Wavelet-Based Extraction of Transient Noise in Gravitational-Wave Interferometers using a Saliency-Guided Learning Architecture
Pith reviewed 2026-06-27 08:39 UTC · model grok-4.3
The pith
A saliency-guided transfer from continuous to discrete wavelet transforms extracts and reconstructs transient glitches in gravitational-wave data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that saliency patterns learned on continuous wavelet transform spectrograms can be transferred to an invertible discrete wavelet transform representation, where adaptive coefficient masking yields exact reconstruction of both glitch-only and glitch-suppressed waveforms across multiple glitch families and in regimes where classical methods fail.
What carries the argument
Saliency-guided transfer between continuous and discrete wavelet transforms followed by adaptive coefficient masking in the discrete basis.
If this is right
- Exact glitch subtraction becomes possible without residual leakage into the cleaned strain.
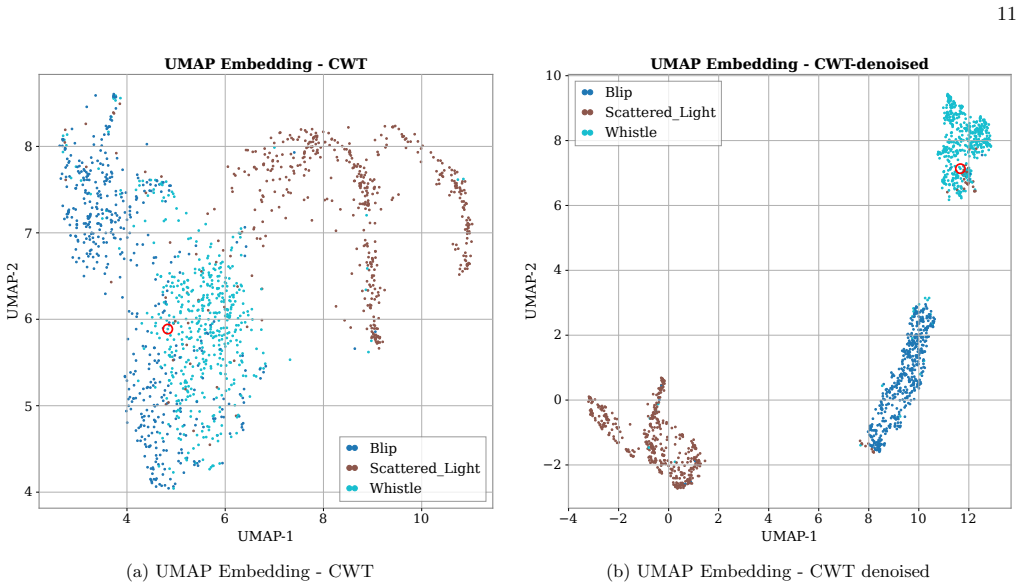
- The same saliency maps can serve as diagnostics for learned representations via UMAP.
- The method scales to larger glitch catalogs because it avoids non-invertible operations after the saliency step.
- Low signal-to-noise and partially overlapping transients can be handled without the failures typical of thresholding or band-limited filters.
Where Pith is reading between the lines
- The framework could be extended to real-time subtraction pipelines if the discrete-wavelet masking step is made sufficiently fast.
- Because the reconstruction is exact, the extracted glitches could be used directly as training targets for future morphology classifiers without additional denoising.
- The approach may generalize to other non-stationary noise sources in interferometric data if the saliency model is retrained on new families.
Load-bearing premise
Saliency patterns identified on continuous wavelet transform spectrograms transfer to the discrete wavelet transform without introducing significant artifacts or information loss that would prevent exact reconstruction.
What would settle it
Apply the pipeline to a set of low signal-to-noise overlapping whistle and scattered-light glitches and measure whether the reconstructed glitch-only waveform matches the injected transient to within the noise floor after subtraction.
