Noise-Aware Framework for Correcting Corrupted Labels
Pith reviewed 2026-06-27 10:31 UTC · model grok-4.3
The pith
CANOLA corrects corrupted labels by estimating the dataset noise distribution and using it for cautious iterative soft-label refinement in a noise-aware neural network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
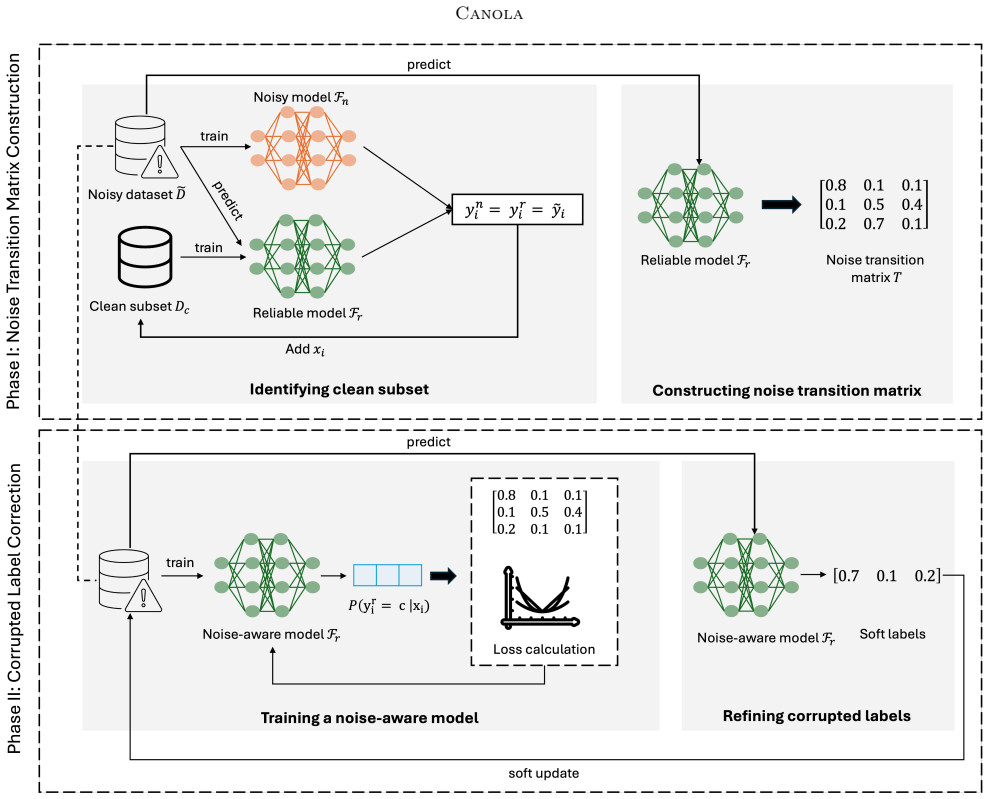
CANOLA explicitly estimates the underlying noise distribution of the dataset and incorporates this information into the training of a noise-aware Deep Neural Network. By incorporating noise characteristics during learning, CANOLA enables the model to down-weight unreliable supervision signals and focus on trustworthy patterns. Label correction is performed via cautious, iterative soft label refinement, in which model predictions are blended with observed labels to prevent premature or erroneous updates. This progressive refinement allows the dataset to be repaired in a stable and controlled manner, leading to consistent outperformance of state-of-the-art methods with relative error reduction
What carries the argument
The CANOLA framework, which estimates the noise distribution from corrupted labels and feeds it into iterative soft-label refinement inside a noise-aware neural network.
If this is right
- Models trained on labels corrected by CANOLA achieve substantial downstream performance gains compared to uncorrected data.
- Simple classifiers trained on CANOLA-corrected data can outperform complex model-centric approaches by margins up to 67 percent.
- The noise-aware training step improves robustness by focusing on trustworthy patterns rather than unreliable labels.
Where Pith is reading between the lines
- The approach could be tested on real-world industrial datasets where noise sources are heterogeneous rather than the synthetic or benchmark noise used here.
