Multi-Label Test-Time Adaptation with Bayesian Conditional Priors
Pith reviewed 2026-06-27 07:36 UTC · model grok-4.3
The pith
Bayesian Conditional Priors refine zero-shot multi-label predictions by estimating conditional label dependencies online from the unlabeled test stream.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
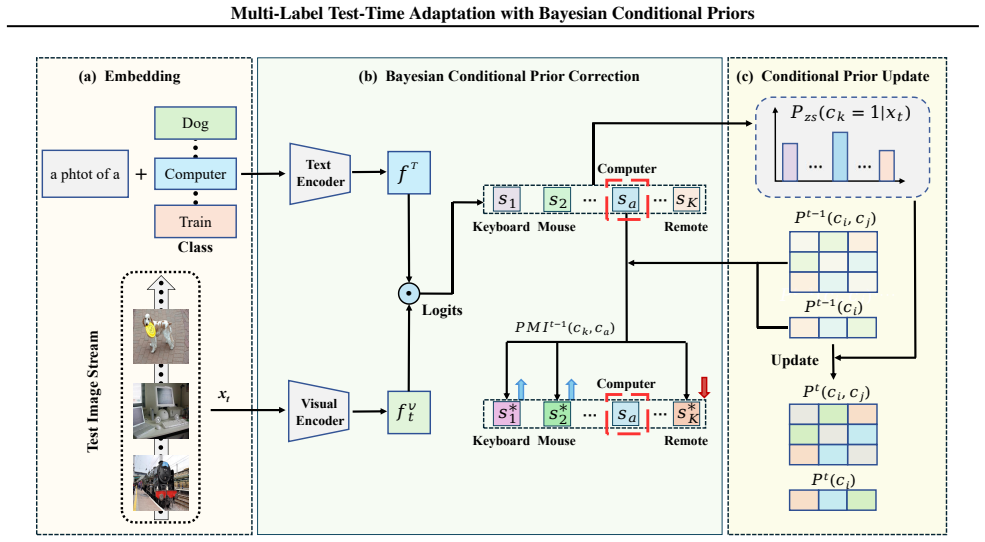
BCP treats zero-shot logits as proxies for marginal posteriors and corrects shift-induced errors by performing an anchor-conditioned Bayesian refinement whose logit-space update explicitly incorporates label co-occurrence structure estimated from the unlabeled test stream.
What carries the argument
Anchor-conditioned Bayesian refinement: a closed-form logit-space update, interpretable via pointwise mutual information, that raises the posterior of labels compatible with a chosen high-confidence anchor while lowering the posterior of incompatible ones.
If this is right
- Label predictions become more coherent because the update promotes labels that actually co-occur with the anchor.
- The adaptation requires only a single forward pass plus cheap second-order statistics and therefore scales to long test streams.
- Performance gains hold across multiple CLIP backbones without any gradient steps on the model.
- The same prior-estimation machinery can be applied at inference time to any frozen VLM used for multi-label tasks.
Where Pith is reading between the lines
- The method suggests that many existing TTA techniques could be strengthened by explicitly modeling label priors instead of only adapting features or thresholds.
- If test streams are short or non-stationary, the online second-order statistics may need regularization or a decay factor to remain accurate.
- The PMI interpretation opens a route to replace the Bayesian update with other information-theoretic measures of label compatibility if desired.
Load-bearing premise
Zero-shot logits can be treated as reliable proxies for marginal posteriors under a fixed image-text likelihood, with most shift errors coming from an incorrect label prior.
What would settle it
If the Bayesian update fails to raise mAP on held-out shifted multi-label test sets relative to the strongest TTA baselines, or if the online co-occurrence estimates do not improve over independent-label baselines.
