EvTexture++: Event-Driven Texture Enhancement for Video Super-Resolution
Pith reviewed 2026-06-27 07:04 UTC · model grok-4.3
The pith
Event signals can be redirected from motion to texture enhancement for better video super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
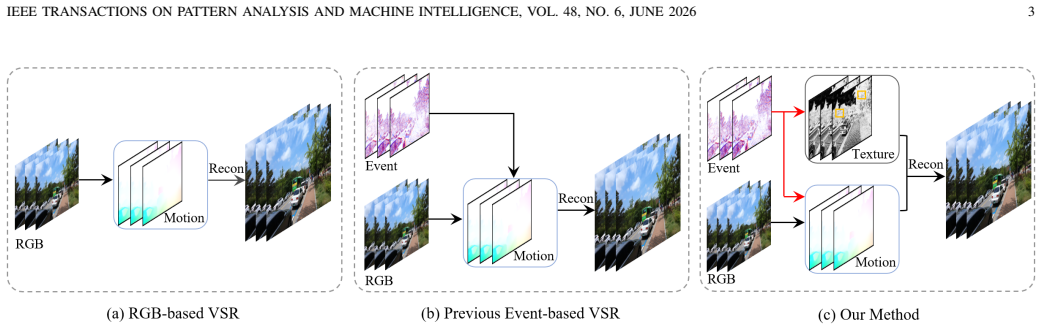
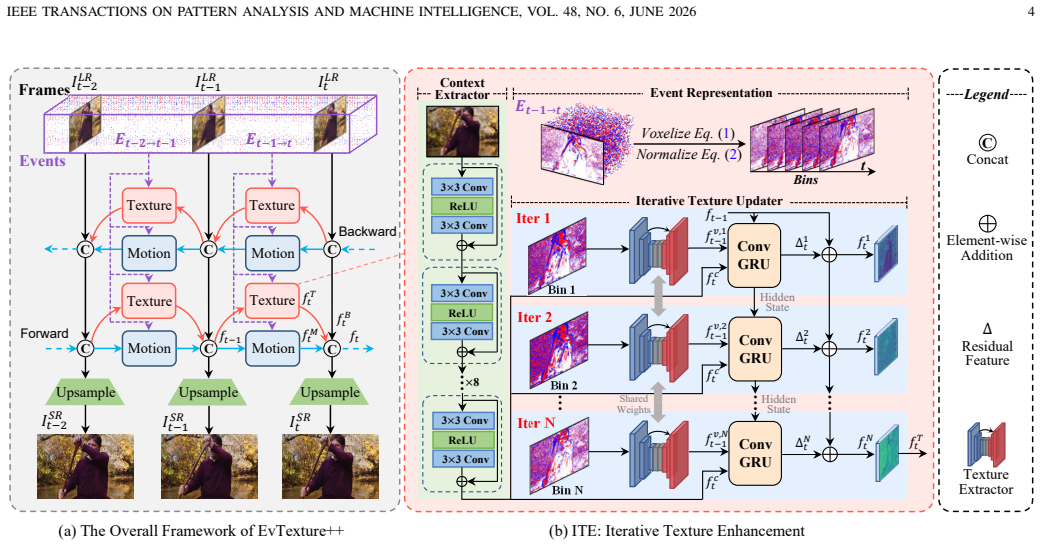
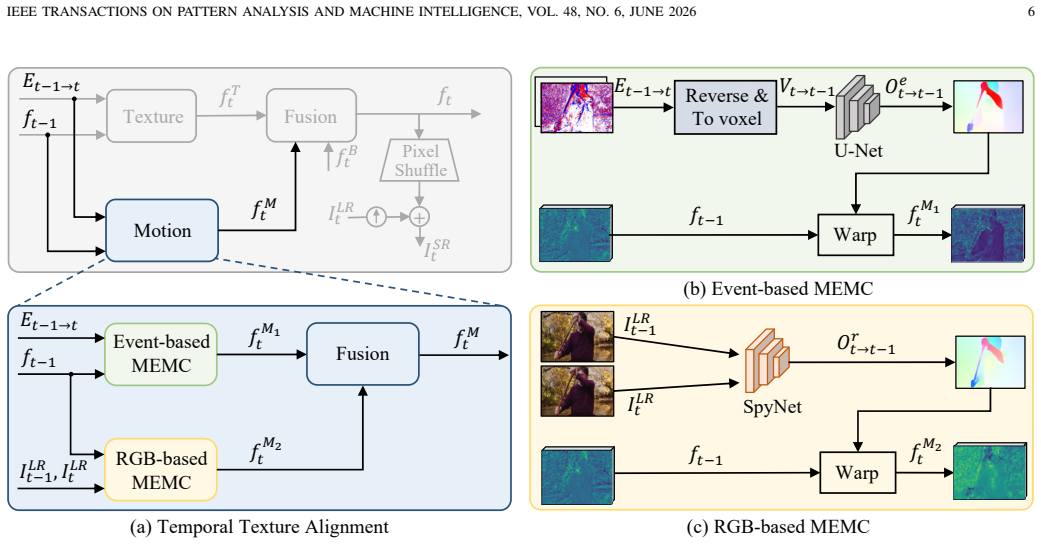
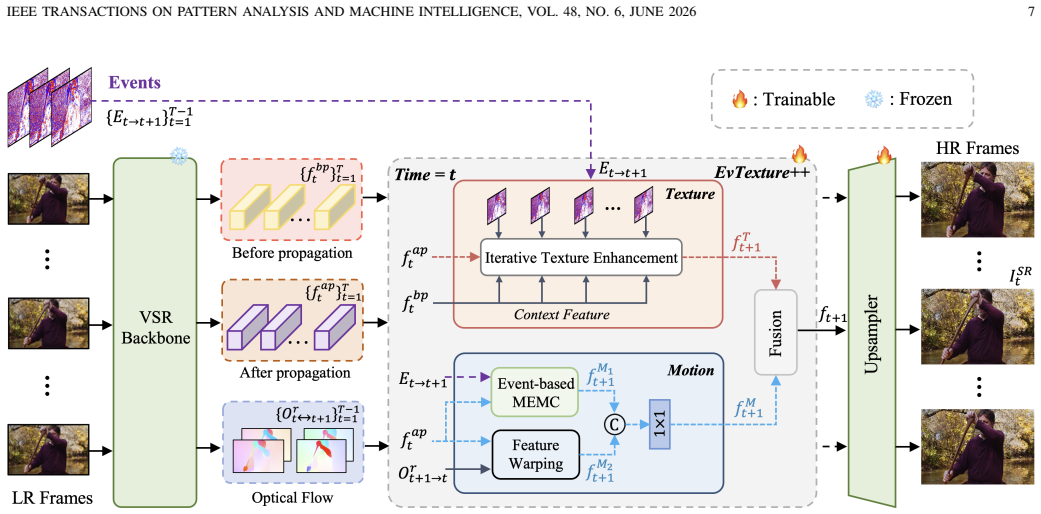
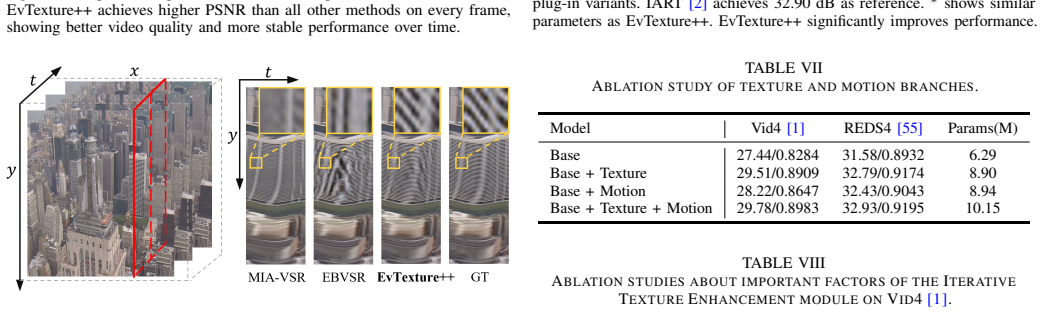
EvTexture++ is the first event-driven framework dedicated to texture enhancement in VSR. It leverages high-frequency spatiotemporal details from events to improve texture recovery. EvTexture++ incorporates a customized texture enhancement branch, along with an iterative texture enhancement module that progressively exploits high-temporal-resolution event information for texture restoration. This enables gradual refinement of texture regions across iterations, yielding more accurate and detailed high-resolution outputs. Besides intra-frame texture recovery, large motions could degrade inter-frame temporal consistency, particularly in texture regions, leading to texture flickering. To mitigate
What carries the argument
The iterative texture enhancement module that progressively exploits high-temporal-resolution event information, paired with the temporal texture alignment module using event-guided texture-aware flow.
If this is right
- Existing VSR models receive consistent performance gains when the framework is added as a plug-in.
- Texture regions in the output videos recover more accurate high-frequency details.
- Inter-frame alignment reduces flickering in moving textured areas.
- The method applies across multiple datasets while remaining flexible for different base models.
Where Pith is reading between the lines
- Event sensors might support detail recovery in related video tasks such as denoising or frame interpolation.
- The iterative refinement pattern could be adapted to other sensor types that provide high-temporal data.
- Real-world tests on raw event streams with varying motion speeds would show whether the alignment holds without extra calibration.
Load-bearing premise
High-frequency spatiotemporal details from event signals can be directly and progressively used for texture restoration and alignment without introducing new artifacts.
What would settle it
Integrating EvTexture++ into a recent VSR model and measuring PSNR on the Vid4 dataset; absence of the reported gain or a drop in performance would falsify the improvement claim.
