ECA: Efficient Continual Alignment for Open-Ended Image-to-Text Generation
Pith reviewed 2026-06-27 09:44 UTC · model grok-4.3
The pith
ECA lets vision-language models adapt to shifting image categories over time without forgetting prior alignments or storing old examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
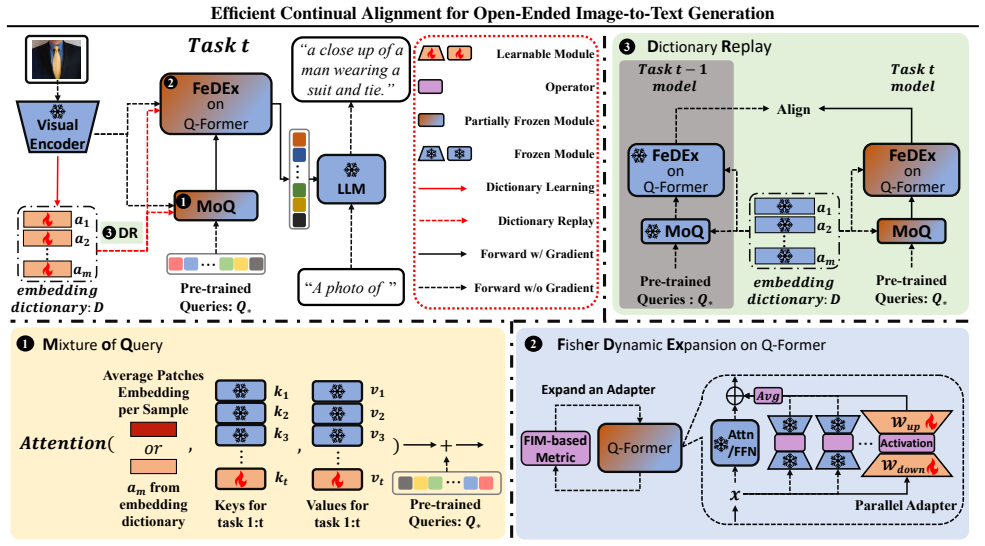
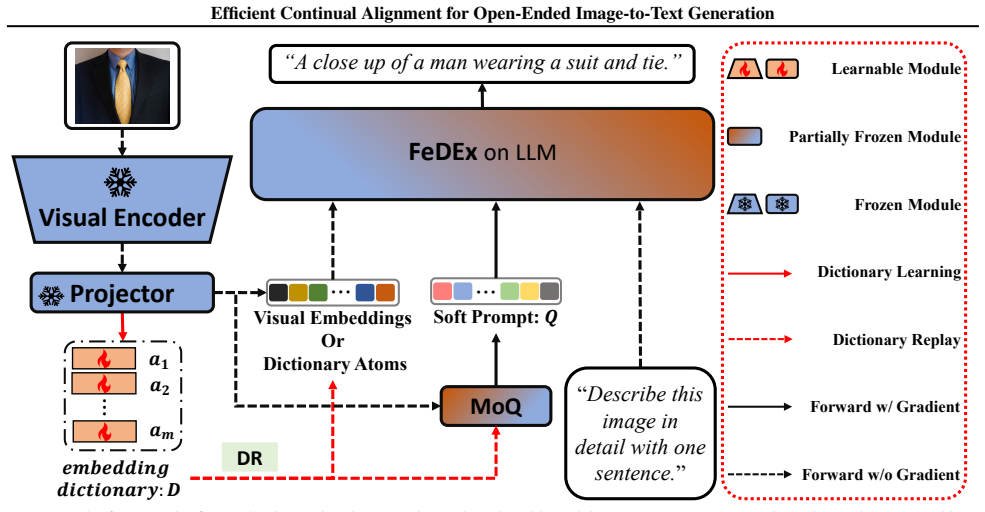
ECA is an exemplar-free incremental learning method for OpenITG that incrementally adapts the alignment module in pre-trained VLMs using a Mixture of Query module to adapt task-specific query tokens, Fisher Dynamic Expansion to grow model structure according to a Fisher Information Matrix metric, and Dictionary Replay from an embedding dictionary to retain past knowledge.