- If the iterative refinement proves stable across domains, it might reduce reliance on manual data cleaning pipelines in large-scale supervised learning.
- Combining the noise estimation step with existing data augmentation techniques could be explored as a way to further boost generalization.
Load-bearing premise
The framework can accurately estimate the underlying noise distribution from the observed corrupted labels and stably incorporate this estimate into training without introducing new bias or instability.
What would settle it
On a synthetic dataset with a known ground-truth noise distribution, measure whether CANOLA's estimated distribution matches the true one within a small tolerance; failure to match or loss of the reported performance gains on held-out noisy data would disprove the central claim.
Figures


read the original abstract
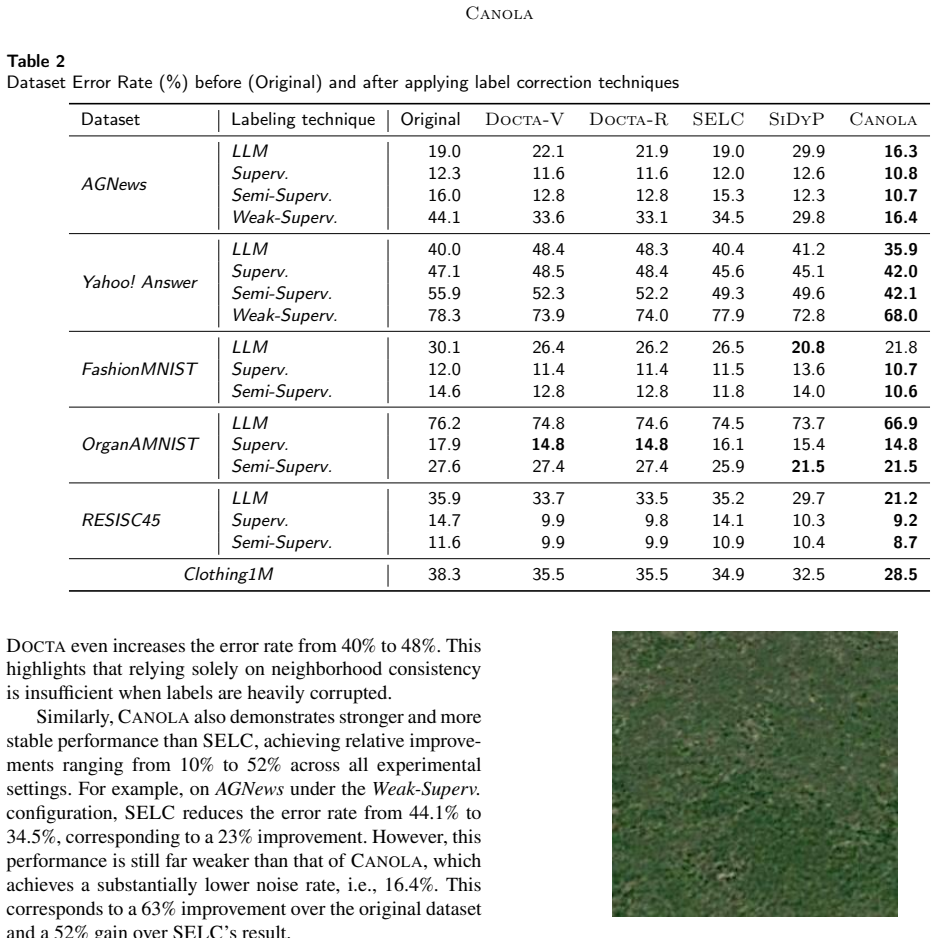
High-quality labeled data is essential for training reliable ML/DL models. However, real-world datasets often contain a considerable proportion of corrupted labels, which can severely degrade model performance. To address this problem, we propose CANOLA, a novel framework for correcting corrupted labels through noise-aware learning and iterative label refinement. CANOLA explicitly estimates the underlying noise distribution of the dataset and incorporates this information into the training of a noise-aware Deep Neural Network. By incorporating noise characteristics during learning, CANOLA enables the model to down-weight unreliable supervision signals and focus on trustworthy patterns, thereby improving robustness and generalization. Label correction is performed via cautious, iterative soft label refinement, in which model predictions are blended with observed labels to prevent premature or erroneous updates. This progressive refinement allows the dataset to be repaired in a stable and controlled manner. We evaluate CANOLA on six widely used datasets under realistic noisy labeling scenarios. Experimental results show that CANOLA consistently outperforms SOTA label correction methods, achieving relative improvements ranging from 19% to 52% in error reduction. Moreover, models trained on datasets corrected by CANOLA obtain substantial downstream performance gains. Even simple classifiers trained on CANOLA's corrected data can outperform complex model-centric approaches by margins of up to 67%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CANOLA, a framework that estimates the underlying noise distribution from corrupted labels, incorporates this into noise-aware DNN training to down-weight unreliable signals, and performs cautious iterative soft-label refinement to correct labels. It evaluates the method on six datasets under noisy labeling scenarios and claims consistent outperformance of SOTA label correction methods with 19-52% relative error reduction, plus substantial downstream gains (up to 67% over model-centric baselines even with simple classifiers).