Figures








read the original abstract
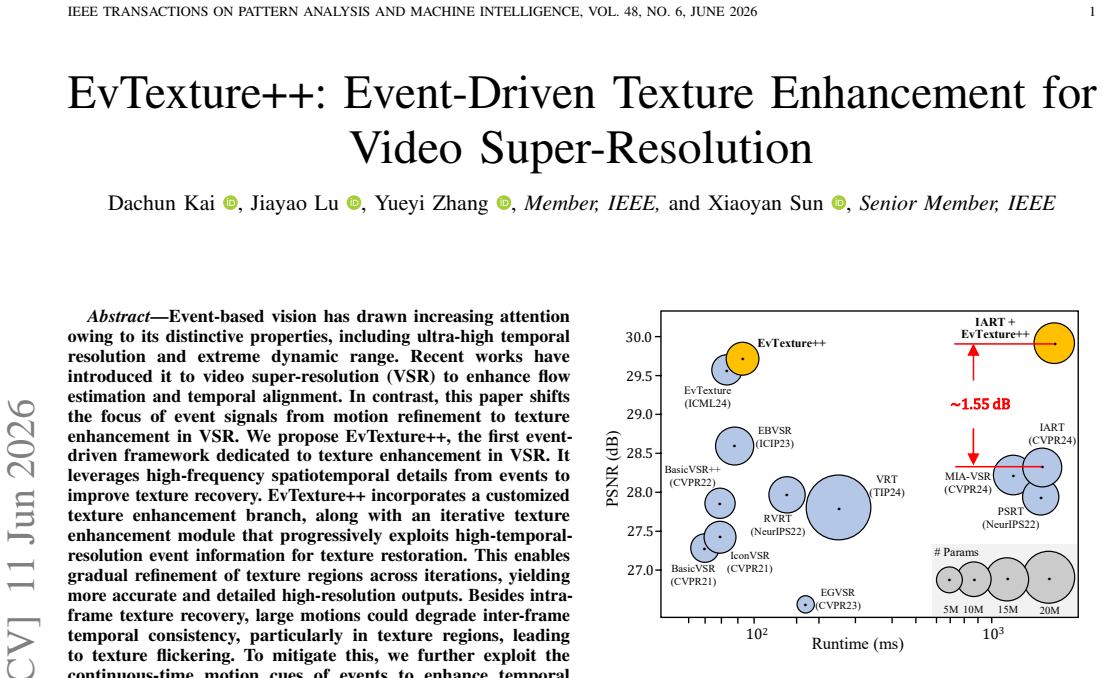
Event-based vision has drawn increasing attention owing to its distinctive properties, including ultra-high temporal resolution and extreme dynamic range. Recent works have introduced it to video super-resolution (VSR) to enhance flow estimation and temporal alignment. In contrast, this paper shifts the focus of event signals from motion refinement to texture enhancement in VSR. We propose EvTexture++, the first event-driven framework dedicated to texture enhancement in VSR. It leverages high-frequency spatiotemporal details from events to improve texture recovery. EvTexture++ incorporates a customized texture enhancement branch, along with an iterative texture enhancement module that progressively exploits high-temporal-resolution event information for texture restoration. This enables gradual refinement of texture regions across iterations, yielding more accurate and detailed high-resolution outputs. Besides intra-frame texture recovery, large motions could degrade inter-frame temporal consistency, particularly in texture regions, leading to texture flickering. To mitigate this, we further exploit the continuous-time motion cues of events to enhance temporal consistency, introducing a temporal texture alignment module that estimates event-guided texture-aware flow for precise inter-frame texture alignment. Moreover, EvTexture++ is designed as a plug-and-play tool to flexibly boost the performance of existing VSR models. Experiments on five datasets demonstrate that EvTexture++ achieves state-of-the-art performance. When integrated into recent VSR models, it yields significant improvements, with gains of up to 1.55 dB in PSNR on the texture-rich Vid4 dataset. Code: https://github.com/DachunKai/EvTexture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvTexture++, the first event-driven framework for texture enhancement in video super-resolution (VSR). It introduces a customized texture enhancement branch, an iterative texture enhancement module that progressively refines textures using high-temporal-resolution event data, and a temporal texture alignment module that uses event-guided texture-aware flow to mitigate texture flickering from large motions. The framework is designed as plug-and-play for integration into existing VSR models. Experiments on five datasets show state-of-the-art performance, with reported PSNR gains of up to 1.55 dB on the texture-rich Vid4 dataset when integrated into recent VSR models. Code is provided at https://github.com/DachunKai/EvTexture.
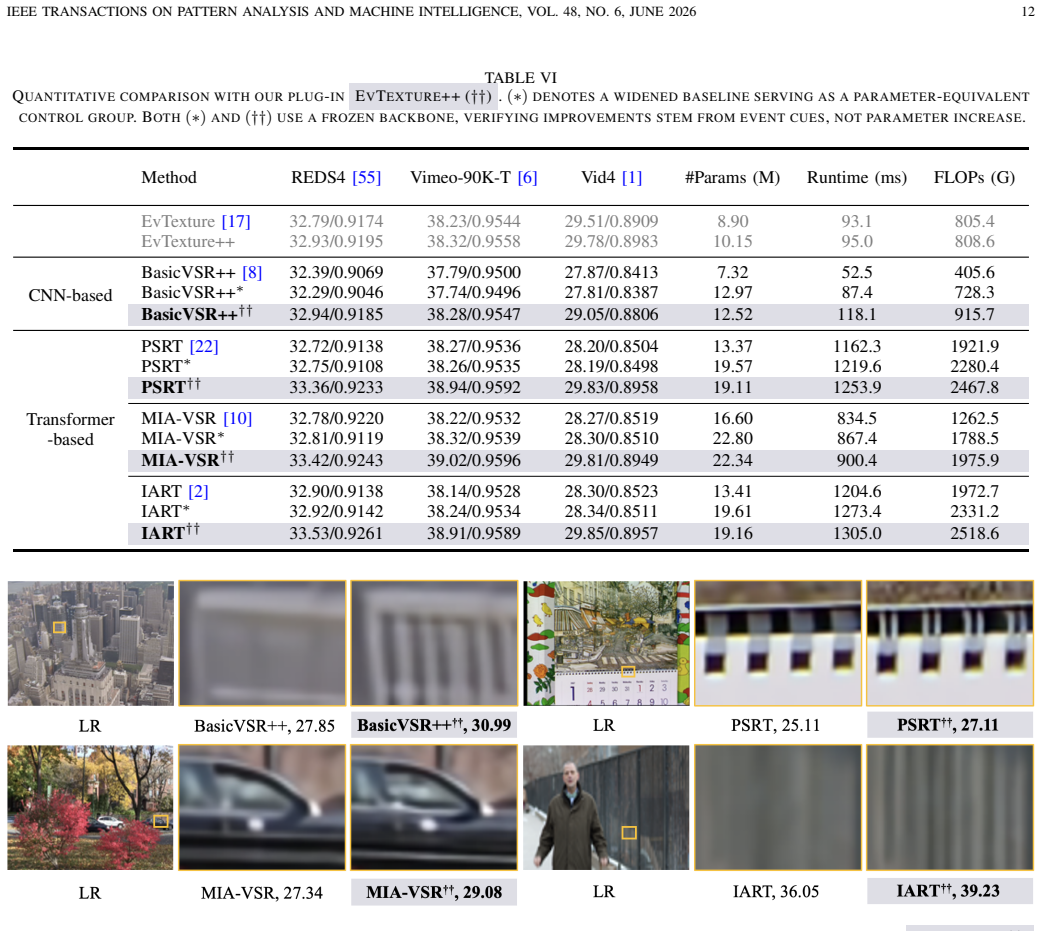
Significance. If the reported gains are supported by the architecture and controls, the work is significant for shifting event-based VSR from motion refinement to texture recovery, exploiting the ultra-high temporal resolution and dynamic range of event cameras for detailed high-resolution outputs and temporal consistency. The plug-and-play design and public code enable reproducibility and easy adoption, which strengthens the potential impact in practical video enhancement applications.