Figures
read the original abstract
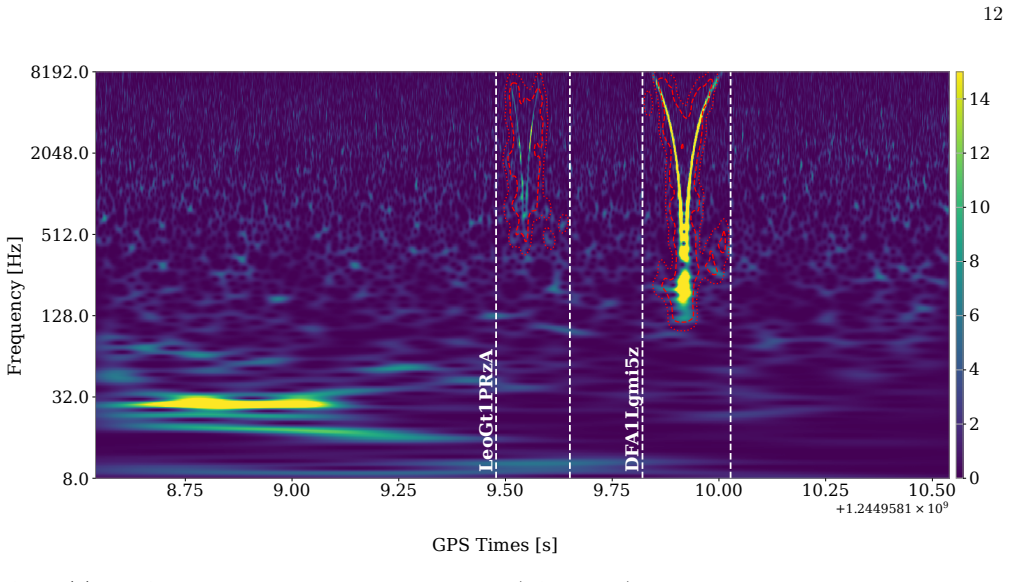
Gravitational-wave interferometers exhibit a wide variety of short-duration non-Gaussian transients, commonly referred to as glitches, that complicate the detection of astrophysical signals, bias parameter estimation, and detector characterisation. Existing machine-learning approaches classify glitch morphologies but do not provide a complete mechanism to segment and extract these disturbances from the strain data. We introduce a wavelet-based, saliency-guided framework for the supervised extraction of transient noise. Candidates are first pre-tagged using Uniform Manifold Approximation and Projection, which is also used as a diagnostic of the learned representations. A traditional learning model operating on Continuous Wavelet Transform spectrograms then identifies relevant time-frequency regions through saliency maps. These saliency patterns are transferred to an invertible multiresolution representation via the Discrete Wavelet Transform, where adaptive coefficient masking enables exact reconstruction of both glitch-only and glitch-suppressed waveforms. We demonstrate effective extraction across several representative glitch families, including 'Whistle' and 'Scattered-Light' transients, and show robustness in challenging regimes such as low signal-to-noise events and partially overlapping structures, where classical thresholding or band-limited filtering methods typically fail or introduce leakage. The proposed framework offers an interpretable and computationally efficient approach to transient-noise extraction, establishing a foundation for scalable applications to larger glitch catalogs and future observing runs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a wavelet-based saliency-guided supervised framework for extracting transient glitches from gravitational-wave strain data. Candidates are pre-tagged with UMAP; saliency maps on CWT spectrograms identify time-frequency regions; these patterns are transferred to an invertible DWT representation for adaptive coefficient masking, enabling claimed exact reconstruction of glitch-only and glitch-suppressed waveforms. The method is demonstrated on representative families such as 'Whistle' and 'Scattered-Light' transients and asserted to be robust in low-SNR and overlapping regimes where classical methods fail.
Significance. If the central extraction claims hold after validation, the framework would supply an interpretable, computationally efficient alternative to existing glitch-classification ML methods, with potential utility for improving strain data quality ahead of future observing runs. The use of UMAP as both pre-tagger and diagnostic is a positive design choice.
major comments (2)
- [Abstract] Abstract (pipeline description): The claim of 'exact reconstruction of both glitch-only and glitch-suppressed waveforms' rests on transfer of saliency patterns from CWT spectrograms to DWT coefficient masks, yet no transfer operator, interpolation rule, or invertibility proof is supplied. Because CWT is redundant while DWT is critically sampled, any non-bijective mapping risks support misalignment and leakage into the cleaned strain; this step is load-bearing for the extraction guarantee but remains undescribed.
- [Abstract] Abstract: The assertions of 'effective extraction across several representative glitch families' and 'robustness in challenging regimes such as low signal-to-noise events and partially overlapping structures' are presented without any quantitative metrics, error bars, baseline comparisons (e.g., against wavelet thresholding or existing ML denoisers), or cross-validation details. The central claim of superiority therefore cannot be assessed from the supplied information.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the manuscript to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (pipeline description): The claim of 'exact reconstruction of both glitch-only and glitch-suppressed waveforms' rests on transfer of saliency patterns from CWT spectrograms to DWT coefficient masks, yet no transfer operator, interpolation rule, or invertibility proof is supplied. Because CWT is redundant while DWT is critically sampled, any non-bijective mapping risks support misalignment and leakage into the cleaned strain; this step is load-bearing for the extraction guarantee but remains undescribed.