Significance. If the noise estimation step proves stable and unbiased, the combination of explicit noise modeling with controlled iterative refinement could advance practical label correction techniques and improve robustness in real-world ML settings where label noise is prevalent.
major comments (2)
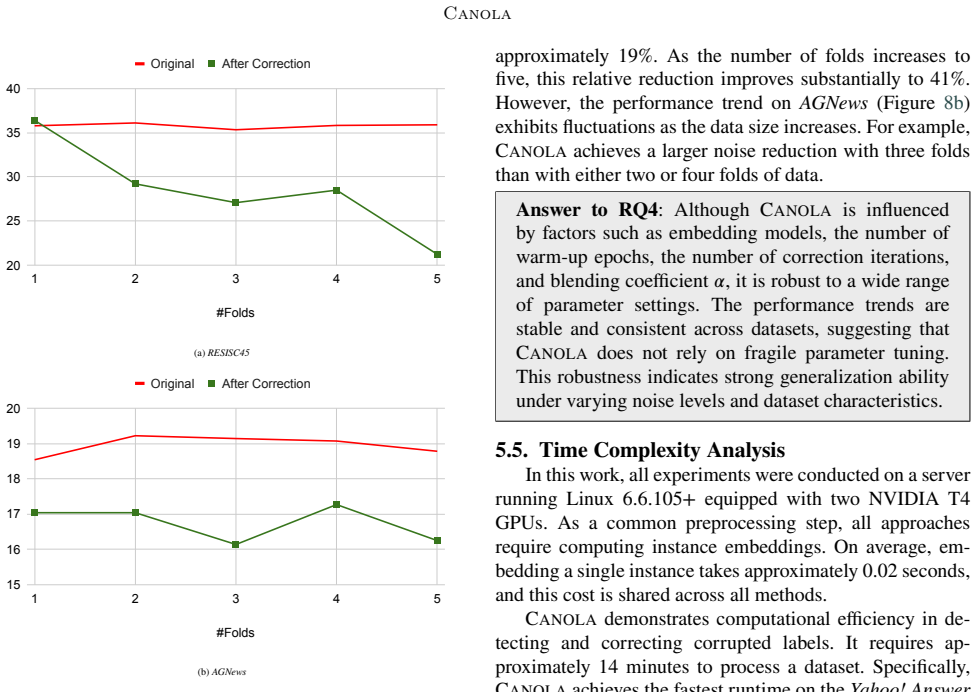
- [Abstract] Abstract: The performance numbers (19-52% error reduction, 67% downstream gains) are stated without any description of the noise model, experimental protocol, error bars, or statistical significance tests; the central empirical claim therefore cannot be evaluated.
