PersonaDrive: Human-Style Retrieval-Augmented VLA Agents for Closed-Loop Driving Simulation
Pith reviewed 2026-06-27 09:51 UTC · model grok-4.3
The pith
One fine-tuned VLA backbone produces any of three human driving styles for non-ego agents by swapping retrieval databases drawn from style-instructed human demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
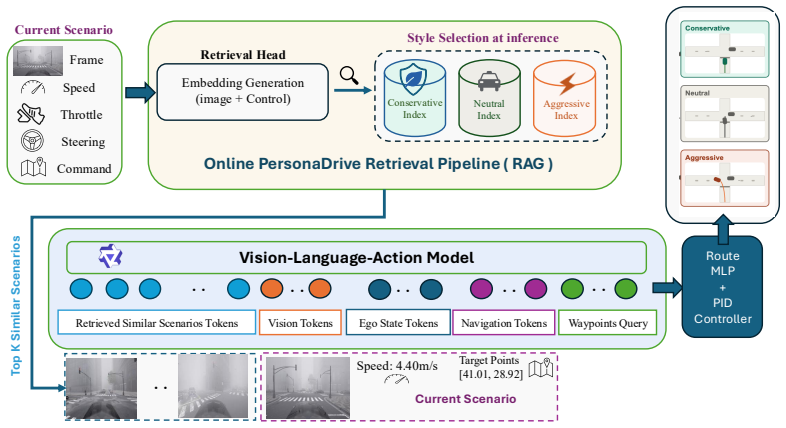
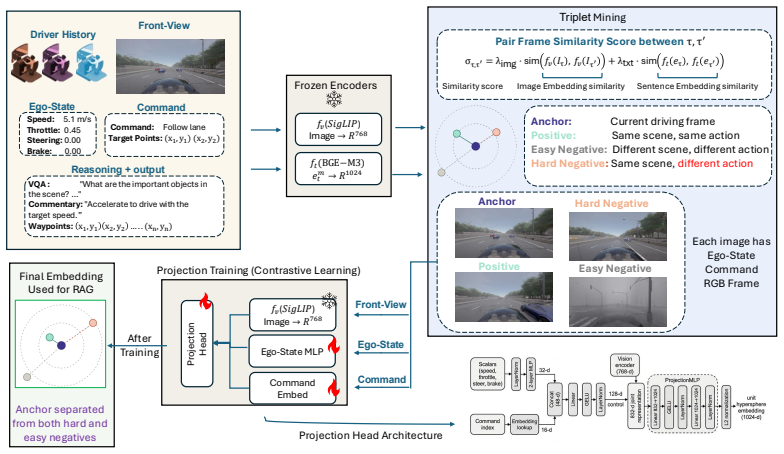
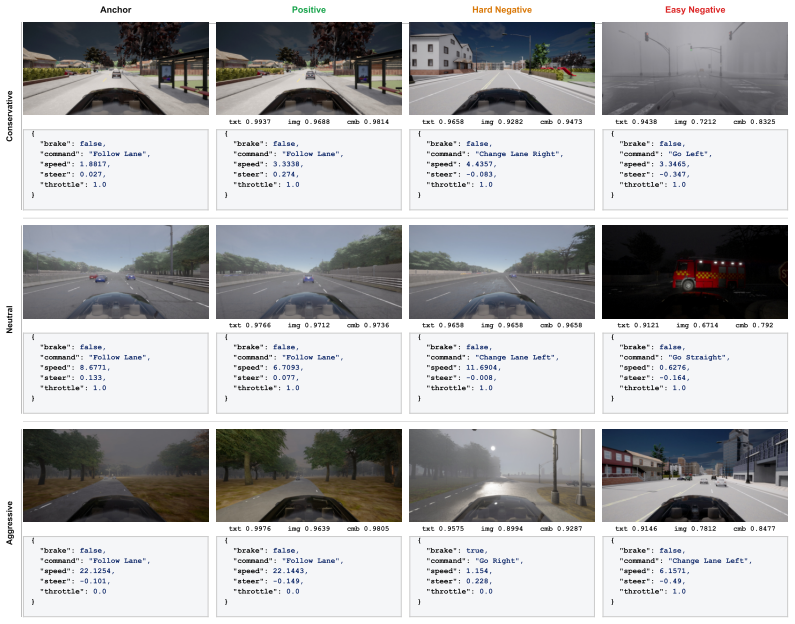
PersonaDrive conditions a vision-language-action driving agent on retrieved demonstrations from a style-instructed human driving dataset; the pipeline mines triplets offline with an image-text similarity score, trains a lightweight retrieval head over per-style databases, and fine-tunes one VLA backbone to use the retrieved points as in-context behavioral signals, allowing any style to be selected at inference by changing only which database is queried.
