Distribution-Agnostic Robust Trajectory Optimization via Chance-Constrained Reinforcement Learning
Pith reviewed 2026-06-27 05:40 UTC · model grok-4.3
The pith
Chance-constrained reinforcement learning robustifies nominal spacecraft trajectories using only samples of uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
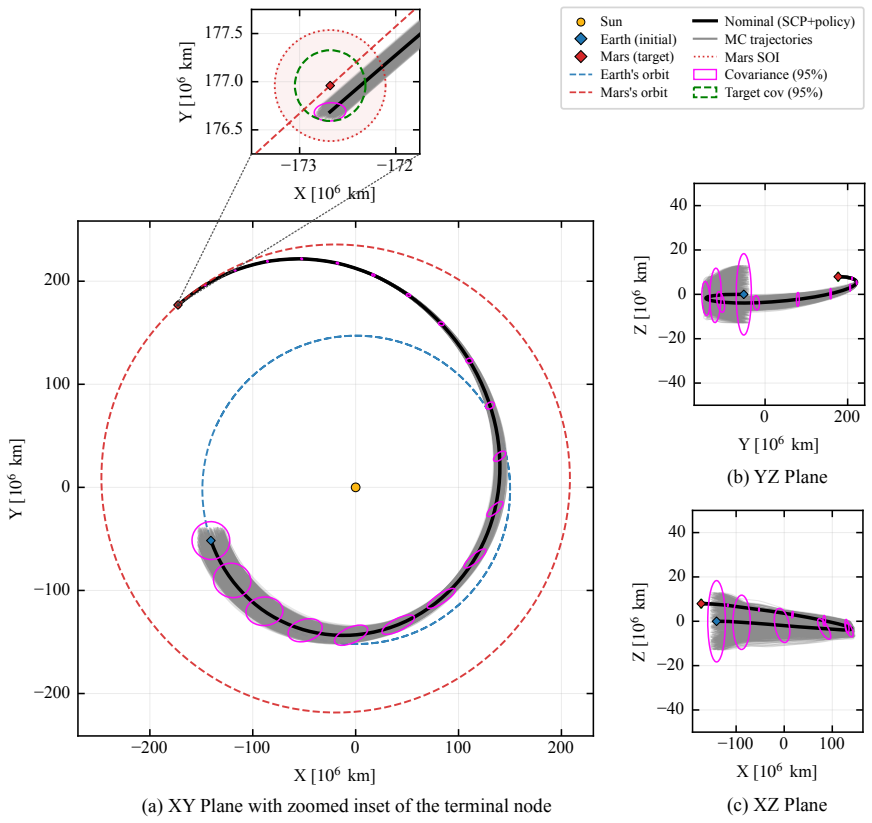
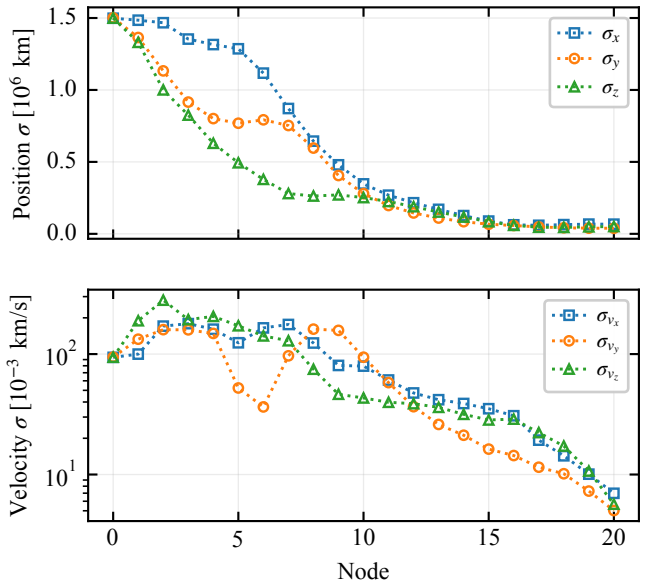
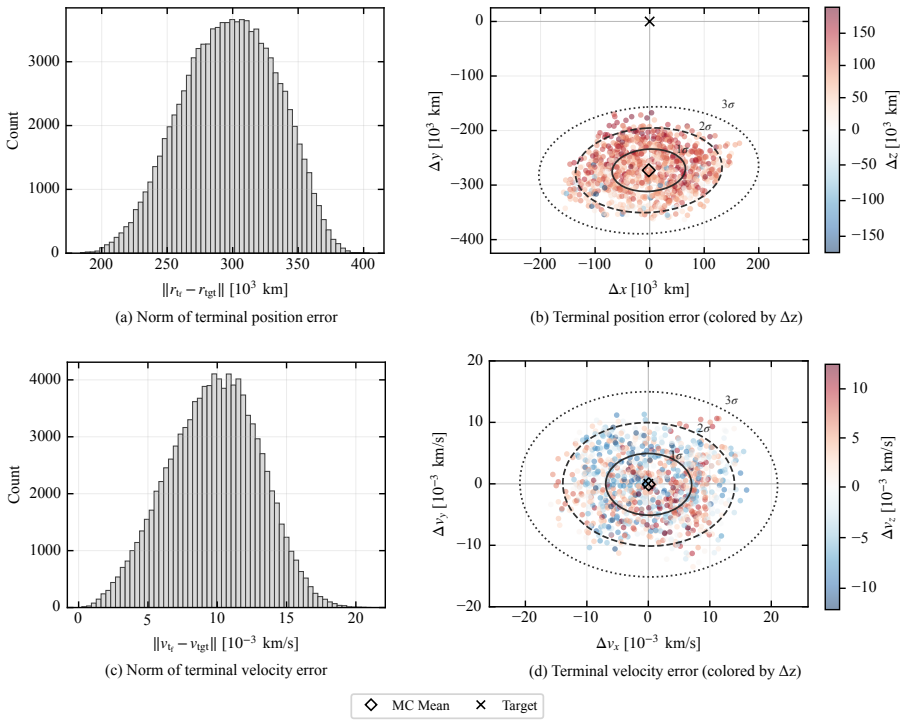
By combining an offline nominal trajectory with a learned affine closed-loop correction law that includes feedforward adjustments and time-varying feedback gains, and by enforcing probabilistic feasibility through empirical upper-tail quantiles from rollouts together with covariance penalties on terminal dispersion, the framework achieves distribution-agnostic robust trajectory optimization that stays competitive in upper-tail fuel cost and transfers without redesign to materially different problems such as multi-impulse transfers and continuous-thrust landings.
