Finding Sparse Subnetworks in One Training Cycle via Progressive Magnitude-Based Pruning
Pith reviewed 2026-06-27 10:09 UTC · model grok-4.3
The pith
Progressive magnitude-based pruning identifies sparse subnetworks in a single training cycle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
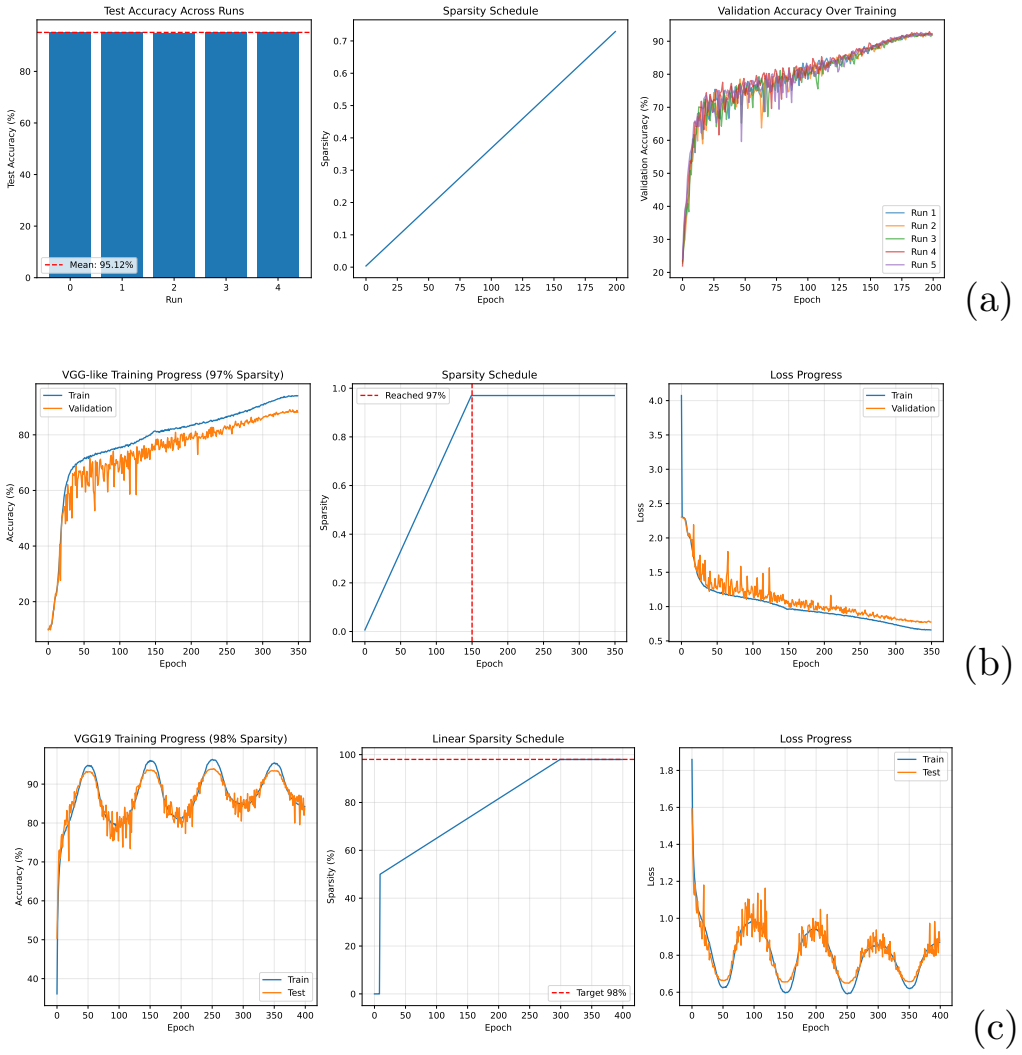
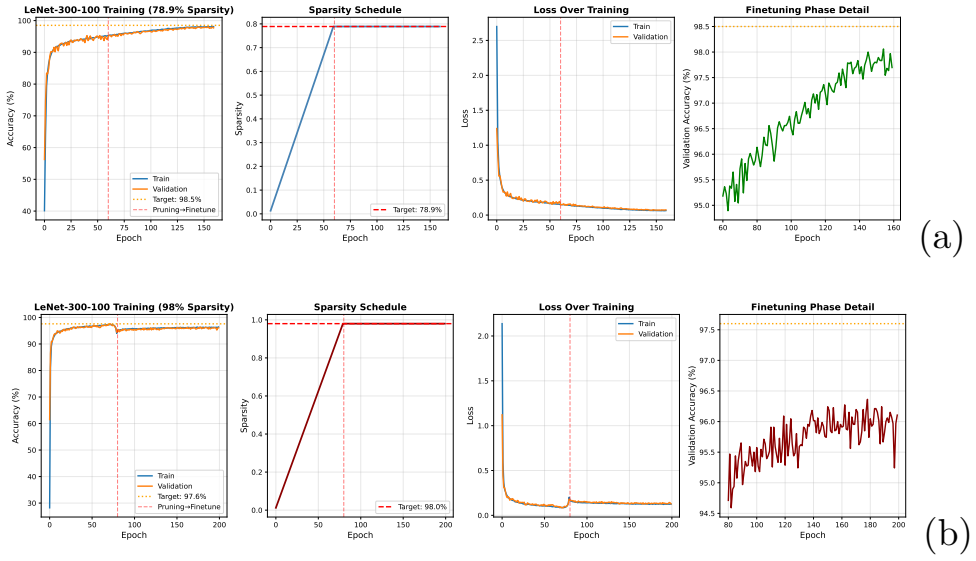
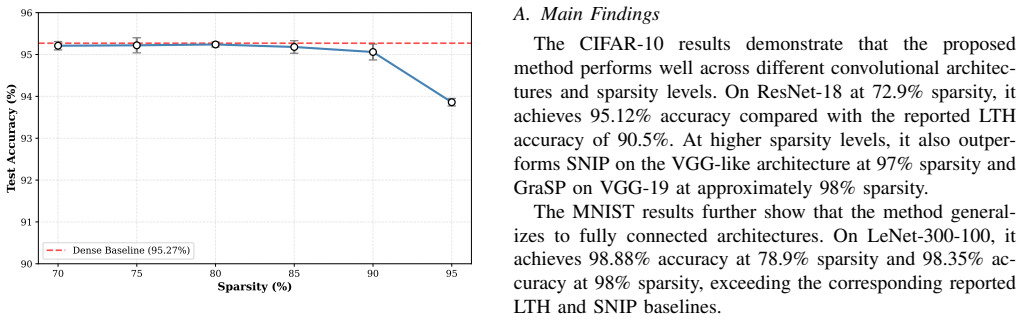
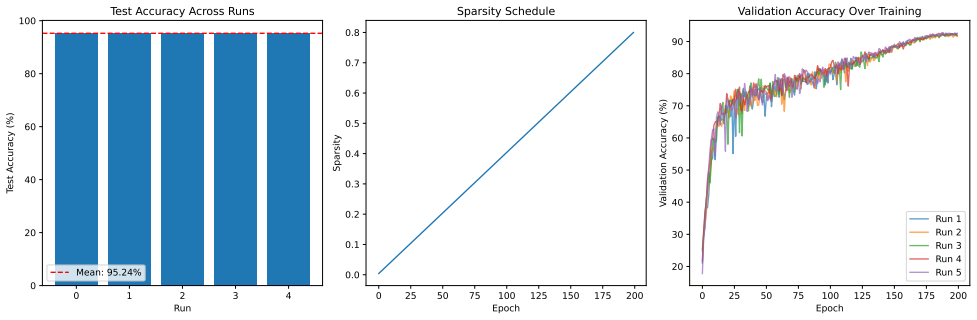
The paper claims that progressive magnitude-based pruning provides an effective single-cycle approach for neural network sparsification, achieving 95.12 percent accuracy on ResNet-18 at 72.9 percent sparsity on CIFAR-10 compared with 90.5 percent for LTH, 93.13 percent on a VGG-like net at 97 percent sparsity, and 93.44 percent on VGG-19 at 97.97 percent sparsity compared with 92.19 percent for GraSP at 98 percent sparsity.
