AgentRivet: an automated system for producing Rivet routines from journal publications
Pith reviewed 2026-06-27 04:48 UTC · model grok-4.3
The pith
Large language models can extract analysis details from papers and generate working Rivet routines with reasonable fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
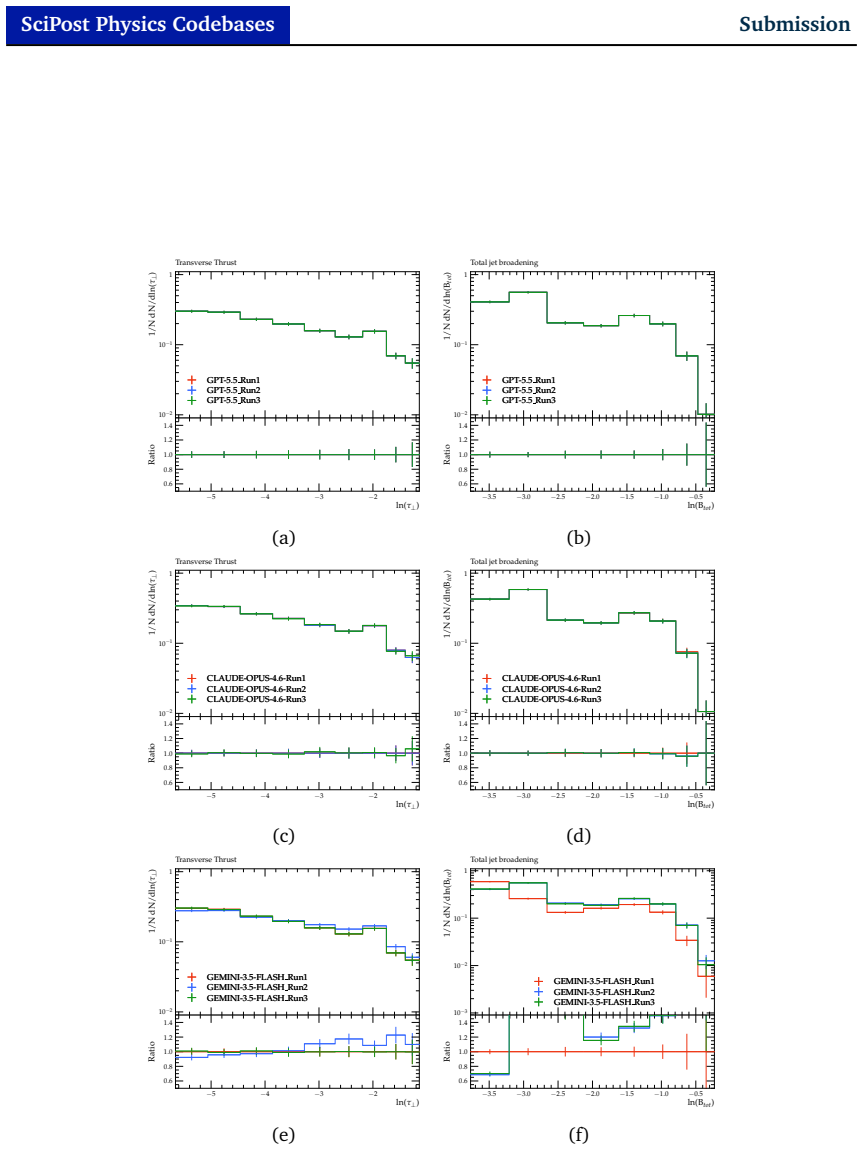
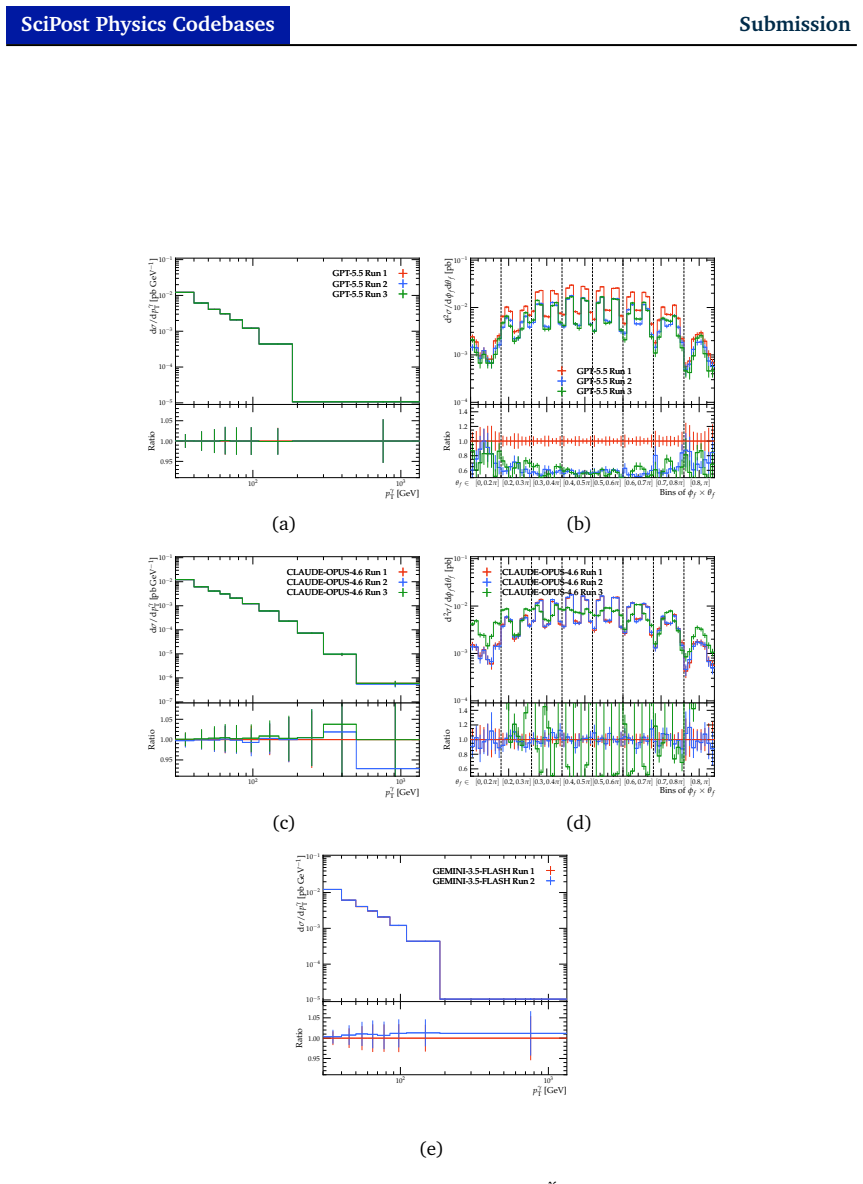
AgentRivet is a multi-step workflow based on Large Language Models that extracts the physics analysis information from published papers and writes the missing Rivet routines, with intermediate code- and physics-reviews as part of an autonomous quality control. Tests on two measurements show that the system produces competent Rivet routines with few syntax errors. The physics fidelity of the routines is reasonable and follows the explanations given in the relevant publications, although physics-implementation issues arise mainly from subtle ambiguities in the source papers.
What carries the argument
The multi-step LLM workflow that extracts observables, cuts and fiducial regions from papers, writes Rivet code, and performs autonomous code and physics reviews before output.
If this is right
- Rivet coverage can rise above the current 39 percent of measurements.
- New Monte Carlo models can be tested against a larger set of preserved analyses without manual coding.
- Searches for physics beyond the Standard Model gain access to additional fiducial measurements.
- Analysis preservation becomes less dependent on individual authors writing routines after publication.
Where Pith is reading between the lines
- The method may allow routine generation to keep pace with the growing volume of published measurements.
- Ambiguous wording in papers will continue to require targeted human checks even after automation.
- The workflow could be extended to flag papers whose definitions are too vague for reliable implementation.
- Integration into journal submission processes might encourage clearer reporting of analysis details.