What carries the argument
The retrieval head that fuses frozen visual features with a small control encoder to select style-specific human demonstration points for in-context conditioning of the VLA waypoint predictor.
Load-bearing premise
Demonstrations collected from humans explicitly told to drive in one style transfer as reliable behavioral signals to a fine-tuned VLA without style-specific retraining or extra reward terms.
What would settle it
If querying the aggressive versus conservative database produces no measurable rise in average speed or acceleration on the same routes, or if the style-conditioned driving scores fall below the strongest baseline in any style.
Figures
read the original abstract
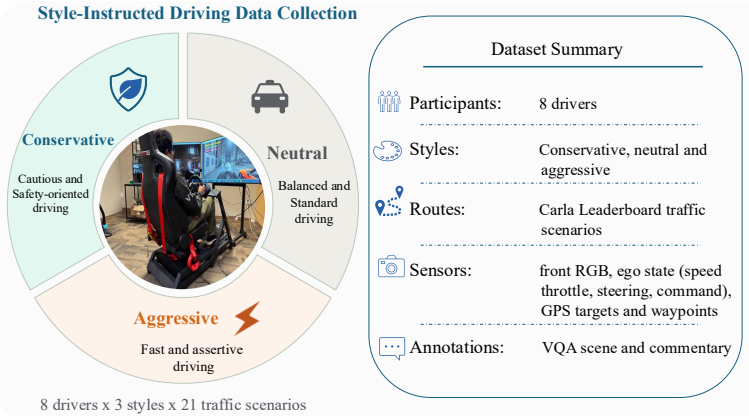
Closed-loop driving simulators typically populate their environments with non-ego traffic agents that behave largely the same way, produced either by rule-based traffic managers or by learned models trained toward a single behavioral mode. Recent work introduces style variation through post-hoc labels on observational data or LLM-inferred reward weights, but these signals act as proxies for what a style should reward rather than demonstrations of humans explicitly asked to drive in that style. We introduce PersonaDrive, a pipeline that conditions a vision-language-action (VLA) driving agent on retrieved demonstrations from a style-instructed human driving dataset, in which participants drive CARLA leaderboard routes under aggressive, neutral, and conservative instructions on a driver-in-the-loop rig. The pipeline has three stages: (i) offline triplet mining over per-style human driving data using a combined image-text similarity score; (ii) training a lightweight retrieval head that fuses frozen visual features with a small control encoder over per-style databases; and (iii) fine-tuning a single VLA backbone to treat retrieved context points as in-context behavioral demonstrations during waypoint prediction. At inference, the same backbone is conditioned on any style by swapping which per-style database the retrieval head queries, so selecting a style requires no per-style retraining while enabling human-style, style-diverse non-ego agents for closed-loop simulation. On Bench2Drive, PersonaDrive (no style) improves the driving score by 4.6% over SimLingo and 2.5% over HiP-AD, and under style conditioning attains the highest driving score in every style within a roughly 2% band (its weakest style surpassing the strongest baseline, DMW, by 5.4%), while average speed and acceleration rise by 18% and 25% from the conservative to the aggressive instruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PersonaDrive, a three-stage pipeline that mines style-partitioned human driving demonstrations (aggressive/neutral/conservative) from a driver-in-the-loop CARLA dataset, trains a retrieval head over per-style databases, and fine-tunes a single VLA backbone to use retrieved context points as in-context demonstrations for waypoint prediction. At inference, style is selected by swapping the retrieval database without per-style retraining. On Bench2Drive the method reports a 4.6% driving-score gain over SimLingo and 2.5% over HiP-AD without style conditioning; under style conditioning it attains the highest score in every style (within a ~2% band) while average speed and acceleration increase 18% and 25% from conservative to aggressive instructions.