minor comments (3)
- [Abstract] Abstract and §1: The claim that EvTexture++ is 'the first event-driven framework dedicated to texture enhancement in VSR' would benefit from an explicit comparison table or paragraph distinguishing it from prior event-based VSR works focused on flow estimation.
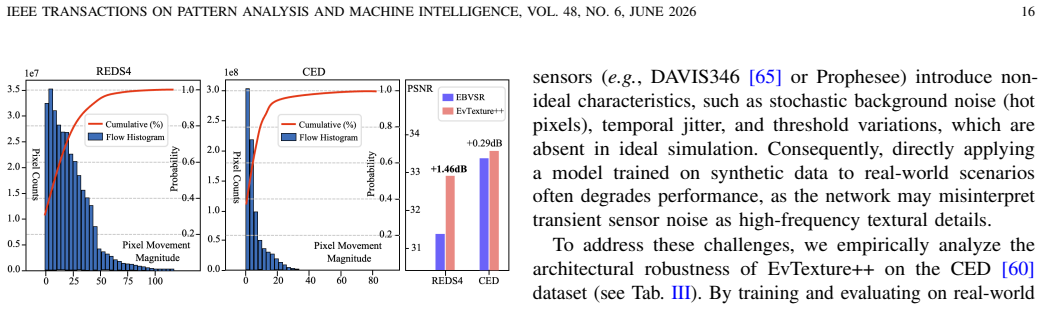
- [Experiments] §4 (Experiments): The reported PSNR gains (e.g., 1.55 dB on Vid4) should include the specific baseline VSR models used for integration and whether event-free ablations of the proposed modules were performed to isolate the contribution of the texture enhancement branch.
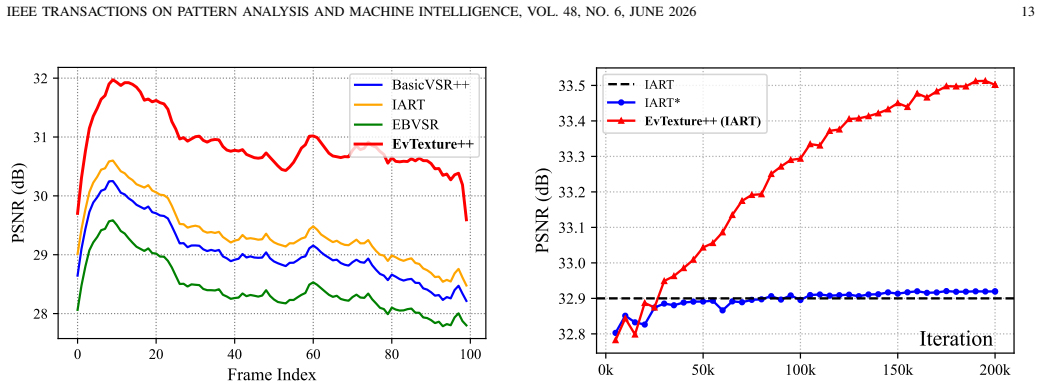
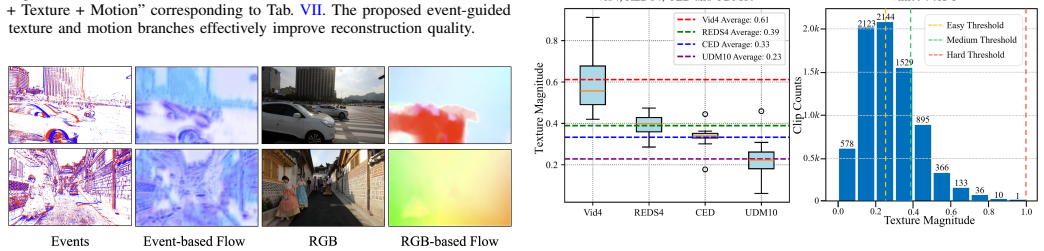
- [Experiments] Figure 3 or equivalent (qualitative results): The visual comparisons would be clearer with zoomed-in insets highlighting texture regions before and after the iterative module and temporal alignment.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of significance, and recommendation of minor revision. The referee's description accurately reflects the paper's focus on shifting event-based VSR toward texture enhancement, the proposed modules, plug-and-play design, and reported gains. No major comments were listed in the report, so we have no specific points requiring response or revision.