Figures

read the original abstract
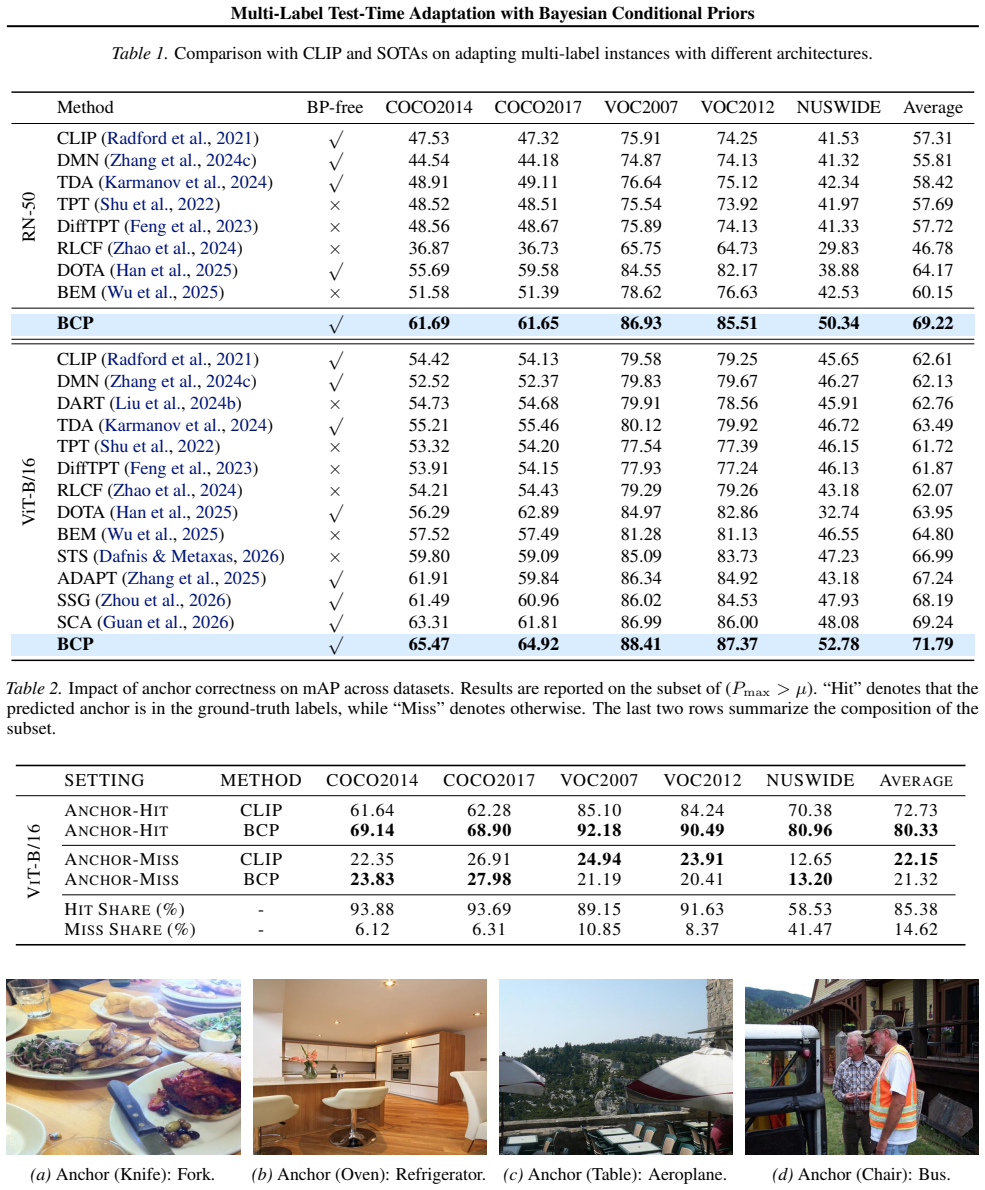
Multi-label recognition with frozen Vision-Language Models (VLMs) is brittle under distribution shift: standard zero-shot inference scores labels independently, ignoring co-occurrence structure and producing incoherent label sets where dominant concepts suppress weaker but compatible labels. We introduce Bayesian Conditional Priors (BCP) Estimation, a gradient-free test-time adaptation method that injects label dependency without tuning the backbone. BCP views zero-shot logits as a proxy for marginal posteriors under a fixed image-text likelihood and attributes shift-induced errors mainly to a mismatched label prior. For each test image, it selects a high-confidence anchor label and applies an anchor-conditioned Bayesian refinement. This update is closed-form in logit space and admits a pointwise mutual information (PMI) interpretation, explicitly promoting compatible labels and suppressing incompatible ones. BCP operates without target annotations by estimating anchor-conditioned priors online from the unlabeled test stream via lightweight second-order co-occurrence statistics, adding negligible overhead beyond a single forward pass. Across standard multi-label benchmarks and multiple CLIP backbones, BCP consistently outperforms strong TTA baselines, e.g., improving RN50 average mAP from 57.31 to 69.22 and ViT-B/16 from 62.61 to 71.79.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bayesian Conditional Priors (BCP) Estimation, a gradient-free test-time adaptation technique for multi-label recognition with frozen VLMs such as CLIP. It treats zero-shot logits as proxies for marginal posteriors under a fixed image-text likelihood, attributes distribution-shift errors primarily to mismatched label priors, and corrects them via an anchor-conditioned Bayesian update in logit space that admits a PMI interpretation. Anchor-conditioned co-occurrence statistics are estimated online from the unlabeled test stream using lightweight second-order moments, enabling closed-form refinement without target labels or backbone tuning. Experiments across multi-label benchmarks report consistent gains, e.g., RN50 mAP rising from 57.31 to 69.22 and ViT-B/16 from 62.61 to 71.79 over strong TTA baselines.
Significance. If the central decomposition and online estimation hold, BCP supplies an efficient, annotation-free route to inject label co-occurrence structure into zero-shot multi-label inference, with negligible overhead beyond one forward pass. The closed-form logit-space update and reproducible online statistics constitute concrete strengths that could influence practical VLM deployment under label-distribution shift.
major comments (2)