Significance. If the central mechanism holds, the approach supplies a practical route to human-style behavioral diversity in closed-loop simulators without reward engineering or per-style fine-tuning, directly addressing the limitation of single-mode traffic agents. The use of explicitly instructed human demonstrations rather than post-hoc labels or LLM-inferred rewards is a clear methodological distinction.
major comments (2)
- [Pipeline description (stages i–iii)] The headline performance claims rest on the unverified assumption that the image-text similarity retrieval selects on dynamic style cues (acceleration profiles, gap acceptance) rather than scene appearance; no ablation or analysis is provided showing that the VLA actually conditions waypoint outputs on the retrieved sequences versus prompt text or the control encoder alone.
- [Abstract / Evaluation] Quantitative results are reported without error bars, dataset sizes, number of evaluation episodes, or verification that participants followed the style instructions; this prevents assessment of whether the 4.6%/2.5% gains and the 18%/25% speed/acceleration shifts are statistically reliable or attributable to the retrieval mechanism.
minor comments (2)
- [Methods] Notation for the retrieval head (frozen visual features + control encoder) and the triplet-mining similarity score should be defined explicitly with equations.
- [Experiments] The Bench2Drive comparison table should include all baselines (SimLingo, HiP-AD, DMW) with the same metrics and episode counts for direct readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Pipeline description (stages i–iii)] The headline performance claims rest on the unverified assumption that the image-text similarity retrieval selects on dynamic style cues (acceleration profiles, gap acceptance) rather than scene appearance; no ablation or analysis is provided showing that the VLA actually conditions waypoint outputs on the retrieved sequences versus prompt text or the control encoder alone.
Authors: The retrieval is performed over explicitly style-partitioned human driving data collected under instructed conditions, using combined image-text similarity to select context points that the VLA is trained to treat as in-context demonstrations. We agree, however, that the current manuscript lacks direct ablations isolating whether waypoint outputs are conditioned on dynamic properties of the retrieved sequences versus scene appearance, text prompt, or the control encoder. We will add such an ablation study, including quantitative comparison of performance with and without retrieved context and analysis of acceleration/gap metrics in selected sequences, in the revised version. revision: yes
-
Referee: [Abstract / Evaluation] Quantitative results are reported without error bars, dataset sizes, number of evaluation episodes, or verification that participants followed the style instructions; this prevents assessment of whether the 4.6%/2.5% gains and the 18%/25% speed/acceleration shifts are statistically reliable or attributable to the retrieval mechanism.
Authors: We will add error bars, dataset sizes, and the number of evaluation episodes to the revised manuscript. The style instructions were provided explicitly to participants during driver-in-the-loop collection, but we do not possess independent post-collection verification of adherence; this will be stated explicitly as a limitation while reporting the instructed collection protocol. revision: partial
- Independent verification of participant adherence to the instructed driving styles beyond the initial collection protocol.