What carries the argument
The Efficient Continual Alignment (ECA) framework, which uses Mixture of Query adaptation, Fisher-based dynamic expansion, and dictionary replay to update cross-modal alignments without raw data access.
If this is right
- New task-specific features can be acquired with reduced interference to previously learned cross-modal alignments.
- Models achieve higher performance on both new and old tasks compared to prior incremental learning baselines.
- Learning proceeds without storing or replaying raw examples from earlier tasks.
- The approach applies specifically to open-ended image-to-text generation under category-shift conditions.
Where Pith is reading between the lines
- The same alignment-adaptation logic could be tested in other generative cross-modal tasks such as text-to-image or audio-to-text.
- Fisher Information Matrix expansion might serve as a general criterion for deciding when to add capacity in other continual learning settings.
- If the new benchmarks prove representative, many existing exemplar-free methods would require similar alignment-specific handling rather than generic parameter regularization.
Load-bearing premise
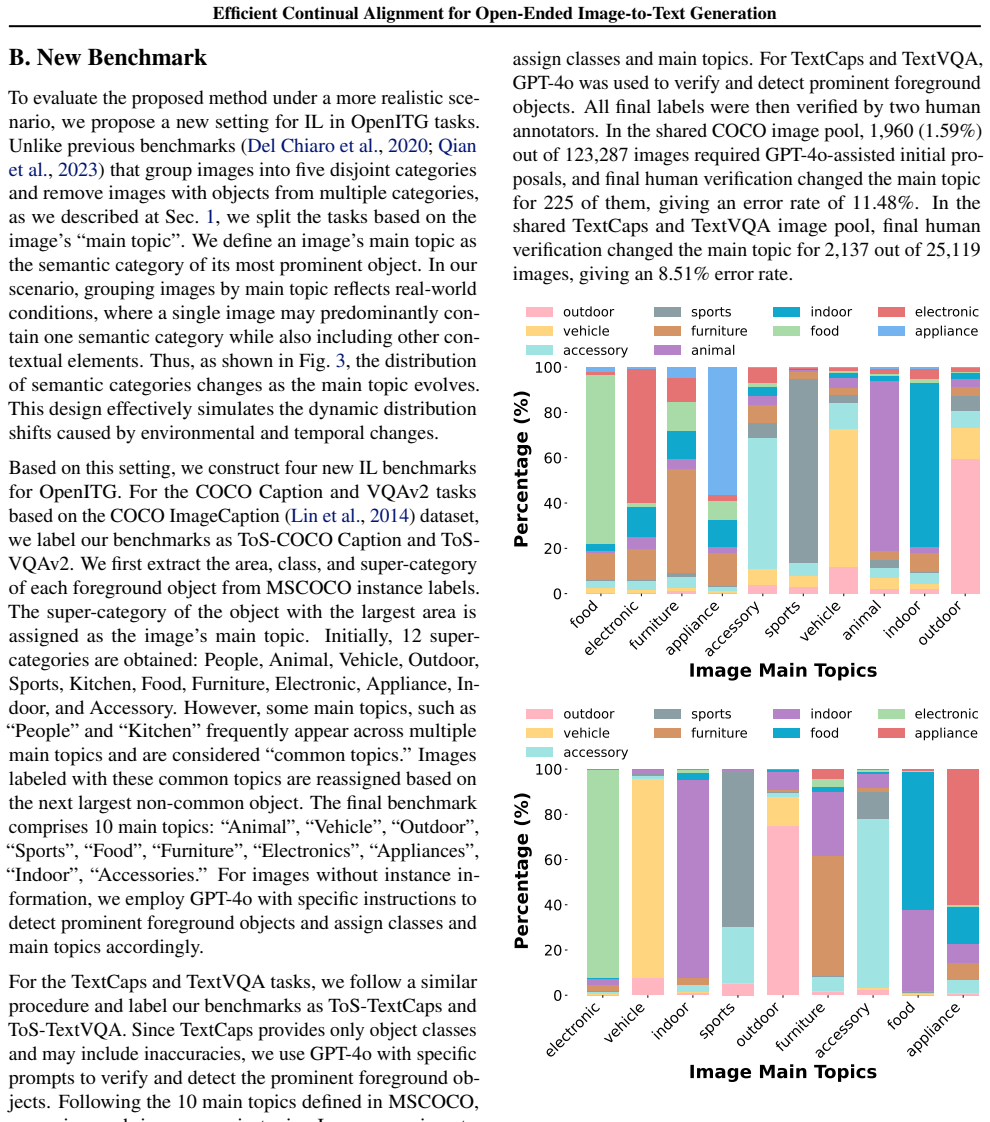
The four constructed IL OpenITG benchmarks accurately capture real-world scenarios where the predominant category of visual data shifts over time.