What carries the argument
The structured affine closed-loop correction law (feedforward adjustment plus time-varying feedback gains) that is learned by reinforcement learning and whose probabilistic feasibility is enforced via rollout-based upper-tail quantiles.
If this is right
- Upper-tail fuel cost remains competitive with a recent robust optimization reference under Gaussian uncertainty.
- Probabilistic feasibility is preserved when the same policy is tested under bounded uniform uncertainty.
- The policy also maintains feasibility under process disturbances that were never seen during training.
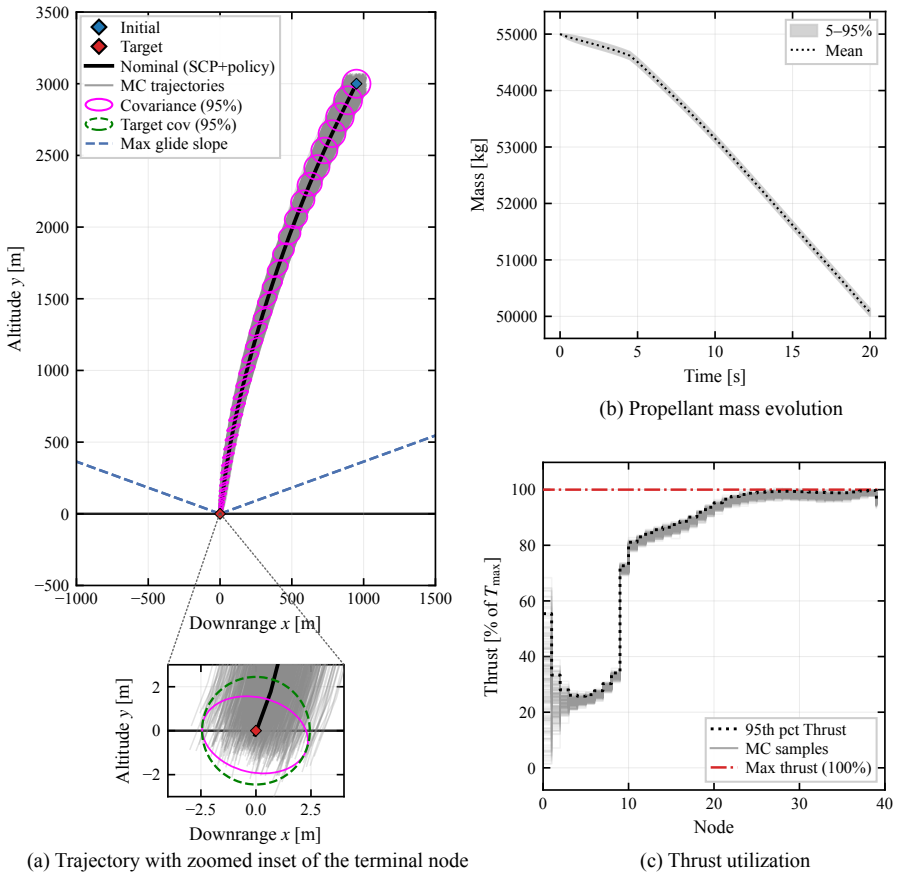
- The identical robustification structure applies to a short-horizon continuous-thrust landing problem with drag, mass depletion, and glide-slope constraints.
Where Pith is reading between the lines
- The sample-only requirement would let mission planners substitute real flight telemetry directly for synthetic noise models.
- The same scaffold could be tested on non-spacecraft problems such as autonomous vehicle path planning where uncertainty distributions are likewise unknown.