- [Method] Method (noise estimation component): No mechanism, parametric form, EM-style procedure, or identifiability argument is provided for recovering the noise distribution solely from corrupted labels; without this, it is impossible to verify whether the estimate remains unbiased when the initial model is itself trained on noisy data, which is load-bearing for all reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional clarity is needed in both the abstract and method description. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance numbers (19-52% error reduction, 67% downstream gains) are stated without any description of the noise model, experimental protocol, error bars, or statistical significance tests; the central empirical claim therefore cannot be evaluated.
Authors: We agree that the abstract would benefit from additional context to make the empirical claims more readily evaluable. In the revision, we will expand the abstract to briefly describe the class-conditional noise model, note that experiments were run on six datasets with controlled synthetic noise rates, multiple random seeds, and error bars, and state that statistical significance was evaluated using paired t-tests. The full protocol remains in Section 4. revision: yes
-
Referee: [Method] Method (noise estimation component): No mechanism, parametric form, EM-style procedure, or identifiability argument is provided for recovering the noise distribution solely from corrupted labels; without this, it is impossible to verify whether the estimate remains unbiased when the initial model is itself trained on noisy data, which is load-bearing for all reported gains.
Authors: We acknowledge that the submitted manuscript does not provide a detailed description of the noise estimation procedure. This is a substantive gap. In the revised version we will expand Section 3.2 to specify the parametric form (class-conditional transition matrix), the EM-style alternating optimization used to recover it from corrupted labels, the identifiability argument relying on anchor points, and new analysis (both theoretical and empirical) showing stability of the estimate when the initial model is trained on noisy data. revision: yes
Circularity Check
No circularity detected; derivation chain not reducible to inputs
full rationale
The provided abstract and description outline a high-level framework for noise distribution estimation and iterative label refinement but contain no equations, fitting procedures, or derivation steps that could be inspected for self-definition, fitted-input predictions, or self-citation load-bearing. Claims rest on empirical outperformance rather than any closed mathematical chain that reduces to its own inputs by construction. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M.I.Jordan,T.M.Mitchell,Machinelearning:Trends,perspectives, and prospects, Science 349 (6245) (2015) 255–260
2015
-
[2]
T.-H.Huang,C.Cao,V.Bhargava,F.Sala,Thealchemist:Automated labeling 500x cheaper than llm data annotators, Advances in Neural Information Processing Systems 37 (2024) 62648–62672
2024
-
[3]
Desmond, E
M. Desmond, E. Duesterwald, K. Brimijoin, M. Brachman, Q. Pan, Semi-automated data labeling, in: NeurIPS 2020 competition and demonstration track, PMLR, 2021, pp. 156–169
2020
-
[4]
Y. Zhu, Z. Yin, G. Tyson, E.-U. Haq, L.-H. Lee, P. Hui, Apt-pipe: A prompt-tuning tool for social data annotation using chatgpt, in: Proceedings of the ACM Web Conference 2024, 2024, pp. 245–255