What would settle it
Running ECA and baseline methods on the four benchmarks and finding that ECA shows no reduction in forgetting or no gain in overall performance would disprove the central effectiveness claim.
Figures

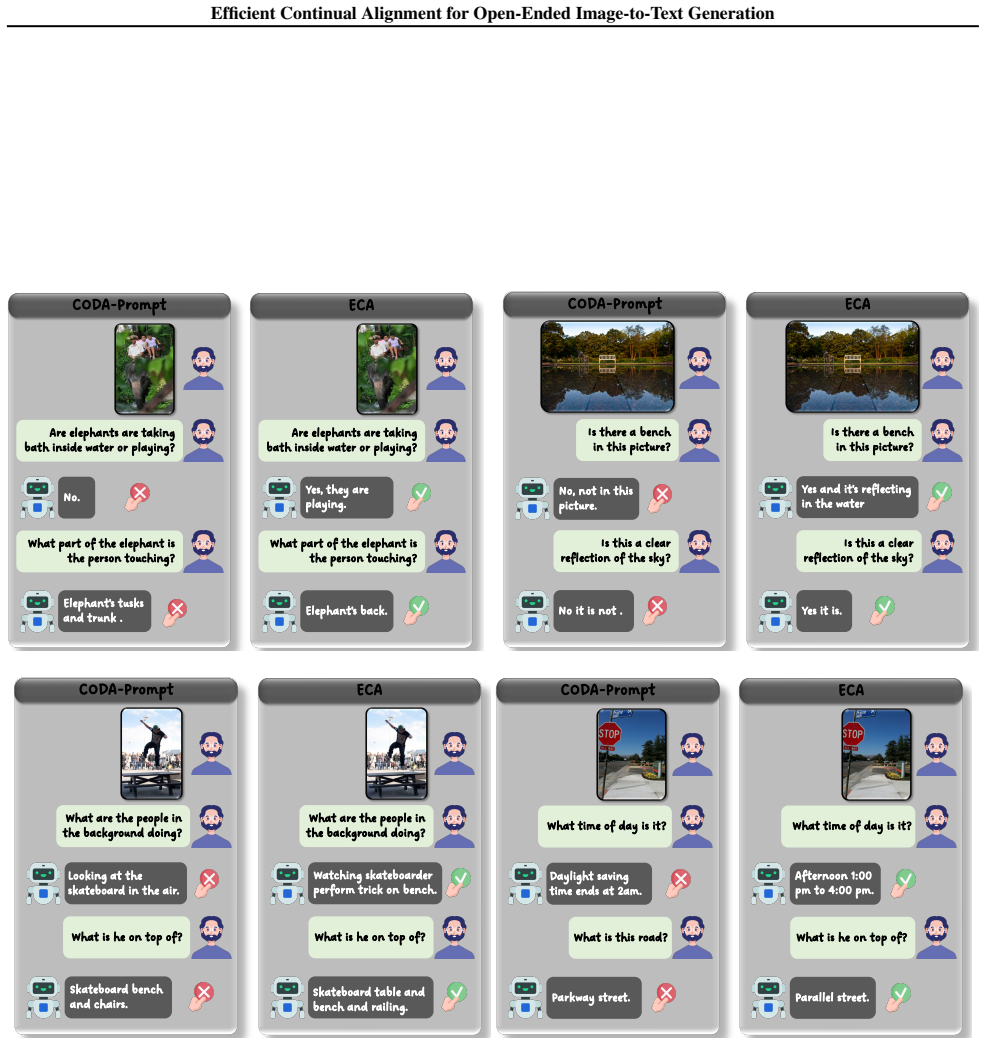
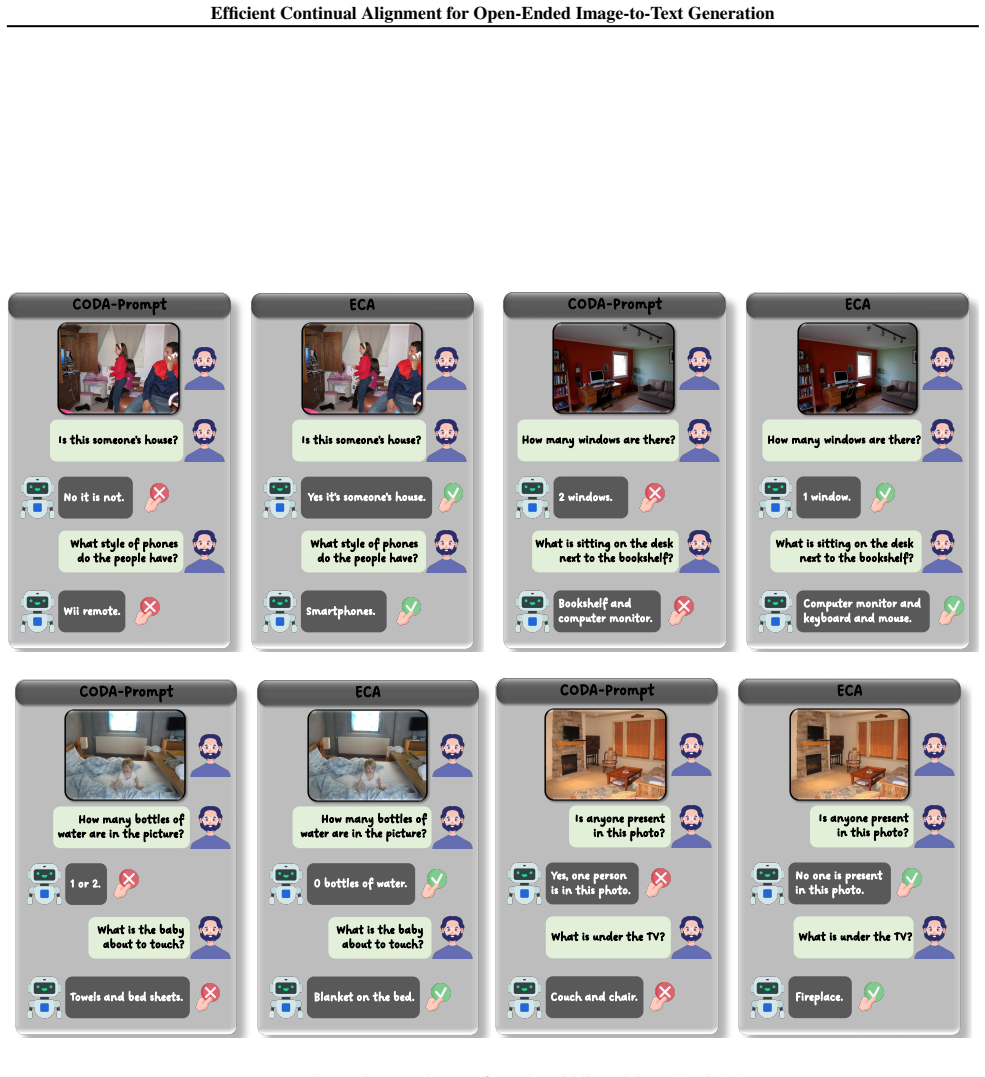
read the original abstract
Incremental Learning (IL) for Open-ended Image-to-Text Generation (OpenITG) enables models to continuously generate accurate, contextually relevant text for new images while preserving previously acquired knowledge. Unlike prior studies, this paper addresses a more practical scenario in which the predominant category of visual data shifts over time as environments evolve. In this context, we introduce a new notion of continual alignment, which incrementally adapts the alignment module within pre-trained VLMs to preserve high-quality cross-modal representations. Based on this idea, we propose Efficient Continual Alignment (ECA), a novel exemplar-free IL approach for OpenITG. The key challenge is enabling the model to acquire new, task-specific features while minimizing interference with the established alignment without accessing raw data from previous tasks. To address this, ECA employs three core mechanisms: a Mixture of Query (MoQ) module that adapts task-specific query tokens, a Fisher Dynamic Expansion (FeDEx) that dynamically expands model structure based on a Fisher Information Matrix (FIM)-based metric, and an embedding dictionary with Dictionary Replay (DR) to retain past knowledge. To evaluate ECA's performance, we construct four new IL OpenITG benchmarks that better reflect real-world scenarios. Experimental results demonstrate that ECA significantly mitigates catastrophic forgetting and improves IL performance compared to baseline methods. Code and benchmarks are available at https://github.com/Snowball0823/ECA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Efficient Continual Alignment (ECA), an exemplar-free incremental learning approach for open-ended image-to-text generation (OpenITG) in pre-trained vision-language models. It introduces a notion of continual alignment to adapt the alignment module under shifting visual category distributions, using three mechanisms: Mixture of Query (MoQ) for task-specific query tokens, Fisher Dynamic Expansion (FeDEx) for FIM-based dynamic model growth, and Dictionary Replay (DR) via an embedding dictionary. Four new IL OpenITG benchmarks are constructed to evaluate the method, with experiments claiming that ECA mitigates catastrophic forgetting and outperforms baselines.
Significance. If the benchmarks validly capture gradual, environment-driven category shifts and the mechanisms are shown to operate without data access, the work could advance exemplar-free continual learning for multimodal generation tasks by focusing on alignment preservation rather than full model retraining. The release of code and benchmarks is a positive contribution for reproducibility.
major comments (2)
- [Abstract / §4 (Benchmarks)] Abstract and experimental section (benchmark construction): The central performance claims rest on results from four newly constructed IL OpenITG benchmarks asserted to 'better reflect real-world scenarios in which the predominant category of visual data shifts over time as environments evolve.' No explicit protocol is described for ensuring the task sequences instantiate gradual, environment-driven drift (e.g., via temporal ordering of category prevalence or distribution shifts) rather than static or arbitrary splits; this makes it impossible to determine whether observed gains on MoQ/FeDEx/DR actually support effectiveness under the stated practical scenario.
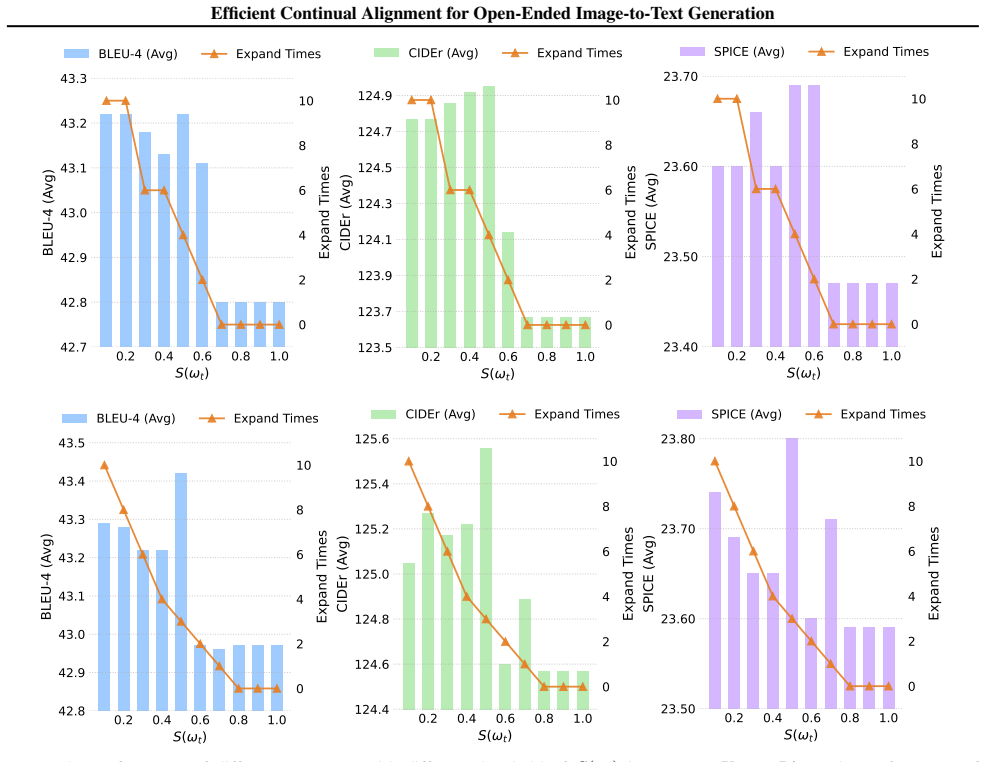
- [§3.2] §3.2 (FeDEx): The dynamic expansion is driven by an FIM-based metric, but the manuscript does not specify how the threshold or expansion criterion is chosen without introducing task-specific hyperparameters that could undermine the 'efficient' and 'exemplar-free' claims when scaling to new tasks.