Circularity Check
No significant circularity; empirical architecture with reported gains
full rationale
The paper introduces EvTexture++ as a plug-and-play architecture comprising a texture enhancement branch, iterative module, and event-guided flow module. Claims rest on experimental integration into existing VSR models and measured PSNR/SSIM gains across five datasets (up to 1.55 dB on Vid4). No equations, first-principles derivations, or predictions that reduce to fitted inputs or self-citations are present in the provided text. The central results are externally falsifiable via the linked code and dataset benchmarks, making the work self-contained without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On Bayesian adaptive video super resolution,
C. Liu and D. Sun, “On Bayesian adaptive video super resolution,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 2, pp. 346–360, 2013
2013
-
[2]
Enhancing video super-resolution via implicit resampling-based alignment,
K. Xu, Z. Yu, X. Wang, M. B. Mi, and A. Yao, “Enhancing video super-resolution via implicit resampling-based alignment,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2024, pp. 2546–2555
2024
-
[3]
Super- resolution system for 4k-hdtv,
T. Goto, T. Fukuoka, F. Nagashima, S. Hirano, and M. Sakurai, “Super- resolution system for 4k-hdtv,” inProc. IEEE Int. Conf. Pattern Recogn., 2014, pp. 4453–4458
2014
-
[4]
A super-resolution reconstruc- tion algorithm for surveillance images,
L. Zhang, H. Zhang, H. Shen, and P. Li, “A super-resolution reconstruc- tion algorithm for surveillance images,”Signal Processing, vol. 90, no. 3, pp. 848–859, 2010. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 48, NO. 6, JUNE 2026 17
2010
-
[5]
A single frame and multi-frame joint network for 360- degree panorama video super-resolution,
H. Liu, W. Ma, Z. Ruan, C. Fang, F. Shang, Y . Liu, L. Wang, C. Wang, and D. Jiang, “A single frame and multi-frame joint network for 360- degree panorama video super-resolution,”Engineering Applications of Artificial Intelligence, vol. 134, Art. no. 108601, 2024
2024
-
[6]
Video enhancement with task-oriented flow,
T. Xue, B. Chen, J. Wu, D. Wei, and W. T. Freeman, “Video enhancement with task-oriented flow,”Int. J. Comput. Vis., vol. 127, pp. 1106–1125, 2019
2019
-
[7]
BasicVSR: The search for essential components in video super-resolution and beyond,
K. C. Chan, X. Wang, K. Yu, C. Dong, and C. C. Loy, “BasicVSR: The search for essential components in video super-resolution and beyond,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2021, pp. 4947–4956
2021
-
[8]
BasicVSR++: Improving video super-resolution with enhanced propagation and alignment,
K. C. Chan, S. Zhou, X. Xu, and C. C. Loy, “BasicVSR++: Improving video super-resolution with enhanced propagation and alignment,” in Proc. IEEE Conf. Comput. Vis. Pattern Recogn., 2022, pp. 5972–5981
2022
-
[9]
Cycmunet+: Cycle- projected mutual learning for spatial-temporal video super-resolution,
M. Hu, K. Jiang, Z. Wang, X. Bai, and R. Hu, “Cycmunet+: Cycle- projected mutual learning for spatial-temporal video super-resolution,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 11, pp. 13 376– 13 392, 2023
2023
-
[10]
Video super- resolution transformer with masked inter&intra-frame attention,
X. Zhou, L. Zhang, X. Zhao, K. Wang, L. Li, and S. Gu, “Video super- resolution transformer with masked inter&intra-frame attention,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2024, pp. 25 399–25 408
2024
-
[11]
Self-supervised deep blind video super-resolution,
H. Bai and J. Pan, “Self-supervised deep blind video super-resolution,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 7, pp. 4641–4653, 2024
2024
-
[12]
EDVR: Video restoration with enhanced deformable convolutional networks,
X. Wang, K. C. Chan, K. Yu, C. Dong, and C. Change Loy, “EDVR: Video restoration with enhanced deformable convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recogn. Workshop, 2019, pp. 1954–1963
2019
-
[13]
A 128×128 120 db 15 µs latency asynchronous temporal contrast vision sensor,
P. Lichtsteiner, C. Posch, and T. Delbruck, “A 128×128 120 db 15 µs latency asynchronous temporal contrast vision sensor,”IEEE journal of solid-state circuits, vol. 43, no. 2, pp. 566–576, 2008
2008
-
[14]
Turning frequency to resolution: Video super-resolution via event cameras,
Y . Jing, Y . Yang, X. Wang, M. Song, and D. Tao, “Turning frequency to resolution: Video super-resolution via event cameras,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2021, pp. 7772–7781
2021
-
[15]
Learning Spatial- Temporal Implicit Neural Representations for Event-Guided Video Super- Resolution,
Y . Lu, Z. Wang, M. Liu, H. Wang, and L. Wang, “Learning Spatial- Temporal Implicit Neural Representations for Event-Guided Video Super- Resolution,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2023, pp. 1557–1567
2023
-
[16]
Video Super-Resolution Via Event-Driven Temporal Alignment,
D. Kai, Y . Zhang, and X. Sun, “Video Super-Resolution Via Event-Driven Temporal Alignment,” inProc. IEEE Int. Conf. Image Process.IEEE, 2023, pp. 2950–2954
2023
-
[17]
EvTexture: Event-driven Texture Enhancement for Video Super-Resolution,
D. Kai, J. Lu, Y . Zhang, and X. Sun, “EvTexture: Event-driven Texture Enhancement for Video Super-Resolution,” inInt. Conf. Mach. Learn., vol. 235. PMLR, 2024, pp. 22 817–22 839