- [§3] §3 (Method), the load-bearing assumption that zero-shot logits equal marginal posteriors p(y|x) under an unchanging likelihood p(x|y): the manuscript provides no diagnostic experiment (e.g., controlled likelihood-shift simulation or comparison against a pure likelihood-adaptation baseline) that would falsify the separation of prior versus likelihood error sources. Without such a test the attribution of gains to prior correction remains unverified.
- [§3.3] §3.3 (online estimation), the precise procedure for computing anchor-conditioned co-occurrence statistics from the streaming test batch: the description is high-level and the independence from any training-set quantities is asserted but not shown via an explicit equation or pseudocode that would allow verification that the update remains purely test-time.
minor comments (2)
- [Tables 2,3] Table 2 and 3: report per-dataset standard deviations or number of runs so that the magnitude of the reported mAP gains can be assessed for statistical reliability.
- [§4.2] §4.2: the anchor-selection rule (high-confidence threshold or top-k) is stated qualitatively; an explicit formula or hyper-parameter sensitivity plot would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our assumptions and implementation details.
read point-by-point responses
-
Referee: [§3] §3 (Method), the load-bearing assumption that zero-shot logits equal marginal posteriors p(y|x) under an unchanging likelihood p(x|y): the manuscript provides no diagnostic experiment (e.g., controlled likelihood-shift simulation or comparison against a pure likelihood-adaptation baseline) that would falsify the separation of prior versus likelihood error sources. Without such a test the attribution of gains to prior correction remains unverified.
Authors: We agree that the central modeling choice—treating zero-shot logits as proxies for marginal posteriors under a fixed likelihood while attributing shift errors primarily to mismatched priors—would benefit from explicit verification. The manuscript motivates this decomposition via the Bayesian update and PMI interpretation, and the empirical gains over strong TTA baselines are consistent with prior correction, yet we acknowledge the absence of a controlled diagnostic. In the revision we will add a simulation experiment that artificially perturbs the likelihood (e.g., via synthetic visual-feature shifts) while holding the label prior fixed, together with a comparison against a pure likelihood-adaptation baseline, to better isolate the contribution of the prior update. revision: yes
-
Referee: [§3.3] §3.3 (online estimation), the precise procedure for computing anchor-conditioned co-occurrence statistics from the streaming test batch: the description is high-level and the independence from any training-set quantities is asserted but not shown via an explicit equation or pseudocode that would allow verification that the update remains purely test-time.
