T2S: A Rehearsal-Based Approach for Extraction-Resistant Model Watermarking
Pith reviewed 2026-06-27 09:22 UTC · model grok-4.3
The pith
Simulating extraction during watermark training produces watermarks that transfer to stolen surrogate models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
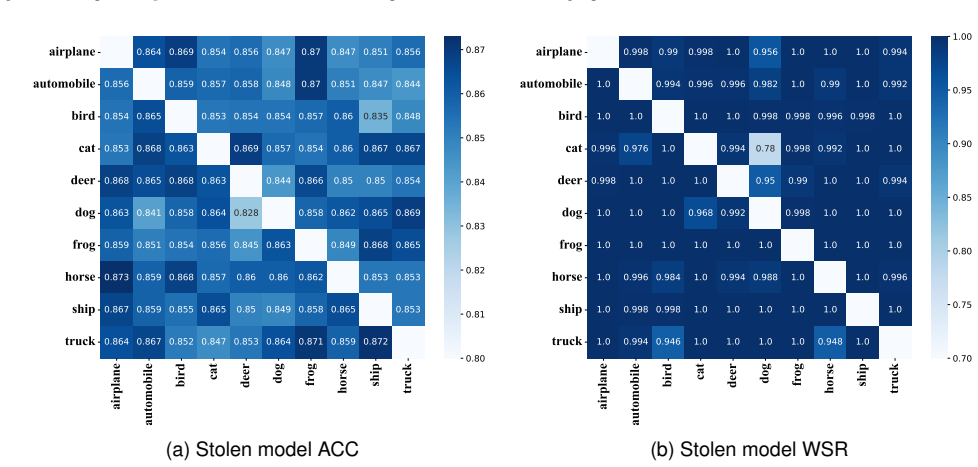
By treating the loss of a simulated stolen model on the trigger set as a training signal, the T2S method fine-tunes the watermark knowledge inside the target model so that the distinctive behavior transfers to any surrogate trained on the target's outputs, raising the chance that the watermark remains detectable after extraction and subsequent removal attacks.
What carries the argument
Rehearsal-based fine-tuning that uses the simulated stolen model's loss on the trigger set as the optimization signal.
If this is right
- The watermark signature remains detectable in surrogate models built from the target's prediction outputs.
- Robustness improves against follow-on attacks that attempt to erase the watermark after extraction succeeds.
- The same fine-tuning step works across varied model architectures, datasets, and extraction settings in the reported tests.
Where Pith is reading between the lines
- The simulation idea could be extended by maintaining an ensemble of simulated extractors that differ in architecture or query cost.
- Watermark design may need to treat extraction as an explicit adversarial game rather than a static embedding problem.
- The method might combine with query-limiting defenses to further reduce the success of extraction before the watermark is even tested.
Load-bearing premise
Training against one simulated extraction process will produce watermark transferability that holds when real adversaries use different query strategies, model architectures, or training data.
What would settle it
Run a real model extraction attack with a query budget, architecture, or data distribution that was not used in the simulation step and measure whether the watermark detection rate in the resulting surrogate falls to chance level.
