Context-Driven Incremental Compression for Multi-Turn Dialogue Generation
Pith reviewed 2026-06-27 09:49 UTC · model grok-4.3
The pith
Context-Driven Incremental Compression keeps dialogue models stable by revising per-thread states in a shared memory at each turn.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
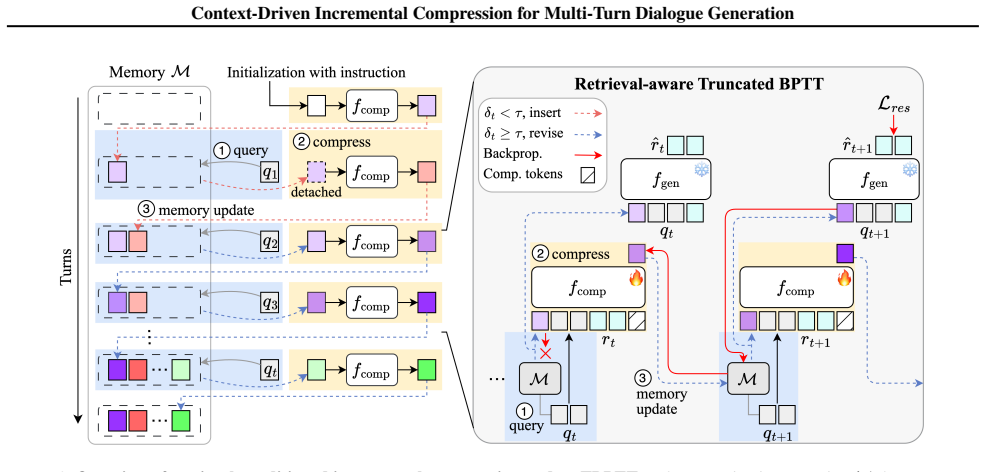
C-DIC treats a conversation as interleaved contextual threads and stores revisable per-thread compression states in a single compact dialogue memory. At each turn a retrieve-revise-write-back loop shares information across turns and updates stale memories, while an adaptation of truncated backpropagation-through-time learns cross-turn dependencies without full-history backpropagation.
What carries the argument
The per-thread compression states held in a compact dialogue memory and updated by a retrieve-revise-write-back loop.
If this is right
- Inference latency remains constant rather than scaling with total history length.
- Perplexity stays flat across hundreds of dialogue turns instead of degrading.
- Cross-turn dependencies can be learned with truncated backpropagation-through-time rather than full-history gradients.
- The same memory mechanism yields higher scores than baselines on long-form dialogue benchmarks.
Where Pith is reading between the lines
- The thread-based revision pattern could apply to any incremental generation task where context accumulates, such as long-document editing or multi-step planning.
- Explicit decomposition into revisable threads may reduce error propagation in other memory-augmented models that currently rely on monolithic summaries.
- Stable long-horizon behavior without periodic resets would let deployed dialogue systems maintain quality in extended sessions without external summarization steps.
Load-bearing premise
Conversations can be decomposed into interleaved contextual threads whose compression states can be revised incrementally without information loss or compounding errors across turns.
What would settle it
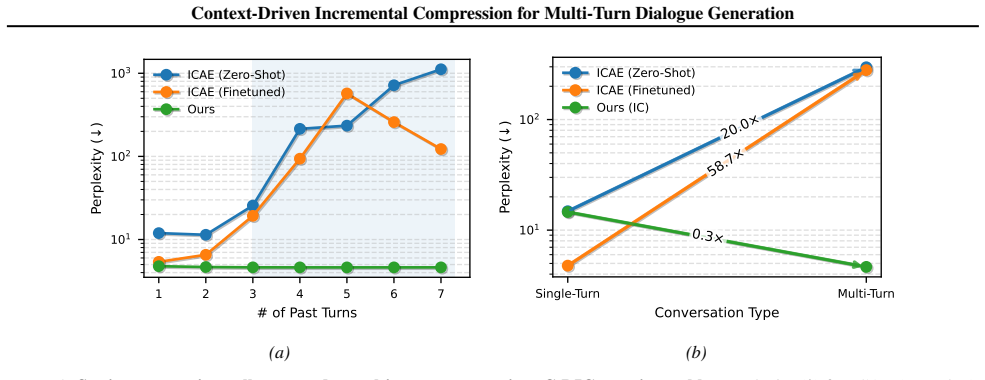
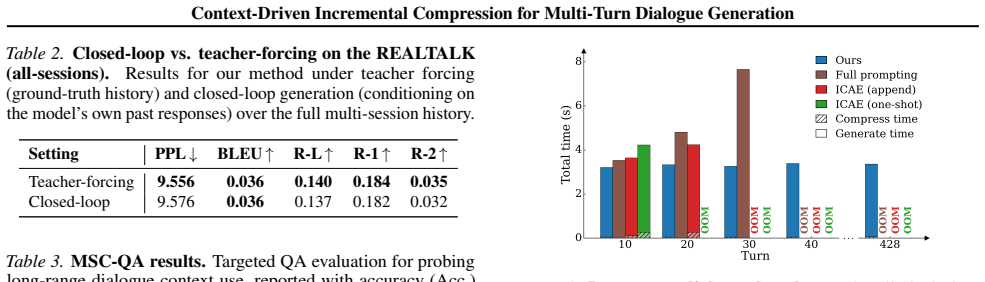
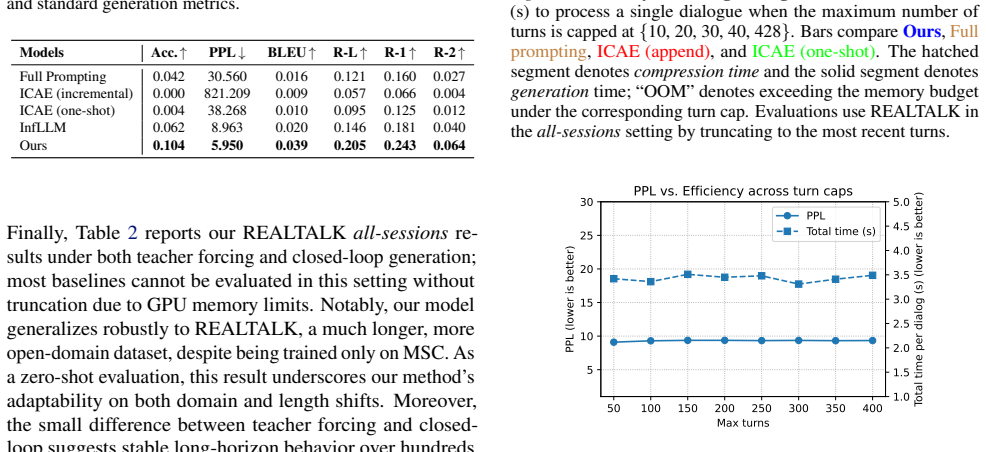
An experiment on a long dialogue benchmark in which C-DIC perplexity or latency begins to rise after roughly 200 turns would falsify the stability claim.
Figures



read the original abstract
Modern conversational agents condition on an ever-growing dialogue history at each turn, incurring redundant attention and encoding costs that grow with conversation length. Naive truncation or summarization degrades fidelity, while existing context compressors lack cross-turn memory sharing or revision, causing information loss and compounding errors in long dialogues. We revisit the context compression under conversational dynamics and empirically present its fragility. To improve both efficiency and robustness, we introduce Context-Driven Incremental Compression (C-DIC), which treats a conversation as interleaved contextual threads and stores revisable per-thread compression states in a single, compact dialogue memory. At each turn, a lightweight retrieve, revise, and write-back loop shares information across turns and updates stale memories, stabilizing long-horizon behavior. In addition, we adapt truncated backpropagation-through-time (TBPTT) to our multi-turn setting, learning cross-turn dependencies without full-history backpropagation. Extensive experiments on long-form dialogue benchmarks demonstrate superior performance and efficiency of C-DIC; notably, C-DIC shows stable inference latency and perplexity over hundreds of dialogue turns, supporting a scalable path to high-quality dialogue modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Context-Driven Incremental Compression (C-DIC) to address growing attention costs in long multi-turn dialogues. It models conversations as interleaved contextual threads whose compression states are stored in a compact dialogue memory and updated via a retrieve-revise-write-back loop; an adaptation of truncated backpropagation-through-time (TBPTT) is used to learn cross-turn dependencies. The central claim is that this yields superior efficiency and robustness relative to prior compressors, with the key empirical result being stable inference latency and perplexity over hundreds of dialogue turns on long-form benchmarks.
Significance. If the stability result holds without compounding reconstruction error, the method would provide a concrete mechanism for maintaining information across very long dialogues while keeping memory and latency bounded, addressing a practical bottleneck in current dialogue systems.
major comments (2)
- [Abstract] Abstract: the claim that C-DIC 'shows stable inference latency and perplexity over hundreds of dialogue turns' is presented without any quantitative results, baselines, metrics, tables, or experimental protocol, so the central empirical assertion cannot be evaluated.
- [Abstract] Abstract: no quantitative bound, plot, or analysis of reconstruction fidelity or error growth rate versus turn count is supplied, leaving the load-bearing assumption that the revise loop incurs 'neither irreversible loss nor accumulating errors' untested.
minor comments (1)
- [Abstract] The abstract introduces 'Dialogue memory storing per-thread compression states' and 'TBPTT adaptation' without a brief definition or reference to the section where they are formalized.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger quantitative grounding in the abstract. We address each major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that C-DIC 'shows stable inference latency and perplexity over hundreds of dialogue turns' is presented without any quantitative results, baselines, metrics, tables, or experimental protocol, so the central empirical assertion cannot be evaluated.
