Family-Aware Residual Architecture for Predicting Quantum Circuit Simulation Performance
Pith reviewed 2026-06-27 09:46 UTC · model grok-4.3
The pith
A family-aware neural network predicts quantum circuit simulation thresholds and runtimes from OpenQASM descriptions alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
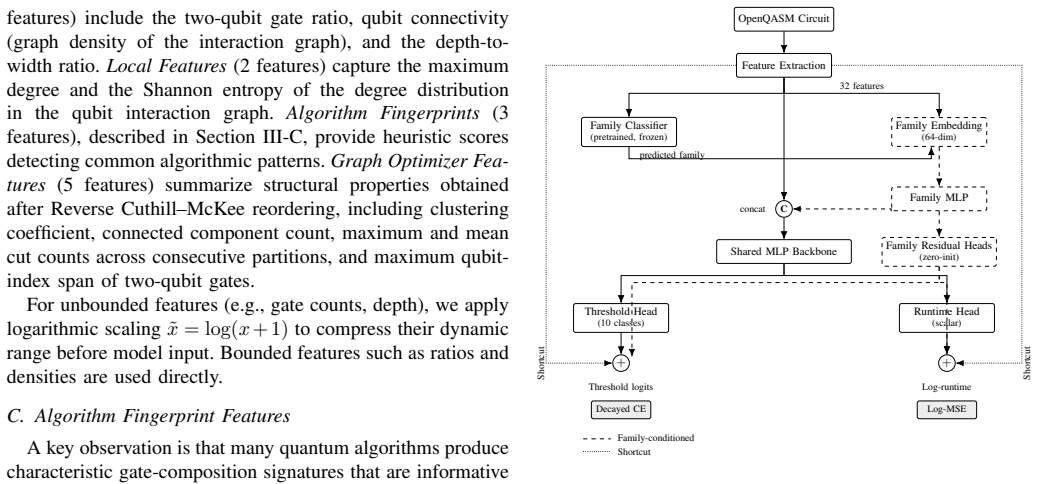
The architecture predicts both the minimum approximation threshold required to achieve target fidelity and the expected wall-clock runtime for quantum circuit simulation, given only the circuit's OpenQASM description and execution context, by employing family-conditioned residual corrections that capture both universal circuit properties and algorithmic nuances across ten families.
What carries the argument
Family-conditioned residual corrections: additive, family-specific adjustments atop a shared backbone, informed by a pretrained family classifier and gate-composition fingerprint features.
If this is right
- Trial-and-error parameter tuning for tensor-network simulators can be replaced by a single 50 ms inference pass.
- Family-aware modeling improves exact threshold accuracy by 3.2 percentage points over a shared-backbone baseline.
- The same model achieves R-squared of 0.82 on runtime prediction across circuits spanning 7 to 130 qubits.
- 91.2 percent of predictions land within one rung of the correct threshold value.
Where Pith is reading between the lines
- If family-level entanglement signatures remain stable, the same conditioning technique could be applied to predict costs for other classical simulation methods such as stabilizer or Monte-Carlo sampling.
- Circuit designers might deliberately choose algorithm families whose predicted simulation cost is lower when rapid classical verification is required.
- One could test whether the pretrained family classifier itself can be used to route circuits to specialized simulators tuned for each family.
Load-bearing premise
That the entanglement structures of the ten algorithm families in the evaluation set are representative of real-world circuits and that the family-specific corrections will generalize to unseen circuits without overfitting.
What would settle it
Apply the trained model to circuits drawn from an eleventh algorithm family never seen during training and check whether exact threshold accuracy falls below 70 percent.
