliary classifiers for document scoring or mixture optimization, adding computational overhead and dependence on labeled data. We propose WebGraphMix, a lightweight data selection framework that computes structural centrality scores over the Common Crawl host-level web graph and uses them to vary the proportion of central versus peripheral documents in the pretraining mixture. We hypothesize that central hosts expose models to reusable abstractions, while peripheral hosts encode specialized, long-tail knowledge. WebGraphMix computes centrality scores efficiently at web scale, requiring no model training, labeled data, or downstream supervision. We integrate WebGraphMix into the DataComp-LM pipeline and train models at 400M and 1B parameter scales with 8B and 28B tokens respectively, evaluating on 23 tasks ranging from factual knowledge to symbolic reasoning. Our experiments show that central and peripheral web regions encode complementary capabilities. Mixture combining both at a ratio of 1:1 achieves 41.4% on average, compared to 39.8% for uniform sampling. Combining structural scores with document-level quality classifier scores further improves performance to 43.8%. These findings demonstrate that web graph topology is a meaningful axis for pretraining data curation, capturing information that is largely orthogonal to existing content-based approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WebGraphMix, a lightweight framework that computes host-level centrality scores on the Common Crawl web graph to curate pretraining mixtures, hypothesizing that central hosts provide reusable abstractions while peripheral hosts supply specialized long-tail knowledge. It integrates this into the DataComp-LM pipeline and reports that a 1:1 central-peripheral mixture achieves 41.4% average performance on 23 tasks (vs. 39.8% for uniform sampling) at 400M and 1B scales with 8B/28B tokens; combining with quality classifiers further reaches 43.8%. The work claims this structural signal is largely orthogonal to content-based quality methods and requires no labeled data or model training.
Significance. If the gains prove robust, the approach supplies a scalable, label-free axis for data selection that exploits web topology, which could complement existing quality filters and reduce reliance on supervised classifiers. The multi-scale evaluation on 23 tasks spanning knowledge and reasoning provides a concrete empirical signal, though the lack of direct content verification leaves the hypothesized mechanism open to alternative explanations such as diversity or duplication effects.
major comments (3)
- [§4] §4 (Experiments): The reported averages (41.4% vs. 39.8%) are given without error bars, standard deviations, or results from multiple random seeds, so it is impossible to determine whether the 2.6-point gain is statistically reliable or sensitive to sampling variance.
- [§3, §5] §3 (Method) and §5 (Analysis): No direct measurements of document properties (topic entropy, abstraction level, duplication rate, or length statistics) across centrality strata are reported, leaving the core claim that central vs. peripheral hosts encode complementary reusable vs. specialized content unverified and open to alternative accounts such as simple diversity increase.
- [§4.2] §4.2 (Mixture ratios): The 1:1 central-to-peripheral ratio is presented without ablation across other ratios or justification for why it is optimal; the free parameter therefore remains unexamined, weakening the claim that the structural signal itself drives the improvement.
minor comments (2)
- [Abstract, §3] The abstract and §3 should specify the exact centrality measure (e.g., PageRank, degree) and any normalization applied to the host graph, as these details are required for reproducibility.
- [§4] Table or figure presenting per-task breakdowns would help clarify whether gains are concentrated in particular capability types (factual vs. reasoning) rather than uniform.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical reporting, mechanistic evidence, and experimental controls. We address each major comment below.
read point-by-point responses
-
Referee: [§4] The reported averages (41.4% vs. 39.8%) are given without error bars, standard deviations, or results from multiple random seeds, so it is impossible to determine whether the 2.6-point gain is statistically reliable or sensitive to sampling variance.
Authors: We agree that variance estimates are necessary to establish reliability. In the revised manuscript we will report results from at least three independent random seeds for the main 400M and 1B experiments, together with standard deviations and error bars on the 23-task averages. revision: yes
-
Referee: [§3, §5] No direct measurements of document properties (topic entropy, abstraction level, duplication rate, or length statistics) across centrality strata are reported, leaving the core claim that central vs. peripheral hosts encode complementary reusable vs. specialized content unverified and open to alternative accounts such as simple diversity increase.
