DuET: Dual Expert Trajectories for Diffusion Image Editing
Pith reviewed 2026-06-27 06:57 UTC · model grok-4.3
The pith
DuET improves diffusion image editing by temporarily switching to text-to-image conditioning during denoising.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
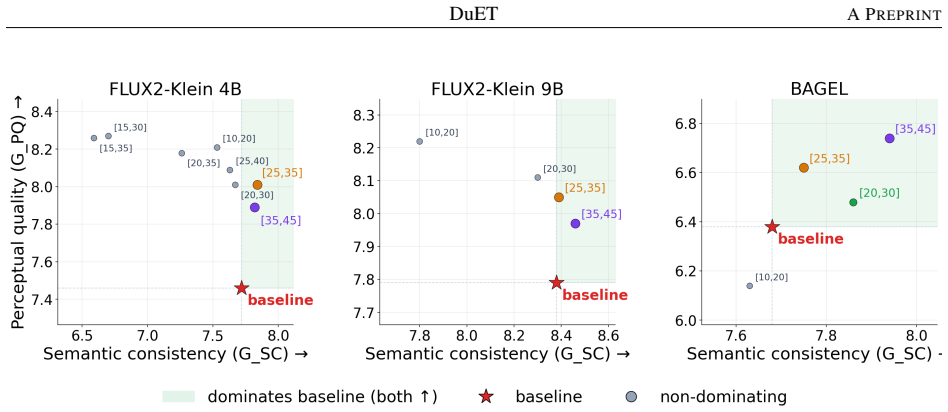
The paper claims that inserting a temporary text-to-image denoising segment into an otherwise image-conditioned editing trajectory moves the sample toward the target distribution more effectively than continuous source conditioning, yielding edits that better satisfy the instruction while retaining structural benefits from the source image.
What carries the argument
Dual Expert Trajectories, the mechanism of switching between an image-conditioned expert and a text-conditioned expert for a portion of the denoising steps before returning to edit mode.
If this is right
- Instruction relevance rises across diverse models and benchmarks without any training or extra compute.
- Semantic fidelity and perceptual quality improve while source-image structure still guides the result.
- The approach reveals a predictable trade-off in which source preservation can decrease modestly when edit fidelity increases.
- The same trajectory switch works without modifying model weights or increasing sampling steps.
Where Pith is reading between the lines
- The same temporary relaxation idea could be tested on video or 3D diffusion pipelines where persistent conditioning also limits large changes.
- The result suggests that full source conditioning throughout denoising may be suboptimal precisely when the edit target diverges most from the input.
- Future work could measure exactly how long the text-only segment should last to maximize the fidelity gain while minimizing any preservation loss.
Load-bearing premise
A temporary transition through a text-to-image phase during denoising will move the trajectory toward the target distribution while retaining the structural benefits of image-conditioned editing without introducing new inconsistencies or artifacts.
What would settle it
A controlled experiment on large-divergence edits where DuET produces no measurable gain in instruction relevance or semantic fidelity metrics, or introduces visible artifacts absent from standard editing, would falsify the central claim.
Figures




read the original abstract
Recent diffusion editors perform diverse instruction-based edits while conditioning on the source image at every denoising step. Yet persistent source-image conditioning can limit how fully an edit is executed and how natural the result appears, especially when the target scene diverges substantially from the input. We introduce DuET (Dual Expert Trajectories), a training-free inference method that temporarily relaxes source-image conditioning by transitioning through a text-to-image phase before returning to edit mode, allowing the denoising trajectory to move toward the target distribution while retaining the structural benefits of image-conditioned editing. Without modifying model weights or increasing sampling cost, DuET consistently improves instruction relevance, semantic fidelity, and perceptual quality across diverse models and benchmarks. In some cases, these gains come with a modest reduction in source-image preservation, revealing a predictable trade-off between source preservation and edit fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DuET, a training-free inference-time method for instruction-based diffusion image editing. It temporarily relaxes persistent source-image conditioning by transitioning the denoising trajectory through a text-to-image phase before returning to edit mode, with the goal of allowing fuller movement toward the target distribution while retaining structural benefits from image conditioning. The central claim is that this dual-trajectory construction yields consistent gains in instruction relevance, semantic fidelity, and perceptual quality across models and benchmarks without modifying weights or increasing sampling cost, at the possible expense of modest reductions in source-image preservation for some cases.