2024
-
[5]
Cheng, Z
H. Cheng, Z. Zhu, X. Li, Y. Gong, X. Sun, Y. Liu, Learning with instance-dependentlabelnoise:Asamplesieveapproach,in:Interna- tional Conference on Learning Representations, 2021
2021
-
[6]
H. Song, M. Kim, J.-G. Lee, Selfie: Refurbishing unclean samples for robust deep learning, in: International conference on machine learning, PMLR, 2019, pp. 5907–5915
2019
-
[7]
2691–2699
T.Xiao,T.Xia,Y.Yang,C.Huang,X.Wang,Learningfrommassive noisy labeled data for image classification, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 2691–2699
2015
-
[9]
J. Li, R. Socher, S. C. Hoi, Dividemix: Learning with noisy labels as semi-supervised learning, arXiv preprint arXiv:2002.07394
arXiv 2002
-
[10]
B.Han,Q.Yao,X.Yu,G.Niu,M.Xu,W.Hu,I.Tsang,M.Sugiyama, Co-teaching:Robusttrainingofdeepneuralnetworkswithextremely noisy labels, Advances in neural information processing systems 31
-
[11]
T. M. Khoshgoftaar, J. Van Hulse, A. Napolitano, Comparing boost- ing and bagging techniques with noisy and imbalanced data, IEEE TransactionsonSystems,Man,andCybernetics-PartA:Systemsand Humans 41 (3) (2010) 552–568
2010
-
[12]
J. Li, Y. Wong, Q. Zhao, M. S. Kankanhalli, Learning to learn from noisy labeled data, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5051–5059
2019
-
[13]
Z. Zhu, Z. Dong, Y. Liu, Detecting corrupted labels without training a model to predict, in: International conference on machine learning, PMLR, 2022, pp. 27412–27427
2022
-
[14]
S. Kim, D. Lee, S. Kang, S. Chae, S. Jang, H. Yu, Learning discrim- inative dynamics with label corruption for noisy label detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22477–22487
2024
-
[15]
Lam, H.-L
P. Lam, H.-L. Nguyen, X.-T. D. Dang, V.-S. Tran, M.-D. Le, T.- T. Nguyen, S. Nguyen, H. D. Vo, Leveraging local and global rela- tionships for corrupted label detection, Future Generation Computer Systems 166 (2025) 107729
2025
-
[16]
P. Liu, J. Yang, L. Wang, S. Wang, Y. Hao, H. Bai, Retrieval-based unsupervisednoisylabeldetectionontextdata,in:Proceedingsofthe 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 4099–4104
2023
-
[17]
Sharma, P
K. Sharma, P. Donmez, E. Luo, Y. Liu, I. Z. Yalniz, Noiserank: Unsupervised label noise reduction with dependence models, in: European conference on computer vision, Springer, 2020, pp. 737– 753
2020
-
[18]
2, 2025, pp
L.Ye,A.Shah,C.Zhang,S.Chava,Calibratingpre-trainedlanguage classifiers on llm-generated noisy labels via iterative refinement, in: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2, 2025, pp. 3598–3609
2025
-
[19]
3278–3284
Y.Lu,W.He,Selc:Self-ensemblelabelcorrectionimproveslearning with noisy labels, in: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI’22), International Joint Conferences on Artificial Intelligence Organization, 2022, pp. 3278–3284
2022
-
[20]
H. Wang, Z. Huang, Z. Lin, T. Liu, Noisegpt: Label noise detection and rectification through probability curvature, Advances in Neural Information Processing Systems 37 (2024) 120159–120183
2024
-
[21]
P.Li,X.Rao,J.Blase,Y.Zhang,X.Chu,C.Zhang,Cleanml:Astudy for evaluating the impact of data cleaning on ml classification tasks, in: 2021 IEEE 37th International Conference on Data Engineering (ICDE), IEEE, 2021, pp. 13–24
2021
-
[22]
Z. Zhu, J. Wang, H. Cheng, Y. Liu, Unmasking and improving data credibility: A study with datasets for training harmless language models, arXiv preprint arXiv:2311.11202
-
[23]
Zhang, D