Authors: We accept that the online estimation procedure in §3.3 is described at a high level and that explicit verification of its test-time-only nature is needed. The method relies exclusively on second-order moments accumulated from the unlabeled test stream; no training-set statistics are used. In the revision we will supply the precise update equations for the anchor-conditioned co-occurrence matrix and include pseudocode that makes the streaming, training-set-independent computation fully verifiable. revision: yes
Circularity Check
No significant circularity; online unsupervised prior estimation is independent of target labels
full rationale
The derivation attributes shift errors to mismatched label prior p(y) while treating zero-shot logits as fixed-likelihood marginal posteriors, then estimates anchor-conditioned priors via second-order co-occurrence counts from the unlabeled test stream. This estimation step uses only test images and produces the adapted posteriors; it does not reduce to a fit on ground-truth labels or to any quantity derived from the evaluation metric itself. No equations are shown that equate the output to an input by construction, no self-citation chain carries the central claim, and the PMI interpretation follows directly from the stated Bayesian update rather than from renaming a known result. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Zero-shot logits serve as proxy for marginal posteriors under a fixed image-text likelihood
- domain assumption Shift-induced errors are mainly due to a mismatched label prior
invented entities (1)
-
Bayesian Conditional Priors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Boosting vision-language models with transduction , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation , author=
-
[3]
Advances in Neural Information Processing Systems , volume=
Statistics caching test-time adaptation for vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Training-free test-time adaptation via shape and style guidance for vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Test-time spectrum-aware latent steering for zero-shot generalization in vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
Dual Memory Networks: A Versatile Adaptation Approach for Vision-Language Models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
-
[7]
Test-Time Adaptation with
Shuai Zhao and Xiaohan Wang and Linchao Zhu and Yi Yang , booktitle=. Test-Time Adaptation with
-
[8]
Advances in Neural Information Processing Systems , volume=
Enhancing zero-shot vision models by label-free prompt distribution learning and bias correcting , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Discriminant analysis by Gaussian mixtures , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1996 , publisher=
1996
-
[10]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
ViLU: Learning vision-language uncertainties for failure prediction , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[11]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[12]
Advances in Neural Information Processing Systems , volume=
What matters when building vision-language models? , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[14]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[15]
Advances in neural information processing systems , volume=
Delving into out-of-distribution detection with vision-language representations , author=. Advances in neural information processing systems , volume=
-
[16]
European Conference on Computer Vision , pages=
Gallop: Learning global and local prompts for vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[17]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Conditional prompt learning for vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
International Journal of Computer Vision , volume=
Learning to prompt for vision-language models , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Maple: Multi-modal prompt learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
European Conference on Computer Vision , pages=
Proxyclip: Proxy attention improves clip for open-vocabulary segmentation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[22]
Proceedings of the 40th International Conference on Machine Learning , pages=
Open-vocabulary universal image segmentation with MaskCLIP , author=. Proceedings of the 40th International Conference on Machine Learning , pages=
-
[23]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Text is mass: Modeling as stochastic embedding for text-video retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A Parameter-Efficient and Fine-Grained Prompt Learning for Vision-Language Models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Forty-second International Conference on Machine Learning , year=
Understanding and Mitigating Miscalibration in Prompt Tuning for Vision-Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[26]
Proceedings of the 41st International Conference on Machine Learning , pages=
Open-vocabulary calibration for fine-tuned CLIP , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Visual-language prompt tuning with knowledge-guided context optimization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Advances in Neural Information Processing Systems , volume=
Dream the impossible: Outlier imagination with diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
arXiv preprint arXiv:2412.06014 , year=
Post-hoc probabilistic vision-language models , author=. arXiv preprint arXiv:2412.06014 , year=
-
[30]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Probvlm: Probabilistic adapter for frozen vison-language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[31]
Improved Probabilistic Image-Text Representations , author=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Probabilistic embeddings for cross-modal retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Advances in Neural Information Processing Systems , volume=