Figures

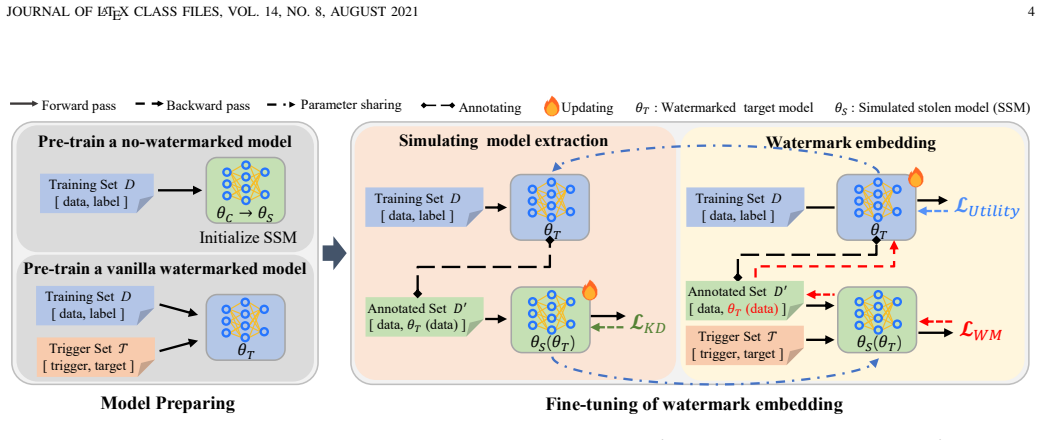
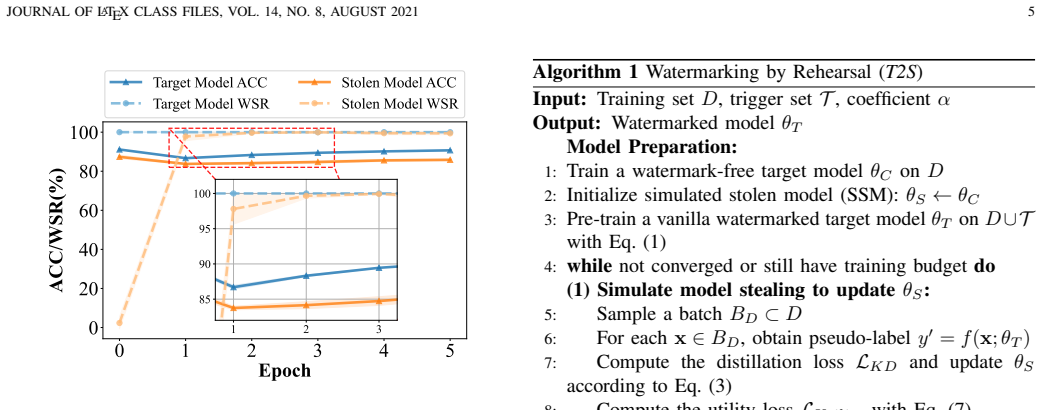
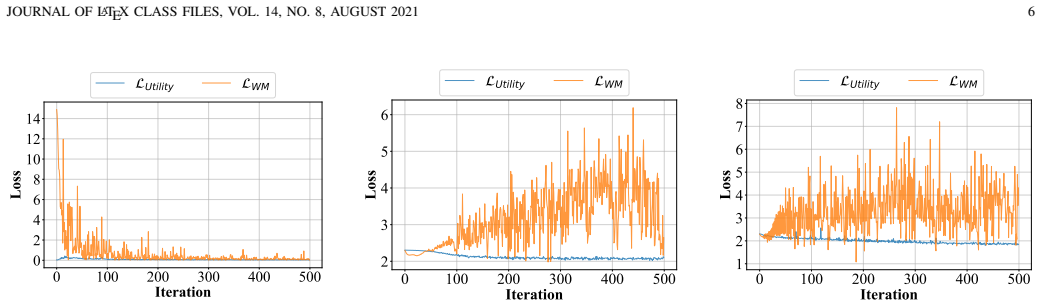
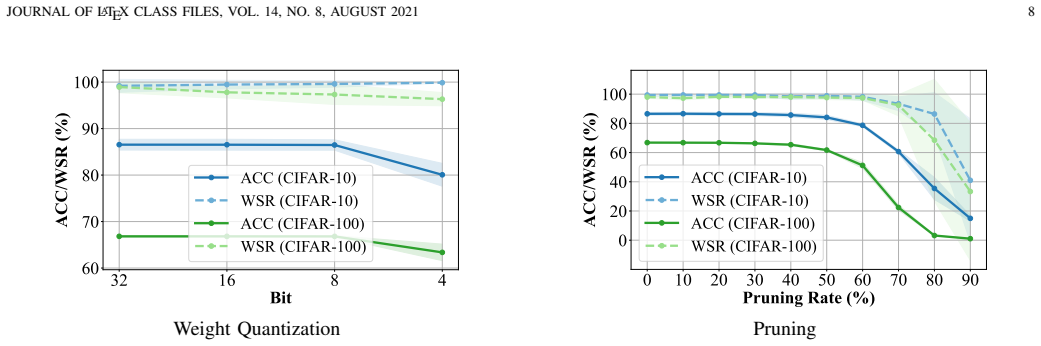
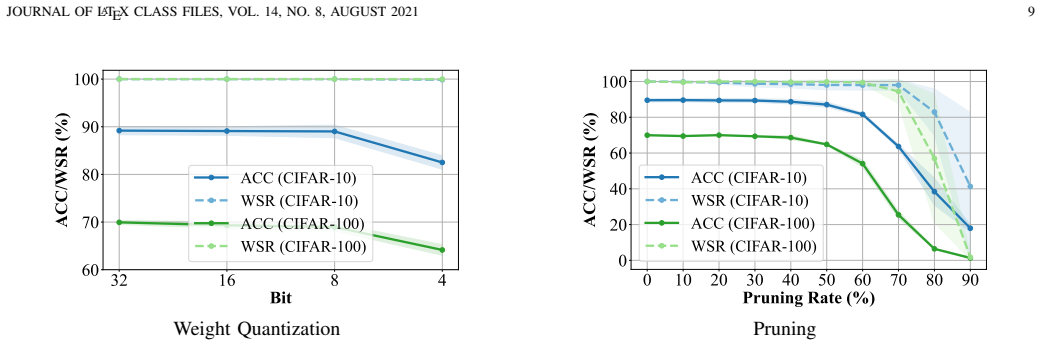
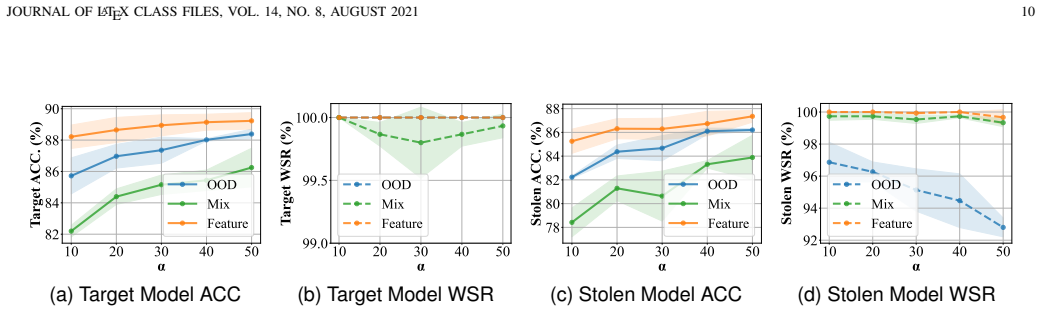
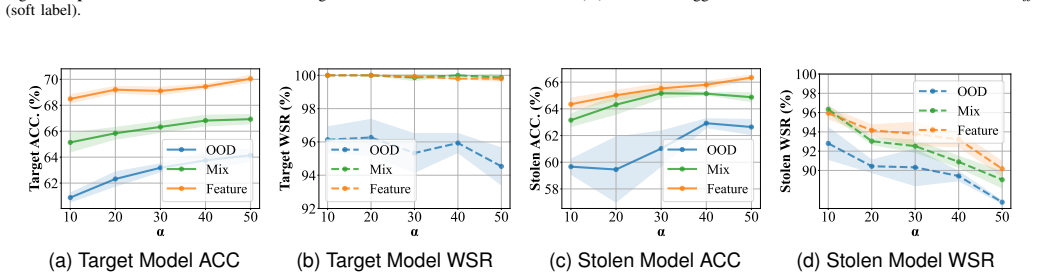
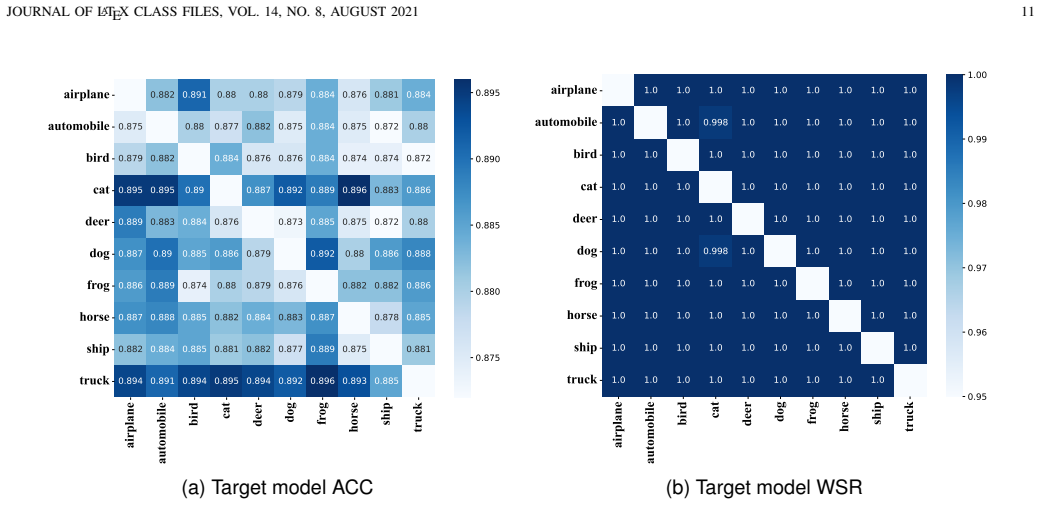
read the original abstract
Model watermarking safeguards AI model intellectual property by embedding distinctive knowledge that induces unique behavioral signatures. The primary technical challenge lies in ensuring watermark robustness against various post-processing attacks on the watermarked model. Model extraction attacks emerge as the most severe threat, where adversaries exploit prediction outputs to train surrogate models that illegally replicate the original model's functionality. In this work, we propose a rehearsal-based watermark embedding framework to enhance the robustness of model watermarks against model extraction attacks. By simulating the extraction process, our method leverages the loss of a \textit{simulated stolen model} on a trigger set as a training signal to fine-tune the watermark knowledge within the target model. This fine-tuning step encourages the watermark to be embedded in a way that boosts transferability, thereby increasing its chances of persisting and remaining detectable in stolen models. Comprehensive experiments conducted under diverse settings demonstrate that the proposed method significantly improves the robustness of model watermarks against both