Authors: We acknowledge that direct content-level verification would strengthen the mechanistic interpretation. While downstream gains and the additive benefit when combined with quality classifiers already indicate orthogonality, we will add to §5 a quantitative comparison of document length, MinHash duplication rate, and LDA topic entropy across centrality bins. revision: yes
-
Referee: [§4.2] The 1:1 central-to-peripheral ratio is presented without ablation across other ratios or justification for why it is optimal; the free parameter therefore remains unexamined, weakening the claim that the structural signal itself drives the improvement.
Authors: The 1:1 ratio was selected after limited pilot runs; we agree a systematic sweep is required. The revision will include an ablation of central:peripheral ratios (0:1, 1:3, 1:1, 3:1, 1:0) evaluated on a held-out subset of tasks to confirm the contribution of the structural signal. revision: yes
Circularity Check
No circularity; empirical method with independent graph computation and task evaluation
full rationale
The paper computes host-level centrality scores on the external Common Crawl web graph, hypothesizes a content distinction, and reports measured downstream performance for empirically chosen mixtures (e.g., 1:1 ratio at 41.4% vs. uniform 39.8%). No equation or claim reduces by construction to its own inputs; centrality is not defined via the target capabilities, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation chain appears. The derivation chain is self-contained against external graph data and task benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- central-to-peripheral ratio
axioms (1)
- domain assumption Host-level centrality on the Common Crawl web graph separates reusable abstractions from long-tail specialized knowledge.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
The fineweb datasets: Decanting the web for the finest text data at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Advances in Neural Information Processing Systems , volume=
Datacomp-lm: In search of the next generation of training sets for language models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author =. arXiv preprint arXiv:2001.08361 , year =. doi:10.48550/arXiv.2001.08361 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[4]
M., Longpre, S., Lambert, N., Wang, X., Muennighoff, N., Hou, B., Pan, L., Jeong, H., et al
A Survey on Data Selection for Language Models , author =. arXiv preprint arXiv:2402.16827 , year =. doi:10.48550/arXiv.2402.16827 , url =
-
[5]
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year =. doi:10.48550/arXiv.2402.00159 , url =
-
[6]
2024 , doi =
Wettig, Alexander and Gupta, Aatmik and Malik, Saumya and Chen, Danqi , booktitle =. 2024 , doi =
2024
-
[7]
Organize the Web: Constructing Domains Enhances Pre-Training Data Curation , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =. doi:10.48550/arXiv.2502.10341 , url =
-
[8]
Longpre, Shayne and Yauney, Gregory and Reif, Emily and Lee, Katherine and Roberts, Adam and Zoph, Barret and Zhou, Denny and Wei, Jason and Robinson, Kevin and Mimno, David and Ippolito, Daphne. A Pretrainer ' s Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity. Proceedings of the 2024 Conference of the North...
-
[9]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[10]
arXiv preprint arXiv:2112.11446 , year=
Scaling language models: Methods, analysis & insights from training gopher , author=. arXiv preprint arXiv:2112.11446 , year=
-
[11]
The RefinedWeb Dataset for Falcon
Guilherme Penedo and Quentin Malartic and Daniel Hesslow and Ruxandra Cojocaru and Hamza Alobeidli and Alessandro Cappelli and Baptiste Pannier and Ebtesam Almazrouei and Julien Launay , booktitle=. The RefinedWeb Dataset for Falcon. 2023 , url=
2023
-
[12]
Proceedings
On the resemblance and containment of documents , author=. Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171) , year=
1997
-
[13]
Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-Burch, C., and Carlini, N
Lee, Katherine and Ippolito, Daphne and Nystrom, Andrew and Zhang, Chiyuan and Eck, Douglas and Callison-Burch, Chris and Carlini, Nicholas. Deduplicating Training Data Makes Language Models Better. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.577
-
[14]
Chi and James Caverlee and Julian McAuley and Derek Zhiyuan Cheng , booktitle=
Noveen Sachdeva and Benjamin Coleman and Wang-Cheng Kang and Jianmo Ni and Lichan Hong and Ed H. Chi and James Caverlee and Julian McAuley and Derek Zhiyuan Cheng , booktitle=. How to train data-efficient. 2026 , url=