W. Zhang, D. Cheng, G. Lu, B. Zhou, J. Li, S. Zhang, Efficient adaptive label refinement for label noise learning, Neurocomputing (2025) 130305
2025
-
[24]
Arpit, S
D. Arpit, S. Jastrzębski, N. Ballas, D. Krueger, E. Bengio, M. S. Kanwal, T. Maharaj, A. Fischer, A. Courville, Y. Bengio, et al., A closer look at memorization in deep networks, in: International conference on machine learning, PMLR, 2017, pp. 233–242
2017
-
[25]
D. Rolnick, A. Veit, S. Belongie, N. Shavit, Deep learning is robust to massive label noise, arXiv preprint arXiv:1705.10694. Nguyenet al.:Preprint submitted to ElsevierPage 17 of 19 Canola
-
[26]
Zheng, P
S. Zheng, P. Wu, A. Goswami, M. Goswami, D. Metaxas, C. Chen, Error-boundedcorrectionofnoisylabels,in:InternationalConference on Machine Learning, PMLR, 2020, pp. 11447–11457
2020
-
[27]
Z. Zhu, Y. Wang, S. Yang, L. Long, R. Wu, X. Tang, J. Zhao, H. Wang, Coral: Collaborative automatic labeling system based on largelanguagemodels,ProceedingsoftheVLDBEndowment17(12) (2024) 4401–4404
2024
-
[28]
S. Wang, Y. Liu, Y. Xu, C. Zhu, M. Zeng, Want to reduce labeling cost? gpt-3 can help, in: Findings of the Association for Computa- tional Linguistics: EMNLP 2021, 2021, pp. 4195–4205
2021
-
[29]
Saito, Y
K. Saito, Y. Ushiku, T. Harada, Asymmetric tri-training for unsu- pervised domain adaptation, in: International conference on machine learning, PMLR, 2017, pp. 2988–2997
2017
-
[30]
F. Liu, Y. Chen, C. Wang, Y. Tain, G. Carneiro, Asymmetric co- teaching with multi-view consensus for noisy label learning, arXiv preprint arXiv:2301.01143
-
[31]
S.Kullback,R.A.Leibler,Oninformationandsufficiency,Theannals of mathematical statistics 22 (1) (1951) 79–86
1951
-
[32]
Tomanek, U
K. Tomanek, U. Hahn, Semi-supervised active learning for sequence labeling, in: Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, 2009, pp. 1039–1047
2009
-
[33]
H. Xiao, K. Rasul, R. Vollgraf, Fashion-mnist: a novel image datasetforbenchmarkingmachinelearningalgorithms,arXivpreprint arXiv:1708.07747
-
[34]
J. Yang, R. Shi, B. Ni, Medmnist classification decathlon: A lightweight automl benchmark for medical image analysis, in: 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), IEEE, 2021, pp. 191–195
2021
-
[35]
J. Yang, R. Shi, D. Wei, Z. Liu, L. Zhao, B. Ke, H. Pfister, B. Ni, Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification, Scientific Data 10 (1) (2023) 41
2023
-
[36]
Cheng, J
G. Cheng, J. Han, X. Lu, Remote sensing image scene classification: Benchmark and state of the art, Proceedings of the IEEE 105 (10) (2017) 1865–1883
2017
-
[37]
X.Zhang,J.Zhao,Y.LeCun,Character-levelconvolutionalnetworks for text classification, Advances in neural information processing systems 28
-
[38]
Nguyen, H.-A
H.-L. Nguyen, H.-A. Nguyen, M.-D. La, P. Lam, T.-T. Nguyen, S.Nguyen,D.H.Vo,Noise-awareframeworkforcorrectingcorrupted labels. URLhttps://github.com/iSE-UET-VNU/CANOLA
-
[39]
Team, Qwen2.5-7b-instruct (September 2024)
Q. Team, Qwen2.5-7b-instruct (September 2024). URLhttps://huggingface.co/Qwen/Qwen2.5-7B-Instruct
2024
-
[40]
Team, Qwen2-vl-7b-instruct (September 2024)
Q. Team, Qwen2-vl-7b-instruct (September 2024). URLhttps://huggingface.co/Qwen/Qwen2-VL-7B-Instruct
2024
-
[41]
Qwen,:,A.Yang,B.Yang,B.Zhang,B.Hui,B.Zheng,B.Yu,C.Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J.Yang,J.Zhou,J.Lin,K.Dang,K.Lu,K.Bao,K.Yang,L.Yu,M.Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y. Fan, Y. Su, Y. Zhang, Y. Wan, Y. Liu, Z. Cui, Z.Zhang,Z.Qiu,Qwen2.5technicalreport(2025).arXi...