minor comments (2)
- [§3.3] Notation for the embedding dictionary in DR is introduced without a clear equation linking it to the alignment module output; adding a formal definition would improve clarity.
- [Abstract / Experiments] The abstract states 'Code and benchmarks are available at https://github.com/Snowball0823/ECA' but the manuscript does not include a reproducibility checklist or details on random seeds and evaluation metrics used in the reported tables.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / §4 (Benchmarks)] Abstract and experimental section (benchmark construction): The central performance claims rest on results from four newly constructed IL OpenITG benchmarks asserted to 'better reflect real-world scenarios in which the predominant category of visual data shifts over time as environments evolve.' No explicit protocol is described for ensuring the task sequences instantiate gradual, environment-driven drift (e.g., via temporal ordering of category prevalence or distribution shifts) rather than static or arbitrary splits; this makes it impossible to determine whether observed gains on MoQ/FeDEx/DR actually support effectiveness under the stated practical scenario.
Authors: We agree that the current description of benchmark construction in §4 does not provide a sufficiently explicit protocol for the task sequencing to guarantee gradual, environment-driven category drift. In the revised manuscript we will expand §4 with a dedicated subsection that details the exact ordering procedure, data partitioning criteria, and any quantitative measures used to ensure the sequences reflect temporal shifts in category prevalence rather than arbitrary splits. revision: yes
-
Referee: [§3.2] §3.2 (FeDEx): The dynamic expansion is driven by an FIM-based metric, but the manuscript does not specify how the threshold or expansion criterion is chosen without introducing task-specific hyperparameters that could undermine the 'efficient' and 'exemplar-free' claims when scaling to new tasks.
Authors: The referee correctly notes that §3.2 does not currently specify the precise rule for selecting the FIM-based expansion threshold. We will revise this section to explicitly state the criterion (including how any fixed value or statistical rule is derived) and demonstrate that the same rule is applied uniformly without per-task retuning or access to prior data, thereby preserving the exemplar-free and efficient properties. revision: yes
Circularity Check
No circularity; derivation is self-contained empirical proposal with external benchmarks.
full rationale
The paper proposes ECA via three mechanisms (MoQ, FeDEx using standard FIM, DR) and evaluates on four newly constructed IL OpenITG benchmarks. No equations or claims reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central performance claims rest on experimental results against baselines on those benchmarks, which are presented as independent testbeds rather than outputs of the method itself. Standard concepts like Fisher Information Matrix are referenced without redefinition or circular prediction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[10]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[11]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[12]
Lewis, Mike and Liu, Yinhan and Goyal, Naman and Ghazvininejad, Marjan and Mohamed, Abdelrahman and Levy, Omer and Stoyanov, Veselin and Zettlemoyer, Luke. BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. Proceedings of the 58th Annual Meeting of the Association for Computational Linguisti...