Authors: We agree that the abstract does not describe the transfer operator, interpolation rule, or invertibility argument. The manuscript body outlines the overall pipeline but does not provide the explicit mapping details or proof. We will add a dedicated subsection to the Methods section that formalizes the saliency-to-DWT mask transfer (including the mathematical operator and any interpolation), along with a discussion of exact reconstruction under adaptive masking and the conditions under which support misalignment is avoided. revision: yes
-
Referee: [Abstract] Abstract: The assertions of 'effective extraction across several representative glitch families' and 'robustness in challenging regimes such as low signal-to-noise events and partially overlapping structures' are presented without any quantitative metrics, error bars, baseline comparisons (e.g., against wavelet thresholding or existing ML denoisers), or cross-validation details. The central claim of superiority therefore cannot be assessed from the supplied information.
Authors: The abstract is a high-level summary and does not include quantitative metrics. The manuscript demonstrates the method on Whistle and Scattered-Light families with qualitative examples but lacks the requested quantitative metrics, error bars, baselines, and cross-validation details in the results. We will revise the abstract to include key quantitative results and expand the Results section with explicit metrics (e.g., suppression ratios, reconstruction errors), baseline comparisons to wavelet thresholding, error bars, and cross-validation details to support the claims. revision: yes
Circularity Check
No significant circularity; pipeline is self-contained methodological proposal
full rationale
The paper introduces a new supervised extraction framework combining UMAP pre-tagging, saliency mapping on CWT spectrograms, and transfer to invertible DWT for coefficient masking. No equations, fitted parameters, or self-citations are presented that reduce any claimed performance or reconstruction guarantee to a self-referential definition or input. The derivation chain consists of independent algorithmic steps whose validity rests on empirical demonstration rather than tautology. The transfer operator between CWT saliency and DWT masks is described as part of the method but is not shown to be equivalent to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
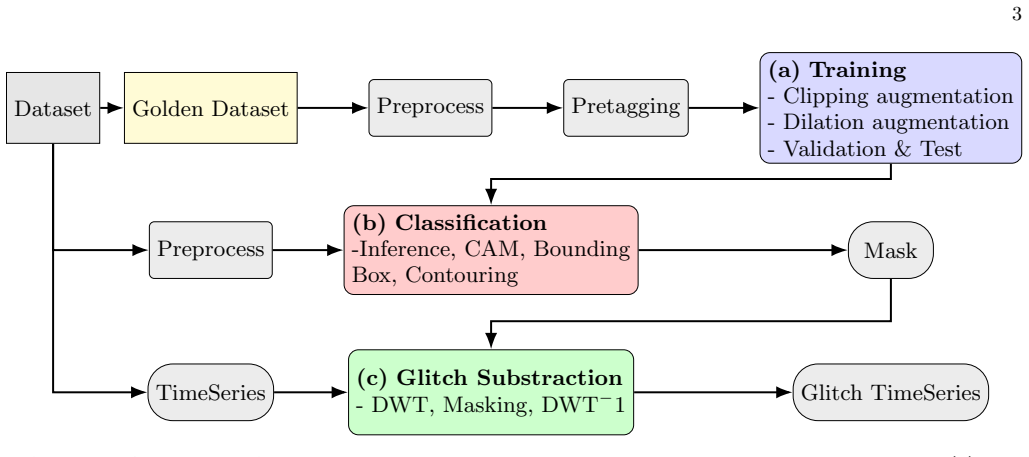
Q-Transform representation The primary representation used by Omicron is the Q-transform, evaluated around trigger times and imple- mented inGWpy. For a strain time seriesx(t), the Q- 3 Dataset Golden Dataset Preprocess Pretagging (a) Training - Clipping augmentation - Dilation augmentation - Validation & Test Preprocess (b) Classification -Inference, CAM...
-
[2]
The CWT of a signalx(t) is defined as Wx(a, b) = 1 |a| 1 p Z +∞ −∞ x(t)ψ ∗ t−b a dt,(2) whereaandbdenote the scale and time shift, respec- tively, andψis the chosen mother wavelet
Continuous Wavelet Transform representation Wavelet-based representations provide a complemen- tary description of transient structures through localized decompositions across multiple scales. The CWT of a signalx(t) is defined as Wx(a, b) = 1 |a| 1 p Z +∞ −∞ x(t)ψ ∗ t−b a dt,(2) whereaandbdenote the scale and time shift, respec- tively, andψis the chosen...