model extraction and subsequent watermark removal attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes T2S, a rehearsal-based watermark embedding framework for model IP protection. It simulates the model extraction process by using the loss of a simulated stolen model on a trigger set as a training signal to fine-tune watermark knowledge in the target model, with the aim of boosting transferability so that the watermark persists and remains detectable in extracted surrogate models. The authors state that comprehensive experiments under diverse settings demonstrate significant improvements in robustness against both model extraction and subsequent watermark removal attacks.
Significance. If the central claim holds under real extraction attacks, the rehearsal-based simulation approach would represent a useful technical contribution to watermarking by directly optimizing for transferability rather than relying solely on post-hoc robustness. This could help address model extraction as the most severe threat to deployed model IP, provided the simulation generalizes beyond matched settings.
major comments (3)
- [Abstract] Abstract: the claim that 'comprehensive experiments conducted under diverse settings demonstrate that the proposed method significantly improves the robustness' is asserted without any quantitative results, baselines, error bars, ablation details, or description of the experimental protocol. This absence prevents verification of the magnitude or reliability of the claimed gains, which are load-bearing for the paper's contribution.
- [Abstract] Method description (abstract): the fine-tuning step uses loss from a 'simulated stolen model' on the trigger set, but provides no specification of how that simulated model is constructed (architecture family, query distribution, training data, or optimization procedure). Without these details the transferability claim cannot be assessed, as the simulation must match the threat model for the robustness gain to hold.
- [Abstract] Abstract / weakest assumption: the method assumes that training against the simulated extractor will produce embeddings robust to real adversaries that may employ different architectures, query budgets, or out-of-distribution data. The provided text gives no indication of experiments testing mismatched simulation vs. attack settings, which directly tests whether the reported robustness improvement generalizes.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on the abstract. We agree that the abstract should better convey key details and will revise it accordingly while preserving its concise nature. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'comprehensive experiments conducted under diverse settings demonstrate that the proposed method significantly improves the robustness' is asserted without any quantitative results, baselines, error bars, ablation details, or description of the experimental protocol. This absence prevents verification of the magnitude or reliability of the claimed gains, which are load-bearing for the paper's contribution.