-
[13]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[14]
International conference on machine learning , pages=
Scaling up visual and vision-language representation learning with noisy text supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[15]
Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXX 16 , pages=
Oscar: Object-semantics aligned pre-training for vision-language tasks , author=. Computer Vision--ECCV 2020: 16th European Conference, Glasgow, UK, August 23--28, 2020, Proceedings, Part XXX 16 , pages=. 2020 , organization=
2020
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Unified vision-language pre-training for image captioning and vqa , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
Perceiver
Andrew Jaegle and Sebastian Borgeaud and Jean-Baptiste Alayrac and Carl Doersch and Catalin Ionescu and David Ding and Skanda Koppula and Daniel Zoran and Andrew Brock and Evan Shelhamer and Olivier J Henaff and Matthew Botvinick and Andrew Zisserman and Oriol Vinyals and Joao Carreira , booktitle=. Perceiver. 2022 , url=
2022
-
[18]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[19]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[20]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[21]
Proceedings of the IEEE international conference on computer vision , pages=
Vqa: Visual question answering , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[22]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Show and tell: A neural image caption generator , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
A comprehensive survey of continual learning: theory, method and application , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[24]
International Conference on Learning Representations , year=
Towards a Unified View of Parameter-Efficient Transfer Learning , author=. International Conference on Learning Representations , year=
-
[25]
arXiv preprint arXiv:2401.05605 , year=
Scaling laws for forgetting when fine-tuning large language models , author=. arXiv preprint arXiv:2401.05605 , year=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-sustaining representation expansion for non-exemplar class-incremental learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Fetril: Feature translation for exemplar-free class-incremental learning , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Prototype augmentation and self-supervision for incremental learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
The Annals of Applied Statistics , year=
Coordinate descent algorithms for lasso penalized regression , author=. The Annals of Applied Statistics , year=
-
[30]
SIAM review , volume=
Atomic decomposition by basis pursuit , author=. SIAM review , volume=. 2001 , publisher=
2001
-
[31]
SIAM journal on imaging sciences , volume=
A fast iterative shrinkage-thresholding algorithm for linear inverse problems , author=. SIAM journal on imaging sciences , volume=. 2009 , publisher=
2009
-
[32]
Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , volume=
An iterative thresholding algorithm for linear inverse problems with a sparsity constraint , author=. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , volume=. 2004 , publisher=
2004
-
[33]
Advances in Neural Information Processing Systems , volume=
Ratt: Recurrent attention to transient tasks for continual image captioning , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Vqacl: A novel visual question answering continual learning setting , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Symbolic replay: Scene graph as prompt for continual learning on vqa task , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Ramos, Rita and Martins, Bruno and Elliott, Desmond and Kementchedjhieva, Yova , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[37]
Advances in neural information processing systems , volume=
Image captioning: Transforming objects into words , author=. Advances in neural information processing systems , volume=
-
[38]
International Conference on Machine Learning , year=
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention , author=. International Conference on Machine Learning , year=
-
[39]
Open-Ended Visual Question Answering by Multi-Modal Domain Adaptation
Xu, Yiming and Chen, Lin and Cheng, Zhongwei and Duan, Lixin and Luo, Jiebo. Open-Ended Visual Question Answering by Multi-Modal Domain Adaptation. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.34
-
[40]
Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge
Fu, Xingyu and Zhang, Sheng and Kwon, Gukyeong and Perera, Pramuditha and Zhu, Henghui and Zhang, Yuhao and Li, Alexander Hanbo and Wang, William Yang and Wang, Zhiguo and Castelli, Vittorio and Ng, Patrick and Roth, Dan and Xiang, Bing. Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge. Findings of the Association for C...