2026
-
[15]
arXiv preprint arXiv:2507.12466 , year=
Language models improve when pretraining data matches target tasks , author=. arXiv preprint arXiv:2507.12466 , year=
-
[16]
CCN et: Extracting High Quality Monolingual Datasets from Web Crawl Data
Wenzek, Guillaume and Lachaux, Marie-Anne and Conneau, Alexis and Chaudhary, Vishrav and Guzm \'a n, Francisco and Joulin, Armand and Grave, Edouard. CCN et: Extracting High Quality Monolingual Datasets from Web Crawl Data. Proceedings of the Twelfth Language Resources and Evaluation Conference. 2020
2020
-
[17]
Thirty-seventh Conference on Neural Information Processing Systems , year=
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[18]
arXiv preprint arXiv:2505.07293 , year=
Attentioninfluence: Adopting attention head influence for weak-to-strong pretraining data selection , author=. arXiv preprint arXiv:2505.07293 , year=
-
[19]
The Thirteenth International Conference on Learning Representations , year=
Aioli: A Unified Optimization Framework for Language Model Data Mixing , author=. The Thirteenth International Conference on Learning Representations , year=
-
[20]
Nemotron-
Shizhe Diao and Yu Yang and Yonggan Fu and Xin Dong and Dan SU and Markus Kliegl and ZIJIA CHEN and Peter Belcak and Yoshi Suhara and Hongxu Yin and Mostofa Patwary and Yingyan Celine Lin and Jan Kautz and Pavlo Molchanov , booktitle=. Nemotron-. 2026 , url=
2026
-
[21]
arXiv preprint arXiv:2508.17677 , year=
TiKMiX: Take Data Influence into Dynamic Mixture for Language Model Pre-training , author=. arXiv preprint arXiv:2508.17677 , year=
-
[22]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Group-Level Data Selection for Efficient Pretraining , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
Forty-second International Conference on Machine Learning , year=
Metadata Conditioning Accelerates Language Model Pre-training , author=. Forty-second International Conference on Machine Learning , year=
-
[24]
1999 , institution =
Page, Lawrence and Brin, Sergey and Motwani, Rajeev and Winograd, Terry , title =. 1999 , institution =
1999
-
[25]
Journal of the ACM , volume =
Authoritative Sources in a Hyperlinked Environment , author =. Journal of the ACM , volume =. 1999 , publisher =
1999
-
[26]
C raw4 LLM : Efficient Web Crawling for LLM Pretraining
Yu, Shi and Liu, Zhiyuan and Xiong, Chenyan. C raw4 LLM : Efficient Web Crawling for LLM Pretraining. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.712
-
[27]
Internet Mathematics , volume=
Axioms for centrality , author=. Internet Mathematics , volume=. 2014 , publisher=
2014
-
[28]
Baack, Stefan , title =. 2024 , isbn =. doi:10.1145/3630106.3659033 , booktitle =
-
[29]
Journal of Mathematical Sociology , volume =
A Faster Algorithm for Betweenness Centrality , author =. Journal of Mathematical Sociology , volume =. 2001 , publisher =
2001
-
[30]
2024 , howpublished =
2024
-
[31]
arXiv preprint arXiv:2201.05469 , year=
PageRank Algorithm using Eigenvector Centrality--New Approach , author=. arXiv preprint arXiv:2201.05469 , year=
-
[32]
The Thirteenth International Conference on Learning Representations , year=
RegMix: Data Mixture as Regression for Language Model Pre-training , author=. The Thirteenth International Conference on Learning Representations , year=
-
[33]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author =. arXiv preprint arXiv:2203.15556 , year =. doi:10.48550/arXiv.2203.15556 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.15556
-
[34]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Skill-it! A data-driven skills framework for understanding and training language models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[35]
International Conference on Machine Learning , pages=
DOGE: Domain Reweighting with Generalization Estimation , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[36]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[37]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[38]
arXiv preprint arXiv:2306.11644 , year=
Textbooks are all you need , author=. arXiv preprint arXiv:2306.11644 , year=
-
[39]
Freeman , journal =
Linton C. Freeman , journal =. A Set of Measures of Centrality Based on Betweenness , urldate =
-
[40]
A New Status Index Derived from Sociometric Analysis , volume=. Psychometrika , author=. 1953 , pages=. doi:10.1007/BF02289026 , number=
-
[41]
Foster, Kurt C. and Muth, Stephen Q. and Potterat, John J. and Rothenberg, Richard B. , title =. Computational & Mathematical Organization Theory , year =. doi:10.1023/A:1013470632383 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.