Authors: The abstract is intentionally high-level. The full manuscript (Section 4) contains the requested quantitative results, including tables with watermark detection rates, extraction robustness metrics, comparisons against multiple baselines, error bars from repeated runs, and ablation studies on the rehearsal component. To address the concern, we will revise the abstract to include a small number of representative quantitative highlights and a brief reference to the experimental protocol. revision: yes
-
Referee: [Abstract] Method description (abstract): the fine-tuning step uses loss from a 'simulated stolen model' on the trigger set, but provides no specification of how that simulated model is constructed (architecture family, query distribution, training data, or optimization procedure). Without these details the transferability claim cannot be assessed, as the simulation must match the threat model for the robustness gain to hold.
Authors: Section 3.2 of the manuscript specifies the simulated stolen model construction: it uses the same architecture family as the target model, is trained on the trigger set queries with the same optimization procedure (cross-entropy loss on the trigger labels), and employs the same data distribution. We will add a concise clause to the abstract describing this construction to make the method description self-contained. revision: yes
-
Referee: [Abstract] Abstract / weakest assumption: the method assumes that training against the simulated extractor will produce embeddings robust to real adversaries that may employ different architectures, query budgets, or out-of-distribution data. The provided text gives no indication of experiments testing mismatched simulation vs. attack settings, which directly tests whether the reported robustness improvement generalizes.
Authors: The full manuscript reports experiments under diverse settings (Section 4.3) that vary model architectures, query budgets, and data distributions, thereby testing generalization beyond perfectly matched simulation. While exhaustive coverage of every possible mismatch is not feasible, the reported settings include several mismatched cases. We will revise the abstract to explicitly reference these generalization experiments. revision: partial
Circularity Check
Rehearsal-based training procedure with empirical validation; no reduction to self-defined inputs
full rationale
The paper introduces a rehearsal-based fine-tuning method that simulates extraction to embed watermarks with claimed higher transferability. The abstract and description present this as a novel training procedure whose effectiveness is asserted via comprehensive experiments under diverse settings. No equations, derivations, or self-citations are shown that reduce the robustness claim to a quantity defined by the same procedure or prior author work. The central contribution remains an empirical algorithm whose performance is measured externally rather than forced by construction, yielding only minor (non-load-bearing) circularity risk at most.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Simlingo: Vision-only closed-loop autonomous driving with language-action align- ment
Katrin Renz, Long Chen, Elahe Arani, and Oleg Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action align- ment. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11993–12003, 2025
2025
-
[2]
Unseen visual anomaly generation
Han Sun, Yunkang Cao, Hao Dong, and Olga Fink. Unseen visual anomaly generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25508–25517, 2025
2025
-
[3]
J. Zhou, X. He, L. Sun, J. Xu, X. Chen, Y . Chu, L. Zhou, X. Liao, B. Zhang, and S. Afvari et al. Pre-trained multimodal large language model enhances dermatological diagnosis using skingpt-4.Nature Communications, 15(1):5649, 2024
2024
-
[4]
Knockoff nets: Stealing functionality of black-box models
Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz. Knockoff nets: Stealing functionality of black-box models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4954–4963, 2019
2019
-
[5]
High accuracy and high fidelity extraction of neural networks
Matthew Jagielski, Nicholas Carlini, David Berthelot, Alex Kurakin, and Nicolas Papernot. High accuracy and high fidelity extraction of neural networks. In29th USENIX security symposium (USENIX Security 20), pages 1345–1362, 2020
2020
-
[6]
Maze: Data-free model stealing attack using zeroth-order gradient estimation