- If the affine correction form proves insufficient for strongly nonlinear uncertainty propagation, the framework would need a richer policy class while keeping the quantile-based chance-constraint mechanism.
Load-bearing premise
Uncertainties can be represented solely through samples of initial conditions and process noise that the method is allowed to draw.
What would settle it
A set of Monte Carlo rollouts under a new uncertainty distribution, not used in training, in which the empirical fraction of trajectories violating the chance constraints exceeds the allowed probability level.
Figures
read the original abstract
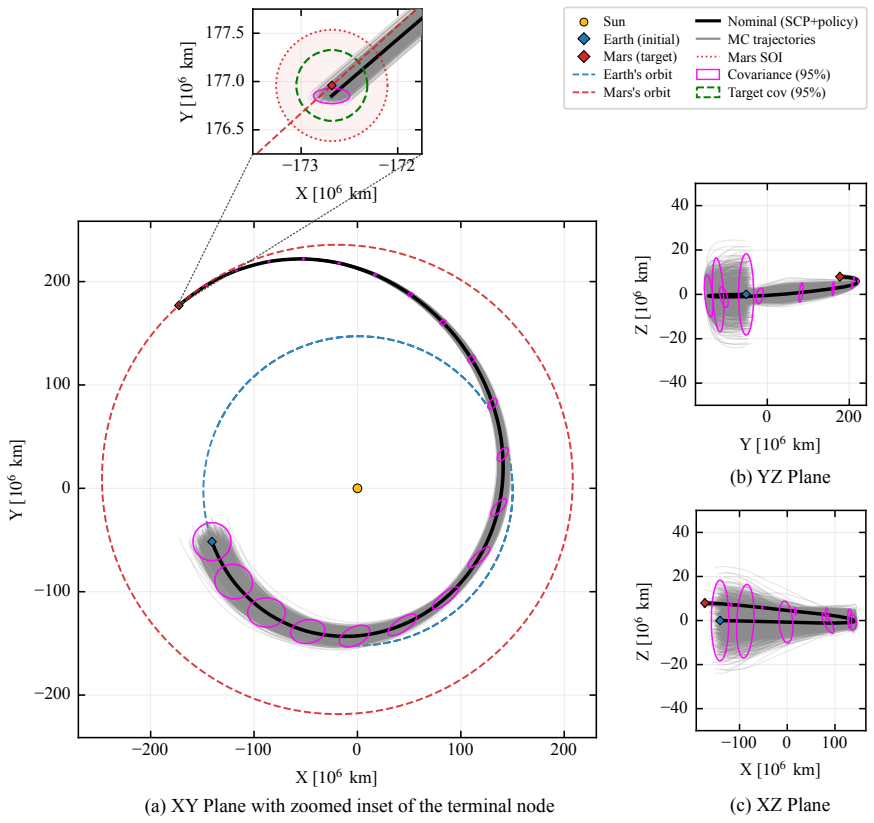
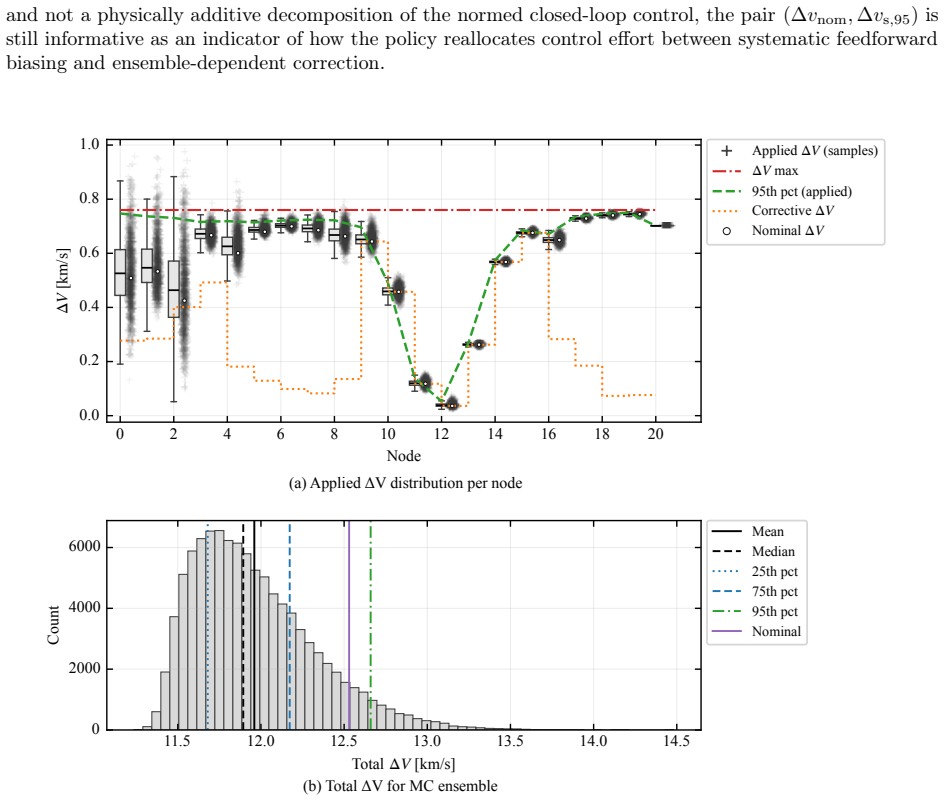
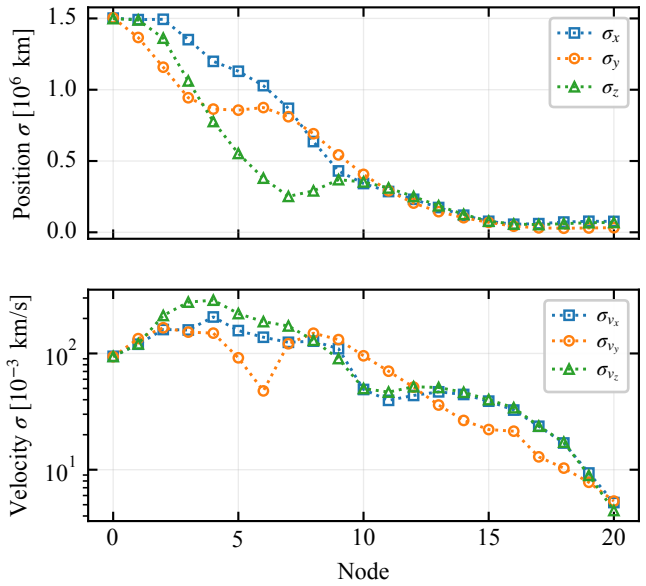
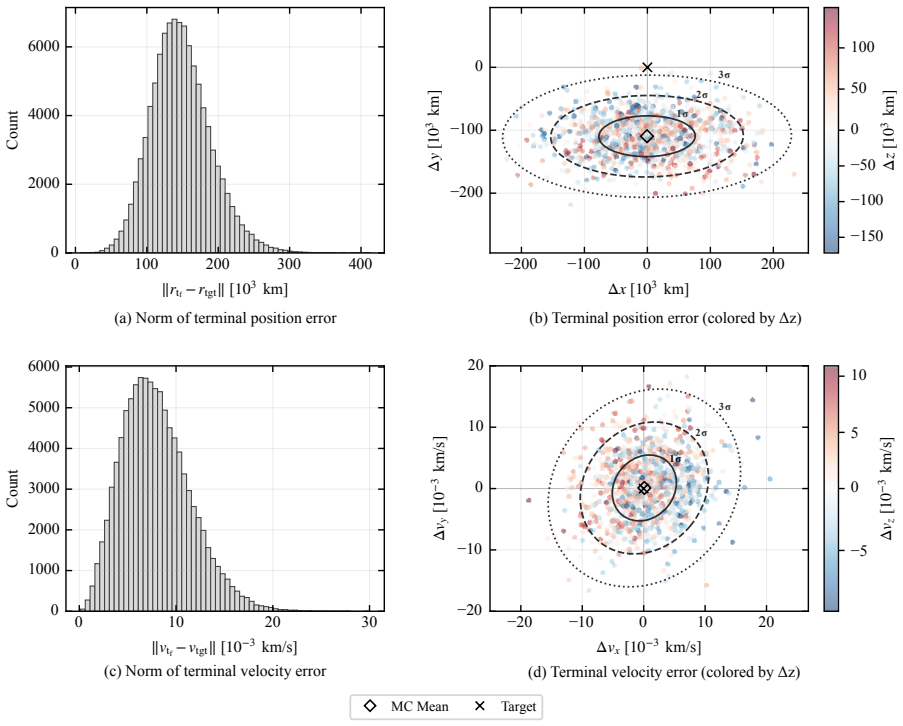
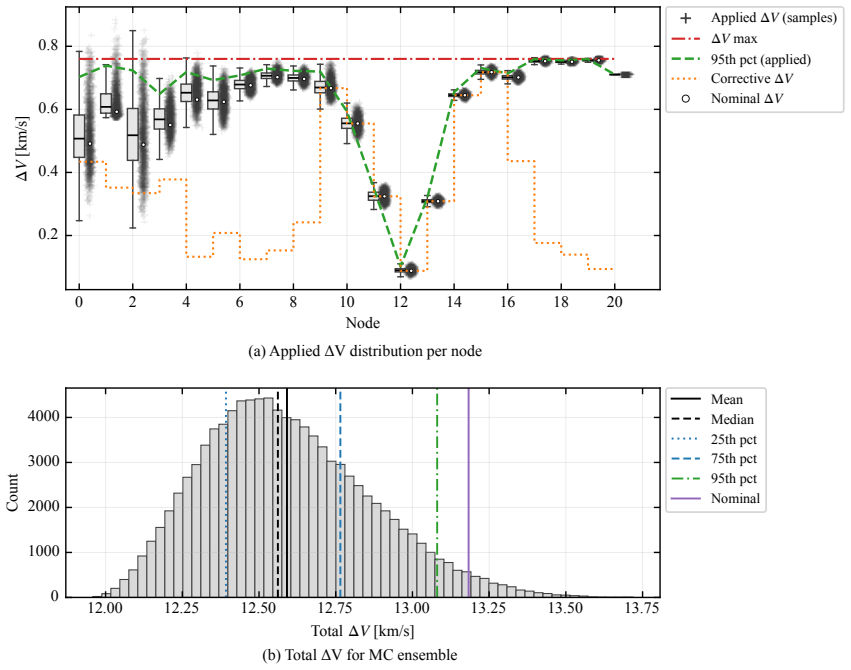
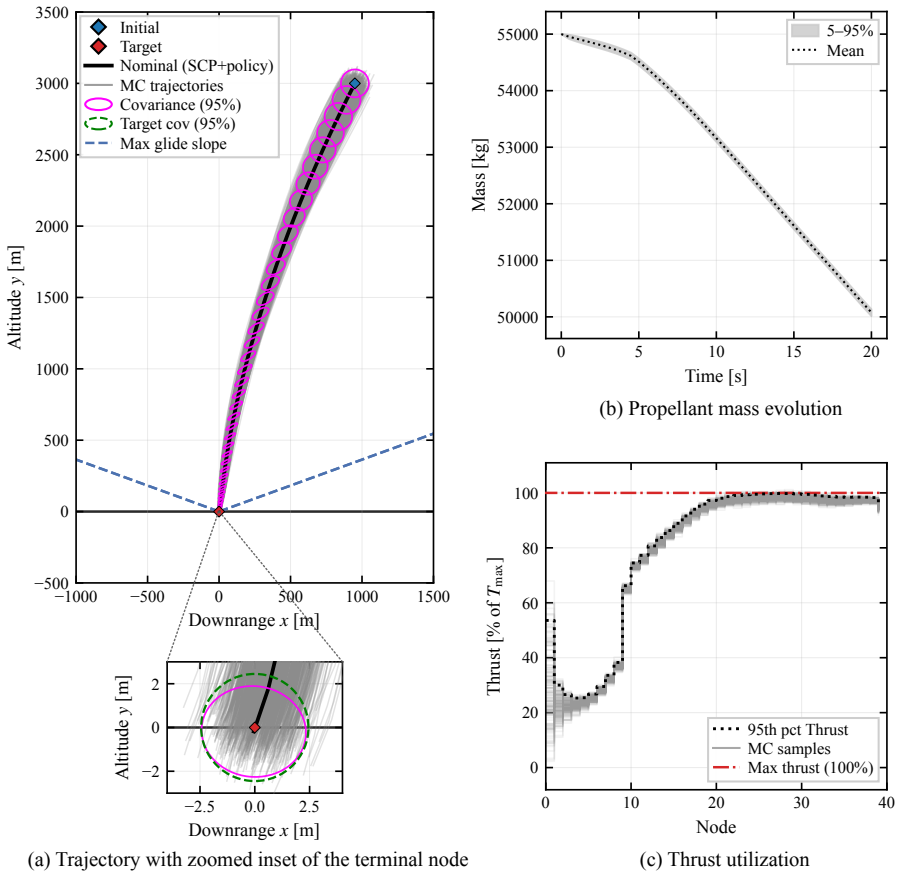
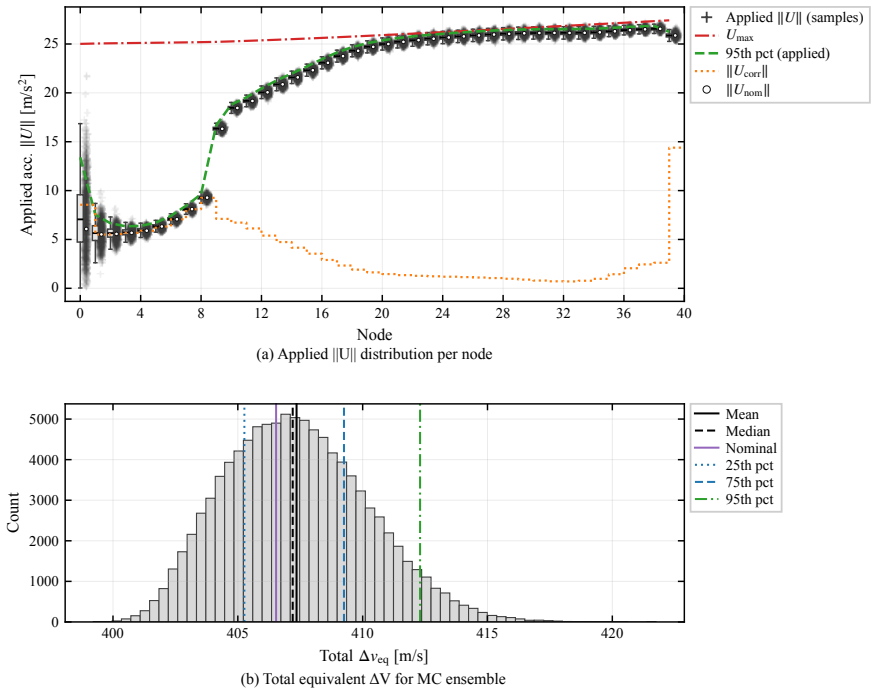
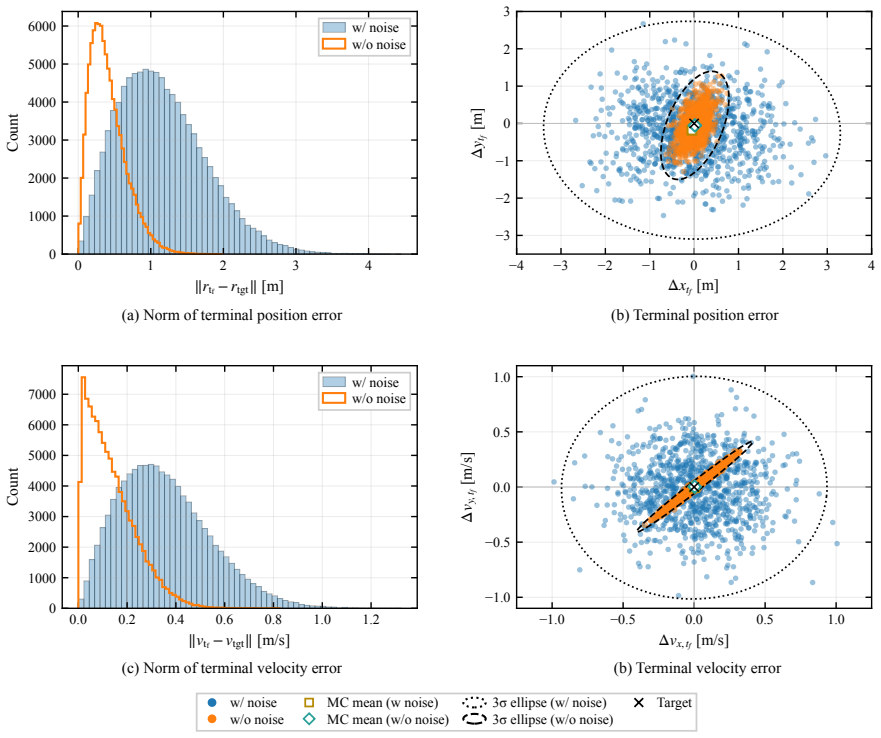
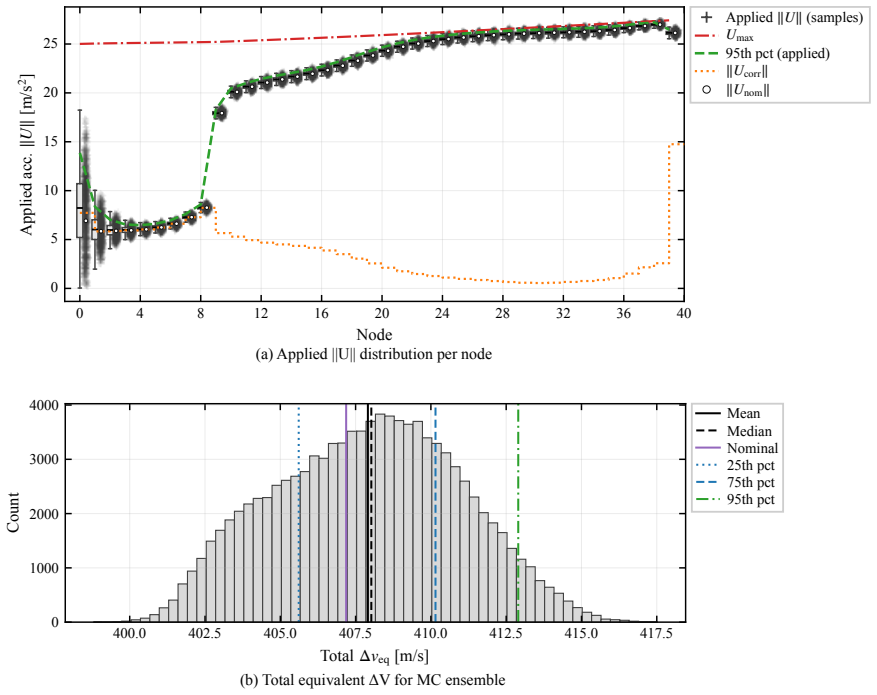
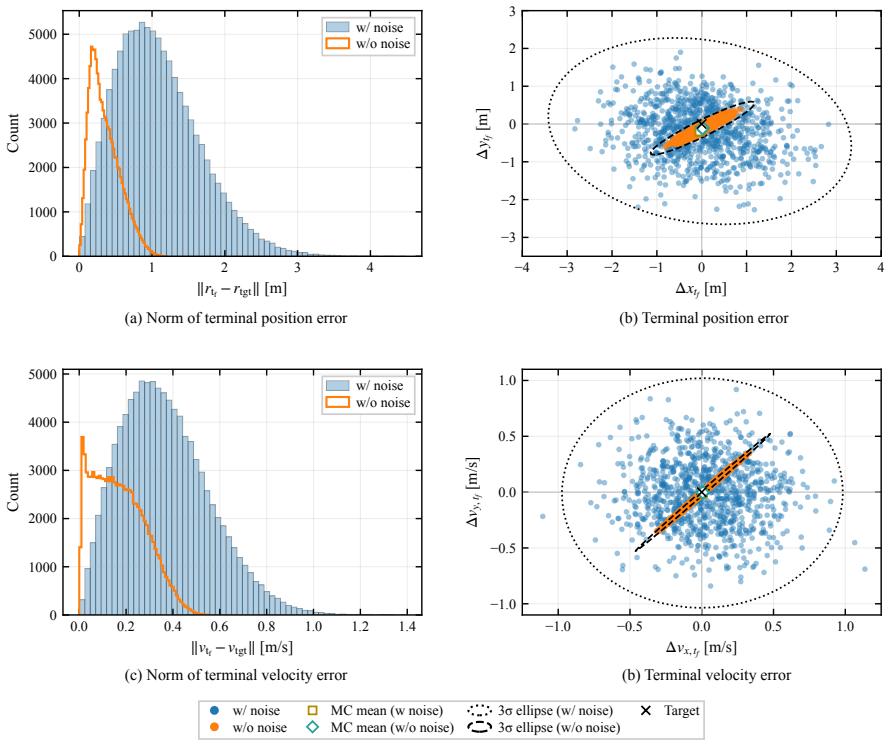
This paper presents a distribution-agnostic robust trajectory-optimization framework based on chance-constrained reinforcement learning. The uncertainty is represented here through initial conditions and process