What carries the argument
Progressive magnitude-based pruning, which applies a linear sparsity schedule and updates the pruning mask from the magnitudes of currently active weights throughout a single training cycle.
If this is right
- Sparse subnetworks can be identified without multiple complete training cycles from scratch.
- Accuracy on ResNet-18 stays within 0.1 percentage points of the dense baseline from 70 to 85 percent sparsity.
- The method reaches or exceeds the accuracy of SNIP and GraSP at extreme sparsity levels near 97-98 percent.
- The single-cycle procedure applies across ResNet, VGG-style, and LeNet architectures on both CIFAR-10 and MNIST.
Where Pith is reading between the lines
- The linear schedule could be tested with other mask-update rules to see whether further efficiency gains are possible.
- This single-cycle route may cut the total compute needed for model compression in settings where repeated full trainings are expensive.
- Running the same protocol on larger datasets such as ImageNet would show whether the reported accuracy retention scales beyond the small-image cases examined.
- Dynamic mask updates during training may capture task-relevant weights more reliably than one-shot initialization-based selection.
Load-bearing premise
That a linear sparsity schedule combined with repeated magnitude-based mask updates during one training run will consistently locate high-performing subnetworks without the need for iterative retraining from scratch.
What would settle it
An experiment on the same ResNet-18 and CIFAR-10 setup that records accuracy well below 95.12 percent at 72.9 percent sparsity, or below the LTH baseline, would falsify the claim that the single-cycle method is effective.
Figures
read the original abstract
Neural network pruning reduces model size by removing less important parameters while aiming to preserve predictive performance. Although the Lottery Ticket Hypothesis (LTH) shows that sparse subnetworks can match dense networks when trained from suitable initializations, its iterative pruning procedure requires multiple complete training cycles. This work evaluates progressive magnitude-based pruning as a single-cycle alternative. The method gradually increases sparsity during training using a linear schedule and updates pruning masks based on active weight magnitudes. We conduct systematic experiments on CIFAR-10 and MNIST across ResNet, VGG-style, and LeNet architectures, comparing the proposed method with representative iterative and initialization-based pruning baselines, including LTH, SNIP, and GraSP. On CIFAR-10, the method achieves 95.12\% accuracy on ResNet-18 at 72.9\% sparsity, compared with 90.5\% reported for LTH. At extreme sparsity, it achieves 93.13\% accuracy on a VGG-like architecture at 97\% sparsity, compared with approximately 92.0\% for SNIP, and 93.44\% accuracy on VGG-19 at 97.97\% sparsity, compared with 92.19\% for GraSP at 98\% sparsity. A sparsity-accuracy analysis on ResNet-18 further shows that accuracy remains within 0.1 percentage points of the dense baseline across 70--85\% sparsity. These results indicate that progressive magnitude-based pruning provides an effective single-cycle approach for neural network sparsification under the evaluated settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes progressive magnitude-based pruning, a single-cycle method that applies a linear sparsity schedule and repeatedly updates pruning masks based on current weight magnitudes during one training run. It evaluates the approach on CIFAR-10 and MNIST using ResNet, VGG-style, and LeNet architectures, reporting results such as 95.12% accuracy on ResNet-18 at 72.9% sparsity (vs. 90.5% cited for LTH), 93.13% on a VGG-like net at 97% sparsity (vs. ~92.0% for SNIP), and 93.44% on VGG-19 at 97.97% sparsity (vs. 92.19% for GraSP at 98%), with accuracy remaining within 0.1 pp of the dense baseline for 70-85% sparsity on ResNet-18.
Significance. If the single-cycle results hold under matched training protocols, the method would offer a practical efficiency gain over multi-cycle iterative pruning (LTH) and initialization-based methods (SNIP, GraSP) by locating competitive subnetworks without repeated full retraining from scratch. The reported stability of accuracy across a wide sparsity band on ResNet-18 is a concrete empirical observation worth confirming.
major comments (3)
- [Abstract] Abstract: The headline comparison (95.12% vs. 90.5% LTH on ResNet-18 CIFAR-10 at 72.9% sparsity) cites previously published LTH numbers rather than re-running LTH under identical optimizer, epoch count, learning-rate schedule, data augmentation, and random seeds. Because the proposed method uses a single training trajectory with repeated mask updates, any mismatch in the underlying dense training protocol confounds attribution of the gap to the progressive schedule itself.