-
[41]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Rainbow memory: Continual learning with a memory of diverse samples , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[42]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
1989
-
[43]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Decouple before interact: Multi-modal prompt learning for continual visual question answering , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[44]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Tokens-to-token vit: Training vision transformers from scratch on imagenet , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[45]
ArXiv , year=
OPT: Open Pre-trained Transformer Language Models , author=. ArXiv , year=
-
[46]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[47]
arXiv preprint arXiv:2405.14129 , year=
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability , author=. arXiv preprint arXiv:2405.14129 , year=
-
[48]
Conference on Parsimony and Learning (Proceedings Track) , year=
Investigating the Catastrophic Forgetting in Multimodal Large Language Model Fine-Tuning , author=. Conference on Parsimony and Learning (Proceedings Track) , year=
-
[49]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep visual-semantic alignments for generating image descriptions , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[50]
Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=
Microsoft coco: Common objects in context , author=. Computer Vision--ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13 , pages=. 2014 , organization=
2014
-
[51]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[52]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[53]
International conference on machine learning , pages=
Continual learning through synaptic intelligence , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[54]
6th international conference on learning representations, ICLR 2018-conference track proceedings , volume=
A scalable laplace approximation for neural networks , author=. 6th international conference on learning representations, ICLR 2018-conference track proceedings , volume=. 2018 , organization=
2018
-
[55]
European Conference on Computer Vision , year=
TextCaps: a Dataset for Image Captioning with Reading Comprehension , author=. European Conference on Computer Vision , year=
-
[56]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Towards VQA Models That Can Read , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[57]
Proceedings of the AAAI conference on artificial intelligence , volume=
End-to-end transformer based model for image captioning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[58]
Advances in neural information processing systems , volume=
Align before fuse: Vision and language representation learning with momentum distillation , author=. Advances in neural information processing systems , volume=
-
[59]
arXiv preprint arXiv:2108.10904 , year=
Simvlm: Simple visual language model pretraining with weak supervision , author=. arXiv preprint arXiv:2108.10904 , year=
-
[60]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[61]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[62]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Visualgpt: Data-efficient adaptation of pretrained language models for image captioning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[63]
arXiv preprint arXiv:2210.07179 , year=
Mapl: Parameter-efficient adaptation of unimodal pre-trained models for vision-language few-shot prompting , author=. arXiv preprint arXiv:2210.07179 , year=
-
[64]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning without forgetting , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2017 , publisher=
2017
-
[65]
Advances in neural information processing systems , volume=
Overcoming catastrophic forgetting by incremental moment matching , author=. Advances in neural information processing systems , volume=
-
[66]
Advances in neural information processing systems , volume=
Uncertainty-based continual learning with adaptive regularization , author=. Advances in neural information processing systems , volume=
-
[67]
Proceedings of the European conference on computer vision (ECCV) , pages=
Memory aware synapses: Learning what (not) to forget , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[68]
Computer vision--ECCV 2020: 16th European conference, Glasgow, UK, August 23--28, 2020, proceedings, part XX 16 , pages=
Podnet: Pooled outputs distillation for small-tasks incremental learning , author=. Computer vision--ECCV 2020: 16th European conference, Glasgow, UK, August 23--28, 2020, proceedings, part XX 16 , pages=. 2020 , organization=
2020
-
[69]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
icarl: Incremental classifier and representation learning , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[70]
Advances in neural information processing systems , volume=
Experience replay for continual learning , author=. Advances in neural information processing systems , volume=
-
[71]
Advances in neural information processing systems , volume=
Dark experience for general continual learning: a strong, simple baseline , author=. Advances in neural information processing systems , volume=
-
[72]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Der: Dynamically expandable representation for class incremental learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[73]
Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
Packnet: Adding multiple tasks to a single network by iterative pruning , author=. Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages=
-
[74]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dytox: Transformers for continual learning with dynamic token expansion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[75]
arXiv preprint arXiv:2204.04662 , year=
FOSTER: Feature Boosting and Compression for Class-Incremental Learning , author=. arXiv preprint arXiv:2204.04662 , year=
-
[76]
The eleventh international conference on learning representations , year=
Beef: Bi-compatible class-incremental learning via energy-based expansion and fusion , author=. The eleventh international conference on learning representations , year=
-
[77]
arXiv preprint arXiv:1701.08734 , year=
Pathnet: Evolution channels gradient descent in super neural networks , author=. arXiv preprint arXiv:1701.08734 , year=
-
[78]
International conference on machine learning , pages=
Overcoming catastrophic forgetting with hard attention to the task , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[79]
Advances in Neural Information Processing Systems , volume=
S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning , author=. Advances in Neural Information Processing Systems , volume=
-
[80]
European conference on computer vision , pages=
Dualprompt: Complementary prompting for rehearsal-free continual learning , author=. European conference on computer vision , pages=. 2022 , organization=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.