LEDGER: A Long-Context Benchmark of Corporate Annual Reports for Grounded Financial Retrieval and Extraction
Pith reviewed 2026-06-27 07:07 UTC · model grok-4.3
The pith
LEDGER supplies 4,999 full corporate annual reports labeled with 31 financial KPIs to support three grounded long-context benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
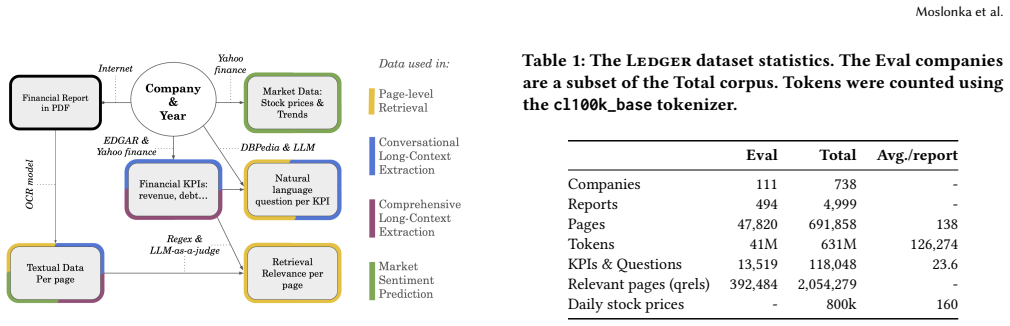
We release LEDGER (Long-context Evaluation of Documents for Grounded Extraction and Retrieval), a corpus of 4,999 digitized corporate annual reports labeled with 31 consolidated financial KPIs to be extracted and linked to the market's reaction at the earnings date, from which we derive three evaluation benchmarks spanning the difficulty spectrum: a pure page-level KPI retrieval task with TREC-style relevance judgments over 118,048 questions in natural language, a conversational needle-in-a-haystack single-value lookup, and a full KPI extraction task, both from long, numerically dense reports.
What carries the argument
The LEDGER corpus of labeled annual reports together with the derived page-retrieval, needle-in-a-haystack, and full-extraction benchmarks that turn the 31 KPIs into ground-truth targets for long-context evaluation.
If this is right
- Models can now be scored on retrieving the correct page for any of 118,048 natural-language questions about the 31 KPIs.
- The needle-in-a-haystack task directly measures whether a model can surface a single numeric value from a full multi-page report given a conversational query.
- The full extraction task tests end-to-end recovery of all 31 KPIs from complete, figure-rich documents.
- Human OCR annotations supply an explicit quality baseline for any automated extraction pipeline.
- The market-reaction case study supplies an additional downstream signal that can be correlated with extracted CEO-letter content.
Where Pith is reading between the lines
- The dataset could be used to test whether models that perform well on page retrieval also maintain accuracy when the retrieved pages must be combined for full KPI extraction.
- Because the reports are digitized rather than plain text, the benchmarks implicitly measure handling of layout and table structure in addition to pure language understanding.
- Linking extracted KPIs to market reactions opens the possibility of studying whether models can surface financially material signals that human analysts already price in.
- The three difficulty levels allow staged evaluation: a model that fails page retrieval is unlikely to succeed at full extraction, providing a natural curriculum for long-context training.
Load-bearing premise
The 31 KPIs can be reliably and consistently extracted across diverse reports with sufficient human annotation quality to serve as ground truth for the three benchmarks.
What would settle it
A new round of independent human annotation on a random sample of reports that produces materially different KPI values or low inter-annotator agreement would show the labels cannot function as reliable ground truth.