-
[3]
The model used in this study is based on aResNet-50 architecture[30] withImageNet-pretrained weights[31], imposing a fixed input size of 224×224 pixels
Learning architecture and Pre-tagging. The model used in this study is based on aResNet-50 architecture[30] withImageNet-pretrained weights[31], imposing a fixed input size of 224×224 pixels. The network begins with an initial convolutional block con- sisting of a 7×7 convolution, batch normalisation, ReLU activation, and a 3×3 max-pooling layer. It is fo...
2048
-
[4]
During training, we vary the clipping threshold of the spectrogram amplitudes by a value randomly drawn from a uniform distribution over the interval [3,23]
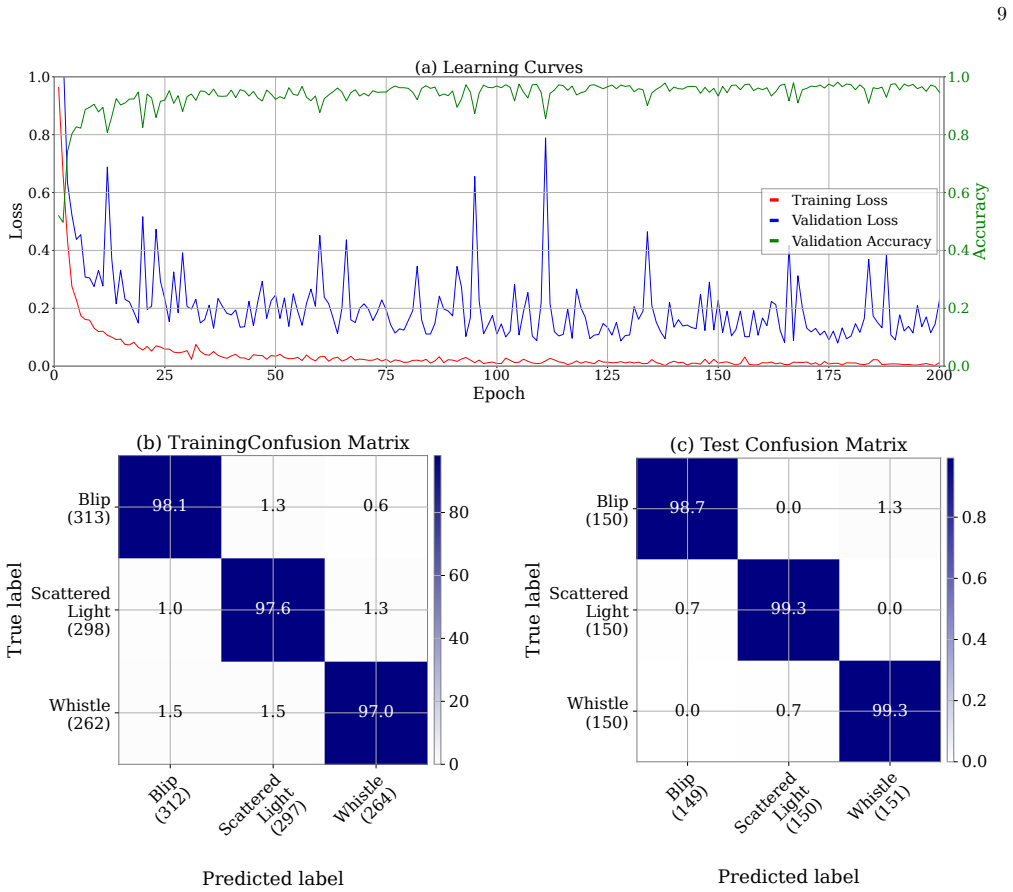
Training The training dataset consists of a balanced sample of 4,500 Gravity Spy glitches drawn from three rep- resentative morphologies:Whistle,Blip, andScattered LightThe dataset is split into training, validation, and test subsets with proportions of 70%, 20%, and 10%, respectively. During training, we vary the clipping threshold of the spectrogram amp...