noise, with the only requirement being that it can be sampled. A deterministic nominal trajectory is first computed offline, and reinforcement learning is then used only to robustify that baseline through a structured affine closed-loop correction law comprising a feedforward control adjustment and time-varying feedback gains. Probabilistic feasibility is enforced empirically through rollout-based upper-tail quantiles, while terminal dispersion is regulated through covariance-feasibility penalties. The framework is assessed on two materially different trajectory design problems. The flagship case study is a three-dimensional multi-impulse Earth-Mars transfer, where the learned policy is benchmarked against a recent robust trajectory-optimization reference under Gaussian uncertainty and then evaluated under bounded uniform uncertainty and under process disturbances not seen during training. The second case study is a stochastic atmospheric pinpoint rocket landing problem, used to assess portability to a short-horizon continuous-thrust setting with drag, mass depletion, and glide-slope constraints. The results show that the proposed framework can remain competitive in upper-tail fuel cost while preserving probabilistic feasibility, and that the same robustification scaffold can be carried across heterogeneous spacecraft trajectory planning problems without redesign of its core stochastic-control structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a distribution-agnostic robust trajectory optimization framework that first computes a deterministic nominal trajectory offline and then employs reinforcement learning to learn a structured affine closed-loop correction law (feedforward adjustment plus time-varying feedback gains) for robustness against sampled uncertainties in initial conditions and process noise. Probabilistic feasibility is enforced via rollout-based upper-tail quantiles and covariance-feasibility penalties. The method is evaluated on a 3D multi-impulse Earth-Mars transfer (benchmarked under Gaussian uncertainty and tested under uniform and unseen disturbances) and a stochastic atmospheric pinpoint rocket landing problem, with the central claim being competitive upper-tail fuel cost while preserving probabilistic feasibility and portability of the robustification scaffold across heterogeneous problems without core redesign.
