Categorical Robustness Assessment for Machine Learning based Network Intrusion Detection Systems
Pith reviewed 2026-06-27 09:24 UTC · model grok-4.3
The pith
CNNs for network intrusion detection retain most accuracy under adversarial perturbations while Random Forests lose over 70 points at the smallest tested change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
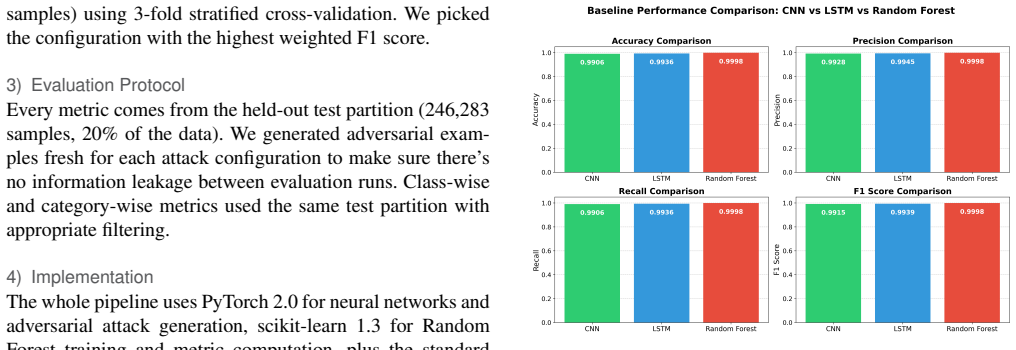
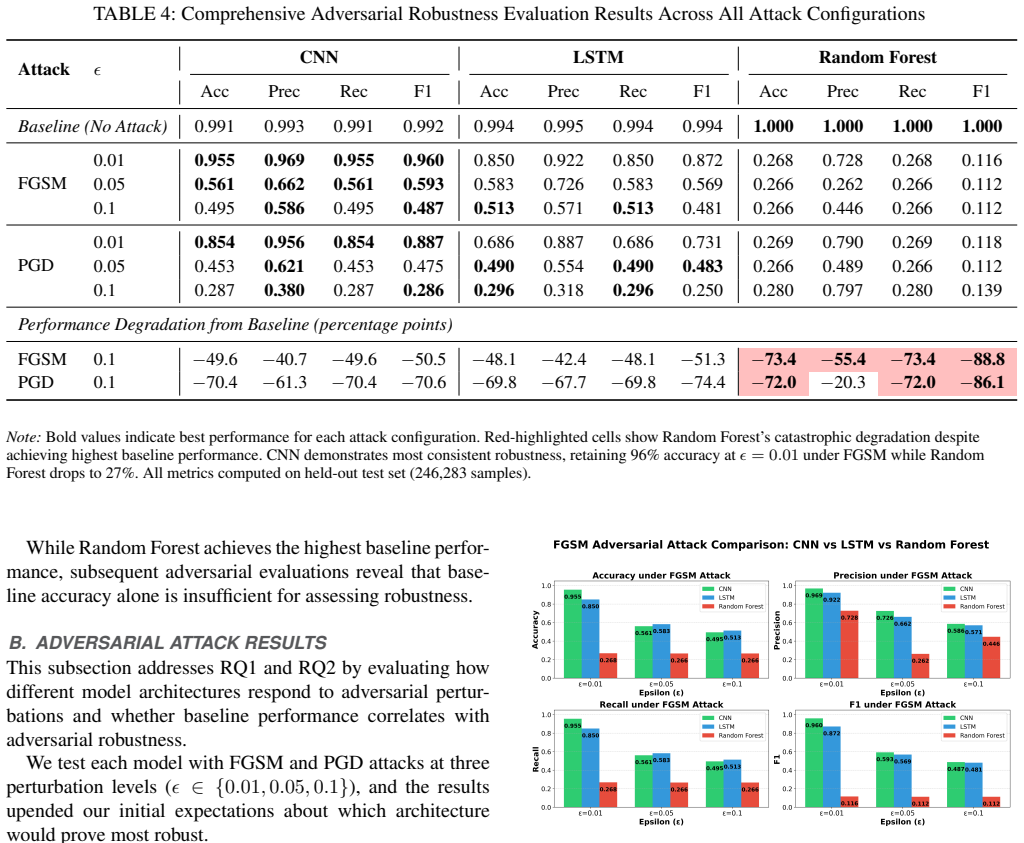
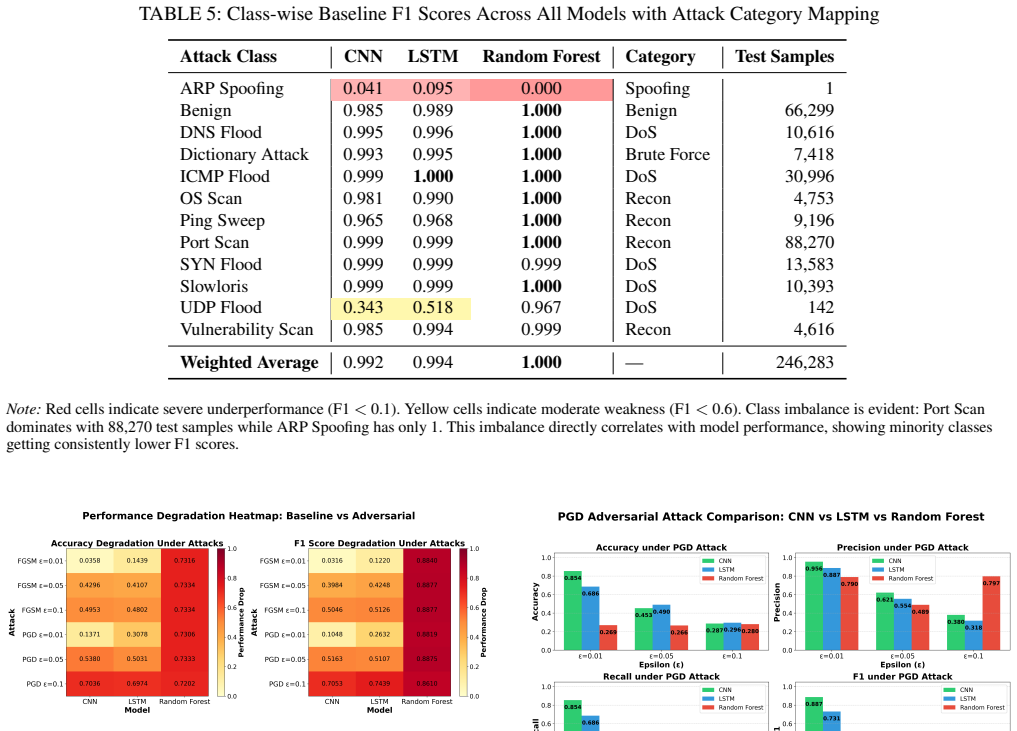
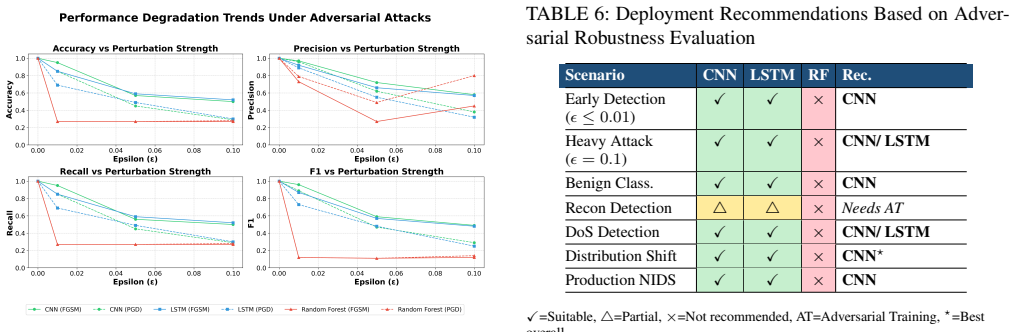
Among the three architectures evaluated on the ACI-IoT-2023 dataset, the 1D convolutional neural network demonstrates the greatest robustness to FGSM and PGD attacks, retaining 95.5 percent accuracy at epsilon equal to 0.01 and degrading gracefully as the perturbation budget increases to 0.1, in contrast to the random forest which falls from a 99.98 percent baseline by 73 percentage points at the smallest epsilon and the LSTM which falls in between.
What carries the argument
Controlled application of FGSM and PGD gradient-based perturbations at fixed epsilon budgets to normalized network traffic features, used to measure accuracy retention across the three classifier architectures.
If this is right
- High baseline accuracy alone is not a reliable predictor of performance when an attacker can apply small input changes.
- CNN architectures should be preferred over random forest ensembles for intrusion detection systems exposed to potential adversarial manipulation.
- LSTM networks provide intermediate robustness, falling between the CNN and random forest under the same attack conditions.
- Deployment choices for network intrusion detection should incorporate expected perturbation strength rather than relying solely on clean-data metrics.
