ReFree: Towards Realistic Co-Speech Video Generation via Reward-Free RL and Multilevel Speech Guidance
Pith reviewed 2026-06-27 06:54 UTC · model grok-4.3
The pith
ReFree-S2V combines multilevel speech guidance with reward-free RL in a flow-matching model to generate more natural talking-head videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
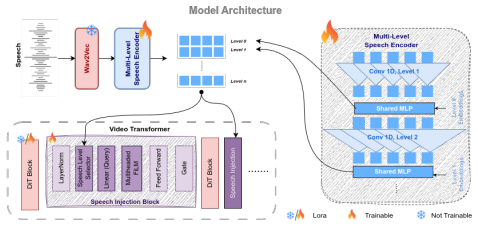
ReFree-S2V is a flow-matching speech-to-portrait animation framework that builds upon a pretrained video generation model, introduces a multi-level speech representation capturing phonetic and prosodic information at both local and global granularities, selectively injects these representations into transformer blocks via learnable level selectors for accurate lip synchronization and natural expressive motion, and incorporates a novel reward-free reinforcement learning scheme into flow-matching training to discourage perceptually implausible head motion without relying on handcrafted synchronization metrics, reward models, or human preference annotation.
What carries the argument
Multi-level speech representation injected via learnable level selectors into transformer blocks of a flow-matching model, combined with reward-free RL added to the training loop.
If this is right
- Lip synchronization and expressive motion can be achieved simultaneously rather than traded off.
- Natural head movements emerge during training without explicit motion rewards or labels.
- Pretrained video generation models can be specialized for speech-driven animation with modest additional components.
- Quantitative lip-sync metrics improve while qualitative human judgments of naturalness also rise.
Where Pith is reading between the lines
- The same multilevel injection and reward-free scheme might transfer to full-body gesture synthesis from audio.
- Training costs could drop further if the RL component is made compatible with even larger pretrained backbones.
- The approach suggests a route to personalization of talking avatars with less reliance on paired motion data.
- Similar reward-free signals might help other motion-generation tasks where perceptual quality is hard to score directly.
Load-bearing premise
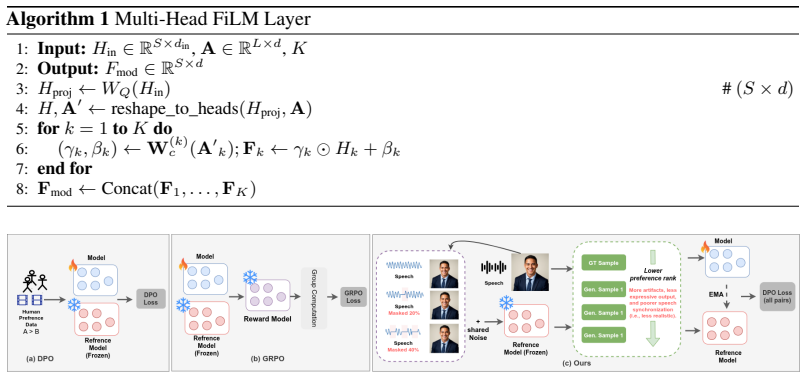
The reward-free reinforcement learning scheme added to flow-matching training can discourage perceptually implausible head motion without any handcrafted synchronization metrics, reward models, or human preference annotations.
What would settle it
An ablation study in which removing the reward-free RL component leaves head motion quality unchanged or worse, or a human evaluation in which ReFree-S2V videos receive lower naturalness or lip-sync scores than strong baselines.