Circularity Check
No circularity: empirical pipeline with external benchmarks
full rationale
The paper presents an empirical pipeline (triplet mining over human data, retrieval head training, single VLA fine-tuning, inference-time database swap) evaluated on Bench2Drive against external baselines (SimLingo, HiP-AD, DMW). No equations, derivations, or 'predictions' are claimed that reduce to fitted parameters or self-definitions by construction. Performance metrics (driving scores, speed/accel shifts) are reported as measured outcomes from standard training and retrieval, not forced by internal redefinitions. No load-bearing self-citations or uniqueness theorems appear. The derivation chain is self-contained against external data and benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal , year =
Last, First , title =. Journal , year =
-
[2]
2022 IEEE Intelligent Vehicles Symposium (IV) , pages=
MAConAuto: Framework for mobile-assisted human-in-the-loop automotive system , author=. 2022 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2022 , organization=
2022
-
[3]
Proceedings of the First International Workshop on Cyber-Physical-Human System Design and Implementation , pages=
Adas-rl: Adaptive vector scaling reinforcement learning for human-in-the-loop lane departure warning , author=. Proceedings of the First International Workshop on Cyber-Physical-Human System Design and Implementation , pages=
-
[4]
Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems , pages=
Sentio: Driver-in-the-loop forward collision warning using multisample reinforcement learning , author=. Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems , pages=
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[6]
Proceedings of the 2024 International Conference on Robotics and Automation (ICRA) , year =
RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model , author =. Proceedings of the 2024 International Conference on Robotics and Automation (ICRA) , year =
2024
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Drive my way: Preference alignment of vision-language-action model for personalized driving , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author =. arXiv preprint arXiv:2402.03300 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding , author =. arXiv preprint arXiv:1807.03748 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
European conference on computer vision , pages=
Drivelm: Driving with graph visual question answering , author=. European conference on computer vision , pages=. 2024 , organization=
2024
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Feedback-guided autonomous driving , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
Driving Style Alignment for LLM-powered Driver Agent , year=
Yang, Ruoxuan and Zhang, Xinyue and Fernandez-Laaksonen, Anais and Ding, Xin and Gong, Jiangtao , booktitle=. Driving Style Alignment for LLM-powered Driver Agent , year=
-
[13]
Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning , author=. arXiv preprint arXiv:2506.13757 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Styledrive: Towards driving-style aware benchmarking of end-to-end autonomous driving , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail , author=. arXiv preprint arXiv:2511.00088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Advances in Neural Information Processing Systems , volume=
Behaviorgpt: Smart agent simulation for autonomous driving with next-patch prediction , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
arXiv preprint arXiv:2505.24808 , year=
Realdrive: Retrieval-augmented driving with diffusion models , author=. arXiv preprint arXiv:2505.24808 , year=
-
[18]
IEEE Transactions on Robotics , volume=
Maveric: A data-driven approach to personalized autonomous driving , author=. IEEE Transactions on Robotics , volume=. 2024 , publisher=
2024
-
[19]
2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Behaviorally diverse traffic simulation via reinforcement learning , author=. 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2020 , organization=
2020
-
[20]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Diverse Human Driving Vehicle Simulation in Background Traffic for Autonomous Driving Tests , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[21]
Conference on robot learning , pages=
CARLA: An open urban driving simulator , author=. Conference on robot learning , pages=. 2017 , organization=
2017
-
[22]
Proceedings of the 4th middle East Symposium on Simulation and Modelling (MESM20002) , pages=
SUMO (Simulation of Urban MObility)-an open-source traffic simulation , author=. Proceedings of the 4th middle East Symposium on Simulation and Modelling (MESM20002) , pages=
-
[23]
Advances in Neural Information Processing Systems , volume=
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
IEEE Robotics and Automation Letters , volume=
B-gap: Behavior-rich simulation and navigation for autonomous driving , author=. IEEE Robotics and Automation Letters , volume=. 2022 , publisher=
2022
-
[25]
2020 , howpublished =
CARLA Autonomous Driving Leaderboard --- Scenarios , author =. 2020 , howpublished =
2020
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Trajectory-Guided Control Prediction for End-to-End Autonomous Driving: A Simple yet Strong Baseline , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Think Twice before Driving: Towards Scalable Decoders for End-to-End Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[29]
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes , author =. arXiv preprint arXiv:2305.10430 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Planning-Oriented Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[31]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
VAD: Vectorized Scene Representation for Efficient Autonomous Driving , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[32]
arXiv preprint arXiv:2503.08612 , year =
HiP-AD: Hierarchical and Multi-Granularity Planning with Deformable Attention for Autonomous Driving in a Single Decoder , author =. arXiv preprint arXiv:2503.08612 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.