Sanjay Kariyappa, Atul Prakash, and Moinuddin K Qureshi. Maze: Data-free model stealing attack using zeroth-order gradient estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13814–13823, 2021
2021
-
[7]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[8]
Embedding watermarks into deep neural networks
Yusuke Uchida, Yuki Nagai, Shigeyuki Sakazawa, and Shin’ichi Satoh. Embedding watermarks into deep neural networks. InProceedings of the ACM on international conference on multimedia retrieval, pages 269–277, 2017
2017
-
[9]
Protecting intellectual property of deep neural networks with watermarking
Jialong Zhang, Zhongshu Gu, Jiyong Jang, Hui Wu, Marc Ph Stoecklin, Heqing Huang, and Ian Molloy. Protecting intellectual property of deep neural networks with watermarking. InProceedings of the Asia conference on computer and communications security, pages 159–172, 2018
2018
-
[10]
Entangled watermarks as a defense against model extraction
Hengrui Jia, Christopher A Choquette-Choo, Varun Chandrasekaran, and Nicolas Papernot. Entangled watermarks as a defense against model extraction. In30th USENIX security symposium, pages 1937–1954, 2021
1937
-
[11]
Sok: JOURNAL OF LATEX CLASS FILES, VOL
Nils Lukas, Edward Jiang, Xinda Li, and Florian Kerschbaum. Sok: JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 How robust is image classification deep neural network watermarking? In2022 IEEE Symposium on Security and Privacy (SP), pages 787–804. IEEE, 2022
2021
-
[12]
Turning your weakness into a strength: Watermarking deep neural networks by backdooring
Yossi Adi, Carsten Baum, Moustapha Cisse, Benny Pinkas, and Joseph Keshet. Turning your weakness into a strength: Watermarking deep neural networks by backdooring. In27th USENIX security symposium, pages 1615–1631, 2018
2018
-
[13]
MEA- Defender: A Robust Watermark against Model Extraction Attack
Peizhuo Lv, Hualong Ma, Kai Chen, Jiachen Zhou, Shengzhi Zhang, Ruigang Liang, Shenchen Zhu, Pan Li, and Yingjun Zhang. MEA- Defender: A Robust Watermark against Model Extraction Attack . In IEEE Symposium on Security and Privacy (SP), pages 2515–2533, 2024
2024
-
[14]
Deep neural network watermarking against model extraction attack
Jingxuan Tan, Nan Zhong, Zhenxing Qian, Xinpeng Zhang, and Sheng Li. Deep neural network watermarking against model extraction attack. InProceedings of the 31st ACM International Conference on Multime- dia, pages 1588–1597, 2023
2023
-
[15]
Stealing machine learning models via prediction APIs
Florian Tram `er, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning models via prediction APIs. In 25th USENIX security symposium, pages 601–618, 2016
2016
-
[16]
Data-free model extraction
Jean-Baptiste Truong, Pratyush Maini, Robert J Walls, and Nicolas Papernot. Data-free model extraction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4771– 4780, 2021
2021
-
[17]
Towards data-free model stealing in a hard label setting
Sunandini Sanyal, Sravanti Addepalli, and R Venkatesh Babu. Towards data-free model stealing in a hard label setting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15284–15293, 2022
2022
-
[18]
Prediction poisoning: Towards defenses against DNN model stealing attacks
Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz. Prediction poisoning: Towards defenses against DNN model stealing attacks. In International Conference on Learning Representations, 2020
2020
-
[19]
Protecting DNNs from theft using an ensemble of diverse models
Sanjay Kariyappa, Atul Prakash, and Moinuddin K Qureshi. Protecting DNNs from theft using an ensemble of diverse models. InInternational Conference on Learning Representations, 2021
2021
-
[20]
Defending against model stealing attacks with adaptive misinformation
Sanjay Kariyappa and Moinuddin K Qureshi. Defending against model stealing attacks with adaptive misinformation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 770–778, 2020
2020
-
[21]
Stateful detection of black-box adversarial attacks
Steven Chen, Nicholas Carlini, and David Wagner. Stateful detection of black-box adversarial attacks. InProceedings of the 1st ACM Workshop on Security and Privacy on Artificial Intelligence, pages 30–39, 2020
2020
-
[22]
Haitian Zhang, Guang Hua, Xinya Wang, Hao Jiang, and Wen Yang. Categorical inference poisoning: Verifiable defense against black-box DNN model stealing without constraining surrogate data and query times.IEEE Transactions on Information Forensics and Security, 18:1473–1486, 2023