Figures
read the original abstract
Approximate tensor-network simulators enable classical simulation of quantum circuits beyond the reach of exact methods, but selecting optimal approximation parameters -- such as bond dimension thresholds -- remains a costly trial-and-error process. We present a family-aware neural architecture that predicts both the minimum approximation threshold required to achieve target fidelity and the expected wall-clock runtime for quantum circuit simulation, given only the circuit's OpenQASM description and execution context. Our key insight is that quantum circuits from different algorithmic families (e.g., QFT, Grover, VQE) exhibit fundamentally distinct simulation cost profiles due to their differing entanglement structures. We employ family-conditioned residual corrections -- additive, family-specific adjustments atop a shared backbone, drawing on established conditional computation techniques -- enabling the model to capture both universal circuit properties and algorithmic nuances. The architecture incorporates a pretrained family classifier (97.5% accuracy) and domain-informed algorithm fingerprint features derived from gate-composition heuristics. Evaluated on circuits spanning 7--130 qubits across 10 algorithm families, our system achieves 79.5% exact threshold accuracy (91.2% within one rung) and $R^2 = 0.82$ runtime correlation, with inference completing in approximately 50 ms -- replacing trial-and-error simulation runs that may take minutes to hours. Ablation studies confirm that family-aware modeling provides the single largest performance improvement (+3.2 percentage points), validating the hypothesis that algorithm family is a first-class feature for simulation cost prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a neural architecture for predicting the minimum bond-dimension threshold needed for target fidelity and the expected runtime of approximate tensor-network simulation of quantum circuits. The model consists of a shared backbone augmented by family-conditioned residual corrections, a 97.5%-accurate family classifier, and gate-composition fingerprint features. Evaluated on circuits of 7–130 qubits drawn from 10 algorithm families, the system reports 79.5% exact threshold accuracy (91.2% within one rung), R² = 0.82 for runtime, and ~50 ms inference; ablation studies attribute the largest gain (+3.2 pp) to the family-aware component.
Significance. If the reported metrics hold and the family residuals prove transferable, the approach could replace costly trial-and-error parameter searches with rapid inference. The ablation result provides concrete evidence that conditioning on algorithm family improves predictive accuracy on the evaluated distribution. However, the practical significance is limited by the absence of any test on circuits belonging to algorithm families outside the ten used for training and residual fitting.
major comments (2)
- [Abstract] Abstract: the headline performance figures (79.5% exact accuracy, +3.2 pp from family-aware ablation) and the claim that 'algorithm family is a first-class feature' are obtained exclusively on circuits from the same 10 families used to train the family classifier and the family-specific residual vectors. No cross-family or out-of-distribution evaluation is described, so it remains untested whether the residual corrections transfer to a genuinely novel algorithmic family whose entanglement profile was never observed.
- [Abstract] Abstract: the manuscript states that circuits are drawn from 10 algorithm families but provides no information on the number of circuits per family, the train/test split strategy, or controls ensuring that family-specific residuals are not simply memorizing entanglement statistics present in the collected data. Without these details the ablation delta cannot be interpreted as evidence of generalization beyond the training distribution.
minor comments (1)
- [Abstract] The abstract mentions 'domain-informed algorithm fingerprint features' but does not specify how these heuristics are computed or whether they are ablated independently of the family residuals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our evaluation and the need for additional experimental details. We address each major comment below. We can clarify data collection and split procedures in a revision, but out-of-distribution testing on novel families is not present in the current work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance figures (79.5% exact accuracy, +3.2 pp from family-aware ablation) and the claim that 'algorithm family is a first-class feature' are obtained exclusively on circuits from the same 10 families used to train the family classifier and the family-specific residual vectors. No cross-family or out-of-distribution evaluation is described, so it remains untested whether the residual corrections transfer to a genuinely novel algorithmic family whose entanglement profile was never observed.
Authors: The reported metrics and ablation delta are computed exclusively within the distribution of the ten families used for training the classifier and residuals. The claim that algorithm family is a first-class feature is supported by the +3.2 pp gain observed on this distribution. The manuscript does not claim or demonstrate transfer to genuinely novel families, and we agree that such transfer remains untested. The architecture is intended to be extensible via the residual mechanism, but evaluating it on unseen families would require new data collection outside the present scope. revision: no
-
Referee: [Abstract] Abstract: the manuscript states that circuits are drawn from 10 algorithm families but provides no information on the number of circuits per family, the train/test split strategy, or controls ensuring that family-specific residuals are not simply memorizing entanglement statistics present in the collected data. Without these details the ablation delta cannot be interpreted as evidence of generalization beyond the training distribution.