Load-bearing premise
Published papers contain sufficiently unambiguous definitions of observables, cuts and fiducial regions that LLMs can extract and implement them correctly without human clarification.
What would settle it
Running the generated Rivet routines on the original datasets and comparing the resulting distributions directly to the published measurement results would show whether the physics implementation is correct.
Figures

read the original abstract
Particle physics collider experiments provide Rivet routines as part of the analysis preservation strategy for model-independent measurements. Rivet is a C++ toolkit that allow new theoretical models to be compared to the measurements, thus aiding the development and tuning of Monte Carlo event generators as well as searches for physics beyond the Standard Model. However, analysis coverage is known to be incomplete, with only 39% of measurements having documented and publicly available Rivet routines. In this article, we design and implement an automated workflow based on Large Language Models with the goal of providing the missing routines. This multi-step workflow, referred to as AgentRivet, extracts the physics analysis information from published papers and writes the missing Rivet routines, with intermediate code- and physics- reviews as part of an autonomous quality control. We report the results obtained using commercial Large Language Models, provided by OpenAI, Anthropic, and Google, for two recent measurements from the ATLAS and CMS experiments. We find that AgentRivet produces competent Rivet routines with few syntax errors. The physics fidelity of the routines is reasonable and follows the explanations given in the relevant publications. Nevertheless, physics-implementation issues do arise and are investigated using the artefacts produced by AgentRivet. The majority of physics implementation issues arise from subtle-but-ambiguous definitions in the given publication, although some models struggle to implement complex observables even when clear definitions are given.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentRivet, an automated multi-step workflow using commercial LLMs (from OpenAI, Anthropic, and Google) to extract physics analysis details from journal publications and generate Rivet routines, incorporating intermediate code- and physics-review steps for quality control. It reports results from applying the system to two recent ATLAS and CMS measurements, claiming that the output routines are competent with few syntax errors and exhibit reasonable physics fidelity that follows the source publications, while noting that some implementation issues arise primarily from ambiguous definitions in the papers.
Significance. If the approach can be shown to scale reliably, it would address the known gap in Rivet coverage (currently only 39% of measurements) and thereby improve model-independent comparisons between theory and experiment, Monte Carlo tuning, and BSM searches. The multi-provider LLM strategy and autonomous review steps represent a constructive engineering effort toward automation; however, the present demonstration supplies no quantitative performance metrics and rests on a sample of two analyses, so the immediate significance remains limited.
major comments (2)
- [Abstract] Abstract and reported results: the central claim that AgentRivet 'produces competent Rivet routines' rests on qualitative judgments ('few syntax errors', 'reasonable' fidelity) for exactly two test cases, with no tabulated error counts, success rates, inter-rater agreement, or side-by-side comparison against human-written Rivet code. This small-N, non-metric evaluation is load-bearing for the claim and leaves its generality unestablished.
- [Workflow and results] Workflow description and results: the physics-review stage is performed by an LLM of the same class as the generation stage, yet the manuscript supplies neither frequency/severity statistics for the observed physics issues nor an external validation protocol. Without these, the assertion that issues 'arise from subtle-but-ambiguous definitions' cannot be quantified even within the two reported cases.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. Our work presents AgentRivet as a proof-of-concept demonstration on two analyses, and we agree the evaluation can be strengthened with additional quantitative details from the existing cases. We respond point-by-point below, indicating planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and reported results: the central claim that AgentRivet 'produces competent Rivet routines' rests on qualitative judgments ('few syntax errors', 'reasonable' fidelity) for exactly two test cases, with no tabulated error counts, success rates, inter-rater agreement, or side-by-side comparison against human-written Rivet code. This small-N, non-metric evaluation is load-bearing for the claim and leaves its generality unestablished.