2023
-
[23]
Prada: protecting against dnn model stealing attacks
Mika Juuti, Sebastian Szyller, Samuel Marchal, and N Asokan. Prada: protecting against dnn model stealing attacks. In2019 IEEE European Symposium on Security and Privacy (EuroS&P), pages 512–527. IEEE, 2019
2019
-
[24]
Embedding watermarks into deep neural networks
Yusuke Uchida, Yuki Nagai, Shigeyuki Sakazawa, and Shin’ichi Satoh. Embedding watermarks into deep neural networks. InProceedings of the 2017 ACM on international conference on multimedia retrieval, pages 269–277, 2017
2017
-
[25]
Digital watermarking for deep neural networks.International Journal of Multimedia Information Retrieval, 7(1):3–16, 2018
Yuki Nagai, Yusuke Uchida, Shigeyuki Sakazawa, and Shin’ichi Satoh. Digital watermarking for deep neural networks.International Journal of Multimedia Information Retrieval, 7(1):3–16, 2018
2018
-
[26]
Deepmarks: A secure fingerprinting framework for digital rights management of deep learning models
Huili Chen, Bita Darvish Rouhani, Cheng Fu, Jishen Zhao, and Farinaz Koushanfar. Deepmarks: A secure fingerprinting framework for digital rights management of deep learning models. InProceedings of the 2019 on international conference on multimedia retrieval, pages 105– 113, 2019
2019
-
[27]
Deepsigns: An end-to-end watermarking framework for ownership protection of deep neural networks
Bita Darvish Rouhani, Huili Chen, and Farinaz Koushanfar. Deepsigns: An end-to-end watermarking framework for ownership protection of deep neural networks. InProceedings of the twenty-fourth international conference on architectural support for programming languages and operating systems, pages 485–497, 2019
2019
-
[28]
Delving in the loss landscape to embed robust watermarks into neural networks
Enzo Tartaglione, Marco Grangetto, Davide Cavagnino, and Marco Botta. Delving in the loss landscape to embed robust watermarks into neural networks. In2020 25th International Conference on Pattern Recognition (ICPR), pages 1243–1250. IEEE, 2021
2021
-
[29]
Anti-distillation backdoor attacks: Backdoors can really survive in knowledge distillation
Yunjie Ge, Qian Wang, Baolin Zheng, Xinlu Zhuang, Qi Li, Chao Shen, and Cong Wang. Anti-distillation backdoor attacks: Backdoors can really survive in knowledge distillation. InProceedings of the 29th ACM International Conference on Multimedia, pages 826–834, 2021
2021
-
[30]
Badnets: Evaluating backdooring attacks on deep neural networks.IEEE Access, 7:47230–47244, 2019
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Evaluating backdooring attacks on deep neural networks.IEEE Access, 7:47230–47244, 2019
2019
-
[31]
BERT learns to teach: Knowledge distillation with meta learning
Wangchunshu Zhou, Canwen Xu, and Julian McAuley. BERT learns to teach: Knowledge distillation with meta learning. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 7037–7049, 2022
2022
-
[32]
Narcissus: A practical clean-label backdoor attack with limited information
Yi Zeng, Minzhou Pan, Hoang Anh Just, Lingjuan Lyu, Meikang Qiu, and Ruoxi Jia. Narcissus: A practical clean-label backdoor attack with limited information. InProceedings of the ACM SIGSAC Conference on Computer and Communications Security, pages 771–785, 2023
2023
-
[33]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[34]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[35]
Ipremover: A generative model inversion attack against deep neural network fingerprinting and watermarking
Wei Zong, Yang-Wai Chow, Willy Susilo, Joonsang Baek, Jongkil Kim, and Seyit Camtepe. Ipremover: A generative model inversion attack against deep neural network fingerprinting and watermarking. InThirty- Eighth AAAI Conference on Artificial Intelligence, pages 7837–7845, 2024
2024
-
[36]
Quantized neural networks: Training neural networks with low precision weights and activations.Journal of Machine Learning Research, 18(187):1–30, 2018
Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Quantized neural networks: Training neural networks with low precision weights and activations.Journal of Machine Learning Research, 18(187):1–30, 2018
2018
-
[37]
To prune, or not to prune: Exploring the efficacy of pruning for model compression
Michael Zhu and Suyog Gupta. To prune, or not to prune: Exploring the efficacy of pruning for model compression. InInternational Conference on Learning Representations Workshop, 2017
2017
-
[38]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.