2024
-
[18]
Event- based vision: A survey,
G. Gallego, T. Delbr ¨uck, G. Orchard, C. Bartolozzi, B. Taba, A. Censi, S. Leutenegger, A. J. Davison, J. Conradt, K. Daniilidiset al., “Event- based vision: A survey,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 1, pp. 154–180, 2020
2020
-
[19]
TDPN: Texture and detail-preserving network for single image super-resolution,
Q. Cai, J. Li, H. Li, Y .-H. Yang, F. Wu, and D. Zhang, “TDPN: Texture and detail-preserving network for single image super-resolution,”IEEE Trans. Image Process., vol. 31, pp. 2375–2389, 2022
2022
-
[20]
CTE-Net: Contextual Texture Enhancement Network for Image Super-Resolution,
D. Liu, X. Wang, R. Han, N. Bai, J. Hou, and S. Pang, “CTE-Net: Contextual Texture Enhancement Network for Image Super-Resolution,” IEEE Trans. Multimedia, 2024
2024
-
[21]
Egovsr: Toward high- quality egocentric video super-resolution,
Y . Chi, J. Gu, J. Zhang, W. Yang, and Y . Tian, “Egovsr: Toward high- quality egocentric video super-resolution,”IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 11, pp. 11 838–11 850, 2024
2024
-
[22]
Rethinking alignment in video super-resolution transformers,
S. Shi, J. Gu, L. Xie, X. Wang, Y . Yang, and C. Dong, “Rethinking alignment in video super-resolution transformers,”Proc. Adv. Neural Inf. Process. Syst., vol. 35, pp. 36 081–36 093, 2022
2022
-
[23]
Unifying low- resolution and high-resolution alignment by event cameras for space-time video super-resolution,
H. Cho, J.-Y . Kang, T. Kim, Y . Jeong, and K.-J. Yoon, “Unifying low- resolution and high-resolution alignment by event cameras for space-time video super-resolution,” inProc. Winter Conf. Appl. Comput. Vis.IEEE, 2025, pp. 9509–9520
2025
-
[24]
VRT: A Video Restoration Transformer,
J. Liang, J. Cao, Y . Fan, K. Zhang, R. Ranjan, Y . Li, R. Timofte, and L. Van Gool, “VRT: A Video Restoration Transformer,”IEEE Trans. Image Process., vol. 33, pp. 2171–2182, 2024
2024
-
[25]
Learning degradation- robust spatiotemporal frequency-transformer for video super-resolution,
Z. Qiu, H. Yang, J. Fu, D. Liu, C. Xu, and D. Fu, “Learning degradation- robust spatiotemporal frequency-transformer for video super-resolution,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 12, pp. 14 888– 14 904, 2023
2023
-
[26]
ESRGAN: Enhanced super-resolution generative adversarial networks,
X. Wang, K. Yu, S. Wu, J. Gu, Y . Liu, C. Dong, Y . Qiao, and C. Change Loy, “ESRGAN: Enhanced super-resolution generative adversarial networks,” inProc. Eur. Conf. Comput. Vis. Workshop, 2018, pp. 63–79
2018
-
[27]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Proc. Adv. Neural Inf. Process. Syst., vol. 30, pp. 5998–6008, 2017
2017
-
[28]
SwinIR: Image restoration using swin transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “SwinIR: Image restoration using swin transformer,” inProc. IEEE Int. Conf. Comput. Vis. Workshop, 2021, pp. 1833–1844
2021
-
[29]
RAFT: Recurrent All-pairs Field Transforms for optical flow,
Z. Teed and J. Deng, “RAFT: Recurrent All-pairs Field Transforms for optical flow,” inProc. Eur. Conf. Comput. Vis., 2020, pp. 402–419
2020
-
[30]
Deformable convolutional networks,
J. Dai, H. Qi, Y . Xiong, Y . Li, G. Zhang, H. Hu, and Y . Wei, “Deformable convolutional networks,” inProc. IEEE Int. Conf. Comput. Vis., 2017, pp. 764–773
2017
-
[31]
Secrets of event-based optical flow, depth and ego-motion estimation by contrast maximization,
S. Shiba, Y . Klose, Y . Aoki, and G. Gallego, “Secrets of event-based optical flow, depth and ego-motion estimation by contrast maximization,” IEEE Trans. Pattern Anal. Mach. Intell., 2024
2024
-
[32]
Superfast: 200× video frame interpolation via event camera,
Y . Gao, S. Li, Y . Li, Y . Guo, and Q. Dai, “Superfast: 200× video frame interpolation via event camera,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 6, pp. 7764–7780, 2022
2022
-
[33]
Ner-net+: Seeing motion at nighttime with an event camera,
H. Liu, J. Xu, S. Peng, Y . Chang, H. Zhou, Y . Duan, L. Zhu, Y . Tian, and L. Yan, “Ner-net+: Seeing motion at nighttime with an event camera,” IEEE Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[34]
Hybrid high dynamic range imaging fusing neuromorphic and conventional images,
J. Han, Y . Yang, P. Duan, C. Zhou, L. Ma, C. Xu, T. Huang, I. Sato, and B. Shi, “Hybrid high dynamic range imaging fusing neuromorphic and conventional images,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 7, pp. 8553–8565, 2023
2023
-
[35]
A unified framework for event-based frame interpolation with ad-hoc deblurring in the wild,
L. Sun, D. Gehrig, C. Sakaridis, M. Gehrig, J. Liang, P. Sun, Z. Xu, K. Wang, L. Van Gool, and D. Scaramuzza, “A unified framework for event-based frame interpolation with ad-hoc deblurring in the wild,”IEEE Trans. Pattern Anal. Mach. Intell., 2024
2024
-
[36]
Eventaid: Benchmarking event-aided image/video enhancement algorithms with real-captured hybrid dataset,
P. Duan, B. Li, Y . Yang, H. Lou, M. Teng, X. Zhou, Y . Ma, and B. Shi, “Eventaid: Benchmarking event-aided image/video enhancement algorithms with real-captured hybrid dataset,”IEEE Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[37]
Event- adapted video super-resolution,
Z. Xiao, D. Kai, Y . Zhang, Z.-J. Zha, X. Sun, and Z. Xiong, “Event- adapted video super-resolution,” inProc. Eur. Conf. Comput. Vis., 2024, pp. 217–235