Authors: We agree the evaluation is qualitative and limited to two cases, consistent with the manuscript's framing as an initial demonstration of workflow feasibility rather than a broad benchmark. We will revise the abstract and results to include tabulated counts of syntax errors (e.g., compilation issues) and physics discrepancies per case, with explicit examples. Inter-rater agreement metrics are not applicable to this author-reviewed assessment. Side-by-side human comparisons are not included, as they require separate expert effort, but all generated routines and artefacts will be released to support such evaluations. The revisions will emphasize the proof-of-concept scope while making the reported observations more precise. revision: yes
-
Referee: [Workflow and results] Workflow description and results: the physics-review stage is performed by an LLM of the same class as the generation stage, yet the manuscript supplies neither frequency/severity statistics for the observed physics issues nor an external validation protocol. Without these, the assertion that issues 'arise from subtle-but-ambiguous definitions' cannot be quantified even within the two reported cases.
Authors: The physics-review LLM provides an initial automated check, but issue classification (ambiguous definitions versus model limitations) derives from the authors' subsequent manual inspection of outputs against the source papers. We will revise the workflow and results sections to add frequency and severity statistics for physics issues in both test cases, with categorization and examples. This will quantify the assertion within the reported scope. A formal external validation protocol is not implemented here and lies beyond the current demonstration; we will explicitly note this as a limitation and potential future extension. revision: yes
Circularity Check
No circularity: workflow and evaluation rest on external publications and standard Rivet framework
full rationale
The paper presents an LLM-driven workflow (AgentRivet) that extracts analysis details from published papers and generates Rivet code, with intermediate reviews. Its central claim is an empirical demonstration on two independent ATLAS/CMS measurements, asserting competent output and reasonable fidelity by direct comparison to the source publications' explanations. No equations, fitted parameters, or derivations are involved. No self-citations are invoked as load-bearing premises, and the evaluation does not reduce to any input by construction. The process is self-contained against external benchmarks (the original journal papers and the Rivet toolkit), satisfying the default expectation of no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
HEPData: a repository for high energy physics data
Maguire, Eamonn and Heinrich, Lukas and Watt, Graeme. HEPData: a repository for high energy physics data. J. Phys. Conf. Ser. 2017. doi:10.1088/1742-6596/898/10/102006. arXiv:1704.05473
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/1742-6596/898/10/102006 2017
-
[2]
Christian Bierlich and others , journal=. 2024 , publisher=. doi:10.21468/SciPostPhysCodeb.36 , url=
-
[3]
A. Buckley and others , journal=. 2021 , publisher=. doi:10.21468/SciPostPhysCore.4.2.013 , url=
-
[4]
ATLAS Collaboration. Measurement and interpretation of inclusive W production in proton-proton collisions at s =13 TeV using the ATLAS detector. 2026. arXiv:2603.22478
arXiv 2026
-
[5]
ATLAS Collaboration. Precise measurement of the t t production cross-section and lepton differential distributions in e dilepton events from s =13 TeV pp collisions with the ATLAS detector. Eur. Phys. J. C. 2026. doi:10.1140/epjc/s10052-026-15311-0. arXiv:2509.15066
-
[6]
CMS Collaboration. Measurement of event shape variables using charged particles inside jets in proton-proton collisions at s = 13 TeV. 2026. arXiv:2602.17509
arXiv 2026
-
[7]
Alwall, J. and others. The automated computation of tree-level and next-to-leading order differential cross sections, and their matching to parton shower simulations. JHEP. 2014. doi:10.1007/JHEP07(2014)079. arXiv:1405.0301