-
[5]
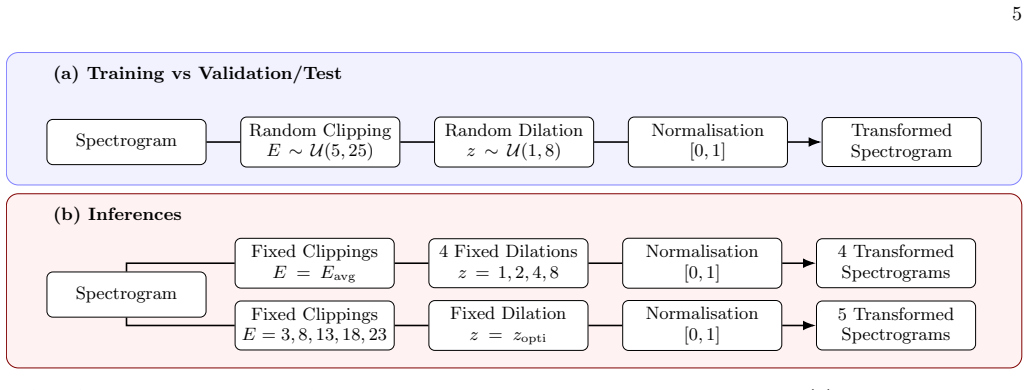
The way the data augmentation apply during the inference phase is describe on Fig
Inference for glitch denoising Two distinct inference procedures are employed. The way the data augmentation apply during the inference phase is describe on Fig. 2b. In the first stage, the ob- jective is to localize the glitch within the input. A single clipping threshold, fixed at 13, is used while all four pre- defined durations (0.5, 1, 2, and 4 s) ar...
-
[6]
CAM selection and combination Beyond classification, this architecture is ex- tended to localize transient structures by coupling GradCAM++[22] to generate two-dimensional saliency maps that highlight the regions contributing most strongly to the classification decision. The Grad- CAM++ using higher order derivative may fail to compute a map, as a fallbac...
-
[7]
After the flattening, to select the crop, we search for the excesses of signal above the average value