2024
-
[38]
Event- enhanced blurry video super-resolution,
D. Kai, Y . Zhang, J. Wang, Z. Xiao, Z. Xiong, and X. Sun, “Event- enhanced blurry video super-resolution,” inProc. AAAI Conf. Artificial Intell., vol. 39, no. 4, 2025, pp. 4175–4183
2025
-
[39]
Event-based video super-resolution via state space models,
Z. Xiao and X. Wang, “Event-based video super-resolution via state space models,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., June 2025, pp. 12 564–12 574
2025
-
[40]
Seeing the unseen: Zooming in the dark with event cameras,
D. Kai, Z. Xiao, H. Zhu, J. Wang, Y . Zhang, and X. Sun, “Seeing the unseen: Zooming in the dark with event cameras,” inProc. AAAI Conf. Artificial Intell., 2026
2026
-
[41]
Vision mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,” inInt. Conf. Mach. Learn., vol. 235. PMLR, 2024, pp. 62 429–62 442
2024
-
[42]
Evstvsr: Event guided space-time video super-resolution,
H. Yan, Z. Lu, Z. Chen, D. Ma, H. Tang, Q. Zheng, and G. Pan, “Evstvsr: Event guided space-time video super-resolution,” inProc. AAAI Conf. Artificial Intell., vol. 39, no. 9, 2025, pp. 9085–9093
2025
-
[43]
Local texture pattern estimation for image detail super-resolution,
F. Fan, Y . Zhao, Y . Chen, N. Li, W. Jia, and R. Wang, “Local texture pattern estimation for image detail super-resolution,”IEEE Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[44]
Unsupervised event- based learning of optical flow, depth, and egomotion,
A. Z. Zhu, L. Yuan, K. Chaney, and K. Daniilidis, “Unsupervised event- based learning of optical flow, depth, and egomotion,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2019, pp. 989–997
2019
-
[45]
Learning dense and continuous optical flow from an event camera,
Z. Wan, Y . Dai, and Y . Mao, “Learning dense and continuous optical flow from an event camera,”IEEE Trans. Image Process., vol. 31, pp. 7237–7251, 2022
2022
-
[46]
EventGAN: Leveraging large scale image datasets for event cameras,
A. Z. Zhu, Z. Wang, K. Khant, and K. Daniilidis, “EventGAN: Leveraging large scale image datasets for event cameras,” inProc. IEEE Int. Conf. Comput. Photography. IEEE, 2021, pp. 1–11
2021
-
[47]
Real-time single image and video super- resolution using an efficient sub-pixel convolutional neural network,
W. Shi, J. Caballero, F. Husz ´ar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang, “Real-time single image and video super- resolution using an efficient sub-pixel convolutional neural network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recogn., 2016, pp. 1874–1883
2016
-
[48]
U-Net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” inProc. Int. Conf. Med. Image Comput. Comput. Assist. Interv., 2015, pp. 234–241
2015
-
[49]
Super SloMo: High Quality Estimation of Multiple Intermedi- ate Frames for Video Interpolation,
H. Jiang, D. Sun, V . Jampani, M.-H. Yang, E. Learned-Miller, and J. Kautz, “Super SloMo: High Quality Estimation of Multiple Intermedi- ate Frames for Video Interpolation,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2018, pp. 9000–9008
2018
-
[50]
Optical flow estimation using a spatial pyramid network,
A. Ranjan and M. J. Black, “Optical flow estimation using a spatial pyramid network,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2017, pp. 4161–4170
2017
-
[51]
Delving deeper into convolutional networks for learning video representations,
N. Ballas, L. Yao, C. Pal, and A. Courville, “Delving deeper into convolutional networks for learning video representations,” inProc. Int. Conf. Learn. Repr., 2016, pp. 1–12. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 48, NO. 6, JUNE 2026 18
2016
-
[52]
Dense continuous-time optical flow from event cameras,
M. Gehrig, M. Muglikar, and D. Scaramuzza, “Dense continuous-time optical flow from event cameras,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 7, pp. 4736–4746, 2024
2024
-
[53]
Time lens: Event-based video frame interpolation,
S. Tulyakov, D. Gehrig, S. Georgoulis, J. Erbach, M. Gehrig, Y . Li, and D. Scaramuzza, “Time lens: Event-based video frame interpolation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recogn., 2021, pp. 16 155–16 164
2021
-
[54]
Spatial transformer networks,
M. Jaderberg, K. Simonyan, A. Zissermanet al., “Spatial transformer networks,”Proc. Adv. Neural Inf. Process. Syst., vol. 28, pp. 2017–2025, 2015
2017
-
[55]
Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study,
S. Nah, S. Baik, S. Hong, G. Moon, S. Son, R. Timofte, and K. Mu Lee, “Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn. Workshop, 2019, pp. 1996–2005
2019
-
[56]
Revisiting temporal alignment for video restoration,
K. Zhou, W. Li, L. Lu, X. Han, and J. Lu, “Revisiting temporal alignment for video restoration,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2022, pp. 6053–6062
2022
-
[57]
Recurrent video restoration transformer with guided deformable attention,
J. Liang, Y . Fan, X. Xiang, R. Ranjan, E. Ilg, S. Green, J. Cao, K. Zhang, R. Timofte, and L. V . Gool, “Recurrent video restoration transformer with guided deformable attention,”Proc. Adv. Neural Inf. Process. Syst., vol. 35, pp. 378–393, 2022
2022
-
[58]
Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations,
P. Yi, Z. Wang, K. Jiang, J. Jiang, and J. Ma, “Progressive fusion video super-resolution network via exploiting non-local spatio-temporal correlations,” inProc. IEEE Int. Conf. Comput. Vis., 2019, pp. 3106–3115