Pith/arXiv arXiv 2025
-
[42]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, et al., Qwen2. 5-vl technical report, arXiv preprint arXiv:2502.13923
-
[43]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies,volume1(longandshortpapers),2019,pp.4171–4186
2019
-
[44]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G.Sastry,A.Askell,P.Mishkin,J.Clark,etal.,Learningtransferable visual models from natural language supervision, in: International conference on machine learning, PmLR, 2021, pp. 8748–8763
2021
-
[45]
D. Zhou, O. Bousquet, T. Lal, J. Weston, B. Schölkopf, Learning with local and global consistency, Advances in neural information processing systems 16
-
[46]
Ratner, S
A. Ratner, S. H. Bach, H. Ehrenberg, J. Fries, S. Wu, C. Ré, Snorkel: Rapid training data creation with weak supervision, in: Proceedings oftheVLDBendowment.Internationalconferenceonverylargedata bases, Vol. 11, 2017, p. 269
2017
-
[47]
Y. Wang, X. Ma, Z. Chen, Y. Luo, J. Yi, J. Bailey, Symmetric cross entropy for robust learning with noisy labels, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 322–330
2019
-
[48]
C. Feng, G. Tzimiropoulos, I. Patras, Clipcleaner: Cleaning noisy labels with clip, in: Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 876–885
2024
-
[49]
C. M. Bishop, N. M. Nasrabadi, Pattern recognition and machine learning, Vol. 4, Springer, 2006
2006
-
[50]
D.A.Cieslak,T.R.Hoens,N.V.Chawla,W.P.Kegelmeyer,Hellinger distance decision trees are robust and skew-insensitive, Data Mining and Knowledge Discovery 24 (1) (2012) 136–158
2012
-
[51]
Y. Bai, E. Yang, B. Han, Y. Yang, J. Li, Y. Mao, G. Niu, T. Liu, Understanding and improving early stopping for learning with noisy labels,AdvancesinNeuralInformationProcessingSystems34(2021) 24392–24403
2021
-
[52]
Y. Liu, Y. Zhang, D. Ghosh, L. Schmidt, S. Yeung-Levy, Data or languagesupervision:Whatmakesclipbetterthandino?,in:Findings of the Association for Computational Linguistics: EMNLP 2025, 2025, pp. 1868–1874
2025
-
[53]
O. Siméoni, H. V. Vo, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V. Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al., Dinov3, arXiv preprint arXiv:2508.10104
-
[54]
X. Zhai, B. Mustafa, A. Kolesnikov, L. Beyer, Sigmoid loss for language image pre-training, in: Proceedings of the IEEE/CVF inter- national conference on computer vision, 2023, pp. 11975–11986
2023
-
[55]
Y.Liu,M.Ott,N.Goyal,J.Du,M.Joshi,D.Chen,O.Levy,M.Lewis, L. Zettlemoyer, V. Stoyanov, Roberta: A robustly optimized bert pretraining approach, arXiv preprint arXiv:1907.11692
Pith/arXiv arXiv 1907
-
[56]
Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, Q. V. Le,Xlnet:Generalizedautoregressivepretrainingforlanguageunder- standing, Advances in neural information processing systems 32
-
[57]
Schmarje, V
L. Schmarje, V. Grossmann, C. Zelenka, S. Dippel, R. Kiko, M. Os- zust, M. Pastell, J. Stracke, A. Valros, N. Volkmann, et al., Is one annotationenough?-adata-centricimageclassificationbenchmarkfor noisy and ambiguous label estimation, Advances in Neural Informa- tion Processing Systems 35 (2022) 33215–33232
2022
-
[58]
W. Hou, L. Hong, Z. Zhu, Kgred: Knowledge-graph-based rule dis- covery for weakly supervised data labeling, Information Processing & Management 61 (5) (2024) 103816
2024
-
[59]
Galhotra, B
S. Galhotra, B. Golshan, W.-C. Tan, Adaptive rule discovery for la- belingtextdata,in:Proceedingsofthe2021Internationalconference on management of data, 2021, pp. 2217–2225
2021
-
[60]
Y.Bengio,O.Delalleau,N.LeRoux,Labelpropagationandquadratic criterion, Semi-Supervised Learning (2006) 193–216
2006
-
[61]
Belkin, P