CAM-based glitch localization The CAM obtained is flatten along frequency axis tak- ing the maximum values to estimate an effective glitch duration, which is used to define a refined temporal crop ∆tof the spectrogram. After the flattening, to select the crop, we search for the excesses of signal above the average value. Ranking the excesses by there maxi...
-
[8]
Mask construction The cCAM is used to reweight the input spectrogram in order to enhance regions relevant to the glitch while suppressing unrelated high-amplitude features. The weighted spectrogram is defined as: wpx,ij = q inputij ×CAM ij.(7) wherew px,ij denotes the weighted pixel value at posi- tion (i, j), input ij is the original spectrogram intensit...
-
[9]
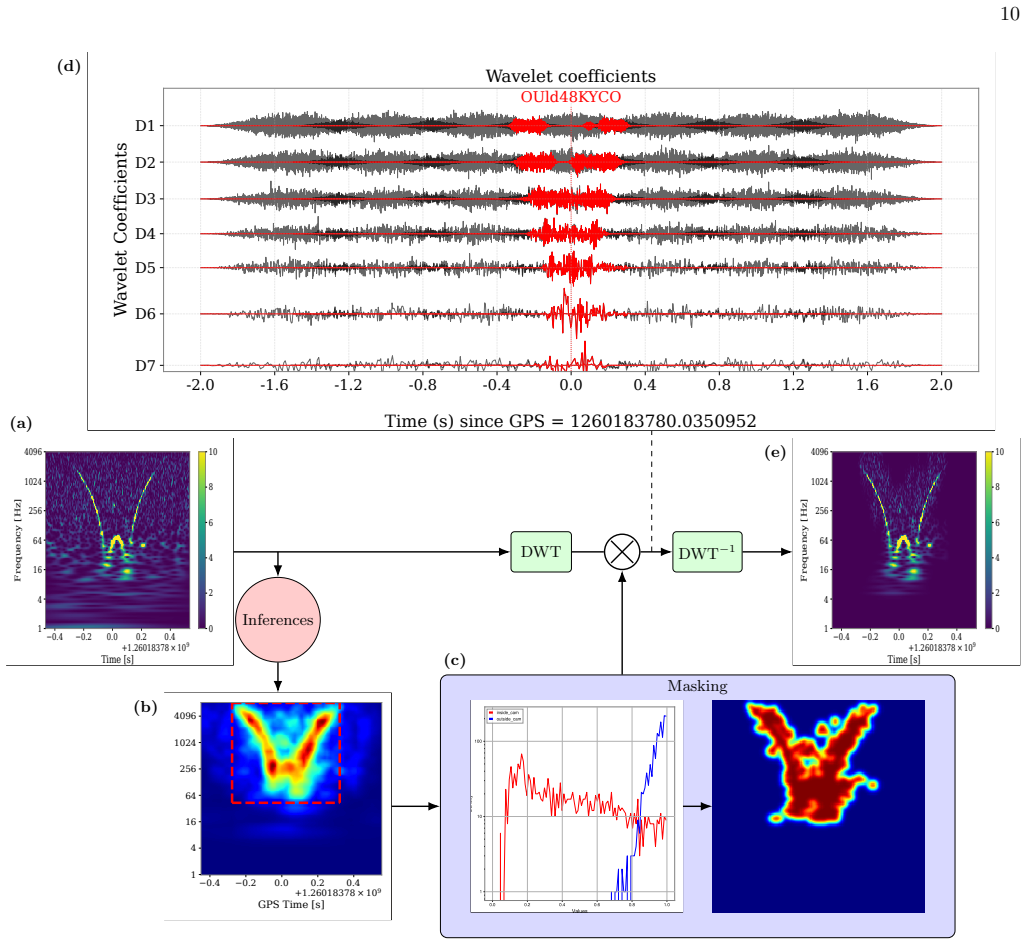
The red dashed box is the coarse saliency bounding box of width ∆tand height ∆f.(c)The computation of the mask
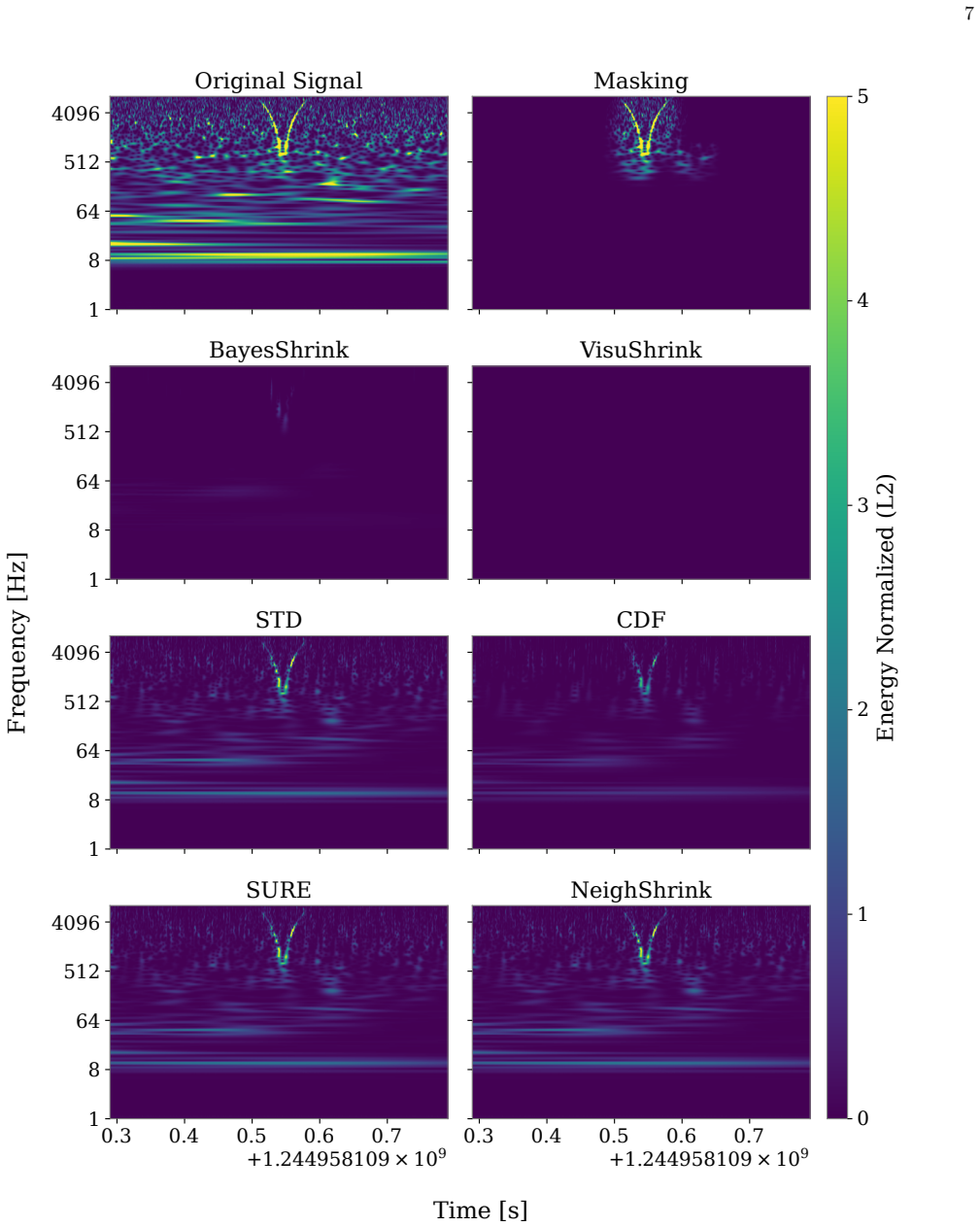
The mother wavelet used is a complex Morlet with the parameter 0.25 and 8 with a L2-norm.(b)The CAM corresponding to the inference on the input image. The red dashed box is the coarse saliency bounding box of width ∆tand height ∆f.(c)The computation of the mask. The two plots included show an example of distributions of CAM pixel’s inside (red) or outside...