Figures




read the original abstract
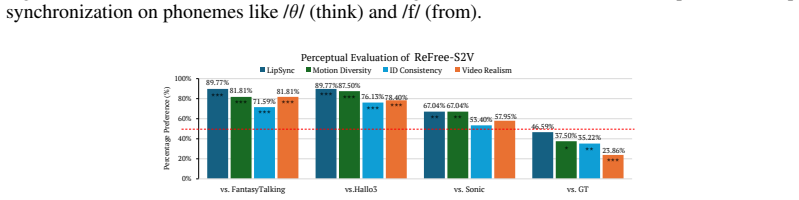
Speech-driven talking character animation seeks to generate life-like portrait videos that convey natural conversation behavior, aligning facial motion with spoken audio. Although recent advances in video generation have substantially improved realism in video-based animation, achieving both accurate lip articulation and expressive behavior remains challenging. Existing approaches typically trade off precise phoneme-to-lip synchronization against dynamic facial expressions and head motion, yielding animations that are either accurate yet rigid, or expressive but poorly synchronized. We address this challenge by proposing ReFree-S2V, a flow-matching speech-to-portrait animation framework that builds upon a pretrained video generation model to achieve fine-grained speech articulation and high-level expressive cues in speech-driven portrait animation. This model introduces a multi-level speech representation capturing phonetic and prosodic information at both local and global granularities. These representations are selectively injected into transformer blocks via learnable level selectors, enabling both accurate lip synchronization and natural expressive motion. To achieve natural head movements, we further introduce a novel reward-free reinforcement learning scheme into flow-matching training to discourage perceptually implausible motion without relying on handcrafted synchronization metrics or reward models, or the high cost of human preference annotation. Extensive experiments demonstrate that ReFree-S2V achieves state-of-the-art performance, significantly outperforming existing methods in both quantitative lip-sync accuracy and qualitative human evaluations of naturalness and expressivity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReFree-S2V, a flow-matching framework for speech-driven portrait video generation. It augments a pretrained video model with multilevel speech representations (phonetic and prosodic at local/global scales) that are injected into transformer blocks via learnable level selectors, and adds a reward-free RL stage during training intended to discourage implausible head motion without handcrafted metrics, reward models, or human annotations. The central claim is that this yields SOTA lip-sync accuracy and superior human-rated naturalness/expressivity over prior methods.
Significance. If the reward-free RL component can be shown to supply a usable directional signal from the flow-matching objective alone, the approach would reduce reliance on expensive preference data or auxiliary reward models in co-speech animation. The multilevel guidance mechanism is a standard architectural choice whose incremental value would need isolation via ablations. Overall significance is difficult to judge because the abstract supplies no quantitative results, baselines, or experimental protocol.
major comments (2)
- [Abstract] Abstract: the claim that ReFree-S2V 'achieves state-of-the-art performance, significantly outperforming existing methods in both quantitative lip-sync accuracy and qualitative human evaluations' is presented without any reported metrics, tables, datasets, baselines, or ablation results. This absence is load-bearing for the central superiority claim and prevents any assessment of the data-to-claim link.
- [Abstract] Abstract (reward-free RL paragraph): the scheme is asserted to 'discourage perceptually implausible motion without relying on handcrafted synchronization metrics or reward models, or the high cost of human preference annotation,' yet no objective, selection mechanism, or internal signal is specified that would actually supply a learning gradient. If the signal is functionally equivalent to a standard self-supervised or flow-matching loss, the 'reward-free' attribution cannot be isolated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address both major comments below and will revise the abstract accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that ReFree-S2V 'achieves state-of-the-art performance, significantly outperforming existing methods in both quantitative lip-sync accuracy and qualitative human evaluations' is presented without any reported metrics, tables, datasets, baselines, or ablation results. This absence is load-bearing for the central superiority claim and prevents any assessment of the data-to-claim link.
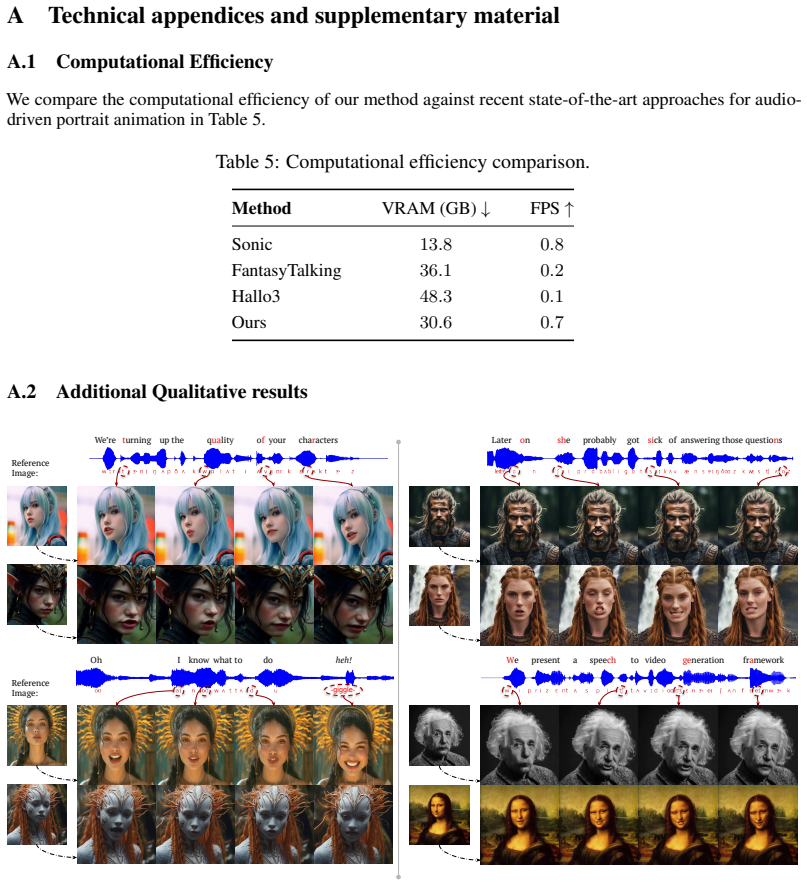