Where Pith is reading between the lines
- If the synthetic perturbations do not map to feasible packet modifications, the measured robustness gaps may not appear in operational traffic.
- Repeating the comparison on datasets with different attack distributions could test whether the CNN advantage generalizes beyond the ACI-IoT-2023 collection.
- Adversarial training applied to the CNN might further widen its robustness margin relative to the other models.
- The pattern of baseline accuracy failing to predict attack resistance may apply to classifier selection in other security domains that use tabular or time-series data.
Load-bearing premise
Gradient-based perturbations added to normalized features produce realistic adversarial network traffic without violating categorical feature constraints or protocol semantics.
What would settle it
Real network packets altered by an attacker who preserves valid protocol formats and categorical values cause the same large accuracy drops in the random forest as the normalized-feature perturbations.
Figures


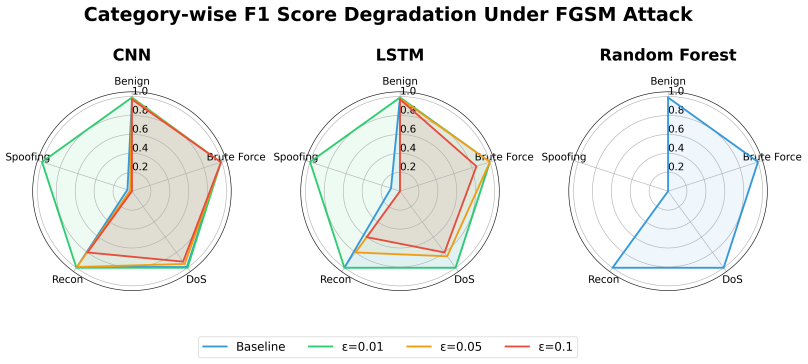
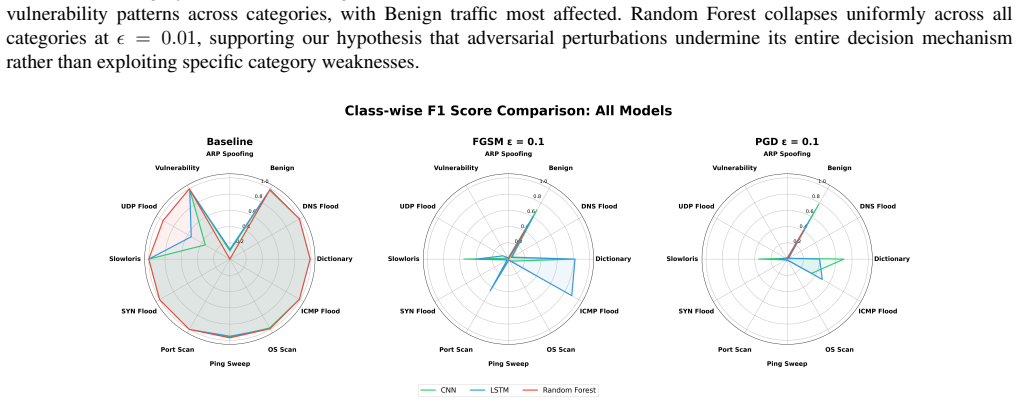
read the original abstract
Network Intrusion Detection Systems (NIDS) heavily utlize Machine Learning (ML) but ML models can be manipulated via adversarial attacks. These attacks add carefully crafted perturbations to network traffic data that leads to misclassifications. While prior work has demonstrated adversarial vulnerabilities in isolated settings, systematic cross-architecture as well as class and category of attack based comparisons under controlled attack conditions remain limited, leaving practitioners without clear guidance on which models to deploy in adversarial environments. This paper asks a simple question: what type of classifier architectures actually hold up when attackers try to manipulate the systems? We put three popular architectures through their paces: a 1D Convolutional Neural Network, a Long Short-Term Memory (LSTM) network, and a Random Forest (RF) ensemble. Using the ACI-IoT-2023 dataset (over 1.2 million samples spanning 12 attack types), we subject each model with FGSM and PGD adversarial attacks, which apply gradient-based perturbations in normalized feature space consistent with established adversarial ML evaluation protocols, at perturbation budgets ranging from $\epsilon=0.01$ to $\epsilon=0.1$. Surprisingly, Random Forest achieved near-perfect baseline accuracy (99.98\%), yet collapsed catastrophically under attack, dropping 73 percentage points at the smallest perturbation we tested. CNN, on the other hand, retained 95.5\% accuracy at $\epsilon=0.01$ and degraded gracefully as perturbations increased. LSTM fell somewhere in between. These findings flip the conventional wisdom where high baseline accuracy means nothing if a model shatters at the first sign of adversarial pressure. For practitioners deploying intrusion detection in adversarial environments, we recommend CNN-based architectures and provide scenario-specific deployment guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates adversarial robustness of 1D-CNN, LSTM, and Random Forest classifiers on the ACI-IoT-2023 dataset (1.2M samples, 12 attack types) using FGSM and PGD attacks at ε from 0.01 to 0.1. It reports RF baseline accuracy of 99.98% collapsing by 73pp at the smallest ε, while CNN retains 95.5% at ε=0.01 and degrades more gracefully; LSTM is intermediate. The central claim is that high baseline accuracy is not indicative of robustness and that CNN architectures are preferable for adversarial NIDS settings.