Authors: The abstract is a high-level summary; the full quantitative results—including measured latency and perplexity values across turn counts, baseline comparisons, metrics, and the experimental protocol—are reported in Section 4 with tables and figures. We will revise the abstract to include a small number of key quantitative highlights (e.g., specific stability ranges) to make the central claim more self-contained while respecting length constraints. revision: partial
-
Referee: [Abstract] Abstract: no quantitative bound, plot, or analysis of reconstruction fidelity or error growth rate versus turn count is supplied, leaving the load-bearing assumption that the revise loop incurs 'neither irreversible loss nor accumulating errors' untested.
Authors: We agree that an explicit analysis of reconstruction fidelity and error growth versus turn count would strengthen support for the revise loop. While empirical stability of perplexity serves as indirect validation, we will add a dedicated plot and quantitative bounds on error accumulation in the revised manuscript to directly test the claim of no compounding errors. revision: yes
Circularity Check
No circularity: empirical method with no self-referential derivations
full rationale
The paper introduces C-DIC as an algorithmic approach to incremental context compression via retrieve-revise-write-back and TBPTT adaptation, evaluated empirically on dialogue benchmarks. No equations, fitted parameters, or first-principles derivations are presented that reduce reported stability or performance to a tautological fit or self-definition. Claims rest on experimental outcomes rather than any load-bearing self-citation chain or ansatz smuggled via prior work. The derivation chain is self-contained as a proposed engineering solution whose validity is tested externally to its own construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A conversation can be treated as interleaved contextual threads whose compression states remain revisable across turns.
invented entities (1)
-
Dialogue memory storing per-thread compression states
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
2025 , eprint=
LLMs Get Lost In Multi-Turn Conversation , author=. 2025 , eprint=
2025
-
[5]
2024 , eprint=
In-context Autoencoder for Context Compression in a Large Language Model , author=. 2024 , eprint=
2024
-
[6]
2023 , eprint=
Adapting Language Models to Compress Contexts , author=. 2023 , eprint=
2023
-
[7]
2023 , eprint=
Attention Is All You Need , author=. 2023 , eprint=
2023
-
[8]
2022 , eprint=
Efficient Transformers: A Survey , author=. 2022 , eprint=
2022
-
[9]
2025 , eprint=
Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models , author=. 2025 , eprint=
2025
-
[10]
2024 , eprint=
A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems , author=. 2024 , eprint=
2024
-
[11]
Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Xu, Jing and Szlam, Arthur and Weston, Jason. Beyond Goldfish Memory: Long-Term Open-Domain Conversation. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.356
-
[12]
2023 , eprint=
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis , author=. 2023 , eprint=
2023
-
[13]
On Context Utilization in Summarization with Large Language Models
Ravaut, Mathieu and Sun, Aixin and Chen, Nancy and Joty, Shafiq. On Context Utilization in Summarization with Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.153
-
[14]
2024 , eprint=
MemGPT: Towards LLMs as Operating Systems , author=. 2024 , eprint=
2024
-
[15]
2025 , eprint=
REALTALK: A 21-Day Real-World Dataset for Long-Term Conversation , author=. 2025 , eprint=
2025
-
[16]
Bleu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =. 2002 , publisher =. doi:10.3115/1073083.1073135 , abstract =
-
[17]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[18]
2021 , eprint=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. 2021 , eprint=
2021
-
[19]
P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
Liu, Xiao and Ji, Kaixuan and Fu, Yicheng and Tam, Weng and Du, Zhengxiao and Yang, Zhilin and Tang, Jie. P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.8
-
[20]
2022 , eprint=
Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models , author=. 2022 , eprint=
2022
-
[21]
2024 , eprint=
Learning to Compress Prompts with Gist Tokens , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[23]
Introducing ChatGPT , year =
-
[24]
, journal=
Werbos, P.J. , journal=. Backpropagation through time: what it does and how to do it , year=
-
[25]
2019 , eprint=
Recurrent Neural Networks (RNNs): A gentle Introduction and Overview , author=. 2019 , eprint=
2019
-
[26]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[27]
2019 , eprint=
Compressive Transformers for Long-Range Sequence Modelling , author=. 2019 , eprint=
2019
-
[28]
2022 , eprint=
Recurrent Memory Transformer , author=. 2022 , eprint=
2022
-
[29]
2023 , eprint=
Automated Annotation with Generative AI Requires Validation , author=. 2023 , eprint=
2023
-
[30]
Calderon, Nitay and Reichart, Roi and Dror, Rotem. The Alternative Annotator Test for LLM -as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.782
-
[31]
2025 , eprint=
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , author=. 2025 , eprint=
2025
-
[32]
2023 , eprint=
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models , author=. 2023 , eprint=
2023
-
[33]
2024 , eprint=
InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory , author=. 2024 , eprint=
2024
-
[34]
2021 , eprint=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. 2021 , eprint=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.