Significance. If the dual-trajectory construction is robust, the method provides a lightweight, training-free way to mitigate limitations of persistent conditioning in diffusion editors, particularly for edits with large scene divergence. The absence of weight changes or extra sampling cost is a practical strength that could allow immediate application to existing models.
major comments (1)
- [Method description] Method description (no section/equation numbers supplied in abstract or provided text): the central claim that the temporary T2I phase moves the trajectory toward the target distribution while retaining structural benefits upon return to edit mode lacks any explicit verification or ablation that the post-T2I latent remains compatible with subsequent image-conditioned steps. This is load-bearing for the reported gains in instruction relevance and semantic fidelity, especially given the acknowledged trade-off in source preservation.
minor comments (1)
- [Abstract] Abstract states consistent improvements but supplies no quantitative metrics, baselines, or experimental details; the full manuscript should ensure all claims are backed by specific numbers and controls in the results section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the single major comment below and agree that additional verification would strengthen the presentation of the method.
read point-by-point responses
-
Referee: [Method description] Method description (no section/equation numbers supplied in abstract or provided text): the central claim that the temporary T2I phase moves the trajectory toward the target distribution while retaining structural benefits upon return to edit mode lacks any explicit verification or ablation that the post-T2I latent remains compatible with subsequent image-conditioned steps. This is load-bearing for the reported gains in instruction relevance and semantic fidelity, especially given the acknowledged trade-off in source preservation.
Authors: We agree that an explicit ablation or analysis confirming compatibility of the post-T2I latent with resumed image-conditioned steps would more directly substantiate the central claim. The current manuscript supports the claim indirectly through consistent quantitative gains in instruction relevance, semantic fidelity, and perceptual quality across models and benchmarks, together with the observed (and acknowledged) trade-off in source preservation; these outcomes would not be possible if the latent were incompatible upon return to edit mode. Nevertheless, to address the concern directly we will add a targeted ablation in the revision that examines latent compatibility (e.g., via cosine similarity between pre- and post-T2I states when image conditioning is re-applied, or reconstruction fidelity after resuming the edit trajectory). We will also insert explicit section and equation references in the abstract and main text. These changes will appear in the revised version. revision: yes
Circularity Check
No circularity; procedural method with no derived quantities or self-referential reductions.
full rationale
The paper introduces DuET as a training-free inference procedure that temporarily switches diffusion conditioning modes during denoising. No equations, fitted parameters, predictions, or first-principles derivations are present in the provided text. The claimed improvements are presented as empirical outcomes of the described trajectory switch rather than quantities obtained by algebraic reduction or self-citation. No load-bearing steps reduce to inputs by construction, and the method is self-contained as an explicit algorithmic change without invoking uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Karras, and Ming-Yu Liu. eDiff-I: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv preprint arXiv:2211.01324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Improving Text-to-Image Consistency via Automatic Prompt Optimization, March 2024
Oscar Mañas, Pietro Astolfi, Melissa Hall, Candace Ross, Jack Urbanek, Adina Williams, Aishwarya Agrawal, Adriana Romero-Soriano, and Michal Drozdzal. Improving text-to-image consistency via automatic prompt optimization. arXiv preprint arXiv:2403.17804,
-
[5]
Test-time prompt refinement for text-to-image models.arXiv preprint arXiv:2507.22076,
Mohammad Abdul Hafeez Khan, Yash Jain, Siddhartha Bhattacharyya, and Vibhav Vineet. Test-time prompt refinement for text-to-image models.arXiv preprint arXiv:2507.22076,
-
[6]
Shufan Li, Konstantinos Kallidromitis, Akash Gokul, Arsh Koneru, Yusuke Kato, Kazuki Kozuka, and Aditya Grover. Reflect-DiT: Inference-time scaling for text-to-image diffusion transformers via in-context reflection.arXiv preprint arXiv:2503.12271,
-
[7]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, Bingchen Liu, Daquan Zhou, and Song Han. SANA 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer.arXiv preprint arXiv:2501.18427,
-
[8]
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, and Saining Xie. Inference-time scaling for diffusion models beyond scaling denoising steps. arXiv preprint arXiv:2501.09732, 2025b. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, et al. Gemini 2.5: Pushing the frontier with a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, Guopeng Li, Yuang Peng, Quan Sun, Jingwei Wu, Yan Cai, Zheng Ge, Ranchen Ming, Lei Xia, Xianfang Zeng, Yibo Zhu, Binxing Jiao, Xiangyu Zhang, Gang Yu, and Daxin Jiang. Step1X-Edit: A practical framework for general image editing.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. ImgEdit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yusu Qian, Jiasen Lu, Tsu-Jui Fu, Xinze Wang, Chen Chen, Yinfei Yang, Wenze Hu, and Zhe Gan. GIE-Bench: Towards grounded evaluation for text-guided image editing.arXiv preprint arXiv:2505.11493,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.