Significance. If the reported accuracy drops reflect robustness to feasible adversarial traffic rather than sensitivity to invalid inputs, the result would be significant for practitioners selecting NIDS models, as it directly challenges reliance on high-accuracy ensembles like RF. The cross-architecture comparison under controlled budgets is a useful empirical contribution, though its impact is reduced by the lack of evidence that perturbations respect categorical constraints.
major comments (1)
- [Abstract] Abstract and experimental setup description: the attacks are described as applying 'gradient-based perturbations in normalized feature space consistent with established adversarial ML evaluation protocols' with no mention of masking, one-hot projection, discrete rounding, or valid-range enforcement for categorical features (protocol, flags, service) known to be present in ACI-IoT-2023. Continuous perturbations on these features produce non-packet inputs, so the measured drops (e.g., RF 73pp collapse) may quantify sensitivity to invalid samples rather than realistic adversarial robustness.
minor comments (1)
- [Abstract] Abstract: 'utlize' is a typo for 'utilize'; 'leads to misclassifications' should be 'lead to misclassifications'.
Simulated Author's Rebuttal
We thank the referee for highlighting an important methodological consideration regarding the treatment of categorical features under adversarial perturbations. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental setup description: the attacks are described as applying 'gradient-based perturbations in normalized feature space consistent with established adversarial ML evaluation protocols' with no mention of masking, one-hot projection, discrete rounding, or valid-range enforcement for categorical features (protocol, flags, service) known to be present in ACI-IoT-2023. Continuous perturbations on these features produce non-packet inputs, so the measured drops (e.g., RF 73pp collapse) may quantify sensitivity to invalid samples rather than realistic adversarial robustness.
Authors: We agree that the manuscript does not describe any masking, one-hot projection, rounding, or range enforcement for categorical features, and that unconstrained perturbations on normalized features can produce invalid combinations (e.g., non-existent protocol values). This means the reported accuracy drops reflect model sensitivity to perturbations in the normalized space rather than strictly feasible adversarial traffic. Our experiments followed the standard gradient-based protocol on normalized tabular features as described, without additional categorical constraints. To address the concern, we will revise the experimental setup, abstract, and discussion sections to explicitly state this limitation and its implications for interpreting the results as realistic robustness. We will also note that the findings still demonstrate differential architectural sensitivity under controlled perturbation budgets. This constitutes a major revision to the manuscript. revision: yes
Circularity Check
No circularity: purely empirical measurements
full rationale
The paper conducts an empirical study: models (CNN, LSTM, RF) are trained on ACI-IoT-2023, then evaluated under FGSM/PGD perturbations with reported accuracy drops. No equations, derivations, parameter fits, or predictions are claimed. No self-citations are load-bearing for any result. The central findings are direct outputs of the described experiments, with no reduction of outputs to inputs by construction. The noted concern about categorical feature validity is a methodological limitation, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FGSM and PGD attacks in normalized feature space are valid for assessing NIDS model robustness
Reference graph
Works this paper leans on
-
[1]
The average size of matchings in graphs
A. Ahmim, L. Maglaras, M. A. Ferrag, M. Derdour, and H. Janicke, “A novel hierarchical intrusion detection system based on decision tree and rules-based models,” arXiv preprint arXiv:1903.09825, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[2]
Toward generating a new intrusion detection dataset and intrusion traffic characterization,
I. Sharafaldin, A. H. Lashkari, and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization,” in International Conference on Information Systems Security and Privacy, 2018, pp. 108–116
2018
-
[3]
Kitsune: An ensem- ble of autoencoders for online network intrusion detection,
Y . Mirsky, T. Doitshman, Y . Elovici, and A. Shabtai, “Kitsune: An ensem- ble of autoencoders for online network intrusion detection,” in Network and Distributed System Security Symposium (NDSS), 2018
2018
-