M. Belkin, P. Niyogi, V. Sindhwani, Manifold regularization: A geo- metricframeworkforlearningfromlabeledandunlabeledexamples., Journal of machine learning research 7 (11)
-
[62]
D.-H. Lee, et al., Pseudo-label: The simple and efficient semi- supervised learning method for deep neural networks, in: Workshop onchallengesinrepresentationlearning,ICML,Vol.3,Atlanta,2013, p. 896
2013
-
[63]
X. Yang, Z. Song, I. King, Z. Xu, A survey on deep semi-supervised learning, IEEE Transactions on Knowledge and Data Engineering 35 (9) (2022) 8934–8954
2022
-
[64]
Z. Song, Y. Zhang, I. King, Optimal block-wise asymmetric graph construction for graph-based semi-supervised learning, Advances in Neural Information Processing Systems 36
-
[65]
R.Jiao,Y.Zhang,L.Ding,B.Xue,J.Zhang,R.Cai,C.Jin,Learning with limited annotations: a survey on deep semi-supervised learning formedicalimagesegmentation,ComputersinBiologyandMedicine 169 (2024) 107840
2024
-
[66]
Kholodna, S
N. Kholodna, S. Julka, M. Khodadadi, M. N. Gumus, M. Granitzer, Llms in the loop: Leveraging large language model annotations for Nguyenet al.:Preprint submitted to ElsevierPage 18 of 19 Canola activelearninginlow-resourcelanguages,in:JointEuropeanConfer- ence on Machine Learning and Knowledge Discovery in Databases, Springer, 2024, pp. 397–412
2024
-
[67]
P. Ma, R. Ding, S. Wang, S. Han, D. Zhang, Insightpilot: An llm- empowered automated data exploration system, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2023, pp. 346–352
2023
-
[68]
M. V. Reiss, Testing the reliability of chatgpt for text anno- tation and classification: A cautionary remark, arXiv preprint arXiv:2304.11085
-
[69]
Huang, H
F. Huang, H. Kwak, J. An, Is chatgpt better than human annotators? potentialandlimitationsofchatgptinexplainingimplicithatespeech, in:CompanionproceedingsoftheACMwebconference2023,2023, pp. 294–297
2023
-
[70]
C. Yu, X. Ma, W. Liu, Delving into noisy label detection with clean data, in: International Conference on Machine Learning, PMLR, 2023, pp. 40290–40305
2023
-
[71]
5796–5808
Z.Wang,Z.Lin,J.Wen,X.Chen,P.Liu,G.Zheng,Y.Chen,Z.Yang, Learning to detect noisy labels using model-based features, in: Find- ingsoftheAssociationforComputationalLinguistics:EMNLP2022, 2022, pp. 5796–5808
2022
-
[72]
Y. Yin, Y. Feng, S. Weng, Z. Liu, Y. Yao, Y. Zhang, Z. Zhao, Z.Chen,Dynamicdatafaultlocalizationfordeepneuralnetworks,in: Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engi- neering, 2023, pp. 1345–1357
2023
-
[73]
S. Kong, Y. Li, J. Wang, A. Rezaei, H. Zhou, Knn-enhanced deep learning against noisy labels, arXiv preprint arXiv:2012.04224
arXiv 2012
-
[74]
1143–1152
J.Lee,H.Park,M.Kim,J.Yoon,K.Yoo,S.-J.Byun,Fastsimifeat:A fast and generalized approach utilizing k-nn for noisy data handling, in: Proceedings of the 33rd ACM International Conference on Infor- mation and Knowledge Management, 2024, pp. 1143–1152
2024
-
[75]
Y. Xu, X. Niu, J. Yang, R. Su, J. Zhang, S. Liu, S. Drew, Revisiting interpolation for noisy label correction, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, 2025, pp. 21833– 21841
2025
-
[76]
Arazo, D
E. Arazo, D. Ortego, P. Albert, N. O’Connor, K. McGuinness, Un- supervisedlabelnoisemodelingandlosscorrection,in:International conference on machine learning, PMLR, 2019, pp. 312–321
2019
-
[77]
J. Han, P. Luo, X. Wang, Deep self-learning from noisy labels, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 5138–5147
2019
-
[78]
Lienen, E
J. Lienen, E. Hüllermeier, Mitigating label noise through data am- biguation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, 2024, pp. 13799–13807. Nguyenet al.:Preprint submitted to ElsevierPage 19 of 19
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.