Figures
read the original abstract
Finance reporting is a natural proving ground for large language models, and the very-long-context capabilities of recent models across all sizes make rigorous evaluation in this domain an increasingly pressing need. Yet most public financial resources reduce the task to plain-text SEC 10-K filings paired with a handful of question-answer items. We release LEDGER (Long-context Evaluation of Documents for Grounded Extraction and Retrieval), a corpus of 4,999 digitized corporate annual reports - full documents with figures, tables, and narrative, not just regulatory filings. Each report is labeled with 31 consolidated financial KPIs to be extracted and linked to the market's reaction at the earnings date. From this data we derive three evaluation benchmarks spanning the difficulty spectrum: a pure page-level KPI retrieval task with TREC-style relevance judgments over 118,048 questions in natural language, a conversational "needle-in-a-haystack" single-value lookup, and a full KPI extraction task, both from long, numerically dense reports. We additionally provide human OCR-quality annotations with inter-annotator agreement and the complete extraction, validation, and scoring toolchain. We further demonstrate the dataset's research utility with a case study linking CEO-letter rhetoric to post-publication market impact.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the LEDGER dataset, comprising 4,999 digitized corporate annual reports labeled with 31 consolidated financial KPIs. It derives three benchmarks for long-context tasks: page-level retrieval with 118,048 questions, conversational needle-in-a-haystack, and full KPI extraction. The authors provide human annotations with inter-annotator agreement, the extraction toolchain, and a case study linking CEO rhetoric to market reactions.
Significance. If the ground-truth labels prove reliable, LEDGER would fill an important gap by providing a large-scale, long-context financial document benchmark that goes beyond plain-text 10-K filings and includes figures, tables, and narrative. The linkage to market reactions and the release of the full toolchain are notable strengths that could enable reproducible research in grounded financial NLP.
major comments (2)
- [Abstract and labeling section] Abstract and labeling description: the claim that the 31 KPI labels constitute reliable ground truth rests on human OCR-quality annotations with inter-annotator agreement, yet no numerical IAA scores, per-KPI error rates, or validation statistics are supplied. This directly affects whether the three derived benchmarks can be used for grounded evaluation.
- [Benchmark construction] Benchmark derivation: the manuscript states that three benchmarks spanning the difficulty spectrum are derived from the corpus, but supplies no quantitative validation results, error analysis, or details on how page-level judgments, needle-in-a-haystack items, or full extraction tasks were constructed and tested.
minor comments (1)
- [Abstract] The abstract reports 4,999 reports and 118,048 questions; confirm these figures are presented consistently in the main text and tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that supply the requested quantitative details.
read point-by-point responses
-
Referee: [Abstract and labeling section] Abstract and labeling description: the claim that the 31 KPI labels constitute reliable ground truth rests on human OCR-quality annotations with inter-annotator agreement, yet no numerical IAA scores, per-KPI error rates, or validation statistics are supplied. This directly affects whether the three derived benchmarks can be used for grounded evaluation.
Authors: We agree that explicit numerical IAA scores, per-KPI error rates, and validation statistics are required to substantiate the ground-truth claim. The current manuscript mentions the existence of IAA but does not report the values. In the revision we will add a new subsection (or expanded table) under the labeling description that reports overall and per-KPI Cohen’s kappa / percentage agreement, annotator disagreement rates, and any post-annotation validation statistics. This will directly support the reliability of the 31 KPI labels. revision: yes
-
Referee: [Benchmark construction] Benchmark derivation: the manuscript states that three benchmarks spanning the difficulty spectrum are derived from the corpus, but supplies no quantitative validation results, error analysis, or details on how page-level judgments, needle-in-a-haystack items, or full extraction tasks were constructed and tested.