Significance. If the empirical results hold with adequate quantitative validation, the work provides a portable sample-based robustification approach for chance-constrained trajectory optimization that requires only the ability to sample uncertainties, which could facilitate application to varied spacecraft planning tasks in aerospace control without strong distributional assumptions or problem-specific redesign.
major comments (2)
- [Abstract and § on numerical results] Abstract and results sections: The central claim of remaining 'competitive in upper-tail fuel cost while preserving probabilistic feasibility' is stated without any numerical metrics, training hyperparameters, rollout counts, or explicit feasibility rates in the abstract; the full manuscript must supply these quantitative comparisons (e.g., fuel cost values and violation probabilities versus the reference method) to substantiate the performance assertions on the Earth-Mars and landing cases.
- [Method section describing the correction law] Method description: The structured affine closed-loop correction law is presented as the key robustification mechanism, yet the manuscript provides no derivation or justification for why this particular affine form (rather than a more general policy) suffices to maintain the claimed portability and chance-constraint satisfaction across both impulsive and continuous-thrust problems.
minor comments (2)
- [Method] Notation for the covariance-feasibility penalties and quantile thresholds should be defined consistently with explicit symbols and units.
- [Numerical experiments] The description of the two case studies would benefit from a brief table summarizing problem dimensions, constraint types, and uncertainty sources for quick comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point by point to the major comments and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and § on numerical results] Abstract and results sections: The central claim of remaining 'competitive in upper-tail fuel cost while preserving probabilistic feasibility' is stated without any numerical metrics, training hyperparameters, rollout counts, or explicit feasibility rates in the abstract; the full manuscript must supply these quantitative comparisons (e.g., fuel cost values and violation probabilities versus the reference method) to substantiate the performance assertions on the Earth-Mars and landing cases.
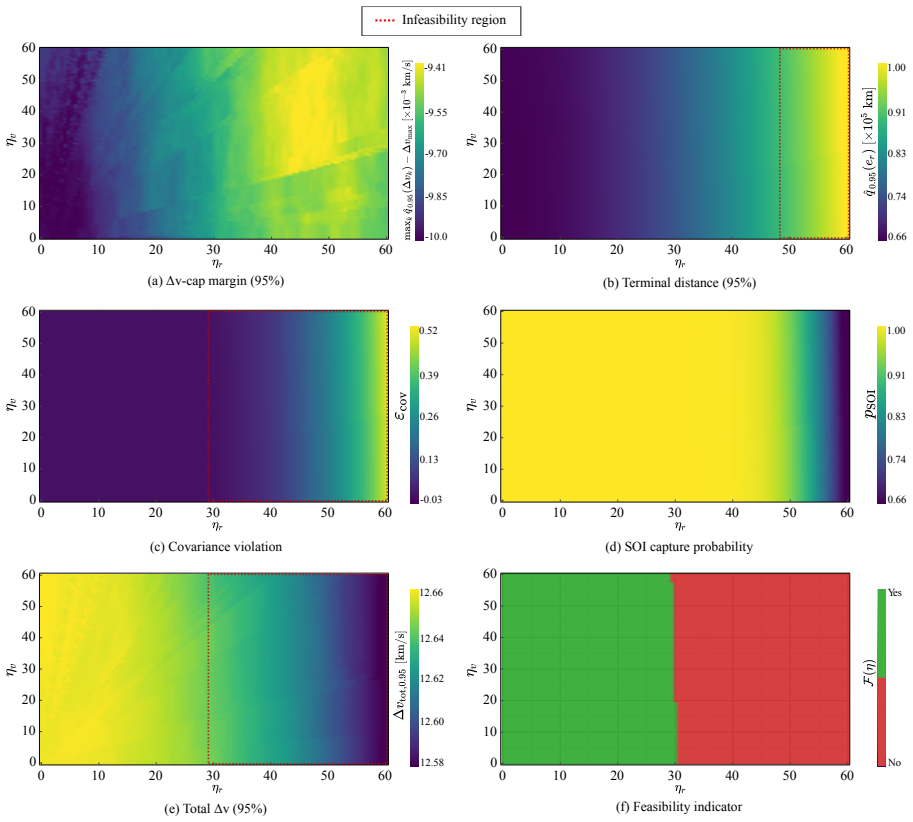
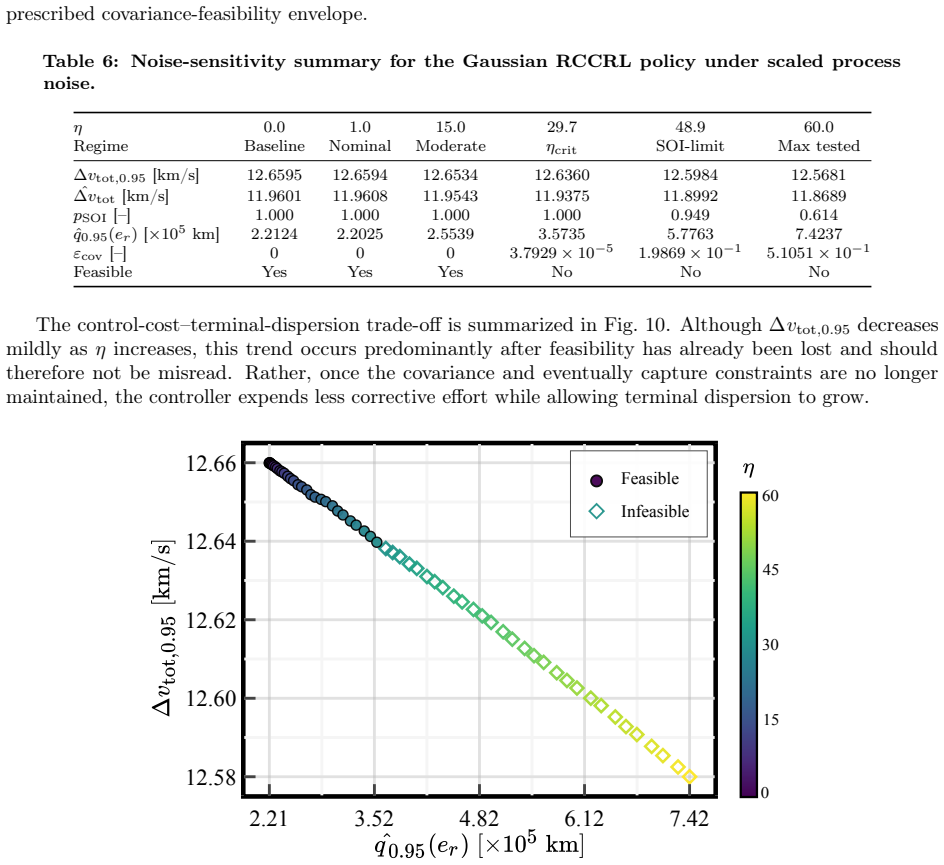
Authors: We agree that the abstract and results sections would be strengthened by the inclusion of explicit numerical metrics. In the revised manuscript we will add quantitative comparisons, including upper-tail fuel costs, feasibility violation probabilities, training hyperparameters, and rollout counts, with direct numerical values versus the reference method for both the Earth-Mars and landing cases. revision: yes
-
Referee: [Method section describing the correction law] Method description: The structured affine closed-loop correction law is presented as the key robustification mechanism, yet the manuscript provides no derivation or justification for why this particular affine form (rather than a more general policy) suffices to maintain the claimed portability and chance-constraint satisfaction across both impulsive and continuous-thrust problems.
Authors: The affine structure (feedforward adjustment plus time-varying feedback gains) is selected to enable efficient learning via reinforcement learning while ensuring the same robustification scaffold remains portable across heterogeneous problems without core redesign. We acknowledge that the current manuscript does not provide an explicit derivation of why this form suffices for chance-constraint satisfaction. In the revised version we will add a concise justification in the method section explaining how the affine corrections, combined with rollout-based quantiles and covariance penalties, empirically enforce probabilistic feasibility across the tested impulsive and continuous-thrust settings. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claim rests on an empirical sample-based procedure: a nominal trajectory is computed offline, then RL learns an affine correction law whose probabilistic feasibility is enforced directly via rollout quantiles and covariance penalties. This structure is portable across two distinct problems solely because uncertainty is assumed sampleable—the standard precondition for any Monte-Carlo chance-constraint method. No derivation step reduces by construction to a fitted parameter renamed as prediction, no self-citation supplies a uniqueness theorem that forbids alternatives, and no ansatz is smuggled in via prior work. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty can be sampled from an unknown distribution