- [Abstract] Abstract: No error bars, standard deviations, or number of independent runs are reported for any accuracy figure, and the text gives no indication that the listed sparsity levels were pre-specified rather than selected post-hoc from a larger set of trials. Both omissions are load-bearing for the claim that the method “achieves” the stated accuracies at the stated sparsities.
- [Abstract] Abstract: The manuscript does not state or verify that the single training cycle consumes the same total compute budget (epochs imes FLOPs) as the multi-cycle baselines to which it is compared; without this equivalence the efficiency advantage cannot be isolated from possible differences in total training effort.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to improve clarity, statistical reporting, and experimental rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline comparison (95.12% vs. 90.5% LTH on ResNet-18 CIFAR-10 at 72.9% sparsity) cites previously published LTH numbers rather than re-running LTH under identical optimizer, epoch count, learning-rate schedule, data augmentation, and random seeds. Because the proposed method uses a single training trajectory with repeated mask updates, any mismatch in the underlying dense training protocol confounds attribution of the gap to the progressive schedule itself.
Authors: We agree that direct re-implementation of LTH under the exact same training protocol would strengthen the comparison and reduce potential confounding. While citing reported numbers follows common practice in the pruning literature, we will re-run LTH (and other baselines where feasible) using our optimizer, epoch count, learning-rate schedule, data augmentation, and random seeds in the revised manuscript to enable a matched-protocol evaluation. revision: yes
-
Referee: [Abstract] Abstract: No error bars, standard deviations, or number of independent runs are reported for any accuracy figure, and the text gives no indication that the listed sparsity levels were pre-specified rather than selected post-hoc from a larger set of trials. Both omissions are load-bearing for the claim that the method “achieves” the stated accuracies at the stated sparsities.
Authors: We acknowledge the importance of reporting variance and clarifying experimental design choices. The sparsity levels were pre-specified based on standard ranges used in prior work (e.g., 70–98% sparsity). In the revision we will report mean accuracy and standard deviation over multiple independent runs (with fixed seeds for reproducibility) and explicitly state how sparsity targets were chosen. revision: yes
-
Referee: [Abstract] Abstract: The manuscript does not state or verify that the single training cycle consumes the same total compute budget (epochs × FLOPs) as the multi-cycle baselines to which it is compared; without this equivalence the efficiency advantage cannot be isolated from possible differences in total training effort.
Authors: The method is intentionally single-cycle, so its total compute for subnetwork discovery is one training run by design, whereas LTH requires multiple full cycles. We will add an explicit compute analysis (epochs and approximate FLOPs) comparing our single-cycle procedure against the multi-cycle baselines to make the efficiency difference transparent and to isolate the contribution of the progressive schedule. revision: yes
Circularity Check
No significant circularity; purely empirical method with external comparisons
full rationale
The paper describes a progressive magnitude-based pruning algorithm and evaluates it through experiments on CIFAR-10 and MNIST. No equations, derivations, or self-citations are present that reduce any performance claim to a fitted input or prior result by construction. Reported accuracies (e.g., 95.12% at 72.9% sparsity) are direct experimental outputs, not predictions forced by the method's own parameters. Comparisons to LTH, SNIP, and GraSP cite external reported numbers without any internal reduction or self-referential loop. This is a standard empirical pruning study with no load-bearing self-definitional or fitted-input steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” inProc. Advances in Neural Information Processing Systems (NeurIPS), pp. 1097–1105, 2012