2019
-
[59]
ESIM: an open event camera simulator,
H. Rebecq, D. Gehrig, and D. Scaramuzza, “ESIM: an open event camera simulator,” inConference on Robot Learning (CORL). PMLR, 2018, pp. 969–982
2018
-
[60]
CED: Color event camera dataset,
C. Scheerlinck, H. Rebecq, T. Stoffregen, N. Barnes, R. Mahony, and D. Scaramuzza, “CED: Color event camera dataset,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn. Workshop, 2019, pp. 1684–1693
2019
-
[61]
Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation,
Y . Jo, S. W. Oh, J. Kang, and S. J. Kim, “Deep video super-resolution network using dynamic upsampling filters without explicit motion compensation,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2018, pp. 3224–3232
2018
-
[62]
Deep video super-resolution using HR optical flow estimation,
L. Wang, Y . Guo, L. Liu, Z. Lin, X. Deng, and W. An, “Deep video super-resolution using HR optical flow estimation,”IEEE Trans. Image Process., vol. 29, pp. 4323–4336, 2020
2020
-
[63]
TDAN: Temporally-deformable alignment network for video super-resolution,
Y . Tian, Y . Zhang, Y . Fu, and C. Xu, “TDAN: Temporally-deformable alignment network for video super-resolution,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2020, pp. 3360–3369
2020
-
[64]
Recurrent back-projection network for video super-resolution,
M. Haris, G. Shakhnarovich, and N. Ukita, “Recurrent back-projection network for video super-resolution,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2019, pp. 3897–3906
2019
-
[65]
Real-time, high-speed video decompression using a frame-and event-based DA VIS sensor,
C. Brandli, L. Muller, and T. Delbruck, “Real-time, high-speed video decompression using a frame-and event-based DA VIS sensor,” inIEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2014, pp. 686–689
2014
-
[66]
Deep laplacian pyramid networks for fast and accurate super-resolution,
W.-S. Lai, J.-B. Huang, N. Ahuja, and M.-H. Yang, “Deep laplacian pyramid networks for fast and accurate super-resolution,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2017, pp. 624–632
2017
-
[67]
Adam: A Method for Stochastic Optimization,
D. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” inProc. Int. Conf. Learn. Repr., 2015, pp. 1–15
2015
-
[68]
SGDR: stochastic gradient descent with warm restarts,
I. Loshchilov and F. Hutter, “SGDR: stochastic gradient descent with warm restarts,” inProc. Int. Conf. Learn. Repr., 2017, pp. 1–16
2017
-
[69]
The perception-distortion tradeoff,
Y . Blau and T. Michaeli, “The perception-distortion tradeoff,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2018, pp. 6228–6237
2018
-
[70]
Learning temporal coherence via self-supervision for gan-based video generation,
M. Chu, Y . Xie, J. Mayer, L. Leal-Taix ´e, and N. Thuerey, “Learning temporal coherence via self-supervision for gan-based video generation,” ACM Transactions on Graphics (TOG), vol. 39, no. 4, Art. no. 75, 2020
2020
-
[71]
All at once: Temporally adaptive multi-frame interpolation with advanced motion modeling,
Z. Chi, R. Mohammadi Nasiri, Z. Liu, J. Lu, J. Tang, and K. N. Plataniotis, “All at once: Temporally adaptive multi-frame interpolation with advanced motion modeling,” inProc. Eur. Conf. Comput. Vis., 2020, pp. 107–123
2020
-
[72]
TMP: Temporal Motion Propagation for Online Video Super-Resolution,
Z. Zhang, R. Li, S. Guo, Y . Cao, and L. Zhang, “TMP: Temporal Motion Propagation for Online Video Super-Resolution,”IEEE Trans. Image Process., 2024
2024
-
[73]
Learning trajectory-aware transformer for video super-resolution,
C. Liu, H. Yang, J. Fu, and X. Qian, “Learning trajectory-aware transformer for video super-resolution,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2022, pp. 5687–5696
2022
-
[74]
Evenhancer: Empowering effectiveness, efficiency and generalizability for continuous space-time video super-resolution with events,
S. Wei, F. Li, S. Tang, Y . Zhao, and H. Bai, “Evenhancer: Empowering effectiveness, efficiency and generalizability for continuous space-time video super-resolution with events,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2025, pp. 17 755–17 766
2025
-
[75]
Motion-guided latent diffusion for temporally consistent real-world video super-resolution,
X. Yang, C. He, J. Ma, and L. Zhang, “Motion-guided latent diffusion for temporally consistent real-world video super-resolution,” inProc. Eur. Conf. Comput. Vis., 2024, pp. 224–242
2024
-
[76]
Seedvr: Seeding infinity in diffusion transformer towards generic video restoration,
J. Wang, Z. Lin, M. Wei, Y . Zhao, C. Yang, C. C. Loy, and L. Jiang, “Seedvr: Seeding infinity in diffusion transformer towards generic video restoration,” inProc. IEEE Conf. Comput. Vis. Pattern Recogn., 2025, pp. 2161–2172. Dachun Kaireceived the B.S. degree from Hefei University of Technology (HFUT), Hefei, China, in
2025
-
[77]
degree with the University of Science and Technology of China (USTC), Hefei, China
He is currently pursuing the Ph.D. degree with the University of Science and Technology of China (USTC), Hefei, China. His research interests include computational photography, image and video processing, and deep learning. Jiayao Lureceived the B.S. degree from University of Science and Technology of China (USTC), Hefei, China, in 2018. He is currently p...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.