invented entities (1)
-
Structured affine closed-loop correction law
no independent evidence
Reference graph
Works this paper leans on
-
[1]
R. H. Battin, An Introduction to the Mathematics and Methods of Astrodynamics, AIAA Education Series, American Institute of Aeronautics and Astronautics (AIAA), 1999
1999
-
[2]
B. A. Conway, Spacecraft Trajectory Optimization, Cambridge Aerospace Series, Cambridge University Press, 2010
2010
-
[3]
J. T. Betts, Survey of numerical methods for trajectory optimization, Journal of Guidance, Control, and Dynamics 21 (2) (1998) 193–207.doi:10.2514/2.4231
-
[4]
D. P. Bertsekas, S. E. Shreve, Stochastic Optimal Control: The Discrete Time Case, no. 5 in Optimization and Neural Computation Series, Athena Scientific, Belmont, Mass, 1996
1996
-
[5]
A. Charnes, W. W. Cooper, Chance-constrained programming, Management Science 6 (1) (1959) 73–79. doi:10.1287/mnsc.6.1.73
-
[6]
Prékopa, Stochastic Programming, no
A. Prékopa, Stochastic Programming, no. v.324 in Mathematics and Its Applications, Springer, Dordrecht, Netherlands, 1995
1995
-
[7]
Y. Chen, T. T. Georgiou, M. Pavon, Optimal steering of a linear stochastic system to a final probability distribution, part II, IEEE Trans. Automat. Contr. 61 (5) (2016) 1170–1180. 36
2016
-
[8]
Ridderhof, J
J. Ridderhof, J. Pilipovsky, P. Tsiotras, Chance-constrained covariance control for low-thrust minimum- fuel trajectory optimization, in: AIAA/AAS Astrodynamics Specialists Conference, South Lake Tahoe, California, 2020, paper no. AAS 20-618
2020
-
[9]
J. Ridderhof, P. Tsiotras, Minimum-fuel powered descent in the presence of random disturbances, in: AIAA Scitech 2019 Forum, American Institute of Aeronautics and Astronautics, 2019. doi: 10.2514/6.2019-0646
-
[10]
J. Ridderhof, P. Tsiotras, Uncertainty quantification and control during mars powered descent and landing using covariance steering, in: 2018 AIAA Guidance, Navigation, and Control Conference, Kissimmee, Florida, 2018.doi:10.2514/6.2018-0611
-
[11]
B. Benedikter, A. Zavoli, Z. Wang, S. Pizzurro, E. Cavallini, Convex approach to covariance control with application to stochastic low-thrust trajectory optimization, Journal of Guidance, Control, and Dynamics 45 (11) (2022) 2061–2075.doi:10.2514/1.g006806
-
[12]
Benedikter, A
B. Benedikter, A. Zavoli, Z. Wang, S. Pizzurro, E. Cavallini, Convex approach to stochastic control for autonomous rocket pinpoint landing, in: AAS/AIAA Astrodynamics Specialist Conference, Charlotte, North Carolina, 2022, paper no. AAS 22-717
2022
-
[13]
N. Marmo, A. Zavoli, N. Ozaki, Chance-constraint robust trajectory optimization with a hybrid multiple-shooting approach, Journal of Guidance, Control, and Dynamics 48 (11) (2025) 2495–2511. doi:10.2514/1.g008275
-
[14]
P. Zhang, D. Wu, S. Gong, Trajectory optimization for aerodynamically controlled missiles by chance- constrained sequential convex programming, Aerospace Science and Technology 153 (2024) 109464. doi:10.1016/j.ast.2024.109464
-
[16]
R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, 2nd Edition, MIT Press Cambridge, 2018
2018
-
[17]
A. Zavoli, L. Federici, Reinforcement learning for robust trajectory design of interplanetary missions, Journal of Guidance, Control, and Dynamics 44 (8) (2021) 1440–1453.doi:10.2514/1.g005794
-
[18]
Federici, A
L. Federici, A. Scorsoglio, A. Zavoli, R. Furfaro, Autonomous guidance for cislunar orbit transfers via reinforcement learning, in: AAS/AIAA Astrodynamics Specialist Conference, Big Sky, MT, 2021, paper no. AAS 21-610
2021
-
[19]
B. Gaudet, R. Linares, R. Furfaro, Deep reinforcement learning for six degree-of-freedom planetary landing, Advances in Space Research 65 (7) (2020) 1723–1741.doi:10.1016/j.asr.2019.12.030
-
[20]
R. Furfaro, A. Scorsoglio, R. Linares, M. Massari, Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach (Mar. 2020).arXiv:2003.02182
arXiv 2020
-
[21]