[4]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Towards evaluating the robustness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in IEEE Symposium on Security and Privacy (SP). IEEE, 2017, pp. 39–57
2017
-
[7]
Classifying IoT devices in smart environments using network traffic characteristics,
A. Sivanathan, H. H. Gharakheili, F. Loi, A. Radford, C. Wiber, A. Vish- wanath, and V . Sivaraman, “Classifying IoT devices in smart environments using network traffic characteristics,” IEEE Transactions on Mobile Com- puting, vol. 18, no. 8, pp. 1745–1759, 2018
2018
-
[8]
Understanding the Mirai botnet,
M. Antonakakis, T. April, M. Bailey et al., “Understanding the Mirai botnet,” in USENIX Security Symposium, 2017, pp. 1093–1110
2017
-
[9]
The Internet of Things: A survey,
L. Atzori, A. Iera, and G. Morabito, “The Internet of Things: A survey,” Computer Networks, vol. 54, no. 15, pp. 2787–2805, 2010
2010
-
[10]
Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues,
I. Corona, G. Giacinto, and F. Roli, “Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues,” Information Sciences, vol. 239, pp. 201–225, 2013
2013
-
[11]
Intrusion detection systems vulnerability on adversarial examples,
A. Warzynski and G. Kolaczek, “Intrusion detection systems vulnerability on adversarial examples,” in Innovations in Intelligent Systems and Appli- cations (INISTA). IEEE, 2018, pp. 1–4
2018
-
[12]
Modeling realistic adversarial attacks against network intrusion detection systems,
G. Apruzzese, M. Colajanni, L. Ferretti, and M. Marchetti, “Modeling realistic adversarial attacks against network intrusion detection systems,” Digital Threats: Research and Practice, vol. 3, no. 3, pp. 1–19, 2022
2022
-
[13]
Intriguing properties of adversarial ml attacks in the problem space [extended version],
J. Cortellazzi, E. Quiring, D. Arp, F. Pendlebury, F. Pierazzi, and L. Cavallaro, “Intriguing properties of adversarial ml attacks in the problem space [extended version],” Digital Threats: Research and Practice, vol. 28, no. 4, Sep. 2025. [Online]. Available: https: //doi.org/10.1145/3742895
-
[14]
Explicit Motion Risk Representation
M. J. Hashemi and E. Keller, “Towards evaluation of NIDS in adversarial setting,” arXiv preprint arXiv:1904.08003, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[15]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[16]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[17]
Random forests,
L. Breiman, “Random forests,” Machine Learning, vol. 45, no. 1, pp. 5–32, 2001
2001
-
[18]
ACI-IoT-2023: A comprehensive IoT network traffic dataset,
E. C. P. Neto, S. Dadkhah, R. Ferreira, A. Zohourian, R. Lu, and A. A. Ghorbani, “ACI-IoT-2023: A comprehensive IoT network traffic dataset,” Canadian Institute for Cybersecurity, University of New Brunswick, 2023
2023
-
[19]
Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
N. Papernot, P. McDaniel, and I. Goodfellow, “Transferability in machine learning: From phenomena to black-box attacks using adversarial sam- ples,” arXiv preprint arXiv:1605.07277, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Evaluating the robustness of neural networks: An extreme value theory approach,
T.-W. Weng, H. Zhang, P.-Y . Chen, J. Yi, D. Su, Y . Gao, C.-J. Hsieh, and L. Daniel, “Evaluating the robustness of neural networks: An extreme value theory approach,” in International Conference on Learning Repre- sentations (ICLR), 2018
2018
-
[21]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” in International Conference on Learning Representations (ICLR), 2014
2014
-
[22]
Quiñonero-Candela, M
J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence, Dataset Shift in Machine Learning. MIT Press, 2008
2008
-
[23]
Batch normalization: Accelerating deep network training by reducing internal covariate shift,
S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in International Conference on Machine Learning (ICML), 2015, pp. 448–456
2015
-
[24]
Adversarial machine learning in network intrusion detection systems,
E. Alhajjar, P. Maxwell, and N. Bastian, “Adversarial machine learning in network intrusion detection systems,” Expert Systems with Applications, vol. 186, p. 115782, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0957417421011507 MA Y ANK RAJ(Student Member, IEEE & COM- SOC) is currently pursuing his Master of Science in Da...
2021
-
[25]
He is currently an Assistant Professor in the Department of Electrical Engineering & Computer Science at the United States Military Academy at West Point, and he serves as Deputy Director of the Robotics Research Center and Principal Inves- tigator of the Laboratory for Artificial Intelligence Research & Engineering (LAIRE). His primary research interests...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.