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/jhep07(2014)079 2014
-
[8]
Recommendations for Best Practices for Data Preservation and Open Science in HEP
Campana, Simone and others. Recommendations for Best Practices for Data Preservation and Open Science in HEP. 2025. arXiv:2508.18892
arXiv 2025
-
[9]
Arbey, Alexandre and others. DPHEP-2025-01 , title = ". 2025. arXiv:2503.23619
arXiv 2025
-
[10]
Waleed Abdallah and others , journal=. 2020 , publisher=. doi:10.21468/SciPostPhys.9.2.022 , url=
-
[11]
A comprehensive guide to the physics and usage of PYTHIA 8.3
Bierlich, Christian and others. A comprehensive guide to the physics and usage of PYTHIA 8.3. SciPost Phys. Codeb. 2022. doi:10.21468/SciPostPhysCodeb.8. arXiv:2203.11601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21468/scipostphyscodeb.8 2022
-
[12]
Jason Wei and others , title =. Trans. Mach. Learn. Res. , volume =. 2022 , eprint =
2022
-
[13]
NeurIPS 2023
Are Emergent Abilities of Large Language Models a Mirage? , author=. NeurIPS 2023. 2023 , eprint=
2023
-
[14]
Mark Chen and others , title =. 2021 , url =. 2107.03374 , timestamp =
Pith/arXiv arXiv 2021
-
[15]
2023 , eprint=
News Summarization and Evaluation in the Era of GPT-3 , author=. 2023 , eprint=
2023
-
[16]
Wang, Lei and others , year=. A survey on large language model based autonomous agents , volume=. Frontiers of Computer Science , publisher=. doi:10.1007/s11704-024-40231-1 , number=
-
[17]
2026 , month =
Hightower, Kelsey , title =. 2026 , month =
2026
-
[18]
Diefenbacher, Sascha and others , title = ". 2025. arXiv:2509.08535
arXiv 2025
-
[19]
Moreno, Eric A. and others. AI Agents Can Already Autonomously Perform Experimental High Energy Physics. 2026. arXiv:2603.20179
Pith/arXiv arXiv 2026
-
[20]
Badea, Anthony and others. Agentic AI -- Physicist Collaboration in Experimental Particle Physics: A Proof-of-Concept Measurement with LEP Open Data. 2026. arXiv:2603.05735
arXiv 2026
-
[21]
Dr.Sai: An agentic AI for real-world physics analysis at BESIII
He, Mingfeng and others. Dr.Sai: An agentic AI for real-world physics analysis at BESIII. 2026. arXiv:2604.22541
Pith/arXiv arXiv 2026
-
[22]
HEPTAPOD: Orchestrating High Energy Physics Workflows Towards Autonomous Agency
Menzo, Tony and others. HEPTAPOD: Orchestrating High Energy Physics Workflows Towards Autonomous Agency. FERMILAB-PUB-25-0923-CSAID-ETD-T. 2025. arXiv:2512.15867
arXiv 2025
-
[23]
GRACE: an Agentic AI for Particle Physics Experiment Design and Simulation
Hill, Justin and Ryoo, Hong Joo. GRACE: an Agentic AI for Particle Physics Experiment Design and Simulation. 2026. arXiv:2602.15039
arXiv 2026
-
[24]
Automating High Energy Physics Data Analysis with LLM-Powered Agents
Gendreau-Distler, Eli and others. Automating High Energy Physics Data Analysis with LLM-Powered Agents. NeurIPS 2025. 2025. arXiv:2512.07785
arXiv 2025
-
[25]
Plehn, Tilman and Schiller, Daniel and Schmal, Nikita. MadAgents. 2026. arXiv:2601.21015
Pith/arXiv arXiv 2026
-
[26]
Qwen2.5-Coder Technical Report
Hui, Binyuan and others. Qwen2.5-Coder Technical Report. 2024. arXiv:2409.12186
Pith/arXiv arXiv 2024
-
[27]
Measurements of ZZ and ZZjj jj productions in pp collisions at s =13 TeV with the ATLAS detector
ATLAS Collaboration. Measurements of ZZ and ZZjj jj productions in pp collisions at s =13 TeV with the ATLAS detector. 2025. arXiv:2511.15569
arXiv 2025
-
[28]
2017 , url =
Ashish Vaswani and others , title =. 2017 , url =
2017
- [29]
-
[30]
doi:10.5281/zenodo.20646340 , url =
Doglioni, Caterina and Gutschow, Christian and Jacques Costa, António and Pilkington, Andrew and Sinha, Sukanya , title = ". doi:10.5281/zenodo.20646340 , url =
-
[31]
and Palacios Schweitzer, Sofia and Pang, Ian and Mishra-Sharma, Siddharth and Shih, David
Faroughy, Darius A. and Palacios Schweitzer, Sofia and Pang, Ian and Mishra-Sharma, Siddharth and Shih, David. Collider-Bench: Benchmarking AI Agents with Particle Physics Analysis Reproduction. 2026. arXiv:2605.13950
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.