2012
-
[2]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 5998–6008, 2017
2017
-
[3]
Deep neural networks for acoustic modeling in speech recognition,
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V . Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury, “Deep neural networks for acoustic modeling in speech recognition,” IEEE Signal Processing Magazine, vol. 29, pp. 82–97, Nov 2012
2012
-
[4]
Efficient processing of deep neural networks: A tutorial and survey,
V . Sze, Y .-H. Chen, T.-J. Yang, and J. S. Emer, “Efficient processing of deep neural networks: A tutorial and survey,”Proceedings of the IEEE, vol. 105, pp. 2295–2329, Dec 2017
2017
-
[5]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” inProc. IEEE Int. Solid-State Circuits Conf. (ISSCC), (San Francisco, CA, USA), pp. 10–14, Feb 2014
2014
-
[6]
A survey of model compression and acceleration for deep neural networks,
Y . Cheng, D. Wang, P. Zhou, and T. Zhang, “A survey of model compression and acceleration for deep neural networks,”IEEE Signal Processing Magazine, vol. 35, pp. 126–136, Jan 2018
2018
-
[7]
The lottery ticket hypothesis: Finding sparse, trainable neural networks,
J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” inProc. Int. Conf. Learning Representations (ICLR), (New Orleans, LA, USA), 2019
2019
-
[8]
Stabilizing the lottery ticket hypothesis,
J. Frankle, G. K. Dziugaite, D. M. Roy, and M. Carbin, “Stabilizing the lottery ticket hypothesis,”arXiv preprint arXiv:1903.01611, 2019
-
[9]
The State of Sparsity in Deep Neural Networks
T. Gale, E. Elsen, and S. Hooker, “The state of sparsity in deep neural networks,”arXiv preprint arXiv:1902.09574, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[10]
Snip: Single-shot network pruning based on connection sensitivity,
N. Lee, T. Ajanthan, and P. H. S. Torr, “Snip: Single-shot network pruning based on connection sensitivity,” inProc. Int. Conf. Learning Representations (ICLR), (New Orleans, LA, USA), 2019
2019
-
[11]
Picking winning tickets before training by preserving gradient flow,
C. Wang, G. Zhang, and R. Grosse, “Picking winning tickets before training by preserving gradient flow,” inProc. Int. Conf. Learning Representations (ICLR), (Addis Ababa, Ethiopia), 2020
2020
-
[12]
Pruning neural networks without any data by iteratively conserving synaptic flow,
H. Tanaka, D. Kunin, D. L. Yamins, and S. Ganguli, “Pruning neural networks without any data by iteratively conserving synaptic flow,” in Proc. Advances in Neural Information Processing Systems (NeurIPS), pp. 6377–6389, 2020
2020
-
[13]
Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science,
D. C. Mocanu, E. Mocanu, P. Stone, P. H. Nguyen, M. Gibescu, and A. Liotta, “Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science,”Nature Communica- tions, vol. 9, pp. 1–12, Jun 2018
2018
-
[14]
Rigging the lottery: Making all tickets winners,
U. Evci, T. Gale, J. Menick, P. S. Castro, and E. Elsen, “Rigging the lottery: Making all tickets winners,” inProc. Int. Conf. Machine Learning (ICML), pp. 2943–2952, 2020
2020
-
[15]
To prune, or not to prune: Exploring the efficacy of pruning for model compression,
M. Zhu and S. Gupta, “To prune, or not to prune: Exploring the efficacy of pruning for model compression,” inICLR Workshop, (Vancouver, Canada), 2018
2018
-
[16]
Regional differences in synap- togenesis in human cerebral cortex,
P. R. Huttenlocher and A. S. Dabholkar, “Regional differences in synap- togenesis in human cerebral cortex,”Journal of Comparative Neurology, vol. 387, pp. 167–178, Oct 1997
1997
-
[17]
Synaptic pruning in de- velopment: A computational account,
G. Chechik, I. Meilijson, and E. Ruppin, “Synaptic pruning in de- velopment: A computational account,”Neural Computation, vol. 10, pp. 1759–1777, Oct 1998
1998
-
[18]
Optimizing neural networks using sparsity and pruning techniques,
R. Qureshi and M. Hosny, “Optimizing neural networks using sparsity and pruning techniques,”Journal of Computer Science, vol. 19, no. 3, 2026