Authors: We will add the missing details to the revised manuscript, including the number of circuits per family, the stratified train/test split procedure (ensuring no circuit overlap), and explicit controls that family residuals are fitted only on training data. These additions will allow readers to interpret the ablation as reflecting the benefit of family conditioning rather than potential memorization. revision: yes
- Absence of cross-family or out-of-distribution evaluation on circuits from algorithm families outside the ten used for training and residual fitting
Circularity Check
No circularity; empirical ML results on held-out data from same distribution
full rationale
The paper describes a neural network trained to predict simulation thresholds and runtimes from circuit descriptions, with performance reported on circuits spanning the same 10 families used in training. This is standard supervised learning with ablation studies; no derivation, first-principles claim, or equation reduces to its own fitted inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or described architecture. The family-conditioned residuals are an explicit modeling choice whose contribution is measured by ablation rather than assumed. Lack of out-of-family testing is a generalization limitation, not a circularity in the reported metrics.
Axiom & Free-Parameter Ledger
free parameters (2)
- Neural network weights and biases
- Family-specific residual correction vectors
axioms (1)
- domain assumption Quantum circuits from different algorithmic families exhibit fundamentally distinct simulation cost profiles due to their differing entanglement structures.
Reference graph
Works this paper leans on
-
[1]
Simulating quantum computation by contract- ing tensor networks,
I. L. Markov and Y . Shi, “Simulating quantum computation by contract- ing tensor networks,”SIAM J. Computing, vol. 38, no. 3, pp. 963–981, 2008
2008
-
[2]
Efficient quantum circuit simulation by tensor network methods on modern GPUs,
F. Panet al., “Efficient quantum circuit simulation by tensor network methods on modern GPUs,”ACM Trans. Quantum Computing, 2024. [arXiv:2310.03978]
-
[3]
Efficient parallelization of tensor network contraction for simulating quantum computation,
C. Huanget al., “Efficient parallelization of tensor network contraction for simulating quantum computation,”Nature Computational Science, vol. 1, pp. 578–587, 2021
2021
-
[4]
Tensor network quantum virtual machine for simu- lating quantum circuits at exascale,
T. Nguyenet al., “Tensor network quantum virtual machine for simu- lating quantum circuits at exascale,”ACM Trans. Quantum Computing, vol. 3, no. 4, 2022
2022
-
[5]
Predicting good quantum circuit compilation options,
N. Quetschlich, L. Burgholzer, and R. Wille, “Predicting good quantum circuit compilation options,” inProc. IEEE/ACM Int’l Conf. Quantum Software, 2023. [arXiv:2210.08027]
-
[6]
MQT Predictor: Au- tomatic device selection with device-specific circuit compilation for quantum computing,
N. Quetschlich, L. Burgholzer, and R. Wille, “MQT Predictor: Au- tomatic device selection with device-specific circuit compilation for quantum computing,”ACM Trans. Quantum Computing, 2025
2025
-
[7]
Compiler optimization for quantum computing using reinforcement learning,
N. Quetschlich, L. Burgholzer, and R. Wille, “Compiler optimization for quantum computing using reinforcement learning,” inProc. Design Automation Conf., 2023
2023
-
[8]
MQT Bench: Bench- marking software and design automation tools for quantum computing,
N. Quetschlich, L. Burgholzer, and R. Wille, “MQT Bench: Bench- marking software and design automation tools for quantum computing,” Quantum, vol. 7, p. 1062, 2023. [arXiv:2204.13719]
-
[9]
Quantum computing in the NISQ era and beyond,
J. Preskill, “Quantum computing in the NISQ era and beyond,”Quan- tum, vol. 2, p. 79, 2018
2018
-
[10]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information. Cambridge University Press, 2010
2010
-
[11]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE/CVF CVPR, 2016, pp. 770–778
2016
-
[12]
Qiskit: An open-source framework for quantum computing,
Qiskit contributors, “Qiskit: An open-source framework for quantum computing,” 2023. [Online]. Available: https://qiskit.org
2023
-
[13]
The MQT Handbook: A summary of design automation tools and software for quantum computing,
R. Willeet al., “The MQT Handbook: A summary of design automation tools and software for quantum computing,” inProc. IEEE QCE, 2024
2024
-
[14]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inProc. AAAI Conf. Artificial Intelligence, 2018
2018
-
[15]
Empowering large scale quantum circuit development: Effective simulation of Sycamore circuits,
V . Kasirajanet al., “Empowering large scale quantum circuit development: Effective simulation of Sycamore circuits,” 2024. [arXiv:2411.12131]
-
[16]
QuEst: Graph transformer for quantum circuit reliability estimation,
H. Wanget al., “QuEst: Graph transformer for quantum circuit reliability estimation,” 2022. [arXiv:2210.16724]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.