2048
-
[10]
T. L. S. Collaboration, Classical and Quantum Gravity 32, 074001 (2015)
2015
-
[11]
Acernese and other, Classical and Quantum Gravity 32, 024001 (2014)
F. Acernese and other, Classical and Quantum Gravity 32, 024001 (2014)
2014
-
[12]
KAGRA Collaboration, Progress of Theoretical and Ex- perimental Physics2021, 05A101 (2020)
2020
-
[13]
B. P. Abbott and other (LIGO Scientific Collaboration and Virgo Collaboration), Phys. Rev. Lett.119, 161101 (2017)
2017
-
[14]
Bahaadini, V
S. Bahaadini, V. Noroozi, N. Rohani, S. Coughlin, M. Zevin, J. Smith, V. Kalogera, and A. Katsaggelos, Information Sciences444, 172 (2018)
2018
-
[15]
Sakai, Y
Y. Sakai, Y. Itoh, P. Jung, K. Kokeyama, C. Kozakai, K. T. Nakahira, S. Oshino, Y. Shikano, H. Takahashi, 14 T. Uchiyama, G. Ueshima, T. Washimi, T. Yamamoto, and T. Yokozawa, Scientific Reports12, 9935 (2022)
2022
-
[16]
Zevin, S
M. Zevin, S. Coughlin, S. Bahaadini, E. Besler, N. Ro- hani, S. Allen, M. Cabero, K. Crowston, A. K. Katsagge- los, S. L. Larson, T. K. Lee, C. Lintott, T. B. Littenberg, A. Lundgren, C. Østerlund, J. R. Smith, L. Trouille, and V. Kalogera, Classical and Quantum Gravity34, 064003 (2017)
2017
-
[17]
L. McInnes, J. Healy, and J. Melville, Umap: Uniform manifold approximation and projection for dimension re- duction (2020), arXiv:1802.03426 [stat.ML]
Pith/arXiv arXiv 2020
-
[18]
Oshino, Y
S. Oshino, Y. Sakai, M. Meyer-Conde, T. Uchiyama, Y. Itoh, Y. Shikano, Y. Terada, and H. Takahashi, Physics Letters B870, 139938 (2025)
2025
-
[19]
Robinet, N
F. Robinet, N. Arnaud, N. Leroy, A. Lundgren, D. Macleod, and J. McIver, SoftwareX12, 100620 (2020)
2020
-
[20]
Daubechies, IEEE Transactions on Information Theory 36, 961 (1990)
I. Daubechies, IEEE Transactions on Information Theory 36, 961 (1990)
1990
-
[21]
Virtuoso and E
A. Virtuoso and E. Milotti, Phys. Rev. D109, 102010 (2024)
2024
-
[22]
Pati and P
Y. Pati and P. Krishnaprasad, inAdvances in Neural In- formation Processing Systems, Vol. 3, edited by R. Lipp- mann, J. Moody, and D. Touretzky (Morgan-Kaufmann, 1990)
1990
-
[23]
N. J. Cornish, Phys. Rev. D102, 124038 (2020)
2020
-
[24]
N. J. Cornish, T. B. Littenberg, B. B´ ecsy, K. Chatziioan- nou, J. A. Clark, S. Ghonge, and M. Millhouse, Physical Review D103, 10.1103/physrevd.103.044006 (2021)
-
[25]
Parida and N
P. Parida and N. Bhoi, Future Computing and Informat- ics Journal2, 65 (2017)
2017
-
[26]
B. P. Abbott and other (LIGO Scientific Collaboration and Virgo Collaboration), Phys. Rev. X9, 031040 (2019)
2019
-
[27]
Abbott and other (LIGO Scientific Collaboration and Virgo Collaboration), Phys
R. Abbott and other (LIGO Scientific Collaboration and Virgo Collaboration), Phys. Rev. X11, 021053 (2021)
2021
-
[28]
T. L. S. Collaboration and the Virgo Collaboration, Gwtc-2.1: Deep extended catalog of compact binary coa- lescences observed by ligo and virgo during the first half of the third observing run (2022), arXiv:2108.01045 [gr- qc]
Pith/arXiv arXiv 2022
-
[29]
Abbott and other (LIGO Scientific Collaboration, Virgo Collaboration, and KAGRA Collaboration), Phys