2026
-
[19]
Learning both weights and connections for efficient neural networks,
S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural networks,” inProc. Advances in Neural Information Processing Systems (NeurIPS), pp. 1135–1143, 2015
2015
-
[20]
One ticket to win them all: Generalizing lottery ticket initializations across datasets and optimizers,
A. S. Morcos, H. Yu, M. Paganini, and Y . Tian, “One ticket to win them all: Generalizing lottery ticket initializations across datasets and optimizers,” inProc. Advances in Neural Information Processing Systems (NeurIPS), pp. 4932–4942, 2019
2019
-
[21]
The lottery ticket hypothesis for pre-trained bert networks,
T. Chen, J. Frankle, S. Chang, S. Liu, Y . Zhang, Z. Wang, and M. Carbin, “The lottery ticket hypothesis for pre-trained bert networks,” inProc. Advances in Neural Information Processing Systems (NeurIPS), pp. 15834–15846, 2020
2020
-
[22]
Proving the lottery ticket hypothesis: Pruning is all you need,
E. Malach, G. Yehudai, S. Shalev-Shwartz, and O. Shamir, “Proving the lottery ticket hypothesis: Pruning is all you need,” inProc. Int. Conf. Machine Learning (ICML), pp. 6682–6691, 2020
2020
-
[23]
What is the state of neural network pruning?,
D. Blalock, J. J. G. Ortiz, J. Frankle, and J. Guttag, “What is the state of neural network pruning?,” inProc. Machine Learning and Systems (MLSys), vol. 2, pp. 129–146, 2020
2020
-
[24]
Deconstructing lottery tickets: Zeros, signs, and the supermask,
H. Zhou, J. Lan, R. Liu, and J. Yosinski, “Deconstructing lottery tickets: Zeros, signs, and the supermask,” inProc. Advances in Neural Information Processing Systems (NeurIPS), vol. 32, pp. 3597–3607, 2019
2019
-
[25]
What’s hidden in a randomly weighted neural network?,
V . Ramanujan, M. Wortsman, A. Kembhavi, A. Farhadi, and M. Raste- gari, “What’s hidden in a randomly weighted neural network?,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), (Seattle, W A, USA), pp. 11893–11902, Jun 2020
2020
-
[26]
Dynamic sparse training: Find efficient sparse network from scratch with trainable masked layers,
S. Liu, T. Chen, X. Chen, L. Atashgahi, G. Dijk, E. Wijmans, M. Salz- mann, L. V . Gool, and P. Fua, “Dynamic sparse training: Find efficient sparse network from scratch with trainable masked layers,” inProc. Int. Conf. Learning Representations (ICLR), (Vienna, Austria), 2020
2020
-
[27]
Layer-adaptive sparsity for the magnitude-based pruning,
J. Lee, S. Park, S. Mo, S. Ahn, and J. Shin, “Layer-adaptive sparsity for the magnitude-based pruning,” inProc. Int. Conf. Learning Repre- sentations (ICLR), (Vienna, Austria), 2021
2021
-
[28]
Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” inProc. Int. Conf. Learning Representations (ICLR), (San Juan, Puerto Rico), 2016
2016
-
[29]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[30]
Exploiting linear structure within convolutional networks for efficient evaluation,
E. L. Denton, W. Zaremba, J. Bruna, Y . LeCun, and R. Fergus, “Exploiting linear structure within convolutional networks for efficient evaluation,” inProc. Advances in Neural Information Processing Sys- tems (NeurIPS), vol. 27, pp. 1269–1277, 2014
2014
-
[31]
Variational dropout spar- sifies deep neural networks,
D. Molchanov, A. Ashukha, and D. Vetrov, “Variational dropout spar- sifies deep neural networks,” inProc. Int. Conf. Machine Learning (ICML), pp. 2498–2507, 2017
2017
-
[32]
Learning sparse neural networks throughl 0 regularization,
C. Louizos, M. Welling, and D. P. Kingma, “Learning sparse neural networks throughl 0 regularization,” inProc. Int. Conf. Learning Rep- resentations (ICLR), (Vancouver, Canada), 2018
2018
-
[33]
Algorithm 65: Find,
C. A. R. Hoare, “Algorithm 65: Find,”Communications of the ACM, vol. 4, no. 7, pp. 321–322, 1961
1961
-
[34]
Time bounds for selection,
M. Blum, R. W. Floyd, V . Pratt, R. L. Rivest, and R. E. Tarjan, “Time bounds for selection,”Journal of Computer and System Sciences, vol. 7, no. 4, pp. 448–461, 1973
1973
-
[35]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, pp. 2278–2324, Nov 1998
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.