Test-time prompt tuning for zero-shot generalization in vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Diverse data augmentation with diffusions for effective test-time prompt tuning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Efficient test-time adaptation of vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Bayesian test-time adaptation for vision-language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[37]
Advances in Neural Information Processing Systems , volume=
Boostadapter: Improving vision-language test-time adaptation via regional bootstrapping , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Dual memory networks: A versatile adaptation approach for vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Advances in Neural Information Processing Systems , year=
Dota: Distributional test-time adaptation of vision-language models , author=. Advances in Neural Information Processing Systems , year=
-
[40]
Advances in Neural Information Processing Systems , year=
Backpropagation-Free Test-Time Adaptation via Probabilistic Gaussian Alignment , author=. Advances in Neural Information Processing Systems , year=
-
[41]
European Conference on Computer Vision , pages=
Identity mappings in deep residual networks , author=. European Conference on Computer Vision , pages=. 2016 , organization=
2016
-
[42]
The Thirteenth International Conference on Learning Representations , year=
Multi-Label Test-Time Adaptation with Bound Entropy Minimization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[43]
European Conference on Computer Vision , pages=
Microsoft coco: Common objects in context , author=. European Conference on Computer Vision , pages=. 2014 , organization=
2014
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Reconstructing pascal voc , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Text to Image for Multi-Label Image Recognition with Joint Prompt-Adapter Learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[46]
International Journal of Computer Vision , volume=
Clip-adapter: Better vision-language models with feature adapters , author=. International Journal of Computer Vision , volume=. 2024 , publisher=
2024
-
[47]
Proceedings of the ACM international conference on image and video retrieval , pages=
Nus-wide: a real-world web image database from national university of singapore , author=. Proceedings of the ACM international conference on image and video retrieval , pages=
-
[48]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
SPARC: Score Prompting and Adaptive Fusion for Zero-Shot Multi-Label Recognition in Vision-Language Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[49]
NeurIPS , pages=
Dualcoop: Fast adaptation to multi-label recognition with limited annotations , author=. NeurIPS , pages=
-
[50]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Texts as images in prompt tuning for multi-label image recognition , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[51]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
TAI++ text as image for multi-label image classification by co-learning transferable prompt , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[52]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Knowledge-guided multi-label few-shot learning for general image recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2020 , publisher=
2020
-
[53]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Inferring prototypes for multi-label few-shot image classification with word vector guided attention , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[54]
IEEE Transactions on Neural Networks and Learning Systems , year=
Leveraging Bilateral Correlations for Multi-Label Few-Shot Learning , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[55]
Language-Driven Cross-Modal Classifier for Zero-Shot Multi-Label Image Recognition , author=
-
[56]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Discriminative region-based multi-label zero-shot learning , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[57]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Generative multi-label zero-shot learning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dart: Dual-modal adaptive online prompting and knowledge retention for test-time adaptation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
Forty-first International Conference on Machine Learning , year=
Language-driven cross-modal classifier for zero-shot multi-label image recognition , author=. Forty-first International Conference on Machine Learning , year=
-
[60]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Dpu: Dynamic prototype updating for multimodal out-of-distribution detection , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[61]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Detecting out-of-distribution through the lens of neural collapse , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[62]
International conference on machine learning , pages=
Out-of-distribution detection with deep nearest neighbors , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[63]
IEEE transactions on pattern analysis and machine intelligence , volume=
Vision-language models for vision tasks: A survey , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[64]
Proceedings of GSCL , volume=
Normalized (pointwise) mutual information in collocation extraction , author=. Proceedings of GSCL , volume=. 2009 , publisher=
2009
-
[65]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Recover and Match: Open-Vocabulary Multi-Label Recognition through Knowledge-Constrained Optimal Transport , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[66]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Is less more? exploring token condensation as training-free test-time adaptation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[67]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
COSMIC: Clique-Oriented Semantic Multi-space Integration for Robust CLIP Test-Time Adaptation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[68]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.