R. Abbott and other (LIGO Scientific Collaboration, Virgo Collaboration, and KAGRA Collaboration), Phys. Rev. X13, 041039 (2023)
2023
-
[30]
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Tor- ralba, Learning deep features for discriminative localiza- tion (2015), arXiv:1512.04150 [cs.CV]
Pith/arXiv arXiv 2015
-
[31]
Chattopadhay, A
A. Chattopadhay, A. Sarkar, P. Howlader, and V. N. Bal- asubramanian, in2018 IEEE Winter Conference on Ap- plications of Computer Vision (WACV)(2018) pp. 839– 847
2018
-
[32]
KAGRA Collaboration, Progress of Theoretical and Ex- perimental Physics2023, 10A101 (2022)
2022
-
[33]
J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi, CoRRabs/1506.02640(2015), 1506.02640
Pith/arXiv arXiv 2015
-
[34]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, At- tention is all you need (2023), arXiv:1706.03762 [cs.CL]
Pith/arXiv arXiv 2023
-
[35]
Zhang, X
Z. Zhang, X. Lu, G. Cao, Y. Yang, L. Jiao, and F. Liu, in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)(2021) pp. 2799–2808
2021
-
[36]
Lilly and S
J. Lilly and S. Olhede, IEEE Transactions on Signal Pro- cessing57, 146–160 (2009)
2009
-
[37]
J. M. Lilly, Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences473, 20160776 (2017)
2017
-
[38]
Kingsbury, Applied and Computational Harmonic Analysis10, 234 (2001)
N. Kingsbury, Applied and Computational Harmonic Analysis10, 234 (2001)
2001
-
[39]
K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition (2015), arXiv:1512.03385 [cs.CV]
Pith/arXiv arXiv 2015
-
[40]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei, in2009 IEEE Conference on Computer Vision and Pattern Recognition(2009) pp. 248–255
2009
-
[41]
R. Fu, Q. Hu, X. Dong, Y. Guo, Y. Gao, and B. Li, Axiom-based grad-cam: Towards accurate visualiza- tion and explanation of cnns (2020), arXiv:2008.02312 [cs.CV]
arXiv 2020
-
[42]
S. G. Chang, C. SG, B. Yu, Y. B, M. Vetterli, and V. M, IEEE transactions on image processing : a publication of the IEEE Signal Processing Society9, 1532 (2000)
2000
-
[43]
D. L. Donoho and I. M. Johnstone, Biometrika81, 425 (1994)
1994
-
[44]
Bajaj, inWavelet Theory, edited by S
N. Bajaj, inWavelet Theory, edited by S. Mohammady (IntechOpen, London, 2020) Chap. 5
2020
-
[45]
Mazumder, M
M. Mazumder, M. Assaduzzaman, M. Islam, and M. S. Hossain, Current Journal of Applied Science and Tech- nology28, 1 (2018)
2018
-
[46]
K M and K
J. K M and K. S., Journal of Applied Research and Tech- nology16, 103 (2018)
2018
-
[47]
Donoho, IEEE Transactions on Information Theory 41, 613 (1995)
D. Donoho, IEEE Transactions on Information Theory 41, 613 (1995)
1995
-
[48]
Koyama, Y
N. Koyama, Y. Sakai, S. Sasaoka, D. Dominguez, K. Somiya, Y. Omae, Y. Terada, M. Meyer-Conde, and H. Takahashi, Machine Learning: Science and Technol- ogy5, 035028 (2024)
2024
-
[49]
S. Soni, N. Mukund, and E. Katsavounidis, Gw-yolo: Multi-transient segmentation in ligo using computer vi- sion (2025), arXiv:2508.17399 [astro-ph.IM]
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.