Authors: We accept that the benchmark-construction section currently lacks the requested quantitative validation, error analysis, and construction details. The revision will expand this section with: (i) summary statistics on the 118,048 page-level questions and their relevance judgments, (ii) construction protocol and sampling method for the needle-in-a-haystack items, (iii) task-definition and annotation guidelines for the full KPI extraction benchmark, and (iv) any available consistency or error-analysis metrics obtained during benchmark creation. These additions will allow readers to assess the soundness of the three derived benchmarks. revision: yes
Circularity Check
No circularity: data release with no derivations or fitted predictions
full rationale
The paper releases a corpus of 4,999 reports with 31 KPI labels and derives three benchmarks from it. No equations, parameter fits, predictions, or self-citation chains appear in the provided text. The central contribution is the dataset and toolchain itself; label quality is an external validity concern, not a circular reduction of any claimed derivation to its inputs. No steps match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Digitized reports and human annotations provide reliable ground truth for KPI extraction across the corpus
Reference graph
Works this paper leans on
-
[1]
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyga- niak, and Zachary Ives. 2007. Dbpedia: A nucleus for a web of open data. In international semantic web conference. Springer, 722–735
2007
-
[2]
Nicolas Boizard, Hippolyte Gisserot-Boukhlef, Duarte M Alves, André Martins, Ayoub Hammal, Caio Corro, Céline Hudelot, Emmanuel Malherbe, Etienne Malaboeuf, Fanny Jourdan, et al. 2025. Eurobert: Scaling multilingual encoders for european languages.arXiv preprint arXiv:2503.05500(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dillon Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021. FinQA: A Dataset of Numerical Reasoning over Financial Data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2021
-
[5]
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. 2022. ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2022
-
[6]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval
2021
-
[7]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for Datasets. Commun. ACM64, 12 (2021), 86–92
2021
-
[8]
Google DeepMind. 2026. Gemini 3.1 Pro Model Card. https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf. Ac- cessed: 2026-06-01
2026
-
[9]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. 2024. RULER: What’s the Real Context Size of Your Long-Context Language Models?. InFirst Conference on Language Modeling. https://openreview.net/forum?id=kIoBbc76Sy
2024
-
[10]
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. 2023. FinanceBench: A New Benchmark for Financial Question Answering. arXiv:2311.11944 [cs.CL] LEDGER: A Long-Context Benchmark of Corporate Annual Reports for Grounded Financial Retrieval and Extraction
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Antonio Jimeno Yepes, Yao You, Jan Milczek, Sebastian Laverde, and Renyu Li
-
[12]
Financial Report Chunking for Effective Retrieval Augmented Generation. arXiv:2402.05131 [cs.CL]
-
[13]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 39–48
2020
-
[14]
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. 2026. Ministral 3.arXiv preprint arXiv:2601.08584 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics12 (2024), 157–173
2024
-
[16]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
António Loison, Quentin Macé, Antoine Edy, Victor Xing, Tom Balough, Gabriel Moreira, Bo Liu, Manuel Faysse, Céline Hudelot, and Gautier Viaud. 2026. ViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios.arXiv preprint arXiv:2601.08620(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Emmanuel Malherbe and Marie-Aude Aufaure. 2016. Bridge the terminology gap between recruiters and candidates: A multilingual skills base built from social media and linked data. In2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). IEEE, 583–590
2016
-
[19]
NVIDIA. 2025. Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning. https://arxiv.org/abs/2512. 20848 Technical report
2025
-
[20]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv:2508.10925 [cs.CL] https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Qwen Team. 2026. Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model. https://qwen.ai/blog?id=qwen3.6-27b
2026
-
[22]
Varshini Reddy, Rik Koncel-Kedziorski, Viet Dac Lai, Michael Krumdick, Charles Lovering, and Chris Tanner. 2024. DocFinQA: A Long-Context Financial Rea- soning Dataset. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Short Papers
2024
-
[23]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics. https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Foundations and Trends in Information Retrieval3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[25]
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2020. Mpnet: Masked and permuted pre-training for language understanding.Advances in neural information processing systems33 (2020), 16857–16867
2020
-
[26]
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, et al. 2025. Embeddinggemma: Powerful and lightweight text representations. arXiv preprint arXiv:2509.20354(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
2005.TREC: Experiment and evaluation in information retrieval
Ellen M Voorhees, Donna K Harman, et al. 2005.TREC: Experiment and evaluation in information retrieval. Vol. 63. MIT press Cambridge
2005
-
[28]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hall- ström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, and Iacopo Poli. 2024. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Infer...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. DeepSeek-OCR: Contexts Optical Compression.arXiv preprint arXiv:2510.18234(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
-
[31]
Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Ap- pleton, Myles Axton, Arie Baak, et al
Mark D. Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, Gabrielle Ap- pleton, Myles Axton, Arie Baak, et al . 2016. The FAIR Guiding Principles for Scientific Data Management and Stewardship.Scientific Data3, 1 (2016), 160018
2016
-
[32]
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. BloombergGPT: A Large Language Model for Finance. arXiv:2303.17564 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2023. C-Pack: Packaged Resources To Advance General Chinese Embedding. arXiv:2309.07597 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. 2021. TAT-QA: A Question An- swering Benchmark on a Hybrid of Tabular and Textual Content in Finance. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.