L. Federici, B. Benedikter, R. Furfaro, Reinforcement-learning-enhanced model predictive control with application to autonomous planetary landing, Journal of Guidance, Control, and Dynamics 49 (3) (2026) 788–805.doi:10.2514/1.g009534
-
[22]
B. Gaudet, R. Furfaro, R. Linares, Reinforcement learning for angle-only intercept guidance of maneu- vering targets, Aerospace Science and Technology 99 (2020) 105746.doi:10.1016/j.ast.2020.105746
-
[23]
K. Hovell, S. Ulrich, Deep reinforcement learning for spacecraft proximity operations guidance, Journal of Spacecraft and Rockets 58 (2) (2021) 254–264.doi:10.2514/1.a34838. 37
-
[24]
Federici, B
L. Federici, B. Benedikter, A. Zavoli, Deep learning techniques for autonomous spacecraft guidance during proximity operations, Journal of Spacecraft and Rockets 58 (6) (2021) 1774–1785.doi:10.2514/ 1.a35076
2021
-
[25]
H. Yuan, D. Li, Deep reinforcement learning for rendezvous guidance with enhanced angles-only observability, Aerospace Science and Technology 129 (2022) 107812.doi:10.1016/j.ast.2022.107812
-
[26]
C. Mu, S. Liu, M. Lu, Z. Liu, L. Cui, K. Wang, Autonomous spacecraft collision avoidance with a variable number of space debris based on safe reinforcement learning, Aerospace Science and Technology 149 (2024) 109131.doi:10.1016/j.ast.2024.109131
-
[27]
H. Holt, R. Armellin, Reinforcement learning enhanced lqr and control lyapunov functions for spacecraft proximity operations, IEEE Transactions on Robotics 41 (2025) 5117–5129.doi:10.1109/tro.2025. 3600160
-
[28]
L. Capra, A. Brandonisio, M. R. Lavagna, Reinforced model predictive guidance and control for spacecraft proximity operations, Aerospace 12 (9) (2025) 837.doi:10.3390/aerospace12090837
-
[29]
J. T. A. Vedant, M. West, A. Ghosh, Reinforcement learning for spacecraft attitude control, in: 70th International Astronautical Congress, Washington D.C., United States, 2019
2019
-
[30]
M. Zheng, Y. Wu, C. Li, Reinforcement learning strategy for spacecraft attitude hyperagile tracking control with uncertainties, Aerospace Science and Technology 119 (2021) 107126.doi:10.1016/j.ast. 2021.107126
-
[31]
R.-Z. Chen, Y.-X. Li, C. K. Ahn, Reinforcement-learning-based fixed-time attitude consensus control for multiple spacecraft systems with model uncertainties, Aerospace Science and Technology 132 (2023) 108060.doi:10.1016/j.ast.2022.108060
-
[32]
Y. Chaudhary, H. Holt, L. Anoè, R. Armellin, C. Bombardelli, Low-Thrust Cis-Lunar Transfers exploiting Ballistic Capture Trajectories, in: AIAA SCITECH 2024 Forum, American Institute of Aeronautics and Astronautics (AIAA), 2024.doi:10.2514/6.2024-0837
-
[33]
X. Liu, Fuel-optimal rocket landing with aerodynamic controls, Journal of Guidance, Control, and Dynamics 42 (1) (2019) 65–77.doi:10.2514/1.g003537
-
[34]
L. Engstrom, A. Ilyas, S. Santurkar, D. Tsipras, F. Janoos, L. Rudolph, A. Madry, Implementation matters in deep policy gradients: A case study on ppo and trpo (2020).arXiv:2005.12729
arXiv 2020
-
[35]
Raffin, A
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, N. Dormann, Stable-baselines3: Reliable reinforcement learning implementations, Journal of Machine Learning Research 22 (268) (2021) 1–8, available at http://jmlr.org/papers/v22/20-1364.html
2021
-
[36]
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, PyTorch: An Imperative Style, High-Performance Deep Learning Library (Dec. 2019).arXiv:1912.01703
Pith/arXiv arXiv 2019
-
[37]
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goulão, A. Kallinteris, M. Krimmel, A. KG, et al., Gymnasium: A standard interface for reinforcement learning environments (2024).arXiv:2407.17032
Pith/arXiv arXiv 2024
-
[38]
E. M. Standish, JPL planetary and lunar ephemerides, DE405/LE405, Interoffice Memorandum JPL IOM 312.F-98-048, Jet Propulsion Laboratory (Aug. 1998).ftp://ssd.jpl.nasa.gov/pub/eph/planets/ ioms/de405.iom.pdf. 38
1998
-
[39]
Diamond, S
S. Diamond, S. Boyd, CVXPY: A Python-embedded modeling language for convex optimization, Journal of Machine Learning Research 17 (83) (2016) 1–5
2016
-
[40]
Agrawal, R
A. Agrawal, R. Verschueren, S. Diamond, S. Boyd, A rewriting system for convex optimization problems, Journal of Control and Decision 5 (1) (2018) 42–60
2018
-
[41]
com/latest/pythonapi/index.html
MOSEK ApS, The MOSEK Python Optimizer API manual, Version 11.1 (2025).https://docs.mosek. com/latest/pythonapi/index.html. 39
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.