Authors: We agree that the abstract should include concrete quantitative support to substantiate the SOTA claim. In the revised version, we will add a sentence reporting key metrics (e.g., LSE-D and LSE-C improvements on VoxCeleb2 and HDTF, plus human preference scores for naturalness/expressivity) along with the main baselines and datasets. This directly addresses the data-to-claim linkage while keeping the abstract concise. revision: yes
-
Referee: [Abstract] Abstract (reward-free RL paragraph): the scheme is asserted to 'discourage perceptually implausible motion without relying on handcrafted synchronization metrics or reward models, or the high cost of human preference annotation,' yet no objective, selection mechanism, or internal signal is specified that would actually supply a learning gradient. If the signal is functionally equivalent to a standard self-supervised or flow-matching loss, the 'reward-free' attribution cannot be isolated.
Authors: The full manuscript (Section 3.3) specifies that the reward-free RL stage derives its learning signal directly from the flow-matching objective via an internal selection mechanism on trajectory samples that penalizes motion distributions deviating from the data manifold, without external rewards. We acknowledge the abstract is too terse on this point. We will revise the abstract paragraph to briefly name the internal signal (flow-matching likelihood) and selection process, allowing isolation from standard losses. revision: yes
Circularity Check
No circularity detectable from provided text
full rationale
The abstract and surrounding description introduce a reward-free RL scheme and multilevel speech guidance but contain no equations, training objectives, derivation steps, or self-citations. Without any quoted paper text exhibiting a reduction of a claimed prediction or result to its own inputs by construction, none of the enumerated circularity patterns can be identified. The derivation chain is therefore treated as self-contained against external benchmarks per the evaluation rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Xu Bin, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,Inter...
2025
-
[3]
URL https://proceedings.iclr.cc/paper_files/paper/2025/ file/ce31378e9f41d8907e97dab172b6c559-Paper-Conference.pdf. Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Z...
2025
-
[4]
URL https: //arxiv.org/abs/2508.18621. Jiahao Cui, Hui Li, Yun Zhan, Hanlin Shang, Kaihui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21086–21095, 2025a. Xiaozho...
-
[6]
Reinforcement learning for large model: A survey.arXiv preprint arXiv:2508.08189, 2025
Weijia Wu, Chen Gao, Joya Chen, Kevin Qinghong Lin, Qingwei Meng, Yiming Zhang, Yuke Qiu, Hong Zhou, and Mike Zheng Shou. Reinforcement learning for large model: A survey.arXiv preprint arXiv:2508.08189,
-
[7]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Zhaoqing Wang, Xiaobo Xia, Zhuolin Bie, Jinlin Liu, Dongdong Yu, Jia-Wang Bian, and Changhu Wang. Taming camera-controlled video generation with verifiable geometry reward.arXiv preprint arXiv:2512.02870, 2025b. Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your perso...
-
[10]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023b. Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Puru...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
In: Proceedings of the 28th ACM International Conference on Multimedia
Association for Computing Machinery. ISBN 9781450379885. doi: 10.1145/3394171.3413532. URLhttps://doi.org/10.1145/3394171.3413532. Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. adtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. InProceedings of ...
-
[12]
Deepvideo-r1: Video reinforcement fine-tuning via difficulty-aware regressive grpo,
Jinyoung Park, Jeehye Na, Jinyoung Kim, and Hyunwoo J Kim. Deepvideo-r1: Video reinforcement fine-tuning via difficulty-aware regressive grpo.arXiv preprint arXiv:2506.07464,
-
[13]
Jiahao Cui, Yan Chen, Mingwang Xu, Hanlin Shang, Yuxuan Chen, Yun Zhan, Zilong Dong, Yao Yao, Jingdong Wang, and Siyu Zhu. Hallo4: High-fidelity dynamic portrait animation via direct preference optimization and temporal motion modulation.arXiv preprint arXiv:2505.23525, 2025b. Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wil...
-
[14]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter
Accessed: 2026-01-22. Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30,
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.